目录
一、前言
二、What Is a Thread?
三、Advantages and Drawbacks of Threads
四、A First Threads Program
1、A Simple Threaded Program(thread1.c)
五、Simultaneous Execution
1、Simultaneous Execution of Two Threads(thread2.c)
六、Synchronization(同步)
1、Synchronization with Semaphores
(1)A Thread Semaphore(thread3.c)
2、Synchronization with Mutexes(使用互斥锁进行同步)
(1)A Thread Mutex(thread1.c)
一、前言
在上一板块“进程与信号”中,我们了解了如何在 Linux ( 以及 UNIX ) 中处理进程。这些多处理特性一直是类 unix 操作系统的一个特性。有时,让一个程序同时做两件事可能非常有用,或者至少看起来是这样做的,或者我们可能希望两件或更多的事情以紧密耦合的方式同时发生,但考虑到使用 fork 创建新进程的开销太大。对于这些情况,我们可以使用线程,它允许单个进程执行多任务。
下面我们将学习到:
❑ Creating new threads within a process
❑ Synchronizing data access between threads in a single process
❑ Modifying the attributes of a thread
❑ Controlling one thread from another in the same process
二、What Is a Thread?
一个程序中的多条执行链称为线程(threads)。更精确的定义是线程是进程中的控制序列。到目前为止,我们看到的所有程序都是作为一个进程执行的,尽管与许多其他操作系统一样,Linux 能够同时运行多个进程。实际上,所有进程都至少有一个执行线程。
重要的是要清楚 fork 系统调用和创建新线程之间的区别。当一个进程执行一个 fork 调用时,它会用自己的变量和自己的 PID 创建一个新的进程副本。这个新进程是独立调度的,并且 (通常) 几乎独立于创建它的进程执行。相反,当我们在进程中创建一个新线程时,执行的新线程将获得自己的堆栈 (以及本地变量),但与创建它的进程共享全局变量、文件描述符、信号处理程序及其当前目录状态。
线程的概念已经存在了一段时间,但是直到 IEEE POSIX 委员会发布了一些标准,它们才在类 unix 操作系统中广泛使用,而且存在的实现往往在不同的供应商之间有所不同。随着 POSIX 1003.1c 规范的出现,这一切都改变了。
线程不仅更好地标准化了,而且在大多数 Linux 发行版上都可以使用。现在多核处理器在桌面计算机中也很常见,大多数计算机也有底层硬件支持,允许它们同时物理地执行多个线程。以前,对于单核 cpu,线程的同时执行只是一个聪明的错觉,尽管其非常高效。
Linux 第一次获得线程支持是在 1996 年左右,它的库通常被称为 “LinuxThreads”。这非常接近 POSIX 标准 (实际上,对于许多目的来说,差异并不明显),这是向前迈出的重要一步,使 Linux 程序员第一次能够使用线程。然而,在 Linux 实现和 POSIX 标准之间有轻微的差异,最明显的是在信号处理方面。这些限制与其说是库实现造成的,不如说是来自 Linux 内核的底层支持的限制造成的。
各种项目都在研究如何改进 Linux 上的线程支持,这不仅是为了消除 POSIX 标准和 Linux 实现之间的细微差异,也是为了提高性能并消除任何不必要的限制。大部分工作集中在如何将用户级线程映射到内核级线程上。两个主要项目是新一代 POSIX 线程 (NGPT) 和原生 POSIX 线程库 (NPTL)。两个项目都必须对 Linux 内核进行更改,以支持新的库,并且都在较老的 Linux 线程之上提供了显著的性能改进。
2002年,NGPT 团队宣布他们不希望分裂社区,并将停止向 NGPT 添加新特性,但将继续致力于 Linux 中的线程支持,有效地支持 NPTL 的工作。NPTL 成为 Linux 上线程的新标准,它的第一个主流发布版本是 Red Hat Linux 9。我们可以在 Ulrich Drepper 和 Ingo Molnar 的题为“Linux 原生 POSIX 线程库”的论文中找到一些关于 NPTL 的有趣背景信息,在撰写本书时,该论文位于http://people.redhat.com/drepper/nptl-design.pdf。
本章中的大部分代码应该与任何线程库一起工作,因为它基于 POSIX 标准,该标准在所有线程库中都是通用的。但是,如果我们使用的是较老的 Linux 发行版,我们可能会看到一些细微的差异,特别是如果我们在运行示例时使用 ps 查看它们。
三、Advantages and Drawbacks of Threads
在某些情况下,创建一个新线程比创建一个新进程有一些明显的优势。创建一个新线程的开销成本明显低于创建一个新进程 (尽管与许多其他操作系统相比,Linux 在创建新进程方面特别高效)。
以下是使用线程的一些优点:
(1)有时,让程序看起来同时做两件事是非常有用的。经典的例子是在编辑文本的同时对文档执行实时单词计数。一个线程可以管理用户的输入并执行编辑。另一种,可以看到相同的文档内容,可以不断更新一个字数变量。第一个线程 (甚至是第三个线程) 可以使用这个共享变量来通知用户。另一个例子是多线程数据库服务器,其中单个进程服务多个客户机,通过服务某些请求,同时阻塞其他请求,等待磁盘活动,从而提高整体数据吞吐量。对于数据库服务器来说,这种明显的多任务处理很难在不同的进程中有效地完成,因为对锁定和数据一致性的要求导致不同的进程非常紧密地耦合。使用多线程比使用多个进程更容易做到这一点。
(2)混合输入、计算和输出的应用程序的性能可以通过将它们作为三个单独的线程运行来提高。当输入或输出线程等待连接时,其他线程中的一个可以继续进行计算。处理多个网络连接的服务器应用程序也很适合多线程程序。
(3)现在,多核 cpu 甚至在台式机和笔记本电脑中也很常见,如果应用程序合适,在一个进程中使用多个线程可以使单个进程更好地利用可用的硬件资源。
(4)一般来说,在线程之间切换需要操作系统做的工作要比在进程之间切换少得多。因此,多线程对资源的要求比多进程少得多,并且在单处理器系统上运行逻辑上需要多个线程执行的程序更实际。也就是说,编写多线程程序的设计困难是显著的,不应掉以轻心。
线程也有缺点:
(1)编写多线程程序需要非常仔细的设计。在多线程程序中引入微妙的计时错误或无意共享变量引起的错误的可能性是相当大的。Alan Cox (非常受尊敬的 Linux 专家) 评论说线程也被称为“如何同时射中自己的两只脚”。
(2)调试多线程程序比调试单线程程序要困难得多,因为线程之间的交互非常难以控制。
(3)一个将大型计算分为两个部分并将两个部分作为不同的线程运行的程序不一定会在单处理器机器上运行得更快,除非计算确实允许多个部分同时进行计算,并且执行它的机器具有多个处理器核心来支持真正的多处理。
四、A First Threads Program
有一整套与线程相关的库调用,其中大多数的名称都以 pthread 开头。要使用这些库调用,必须定义 macro_REENTRANT,包括文件 pthread.h,并使用 -lpthread 链接到线程库。
在设计最初的 UNIX 和 POSIX 库例程时,假定任何进程中都只有一个执行线程。一个明显的例子是 errno,该变量用于在调用失败后检索错误信息。在多线程程序中,默认情况下,所有线程之间只共享一个 errno 变量。在另一个线程能够检索到以前的错误代码之前,可以通过一个线程中的调用轻松地更新该变量。fputs 等函数也存在类似的问题,它们通常使用单个全局区域来缓冲输出。
你需要的 程序(routines) 叫做再入程序。可重入代码可以被多次调用,无论是通过不同的线程,还是通过某种方式的嵌套调用,仍然可以正确地运行。因此,代码的可重入部分通常必须仅以这样一种方式使用局部变量,即对代码的每次调用都获得其自己的唯一数据副本。
在多线程程序中,通过在程序中任何 #include 行之前定义 _reentrant 宏来告诉编译器我们需要这个特性。这可以做三件事,而且做得非常好,通常你甚至不需要知道做了什么:
(1)有些函数获得可重入安全等价的原型。它们通常是相同的函数名,但是 _r 被附加,例如, gethostbyname 被更改为 gethostbyname_r。
(2)一些 stdio.h 函数通常作为宏实现的可重入安全函数。
(3)来自 errno.h 的变量 errno 被更改为调用一个函数,该函数可以以多线程安全的方式确定真正的 errno 值。
包含文件 pthread.h 可以为我们提供代码中需要的其他定义和原型,很像用于标准输入和输出例程的 stdio.h。最后,需要确保包含适当的线程头文件,并链接到实现 pthread 函数的适当线程库。后面的 Program 示例提供了编译程序的更多细节,但首先让我们看看管理线程所需的新函数。pthread_create 创建一个新线程,就像 fork 创建一个新进程一样。

