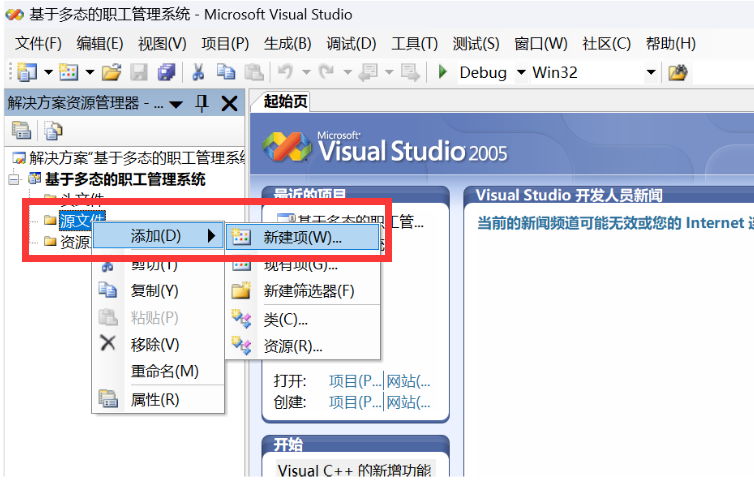
目标检测方法
传统的方法可以按照检测系统分为两种:
- DPM,Deformatable Parts Models,采用sliding window检测
- R-CNN、Fast R-CNN。采用region proposal的方法,生成一些可能包含待检测物体的potential bounding box,再通过一个classifier(SVM)判断每个bbox里是否真的包含物体,以及物体的class probability。
目前深度学习相关的目标检测方法大致可以分为两派:
- 基于区域提名的(regin proposal)的,比如R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN。
- 基于端到端(end to end)的,无需候选区域,如YOLO、SSD。
二阶段的检测方法
通常由两个主要的模块组成:候选区域生成和分类器。
在第一个阶段,候选区域生成模块会生成一组可能包含目标的边界框,这些边界框被称为候选框或region proposal。常见的候选框生成方法包括选择性搜索(Selective Search)、Edge Boxes等。
在第二个阶段,分类器会对每个候选框进行分类,以确定其是否包含目标对象以及目标的类别。
二阶段的检测方法通常比一阶段的方法更准确,但也更慢,因为需要进行两次计算:一次用于生成候选框,另一次用于分类。
二阶段检测方法的代表算法包括:
- Faster R-CNN
- R-CNN
- Fast-RCNN
一阶段的检测方法
YOLO系列将检测任务当做一个回归问题(regression problem)来处理,使用一个神经网络,直接从一整张图像来预测出bounding box 的坐标、box中包含物体的置信度和物体的probabilities。
SSD (Single Shot MultiBox Detector):通过多个卷积层提取特征,通过边界框的大小、长宽比、位置来预测目标的位置和类别。
RetinaNet:使用Focal Loss解决目标类别不平衡的问题,通过融合不同尺度的特征图提高检测性能。
相关名词
栅格(grid cell):YOLO将输入图像划分为S * S的栅格,每个栅格负责检测中心落在该栅格中的物体,论文中设置为7*7,每一个栅格预测B个bounding boxes,以及C个conditional class probability(条件类别概率)
边界框(bounding box):论文中设置为2,每个栅格的两个bounding box都是预测同一类物体。每个bounding box含有5个值(x,y,w,h,confidence)。
x,y:代表了预测的bounding box的中心与某个栅格的偏移值。
w,h:代表了预测的bounding box的width、height相对于整幅图像width,height的比例。
置信度(confidence)=类概率*IoU Pr(Object)是边界框内存在对象的概率,若存在对象,Pr(Object)=1,否则Pr(Object)=0;IOU是真实框(ground truth)与预测框(predicted box)的交并比
通用目标检测数据集
Pascal VOC2007 是一个目标检测中一个中等规模的数据集,共有20个类别。其数据分为三部分:训练、验证和测试,每部分分别包含 2501, 2510 和 5011张图片。
Pascal VOC2012是一个用于对象检测的中型数据集,与Pascal VOC2007拥有相同的20个类别。其数据分为三部分:训练、验证和测试,每部分分别包含5717、5823和10991张图像。VOC2012测试集没有标注信息(annotation)
MSCOCO 是具有80个类别的大规模数据集。其数据分为三部分:训练、验证和测试,每部分分别包含 118287, 5000 和 40670张图片。其测试数据集没有标注信息。
Pascal Open Images 包含1.9M图像,1500万个对象,600个类别。其中500个频率最大的种类用做目标检测基准,这500个种类中超过70%的有1000个以上的样本数量。
LVIS是一个新收集的基准,包含164000张图像和1000多个类别。
ImageNet 也是一个拥有200个类别的重要数据集。然而景观其规模很大,但是目标的尺度范围和VOC数据集相似,所以通常不用做目标检测的基准数据集。但是目标检测模型的backbone却仍在大量采用使用ImageNet预训练好的模型。
YOLOV1算法原理
1 首先将一幅图像分成 S*S网格,如果某个物体真实边界框中心落在该网格中,则由这个网格负责预测这个物体
2 每个网格要预测B个bounding box ,每一个box不仅要预测自身位置坐标(该坐标都是归一化后的),而且还要预测confidence(置信度)。
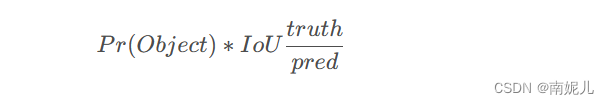
