目录索引
- ==什么是XML:==
文档演示:
- ==XML的节点关系:==
1.父节点:2. 子节点:3. 同胞节点:4. 先辈节点:5. 后代节点:
- ==Xpath:==
1. 相关语法:- *最常用的路径表达式:*
2. 谓语:3. 选取未知节点:4. 选取若干路径:
- ==LXML库配合Xpath进行有效解析:==
1. 导包:2. 实例化解析对象:3. 输出转换后的html代码:1. 实例演示:
- ==总结:==
恭喜你,获得了新的神装:Xpath
技能:解析神器,用于高效处理HTML文档
限制:我们需要先将HTML文件转换成XML文档,然后用Xpath查找HTML里的节点或元素。
永远支持全宇宙最好的BeautifulSoup,当然了Xpath也有它好的一面,都需要了解。Xpath特别适用于文档解析,是以路径的形式来进行描述的。
什么是XML:
- XML指可扩展标记语言
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 的标签需要我们自行定义
- 会自动补齐缺失的尾标签
文档演示:
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
XML的节点关系:
1.父节点:
每个元素以及属性都有一个父
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
我们可以知道:book元素就是其中的父元素,它是 title\author\year\price 元素的父
2. 子节点:
元素节点可能有零个、一个或多个子节点
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
我们得知:title\author\year\price 都是book的子元素节点
3. 同胞节点:
拥有相同的父节点
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
在这里:title\author\year\price 之间互为同胞节点
4. 先辈节点:
父及以上,如爷爷等都是属于先辈节点
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
在这里:author的先辈节点是book元素和bookstore元素
5. 后代节点:
与先辈节点相反,儿孙等都是后代节点
```xml
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
在这里:bookstore的后代是 book\title\author\year\price 元素
Xpath:
这是一门在xml文档中查找信息的语言,可用来在XML文档中对元素和属性进行遍历。XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