这可能看起来很强大,但实际上很容易使用。第一个参数是一个指向 pthread_t 的指针。创建线程时,将标识符写入该变量所指的内存位置。这个标识符使你能够引用线程。下一个参数设置线程属性。通常不需要任何特殊属性,可以简单地将NULL作为这个参数。在后面我们将可以看到如何使用这些属性。最后两个参数告诉线程要开始执行的函数和要传递给该函数的参数。
![]()
前一行只是说,你必须传递一个以 void 指针作为参数的函数的地址,该函数将返回一个指向 void 的指针。因此,我们可以传递任何类型的单个参数并返回指向任何类型的指针。使用 fork 会导致执行在相同的位置继续,但返回码不同,而使用新线程则显式提供了一个指向函数的指针,新线程应该在这里开始执行。
返回值是 0 表示成功,如果有任何错误,则返回一个错误编号。手册页详细介绍了这个函数和其他函数的错误条件。
与大多数 pthread_function 一样,pthread_create 是少数不遵循错误返回值为 1 的惯例的 Linux 函数之一。除非你非常确定,否则在检查返回代码之前再检查一遍手册总是最安全的。
当线程终止时,它调用 pthread_exit 函数,就像进程在终止时调用 exit 一样。此函数终止调用线程,返回指向对象的指针。永远不要使用它来返回指向局部变量的指针,因为当线程这样做时,变量将不再存在,从而导致严重的错误。pthread_exit 的声明如下:

pthread_join 相当于线程中的 wait,进程使用它来收集子进程。这个函数的声明如下:

第一个参数是要等待的线程,即 pthread_create 为你填写的标识符。第二个参数是指向指针的指针,该指针本身指向线程的返回值。与 pthread_create 类似,此函数成功时返回 0,失败时返回错误代码。
1、A Simple Threaded Program(thread1.c)
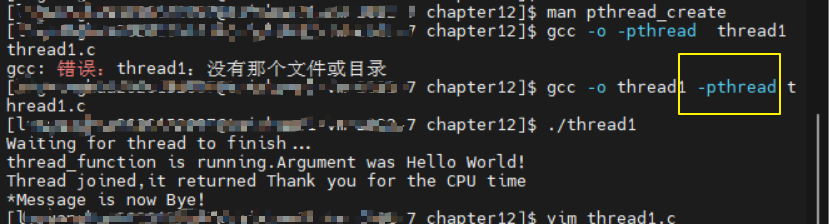
这个程序创建一个单独的额外线程,显示它与原线程共享变量,并让新线程将结果返回给原线程。多线程程序没有比这更简单的了! 下面是 thread1.c:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<pthread.h>
void *thread_function(void *arg);
char message[]="Hello World!";
int main()
{
int res;
pthread_t a_thread;
void *thread_result;
res=pthread_create(&a_thread,NULL,thread_function,(void *)message);
if(res!=0){
perror("Thread creation failed");
exit(EXIT_FAILURE);
}
printf("Waiting for thread to finish...\n");
res=pthread_join(a_thread,&thread_result);
if(res!=0){
perror("Thread join failed");
exit(EXIT_FAILURE);
}
printf("Thread joined,it returned %s\n",(char *)thread_result);
printf("*Message is now %s\n",message);
exit(EXIT_SUCCESS);
}
void *thread_function(void *arg){
printf("thread_function is running.Argument was %s\n",(char *)arg);
sleep(3);
strcpy(message,"Bye!");
pthread_exit("Thank you for the CPU time");
}
- 要编译它,首先需要确保定义了 _REENTRANT。在少数系统上,你可能还需要定义 _POSIX_C_SOURCE,但通常不需要这样做。
- 接下来,你必须确保链接了适当的线程库。如果使用的是较老的 Linux 发行版,其中 NPTL 不是默认线程库,那么你可能需要考虑升级,尽管大多数代码与较老的 Linux 线程实现兼容。一种简单的检查方法是查看 /usr/include/pthread.h, 如果这个文件显示了2003年或以后的版权日期,那么几乎可以肯定它是 NPTL 的实现。如果日期较早,那么可能是时候安装较新的 Linux 了。
- 识别并安装了适当的文件后,你现在可以像这样编译和链接你的程序:

- 如果 NPTL 是 系统上的默认选项 (这很有可能),那么几乎可以肯定不需要 -I 和 -L 选项,可以使用更简单的:
![]()
- 我们将使用编译行的简单版本。

注:非常值得花一点时间来理解这个程序,因为我们将使用它作为大多数例子的基础。
How It Works:
你声明一个函数的原型,当你创建它的时候线程会调用它:
![]()
正如 pthread_create 所要求的,它接受一个指向 void 的指针作为唯一参数,并返回一个指向 void 的指针。(我们稍后将讨论 thread_function 的实现。)
在 main 中,声明一些变量,然后调用 pthread_create 来开始运行新线程。

我们传递一个 pthread_t 对象的地址,你可以在之后使用该对象引用线程。你不希望修改默认线程属性,因此传递NULL作为第二个参数。最后两个形参是要调用的函数和要传递给它的形参。
如果调用成功,现在将运行两个线程。原来的线程 (main) 继续执行 pthread_create 之后的代码,一个新的线程开始在命名为线程函数的“想象”中执行。
原线程检查新线程是否已经启动,然后调用 pthread_join。
![]()
在这里,传递 等待加入的线程的标识符 和 一个指向结果的指针。该函数将等待到另一个线程终止后才返回。然后,它打印来自线程的返回值和变量的内容,然后退出。
新线程在 thread_function 开始时开始执行,该线程打印出它的参数,休眠一小段时间,更新全局变量,然后退出,向主线程返回一个字符串。新线程写入原线程可以访问的同一数组、消息。如果调用的是 fork 而不是 pthread_create ,则数组将是原始消息的副本,而不是相同的数组。
五、Simultaneous Execution
下一个示例展示如何编写一个程序来检查两个线程是否同时执行。(当然,如果你使用的是单处理器系统,CPU将在线程之间巧妙地切换,而不是让硬件使用单独的处理器核心同时执行两个线程)。因为你还没有遇到任何线程同步函数,这将是一个非常低效的程序,它在两个线程之间执行所谓的轮询。同样,我们将利用除了局部函数变量之外的所有内容都在进程中的不同线程之间共享这一事实。
1、Simultaneous Execution of Two Threads(thread2.c)
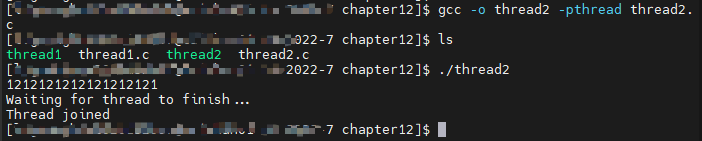
待会儿创建的程序 thread2.c 是通过稍微修改 thread1 .c 创建的。你可以添加一个额外的文件作用域变量来测试哪个线程正在运行:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
void *thread_function(void *arg);
int run_now = 1;
char message[] = "Hello World";
int main() {
int res;
pthread_t a_thread;
void *thread_result;
int print_count1 = 0;
res = pthread_create(&a_thread, NULL, thread_function, (void *)message);
if (res != 0) {
perror("Thread creation failed");
exit(EXIT_FAILURE);
}
while(print_count1++ < 20) {
if (run_now == 1) {
printf("1");
run_now = 2;
}
else {
sleep(1);
}
}
printf("\nWaiting for thread to finish...\n");
res = pthread_join(a_thread, &thread_result);
if (res != 0) {
perror("Thread join failed");
exit(EXIT_FAILURE);
}
printf("Thread joined\n");
exit(EXIT_SUCCESS);
}
void *thread_function(void *arg) {
int print_count2 = 0;
while(print_count2++ < 20) {
if (run_now == 2) {
printf("2");
run_now = 1;
}
else {
sleep(1);
}
}
sleep(3);
}
在执行主函数时将 run_now 设置为1,在执行新线程时将 run_now 设置为2。在main函数中,创建新线程后,添加以下代码:
int print_count1 = 0;
while(print_count1++ < 20) {
if (run_now == 1) {
printf(“1”);
run_now = 2;
}
else {
sleep(1);
}
}如果 run_now 为1,则打印 “1” 并将其设置为 2。否则,将短暂休息并再次检查值。通过反复检查,我们正在等待该值更改为 1。这被称为忙等待,尽管在这里它是通过在检查之间的一秒钟睡眠来减慢。在后面,我们将看到一种更好的方法。
在 thread_function 中,你的新线程正在执行,你做了很多相同的事情,但把值颠倒过来:
int print_count2 = 0;
while(print_count2++ < 20) {
if (run_now == 2) {
printf(“2”);
run_now = 1;
}
else {
sleep(1);
}
}删除参数传递和返回值传递,因为我们不再对它们感兴趣。
当你运行该程序时,将看到以下输出。(可能会发现,程序产生输出需要几秒钟的时间,尤其是在单核CPU机器上。)

