【AI实战】训练一个自己的ChatGPT
- 准备
- 环境
- 代码
- 模型
- 数据集Belle
- 下载 Belle 的开源中文数据集(仅限研究使用,禁止商用!)
- 清洗自己的数据集
- 上述工作完成后,大概是这样子的
- 训练
- 测试
- 参考
本文使用 Alpaca-LoRA 来训练一个自己的 ChatGPT,数据集包括开源的55w数据集和我自己的1000w的医疗问答数据集。
准备
环境
- CUDA 10.2
- Ubuntu 20.04
- python 3.8
- torch 2.0.0
代码
使用 Alpaca-LoRA 的代码,我们先 clone Alpaca-LoRA:
git clone git@github.com:tloen/alpaca-lora.git
若出现下面的报错信息:
# git clone git@github.com:tloen/alpaca-lora.git
Cloning into 'alpaca-lora'...
git@github.com: Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
可以按照这篇文章进行处理:
https://blog.csdn.net/helloasimo/article/details/123778112
-
其他依赖安装
cd alpaca-lora pip install -r requirements.txt若是失败,可以多试几次,可能是网络问题。
-
上面完工后,大概是这样子的
/notebooks/alpaca-lora# ls -lh total 44M -rw-r--r-- 1 root root 20K Mar 31 07:53 DATA_LICENSE -rw-r--r-- 1 root root 635 Mar 31 07:53 Dockerfile -rw-r--r-- 1 root root 12K Mar 31 07:53 LICENSE -rw-r--r-- 1 root root 15K Mar 31 07:53 README.md -rw-r--r-- 1 root root 22M Mar 31 07:53 alpaca_data.json -rw-r--r-- 1 root root 22M Mar 31 07:53 alpaca_data_cleaned.json -rw-r--r-- 1 root root 643 Mar 31 07:53 docker-compose.yml -rw-r--r-- 1 root root 1.5K Mar 31 07:53 export_hf_checkpoint.py -rw-r--r-- 1 root root 3.6K Mar 31 07:53 export_state_dict_checkpoint.py -rw-r--r-- 1 root root 9.5K Mar 31 07:53 finetune.py -rw-r--r-- 1 root root 5.8K Mar 31 07:53 generate.py -rw-r--r-- 1 root root 81K Mar 31 07:53 lengths.ipynb -rw-r--r-- 1 root root 131 Mar 31 07:53 pyproject.toml -rw-r--r-- 1 root root 206 Mar 31 07:53 requirements.txt drwxr-xr-x 2 root root 4.0K Mar 31 07:53 templates drwxr-xr-x 2 root root 4.0K Mar 31 07:53 utils
模型
使用 alpaca-lora-cn-13b 模型作为我们的大模型
地址:https://huggingface.co/facat/alpaca-lora-cn-13b/tree/main
clone模型:
# Make sure you have git-lfs installed (https://git-lfs.github.com)
git lfs install
git clone https://huggingface.co/facat/alpaca-lora-cn-13b
注:可能需要手动下载 adapter_model.bin ,到 https://huggingface.co/facat/alpaca-lora-cn-13b/tree/main 可以手动下载
大概是这样子:
/notebooks# ls -lh alpaca-lora-cn-13b/
total 26M
-rw-r--r-- 1 root root 341 Mar 30 09:50 README.md
-rw-r--r-- 1 root root 371 Mar 30 09:50 adapter_config.json
-rw-rw-r-- 1 1003 1003 26M Mar 30 09:54 adapter_model.bin
数据集Belle
【如果没有自己的数据集,就用这个数据集来训练模型】
下载 Belle 的开源中文数据集(仅限研究使用,禁止商用!)
-
介绍
该数据集有 55w 条
下载数据集地址:
https://huggingface.co/datasets/BelleGroup/generated_train_0.5M_CN/tree/main -
数据格式:
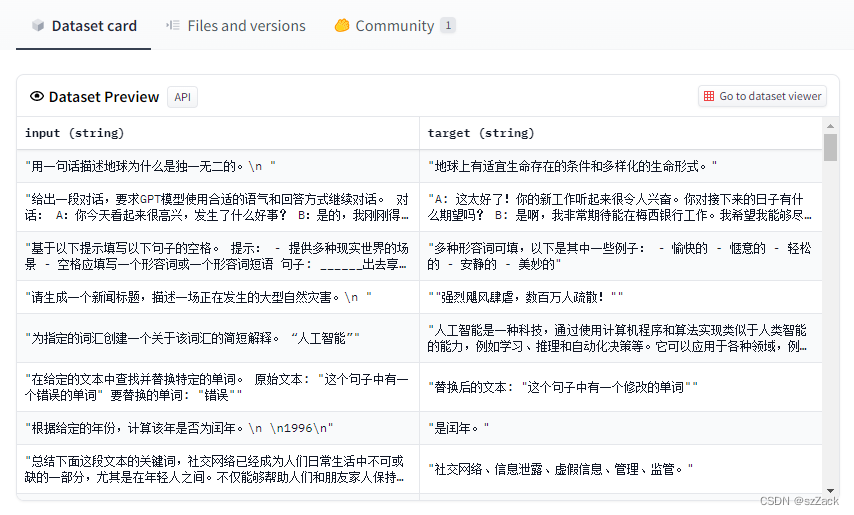
-
json格式
{"input": "用一句话描述地球为什么是独一无二的。\\n\n", "target": "地球上有适宜生命存在的条件和多样化的生命形式。"} {"input": "给出一段对话,要求GPT模型使用合适的语气和回答方式继续对话。\n对话:\nA:你今天看起来很高兴,发生了什么好事?\nB:是的,我刚刚得到一份来自梅西银行的工作通知书。\nA:哇,恭喜你!你打算什么时候开始工作?\nB:下个月开始,所以我现在正为这份工作做准备。", "target": "A: 这太好了!你的新工作听起来很令人兴奋。你对接下来的日子有什么期望吗?\nB: 是啊,我非常期待能在梅西银行工作。我希望我能够尽快适应新环境,并展示出我的所有技能和才能。"}
清洗自己的数据集
将数据清洗为上述 json 格式
数据有1000w条,太大了,这里就不放出来了。
数据格式同上。
数据清洗后的数据格式如下:
all_data.train.json:
[
{
"instruction": "Give three tips for staying healthy.",
"input": "",
"output": "1. Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."