该置信度包含了这个边界框是否包含物体,如果包含物体,这上述第一项为1.第二项是预测边界框和真实边界框得Iou值,表示该边界框得预测准确度。
3 每个网格单元针对20种类别预测bboxes属于单个类别的条件概率 ,属于同一个网格的B个bboxes共享一个条件概率。在测试时,将条件概率分别和单个的bbox的confidence预测相乘

YOLO一共使用了24个级联的卷积层和2个全连接层(fc),其中conv层中包含了1×1和3×3两种kernel,最后一个fc全连接层后经过reshape之后就是YOLO网络的输出,是长度为S×S×(B×5+C)=7×7×30的tensor,最后经过识别过程得到最终的检测结果。
每个grid cell有30维,其中8维是两个预测回归bboxes的坐标信息,2维是bboxes的confidences,还有20维是与类别相关的信息。注意这里20个关于类别的条件概率是因为这里使用Pascal VOC 2007上进行训练的。这里的关于类别的条件概率是两个boudding box共有的,也就是说这个概率其实是属于每个网格的。这里预测两个边界框是为了判断该边界框是否包含物体以及包含物体的准确率。
每个网格预测的类别概率乘以每个bbox的预测confidence,得到每个bbox的class-specific confidence score分数。对每个网格的每一个bounding box进行此运算,最后会得到7×7×2=98个scores,设置一个阈值,滤掉得分低的bboxes,对保留的bboxes进行NMS(Non Maximum Suppression)处理,最终得到目标检测结果。
(总结)首先将图片分割成网格形式,每一个网格负责真实边界框中心落到该网格的物体。每一个网格负责生成B个Bounding box,每一个Bounding box包含了5个数字,分别为(x,y,w,h,confidence),其中置信度描述了该Bounding box 是否含有物体以及该物体有多准的准确性(在公式中表现为两项,第一项为是物体的概率取值为0或1,有物体则1,没有则为0.第二项为真实边界框和预测边界框的IOU)。每一个网格还预测了物体的类别概率,即预测该网格是某类物体的概率,总共20维。在预测的时候会将得到的每一个Bounding box的置信度和类别概率相乘得到每一个Bounding box的 score(这里是20维的张量,因为有20个类别),表示该边界框预测某类物体的概率,总共会有20个数字。将得到的所有Bounding box的置信度分数进行阈值处理,将低于阈值的score设为0.最后得到score最大的框,设置为bbox_max,然后将所有score不为0的bbox(这种bbox也叫做bbox_cur)与bbox_max进行IOU比较,如果IOU大于0.5,说明两个bbox相似度比较高,这是设置该bbox_cur的score 为0.然后继续遍历下一个bbox_cur,将该bbox_cur设置为bbox_max,与剩下的bbox进行IOU比较。直到遍历完所有的bbox。(注意这里分为了两步,首先直接对score进行处理,得到表示该类物体概率最大的边界框。然后此时会有很多重复的边界框,需要对边界框进行去重,所以这是遍历每一个边界框进行IOU比较,去掉重复率比较高的边界框)。通过NMS算法处理后,会有bbox对于某些类的score为0。这是针对某一个bbox的20维张量,寻找最大的score的索引记作class,然后找到score ,如果score大于0,则画出边界框。
搞懂YOLO v1看这篇就够了_yolov1介绍_Antrn的博客-CSDN博客
归一化坐标
yolo预测每个网格的B个边界框向量(x,y,w,h,confidence).
(x,y)是bbox 的中心相对于网格的偏移量。
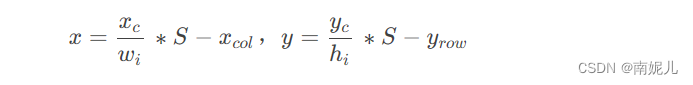
上述的S表示将图片分为S*S个网格,(xcol,yrow)表示该网格的坐标,(hi,wi)表示图片的高和宽,(xc,yc)表示bbox的中心坐标。 将上述公式进行逆变换就可以得到原始的边界框在原始图片中的坐标了。
(w,h)是bbox相对于整个图片的比例。
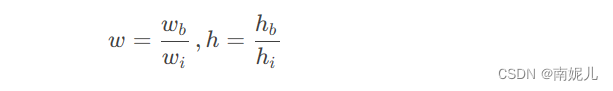
NMS
损失函数


评价指标
目标检测算法使用检测准确度和推断时间作为评估指标。
对于检测准确度,使用mean Average Precision(mAP)作为这些基准数据集上的评估指标。
对于推断时间可以使用FPS进行评估。
代码
参考:
Yolov1-pytorch版 论文、原理及代码实现_yolov1pytorch_今天也学习了嗷的博客-CSDN博客
YOLO-YOLOV5算法原理及网络结构整理_yolov5网络结构_我是快乐的小趴菜的博客-CSDN博客
搞懂YOLO v1看这篇就够了_yolov1介绍_Antrn的博客-CSDN博客