How It Works:
每个线程通过设置 run_now 变量告诉另一个线程运行,然后等待另一个线程更改其值后再再次运行。这表明执行在两个线程之间自动传递,并再次说明两个线程共享 run_now 变量。
六、Synchronization(同步)
在前面我们看到两个线程一起执行,但是在它们之间切换的方法很笨拙,效率非常低。幸运的是,有一组专门设计的函数来提供更好的方法来控制线程的执行和对代码关键部分的访问。
我们在这里介绍两种基本方法:信号量和互斥锁,信号量充当一段代码的门卫,互斥锁充当互斥 (互斥锁因此得名) 设备,以保护代码片段。这些方法是相似的,事实上,一个可以根据另一个来实现。然而,在某些情况下,问题的语义表明一个比另一个更有表现力。例如,控制对某些共享内存的访问 (每次只能有一个线程访问),最自然的方法就是使用互斥锁。然而,控制对一组相同对象的整体访问,例如将一组 5 条可用线路中的一条给线程,更适合计数信号量。你选择哪一种取决于个人偏好和最适合您的程序的机制。
1、Synchronization with Semaphores
信号量有两组接口函数:一组来自 POSIX Realtime Extensions,用于线程,另一组称为 System V 信号量,通常用于进程同步(第二种类型)。两者不能保证可互换,虽然非常相似,但使用不同的函数调用。
荷兰计算机科学家 Dijkstra 首先提出了信号量的概念。信号量是一种特殊类型的变量,可以递增或递减,但对该变量的关键访问保证是原子性的,即使在多线程程序中也是如此。这意味着,如果程序中的两个 (或多个) 线程试图更改一个信号量的值,系统将确保所有操作实际上按顺序发生。对于普通变量,来自同一程序中不同线程的冲突操作的结果是未定义的。
接下来我们将研究最简单的信号量类型,即只接受 0 或 1 值的二进制信号量。还有一种更通用的信号量,一种计数信号量,它接受更大范围的值。通常,信号量用于保护一段代码,以便在任何时候只有一个执行线程可以运行它。对于这项工作,需要一个二进制信号量。有时,你希望允许有限数量的线程执行给定的代码段,为此,你可以使用计数信号量。因为计数信号量不太常见,所以我们在这里不再进一步考虑它们,只是说它们只是二进制信号量的逻辑扩展,而且实际所需的函数调用是相同的。
信号量函数不像大多数特定于线程的函数那样以 pthread_ 开头,而是以 sem_ 开头。线程中使用四个基本信号量函数。它们都很简单。
用 sem_init 函数创建一个信号量,它的声明如下:

这个函数初始化 sem 指向的信号量对象,设置其共享选项 (稍后将详细讨论),并给它一个初始整数值。pshared 参数控制信号量的类型。如果 pshared 值为 0,则该信号量是当前进程的本地信号。否则,信号量可能在进程之间共享。这里我们只对进程之间不共享的信号量感兴趣。(由于版本问题,为pshared 传递非零值可能将导致调用失败)
下一对函数控制信号量的值,声明如下:

它们都接受一个指向通过调用 sem_init 初始化的信号量对象的指针。
sem_post 函数将信号量的值原子地增加 1。Atomically 这里的意思是,如果两个线程同时试图将单个信号量的值增加 1,它们不会相互干扰,而不像两个程序同时向文件读取、增加和写入一个值时可能发生的情况。如果两个程序都试图将值增加 1,那么信号量的值将始终正确地增加 2。
sem_wait 函数会自动地将信号量的值减 1,但总是先等待信号量的计数非零。因此,如果在值为2的信号量上调用 sem_wait,线程将继续执行,但信号量将减少到1。如果在值为 0 的信号量上调用 sem_wait,则该函数将一直等待,直到其他线程将该值递增,使其不再为 0。如果两个线程都在 sem_wait 中等待同一个信号量变为非零,并且该信号量被第三个进程增加了一次,那么两个等待进程中只有一个进程可以减少信号量并继续;另一个将继续等待。在单个函数中这种原子的“测试和设置”能力使信号量如此有价值。
还有另一个信号量函数 sem_trywait,它是 sem_wait 的非阻塞伙伴。我们在这里不再深入讨论。我们可以在手册中找到更多的细节。
最后一个信号量函数是 sem_destroy。这个函数在处理完信号量后对信号量进行整理。声明如下:

同样,这个函数接受一个指向信号量的指针,并整理它可能拥有的任何资源。如果试图销毁某个线程正在等待的信号量,将会得到一个错误。
与大多数 Linux 函数一样,这些函数在成功时都返回 0。
(1)A Thread Semaphore(thread3.c)
这段代码 thread3 .c 也是基于 thread1.c 的。不过也改变了很多东西。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<pthread.h>
#include<semaphore.h>
void *thread_function(void *arg);
sem_t bin_sem;
#define WORK_SIZE 1024
char work_area[WORK_SIZE];
int main()
{
int res;
pthread_t a_thread;
void *thread_result;
res=sem_init(&bin_sem,0,0);
if(res!=0){
perror("Semaphore initialization failed");
exit(EXIT_FAILURE);
}
res=pthread_create(&a_thread,NULL,thread_function,NULL);
if(res!=0){
perror("Semaphore initialization failed");
exit(EXIT_FAILURE);
}
printf("\nWaiting for thread to finish...\n");
res=pthread_join(a_thread,&thread_result);
if(res!=0){
perror("Thread join failed");
exit(EXIT_FAILURE);
}
printf("Thread joined\n");
sem_destory(&bin_sem);
exit(EXIT_SUCCESS);
}
void *thread_function(void *arg){
sem_wait(&bin_sem);
while(strncmp("end",work_area,3)!=0){
printf("You input %d characters\n",strlen(work_area)-1);
sem_wait(&bin_sem);
}
pthread_exit(NULL);
}
第一个重要的变化是包含了 semaphore.h 提供对信号量函数的访问。然后在创建新线程之前声明一个信号量和一些变量并初始化信号量。

