前言
最近学习一些深度学习知识,观看了李沐老师的《动手学深度学习》的视频
练习一下 实战Kaggle比赛:预测房价
巩固一下 前面学习的知识, 不coding一下总感觉什么也没学
陆陆续续调了一天 记录一下
导包
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
import matplotlib.pyplot as plt
from torch.nn import functional as F
from torch.utils import data
from tqdm import tqdm
数据处理
数据处理这块 我总是出错 写法也不是很优雅 主要py还是不太熟
#pd读一下数据
train_data = pd.read_csv('/kaggle/input/california-house-prices/train.csv')
test_data = pd.read_csv('/kaggle/input/california-house-prices/test.csv')
train_data.shape,test_data.shape
注意不要把target 也标准化了,第一次处理时没注意直接把y合并到all_features中了,导致target值也标准化了导致rmse时 全部变为1 出现了nan
# 先把y target 分离出来
y = train_data['Sold Price']
train_data = train_data.drop(['Sold Price'],axis=1)
all_features = train_data.iloc[:,1:]
test_features = test_data.iloc[:,1:]
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
features = list(numeric_features)
# 加上类别数相对较少的Type 这个特征选择是借鉴别的文章
#这2个特征做one-hot的话 不同项比较小 不会报内存 目前特征工程不太会
features.extend(['Type','Bedrooms'])
# 看一下 形状是否正确
all_features.shape,test_features.shape
((47439, 39), (31626, 39))
# 对训练和测试数据做标准化 然后缺失值补0
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x:(x - x.mean()) / (x.std()))
all_features[numeric_features] = all_features[numeric_features].fillna(0)
all_features = pd.get_dummies(all_features[features],dummy_na=True)
test_features[numeric_features] = test_features[numeric_features].apply(
lambda x:(x - x.mean()) / (x.std()))
test_features[numeric_features] = test_features[numeric_features].fillna(0)
test_features = pd.get_dummies(test_features[features],dummy_na=True)
看一下特征数 这里发现测试集的特征数 少一些 可以直接减少一些特性
all_features.shape,test_features.shape
((47439, 442), (31626, 196))
final_test, final_train = test_features.align(all_features,
join='left', axis=1)
test_features = final_test
all_features = final_train
all_features = all_features.fillna(0)
final_train.shape, final_test.shape
((47439, 196), (31626, 196))
把训练数据切割 成 训练和验证集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test= train_test_split(in_features,y, test_size=0.2,
random_state=1)
X_train.shape,y_train.shape,in_features.shape,test_features.shape
((37951, 196), (37951,), (47439, 196), (31626, 196))
# 把数据类型转成tensor
X_train = torch.tensor(X_train.values, dtype=torch.float32)
y_train = torch.tensor(y_train.values, dtype=torch.float32)
X_test = torch.tensor(X_test.values, dtype=torch.float32)
y_test = torch.tensor(y_test.values, dtype=torch.float32)
test_data_t = torch.tensor(test_features.values, dtype=torch.float32)
模型建立
简单感知机模型
class MLP(nn.Module):
def __init__(self,in_features):
super().__init__()
self.layer1 = nn.Linear(in_features,256)
self.layer2 = nn.Linear(256,64)
self.out = nn.Linear(64,1)
def forward(self,X):
X = F.relu(self.layer1(X))
X = F.relu(self.layer2(X))
return self.out(X)
net = MLP(X_train.shape[1])
损失函数 mes均方损失, 这里用rmse 李沐老师有讲 取对数比较好优化 房价的波动比较大
loss = nn.MSELoss()
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()
训练函数
这里跟老师的代码差不多
def load_array(data_array,batch_size,is_Train=True):
dataset = data.TensorDataset(*data_array)
return data.DataLoader(dataset,batch_size,shuffle=is_Train)
def train(net,train_features,train_labels,test_features,test_labels,
nums_epochs,lr,weight_decay,batch_size):
train_ls,test_ls = [],[]
train_iter = load_array((train_features,train_labels),batch_size)
optimizer = torch.optim.Adam(net.parameters(),
lr = lr,
weight_decay = weight_decay)
for epoch in tqdm(range(num_epochs)):
for X, y in train_iter:
# X,y = X.to(device),y.to(device)
optimizer.zero_grad()
l = loss(net(X),y)
l.backward()
optimizer.step()
record_loss = log_rmse(net,train_features,train_labels)
# record_loss = loss(net(train_features),train_labels)
print({'loss': record_loss,'epoch': epoch})
train_ls.append(record_loss)
if test_labels is not None:
record_loss_t = log_rmse(net,test_features,test_labels)
test_ls.append(record_loss_t)
print({'test loss': record_loss_t,'epoch': epoch})
return train_ls,test_ls
这里直接训练了 没有做k折交叉验证 感觉数据量很大 做k折交叉验证提升不是很明显
参数设置
num_epochs, lr, weight_decay, batch_size = 500, 1e-3, 0.05, 256
print("network:",net)
train_ls, valid_ls = train(net, X_train,y_train,X_test,y_test,
num_epochs, lr, weight_decay, batch_size)
这里最后的loss 并不是很理想 验证集一直下不去
训练的loss 能到0.3-0.29 验证一直在1以上
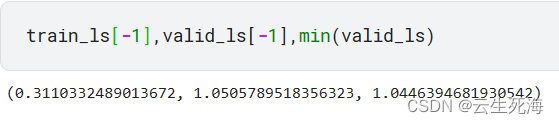
测试结果
搞了一天没啥大优化 就这样吧
preds = net(test_data_t).detach().numpy()
# 将其重新格式化以导出到Kaggle
test_data['Sold Price'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['Sold Price']], axis=1)
submission.to_csv('submission.csv', index=False)
最后结果能到0.44 感觉还可以
跟验证集的结果差的有点多 不知道是哪里的问题 可能是删去了只有测试集里的部分特征导致

总结
第一次这么正式写代码,把前面学习的知识复习了一下,之前感觉一些知识很模式,没怎么用过不太了解,总算实践了一下,但是plt这个画图工具还是不太熟悉,希望之后可以掌握一下,画图可能观察起来更直观。





![[笔记]Python计算机视觉编程《一》 基本的图像操作和处理](https://img-blog.csdnimg.cn/edfadadc826d42c3addc46b5e9403fc3.png)