1. 相关语法:
最常用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。(用的多) |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 (重要) |
举例:
| 路径表达式 | 结果 | |
|---|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 | |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! | |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 | |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 | |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 | |
| //@lang | 选取名为 lang 的所有属性。 |
2. 谓语:
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中
人话就是:用[]框起来表示筛选条件的就是谓语
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()< 3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
注意:
- 元素从第一个开始选,不是零
- []是筛选条件,是将符合的元素呈现出来,而不是取里面的值
3. 选取未知节点:
Xpath通配符可用来选取未知的XML元素
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
- node()表示的是节点,* 表示的是元素,元素、文本、注释都属于节点,而标签属于元素,同时,标签后面的文本也会被识别为元素,只有标签前面的文本被当做文本来识别,所以使用*号时识别不到a标签前面的文本内容
- node()>*
例子:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| html/node()/meta/@* | 选择html下面任意节点下的meta节点的所有属性 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
4. 选取若干路径:
用过在路径表达式中使用"|"运算符,可以选取若干个路径。
例子:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
LXML库配合Xpath进行有效解析:
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
1. 导包:
from lxml import etree
2. 实例化解析对象:
xml = etree.HTML(html网页)
3. 输出转换后的html代码:
直接打印xml是输出不了的,它是一个对象,
#以字节形式输出转换后的html代码,前面带有b。若想正常输出需要用decode()进行解码
etree.tostring()
#举个例子:
print(etree.tostring(xml))
例子:
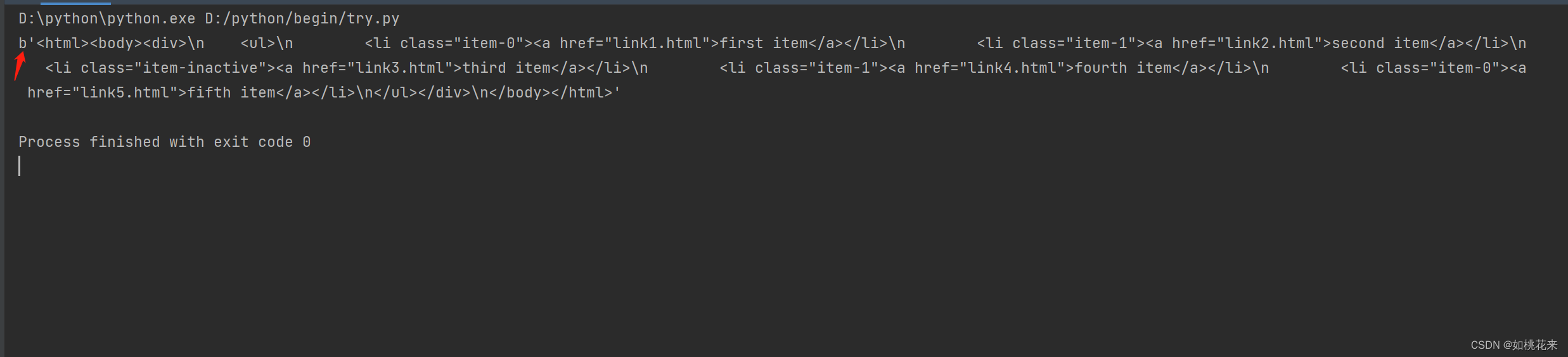
#举个例子:
print(etree.tostring(xml).decode())
呈现效果:

1. 实例演示:
html = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</div>
'''
#1. 导包,使用lxml中的etree类
from lxml import etree
#2. 创建实例化对象,共Xpath的解析对象(转换为xml格式的文档)
xml = etree.HTML(html)
#print(etree.tostring(xml).decode())#会自动补全body,html的尾部标签
下面的拆解的代码,便于阅读,默认拥有以上的代码:
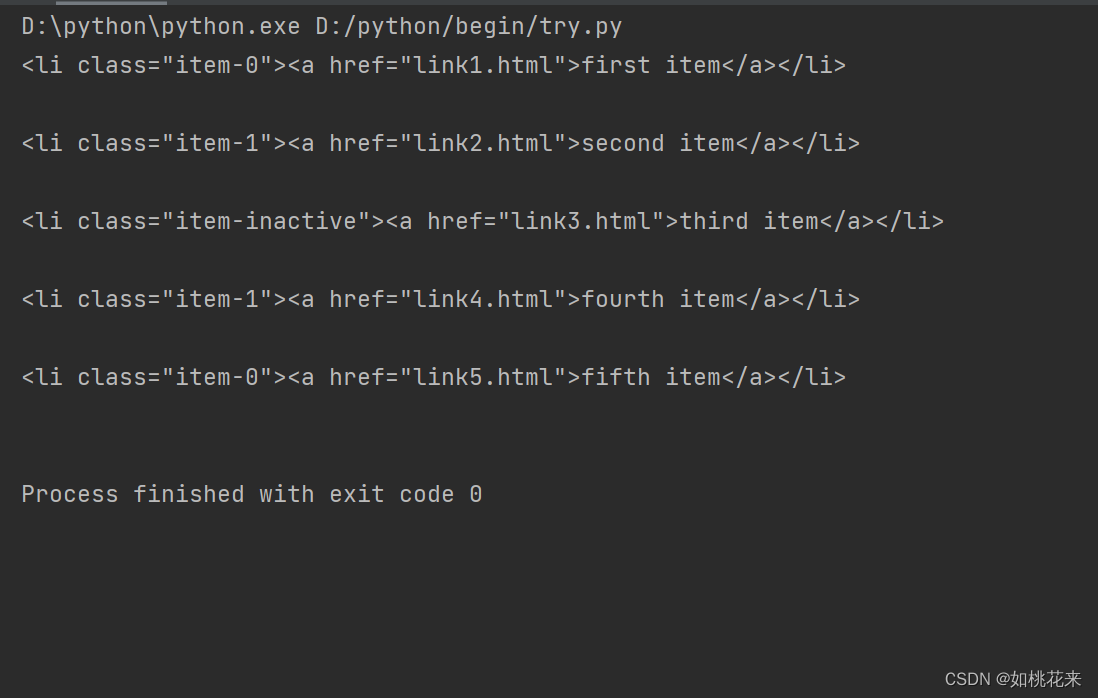
#获取其中的li标签
result = xml.xpath("//li")#获取任意层级下的li标签
#print(result)#打印出来全都是对象,需要用tostring加decode()转化
for i in result:
r = etree.tostring(i).decode()
print(r)
呈现效果:
#获取其中的class属性的值:
result = etree.xpath("//li/@class")
print(result)
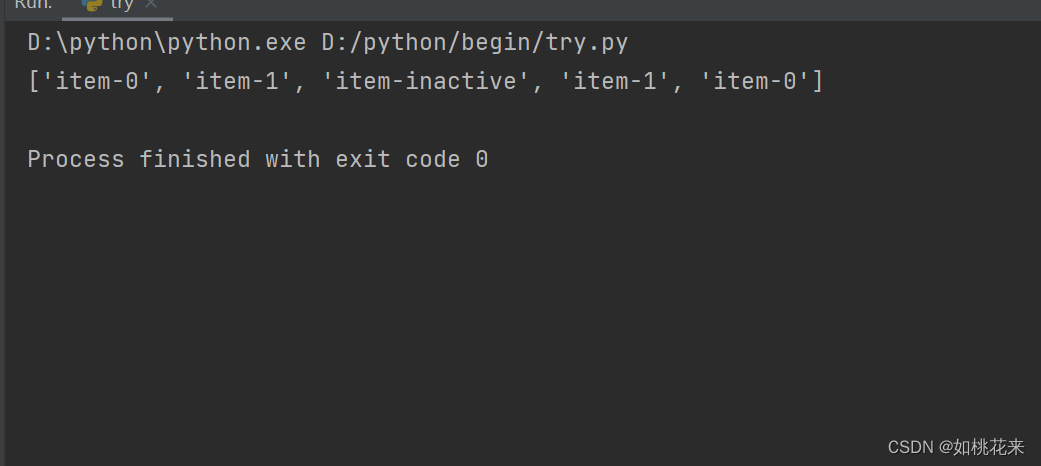
都是以列表的形式输出
#获取a标签中的href值
result = xml.xpath("//li/a/@href")
print(result)
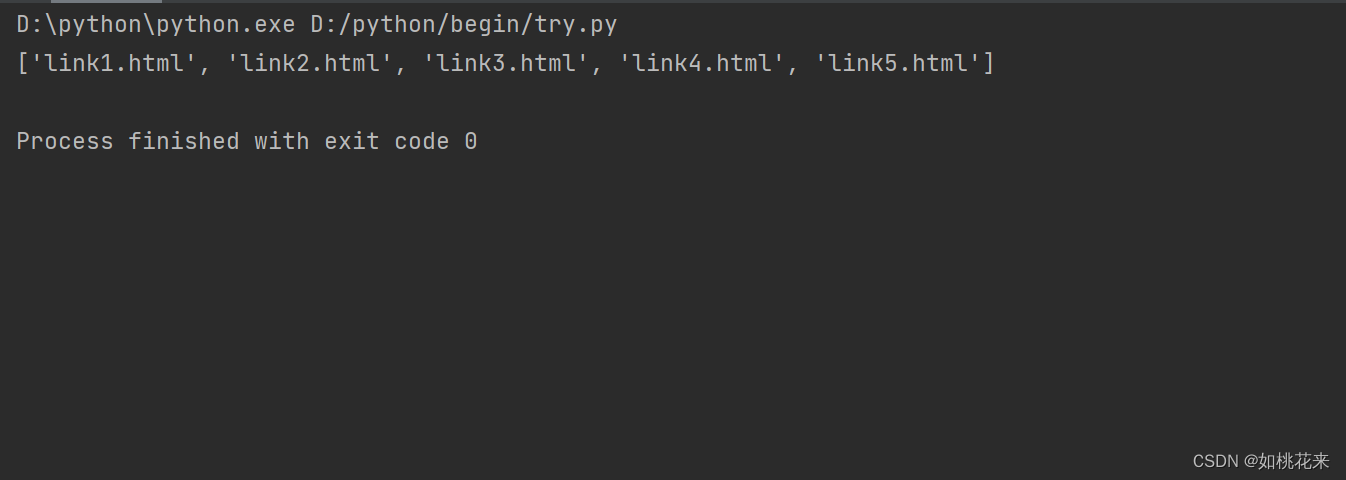
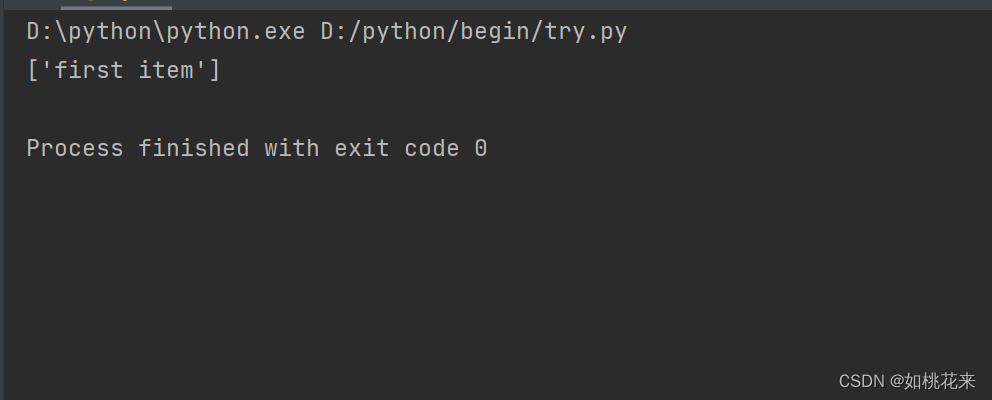
#找li标签下的href为link1.html的a标签的文本内容:
result = xml.xpath('//li/a[@href = "link1.html"]/text()')
print(result)
总结:
- 返回的结果都是列表
- 获取标签的具体内容一般不用tostring()
- 只要涉及到条件,加[]
- 只要涉及获取属性值,加@,@是拿的意思
- 通过/text()可以获取文本内容