注意,信号量的初始值被设置为0。
在 main 函数中,启动新线程后,从键盘读取一些文本,加载工作区域,然后用 sem_post 增加信号量。

在新线程中,等待信号量,然后从输入中计数字符。

在设置了信号量之后,你将等待键盘输入。当有一些输入时,释放信号量,允许第二个线程在第一个线程再次读取键盘之前计数字符。
同样,两个线程共享相同的 work_area 数组。同样,我们省略了一些错误检查,比如 sem_wait 的返回,以使代码示例更简洁,更容易理解。然而,在生产代码中,你应该总是检查错误返回,除非有很好的理由忽略此检查。
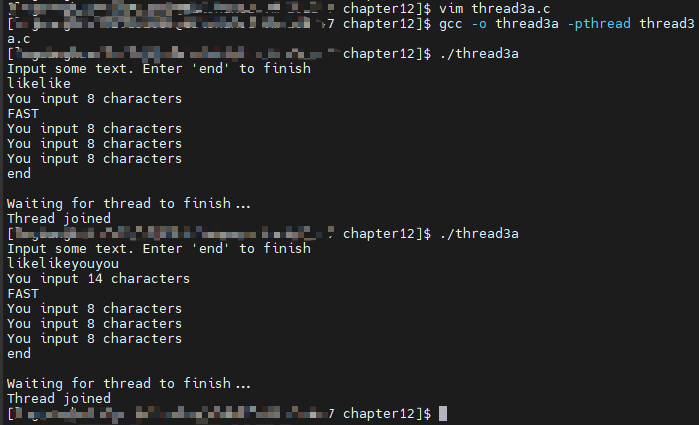
运行这个程序:
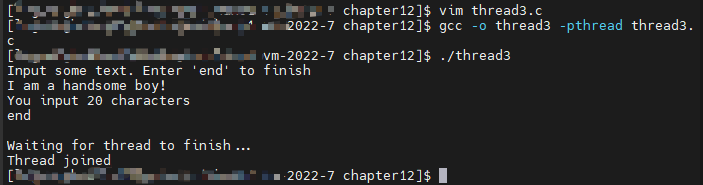
在线程程序中,计时错误总是很难发现,但该程序似乎对快速输入文本和更悠闲的停顿都有弹性。
How It Works:
初始化信号量时,将其值设置为 0。因此,当线程的函数启动时,对 sem_wait 的调用会阻塞,并等待信号量变为非零。
在主线程中,等待直到有一些文本,然后用 sem_post 增加信号量,这立即允许另一个线程从它的 sem_wait 返回并开始执行。计算完字符后,它再次调用 sem_wait 并被阻塞,直到主线程再次调用 sem_post 以增加信号量。
人们很容易忽视导致细微错误的细微设计错误。让我们将程序稍微修改为 thread3a.c,假设键盘输入的文本有时会被自动可用的文本所取代。将 main 中的读取循环修改为:
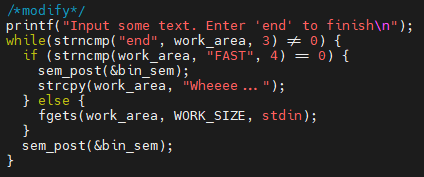
现在,如果你键入 FAST,该程序将调用 sem_post 来允许字符计数器运行,但会立即用不同的内容更新 work_area。
问题是,程序依赖于程序的文本输入,它花了很长时间,以至于在主线程准备好给它更多的单词来计数之前,其他线程有时间来计算单词。当你试着给它两组不同的单词来快速连续计数(从键盘的FAST然后Wheeee…自动地),没有时间执行第二个线程。然而,信号量已经被增加了不止一次,所以计数器线程只是继续计算单词和减少信号量,直到它再次变为零。
这说明了在多线程程序中需要多么小心地考虑计时问题。可以通过使用一个额外的信号量来修复程序,让主线程等待计数器线程有机会完成它的计数,但更简单的方法是使用互斥锁,我们接下来将讨论它。
2、Synchronization with Mutexes(使用互斥锁进行同步)
在多线程程序中同步访问的另一种方法是使用互斥锁,它的作用是允许程序员 “锁定” 一个对象,以便只有一个线程可以访问它。要控制对代码关键部分的访问,可以在进入代码部分之前锁定互斥锁,然后在完成后解锁互斥锁。
使用互斥锁所需的基本函数与信号量所需的函数非常相似。声明如下:

和往常一样,成功时返回 0,失败时返回错误代码,但没有设置 errno,你必须使用返回代码。
与信号量一样,它们都接受一个指向前面声明的对象的指针,在本例中是 pthread_mutex_t。额外的属性参数 pthread_mutex_init 允许为互斥锁提供属性,这些属性控制互斥锁的行为。默认情况下,属性类型是 “fast”。这有一个轻微的缺点,如果你的程序试图在它已经锁定的互斥锁上调用 pthread_mutex_lock,程序将会阻塞。因为持有锁的线程就是现在被阻塞的线程,互斥锁永远不能被解锁,程序就陷入了死锁。可以修改互斥锁的属性,这样互斥锁可以检查并返回错误,也可以递归地执行操作,如果之后有相同数量的解锁,则允许同一个线程进行多个锁定。
设置互斥锁的属性超出了我的能力范围,因此我们将属性指针传递NULL并使用默认行为。通过阅读pthread_mutex_init 的手册页,我们可以找到关于更改属性的更多信息。
(1)A Thread Mutex(thread1.c)
同样,这是对原始 thread1.c 的修改,但修改很大。这一次,将特别注意对关键变量的访问,并使用互斥锁以确保在任何时候只有一个线程访问这些变量。为了使示例代码易于阅读,我们省略了对互斥锁和解锁返回的一些错误检查。在生产代码中,我们将检查这些返回值。下面是新程序thread4.c:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
#include <semaphore.h>
void *thread_function(void *arg);
pthread_mutex_t work_mutex; /* protects both work_area and time_to_exit */
#define WORK_SIZE 1024
char work_area[WORK_SIZE];
int time_to_exit = 0;
int main() {
int res;
pthread_t a_thread;
void *thread_result;
res = pthread_mutex_init(&work_mutex, NULL);
if (res != 0) {
perror("Mutex initialization failed");
exit(EXIT_FAILURE);
}
res = pthread_create(&a_thread, NULL, thread_function, NULL);
if (res != 0) {
perror("Thread creation failed");
exit(EXIT_FAILURE);
}
pthread_mutex_lock(&work_mutex);
printf("Input some text. Enter 'end' to finish\n");
while(!time_to_exit) {
fgets(work_area, WORK_SIZE, stdin);
pthread_mutex_unlock(&work_mutex);
while(1) {
pthread_mutex_lock(&work_mutex);
if (work_area[0] != '\0') {
pthread_mutex_unlock(&work_mutex);
sleep(1);
}
else {
break;
}
}
}
pthread_mutex_unlock(&work_mutex);
printf("\nWaiting for thread to finish...\n");
res = pthread_join(a_thread, &thread_result);
if (res != 0) {
perror("Thread join failed");
exit(EXIT_FAILURE);
}
printf("Thread joined\n");
pthread_mutex_destroy(&work_mutex);
exit(EXIT_SUCCESS);
}
void *thread_function(void *arg) {
sleep(1);
pthread_mutex_lock(&work_mutex);
while(strncmp("end", work_area, 3) != 0) {
printf("You input %d characters\n", strlen(work_area) -1);
work_area[0] = '\0';
pthread_mutex_unlock(&work_mutex);
sleep(1);
pthread_mutex_lock(&work_mutex);
while (work_area[0] == '\0' ) {
pthread_mutex_unlock(&work_mutex);
sleep(1);
pthread_mutex_lock(&work_mutex);
}
}
time_to_exit = 1;
work_area[0] = '\0';
pthread_mutex_unlock(&work_mutex);
pthread_exit(0);
}
How It Works:
你首先声明一个互斥锁,你的工作区域,这一次,一个额外的变量:time_to_exit。

然后初始化互斥锁:

接下来启动新线程,下面是在线程函数中执行的代码:

首先,新线程尝试锁定互斥锁。如果它已经被锁定,调用将阻塞,直到它被释放。一旦你获得了访问权限,你就要检查是否有人要求你退出。如果你被要求退出,只需设置 time_to_exit, zap 工作区域的第一个字符,然后退出。
如果不想退出,请数一数字符,然后将第一个字符转换为空。你使用第一个字符为空来告诉读取程序您已经完成了计数。然后解锁互斥锁并等待主线程运行。定期尝试锁定互斥锁,成功后检查主线程是否给了你更多的工作要做。如果没有,就解锁互斥锁,然后再等待一段时间。如果有,则计算字符数并再次循环。
以下是主线(main thread):
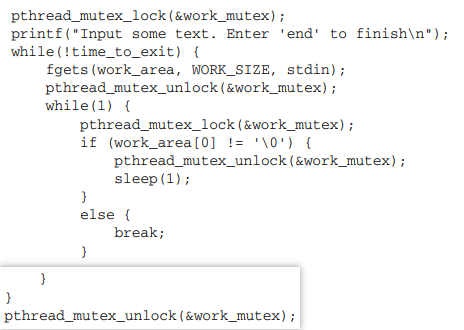
这是非常相似的。我们可以锁定工作区域,以便向其中读取文本,然后解锁它,以便允许其他线程访问来统计单词。定期重新锁定互斥锁,检查单词是否已被计数 ( work_area[0] 设置为空),如果需要等待更长时间,则释放互斥锁。正如我们前面提到的,这种轮询答案的方法通常不是很好的编程实践,在现实世界中,我们可能会使用信号量来避免这种情况。然而,该代码作为使用互斥锁的示例实现了其目的。
以上,POSIX线程(一)
祝好


![[附源码]Python计算机毕业设计SSM临港新片区招商引资项目管理系统的设计与实现(程序+LW)](https://img-blog.csdnimg.cn/04b74db8709f4e3c9ee49536cb8557b4.png)