1字符串的表达方式
字符串是 Python 中最常用的数据类型。我们可以使用引号 ( ' 或 " ) 来创建字符串。
字符串表达方式
a = " I ' m Tom" #一对双引号
b =’Tom said:" I am Tom" ' #一对单引号
c = ‘Tom said: " I\'m Tom" ' #转义字符
d = ' ' ' Tom said: "I'm Tom " ' ' ' # 三个单引号
e = " " " Tom said:"I'm Tom" " " "# 三个双引号
总结:
- 双引号或者单引号中的数据,就是字符串
- 如果使用一对引号来定义字符串,当出现符号冲突时,可以使用转义字符
- 使用三个单引号、双引号定义的字符串可以包裹任意文本
1.1 转义字符
在Python中具有特殊含义的字符,以 \ 开头
| 转义字符 | 描述 |
| \(在行尾时) | 续行符 |
| \\ | 代表一个反斜线字符\ |
| \' | 单引号,用来显示一个单引号 |
| \'' | 双引号,用来显示一个双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行,将当前位置移到下一行开头 |
| \v | 纵向制表符 |
| \t | 横向制表符,用来表示一个制表符 |
| \r | 回车,将当前位置移到本行开头 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
2 字符串的运算
在python中,字符串可以使用以下运算符:
+
*
in
not in
is
is not
==
!=
可以使用*运算符来实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可以使用in和not in来判断一个字符串是否包含另外一个字符串,我们也可以用[]和[:]运算符从字符串取出某个字符或某些字符。
2.1 使用+和*运算符实现字符串的拼接和重复操作。
s1 = 'hello' + ' ' +'world'
print(s1) #结果 hello world
s2 = '!' * 3
print(s2)#结果 !!!
s1 += s2 #s1 = s1 + s2
print(s1) # 结果:hello world!!!
s1 *= 2 #s1 = s1 * 2
print(s1) #结果:hello world!!!hello world!!!2.2 比较运算,比较两个字符串的相等性或大小
字符串在计算机内存中也是以二进制形式存在的
字符串的比较其实比的的是:每个字符对应的编码的大小
例如A的编码是65,而a的编码是97,所有'A' < 'a'的结果相当于就是65 < 97的结果,结果为True。
'boy' < 'bad',因为第一个字符都是'b' 比不出大小,所以实际比较的是第二个字符的大小。因为'o' < 'a'的结果是False,所以'boy' < 'bad'的结果也是False。
如果不清楚两个字符对应的编码是多少,可以使用ord函数来获得。
例如ord('A')的值是65,而ord('黄')的值是40644
s1 = 'how are you'
s2 = 'I am fine'
print(s1 == s2) # false
print(s1 > s2) #True
print(s2 == 'I am fine') #True
