文章目录
- Revisiting Open Domain Query Facet Extraction and Generation
- Motivation
- Contributions
- Method
- Facet Extraction and Generation
- Facet Extraction as Sequence Labeling
- Autoregressive Facet Generation
- Facet Generation as Extreme Multi-Label Classification
- Facet Generation by Prompting Large Language Models
- Unsupervised Facet Extraction from SERP
- Facet Lists Aggregation
- Data
Revisiting Open Domain Query Facet Extraction and Generation
https://dl.acm.org/doi/abs/10.1145/3539813.3545138
Motivation
Revisit the task of query facet extraction and generation and study various formulations of this task
- also explored various aggregation approaches based on relevance and diversity to combine the facet sets produced by different formulations of the task
Contributions
- Introduction of novel formulations for the facet extraction and generation task(by the recent advancements in text understanding and generation)
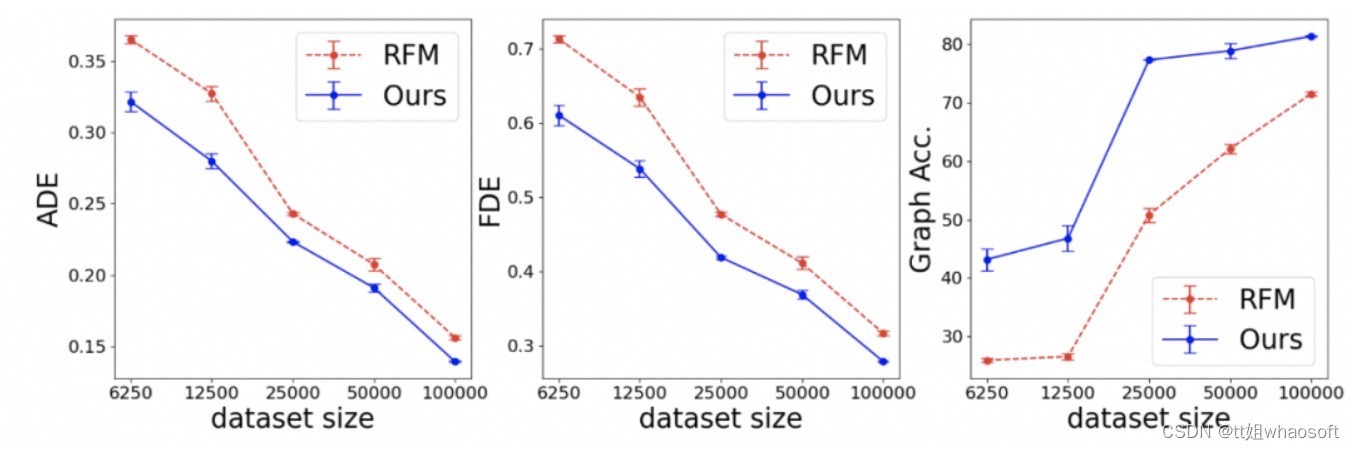
- Through offline evaluation, we demonstrate that the models studied in this paper significantly outperform state-of-art baselines. We demonstrate that their combination leads to improvement in recall
- create an open-source toolkit, named
Faspect, that includes various implementations of facet extraction and generation methods in this paper
Method
Facet Extraction and Generation
We focus on the extraction and generation of facets from the search engine result page (SERP) for a given query
-
training set:

- q i q_i qi is an open-domain search query
- D i = [ d i 1 , d i 2 , ⋯ , d i k ] D_i = [d_{i1}, d_{i2}, \cdots,d_{ik}] Di=[di1,di2,⋯,dik] denotes the top 𝑘 documents returned by a retrieval model in response to query.
- F i = { f i 1 , f i 2 , ⋯ , f i m } F_i = \{f_{i1}, f_{i2}, \cdots,f_{im}\} Fi={fi1,fi2,⋯,fim} is a set of m ground truth facets associated with query q i q_i qi
The task is to train a model to return an accurate list of facets.
Facet Extraction as Sequence Labeling
We can cast the facet extraction problem as sequence labeling task.