},
{
"instruction": "What are the three primary colors?",
"input": "",
"output": "The three primary colors are red, blue, and yellow."
}
]
上述工作完成后,大概是这样子的
/notebooks# ls -lh
total 1.5G
drwxr-xr-x 6 root root 4.0K Mar 31 07:53 alpaca-lora
drwxr-xr-x 3 root root 4.0K Mar 31 08:15 alpaca-lora-cn-13b
drwxrwxr-x 2 1003 1003 4.0K Mar 30 09:14 data
其中清洗的数据:
/notebooks/data# du -sh all_data.train.json
6.2G all_data.train.json
训练
- 单卡训练
python3 finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path '../data/all_data.train.json' \
--output_dir './lora-alpaca-zh' \
--micro_batch_size 1 \
--num_epochs 3
过程如下:
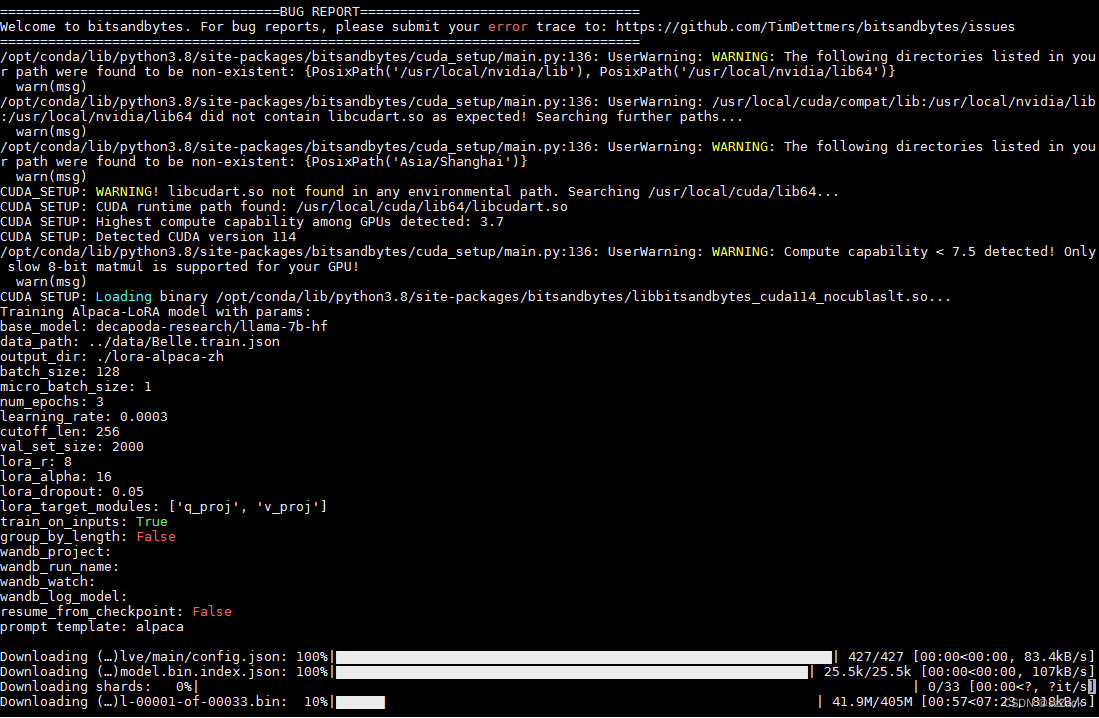
下载数据特别大,需要比较长的时间(我用了大概4个小时)!!!
- 多卡训练
我用了4个卡
WORLD_SIZE=4 CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun \
--nproc_per_node=2 \
--master_port=1234 \
finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path '../data/all_data.train.json' \
--output_dir './lora-alpaca-zh' \
--micro_batch_size 1 \
--num_epochs 3
测试
python3 generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
--lora_weights './lora-alpaca-zh'
- 测试效果
参考
- https://huggingface.co/facat/alpaca-lora-cn-13b/tree/main
- https://github.com/tloen/alpaca-lora
- https://github.com/gururise/AlpacaDataCleaned