- w x ∈ t o k e n i z e ( d i j ) w_x \in tokenize(d_{ij}) wx∈tokenize(dij)
Our M θ e x t M_{\theta_{ext}} Mθext classifies each document token to B,I,O. We use RoBERTa and apply an MLP with the output dimensionality of three to each token representation of BERT.
-
input: [CLS] query tokens [SEP] doc tokens [SEP]
-
objective:

-
where

-
where p p p can be computed by applying a softmax operator to the model’s output for the x t h x^{th} xth token.
-

- inference: get the model output for all the documents in 𝐷 𝑖 𝐷_𝑖 Di and sort them by frequency
Autoregressive Facet Generation
We perform facet generation using an autoregressive text generation model.
For evert query q i q_i qi we concatenate the facets in F i F_i Fi using a separation token as y i y_i yi.
The model is BART(a Transformer-based encoder-decoder model for text generation.) and we use two variations:
-
variations:
-
only takes the query tokens and generates the facets
-
takes the query tokens and the document tokens for all documents in SERP (separated by [SEP]) as input and generates facet tokens one by one.
-
-
objective:

- v v v is the BART encoder’s output
-
inference: perform autoregressive text generation with beam search and sampling, conditioning the probability of the next token on the previous generated tokens
Facet Generation as Extreme Multi-Label Classification
we treat the facet generation task as an extreme multi-label text classification problem.
- The intuition behind this approach is that some facets tend to appear very frequently across different queries
The model is RoBERTa
M
θ
m
c
l
M_{\theta_{mcl}}
Mθmcl
-
get the probability of every facet by applying a linear transformation to the representation of the [CLS] token followed by sigmoid activation
-
objective(binary cross-entropy):

-
where y i , j ′ y'_{i,j} yi,j′ is the probability of relevance of the facet f j f_j fj given the query q i q_i qi and the list of documents D i D_i Di
-
it can be computed by applying a sigmoid operator to the model’s output for the j t h j^{th} jth facet class

-
-
Facet Generation by Prompting Large Language Models
We investigate the few-shot effectiveness of largescale pre-trained autoregressive language models.
model: GPT-3
-
generate facets using a task description followed by a small number of examples(prompt)
- Through prompting, we define the number of facets in the beginning of every example output. so that we can have control over the number of facets GPT-3 can generate.

Unsupervised Facet Extraction from SERP
Use some rules to extract facets from SERP and re-rank them.
Facet Lists Aggregation
We explore three aggregation methods: Learning to Rank, MMR diversification, Round Robin Diversification
-
Facet Relevance Ranking:
-
use a bi-encoder model to assign a score to each candidate facet for each query and re-rank them based on their score in descending order
-
score: use the dot product of the query and facet representations: sim(𝑞𝑖 , 𝑓𝑖 ) = 𝐸(𝑞𝑖 ) · 𝐸( 𝑓𝑖 ).
-
E: use the average token embedding of BERT pre-trained on multiple text similarity tasks. To find optimal parameter, minimize cross-entropy loss for every positive query-facet pair ( q i , f i + ) (q_i,f_i^+) (qi,fi+) in
MIMICSdataset
- B is the training batch size
- { f i , j − } j = 1 B − 1 \{f_{i,j}^-\}_{j=1}^{B-1} {fi,j−}j=1B−1 is the set of in-batch negative examples
-
-
-
MMR diversification:
-
use a popular diversification approach, named
Maximal Marginal Relevance(MMR).-
The intuition is that different models may generate redundant facets
-
score function:

- R R R is the list of extracted facets for a given query
- S S S is the set of already selected facets
-
-
-
Round Robin Diversification:
- iterate over the four lists of facets generated by different models, and alternatively select the facet with the highest score from each list until we generate the desired number of facets.
Data
MIMICS: contains web search queries sampled from the Bing query logs, and for each query, it provides up to 5 facets and the returned result snippets.
- train:
MIMICS-Click - evaluation:
MIMICS-Manual