print(s2 == 'i am fine') # False
print(s2 != 'i am fine') # True
s3 = '黄一'
print(ord('黄'),ord('一')) # 40644 19968
s4 = '李三五'
print(ord('李'),ord('三'),ord('五')) #26446 19977 20116
print(s3 > s4,s3 <= s4) #True False注意:字符串的比较运算比较的是字符串的内容,python中还有一个is运算符(身份运算符),如果用is来比较两个字符串,它比较的是两个变量对应的字符串是否在内存中相同的位置(内存地址),简单的说就是两个变量是否对应内存中的同一个字符串。
s1 = 'hello world'
s2 = 'hello world1'
s3 = s2
#比较字符串的内容
print(s1 == s2,s2 == s3) #False True
#比较字符串的内存地址
print(s1 is s2,s2 is s3) # False True总结:s1 == s2比较的是字符串里面的内容,只要内容相同结果就是True,不同就是False;而s1 is s2则比较的是内存地址,两者内存是不一样的所以False。
2.3 成员运算
用in 和not in判断一个字符串中是否存在另外一个字符或字符串
in 和not in运算通常称为成员运算,会产生布尔值True或False
s1 = 'hello world'
print('he' in s1) # True
s2 = 'sensitive'
print(s2 in s1) #False2.4 获取字符串长度
获取字符串长度使用内置函数len
s = 'hello, world'
print(len(s)) # 12
print(len('sensitive')) # 93 字符串的下标和切片
3.1 下标/索引
“下标”又叫“索引”,就是编号,就好比学校里,每个学生的学号,通过这个学号就能找到相应的学生的基本信息。
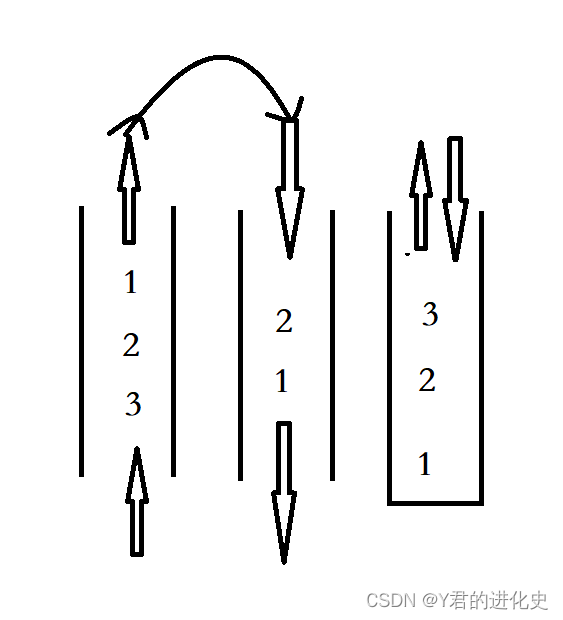
如果有字符串:name = ’abcdef‘,在内存中的实际存储如下:
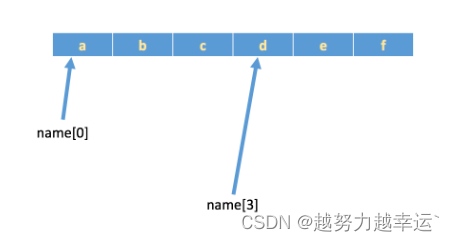
如果想取出部分字符,那么可以通过下标的方法。(在计算机中,下标从0开始)
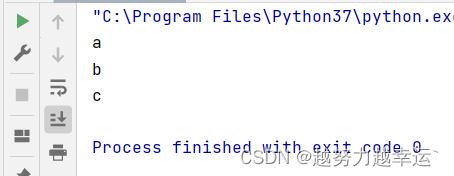
name = 'abcdef'
print(name[0])
print(name[1])
print(name[2])运行结果:
以name = 'abcdef'为例,要把e取出来,该怎么取?
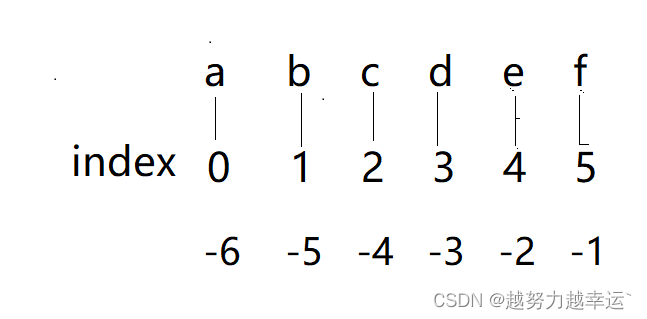
从上图可以看出,e对应的索引是4
print(name[4]) #取字母e取name = 'abcdef' 最后一个字母?
print(name[5]) # f
print(name[-1]) # f
字符串索引机制:
1、 0~len(name) -1
2、-len(name) ~ -1
3.2 字符串切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长],也可以简化使用[起始:步长]
注意:选取的区间从“起始”位开始,到“结束”位的前一位结束(不包含结束位本身),步长表示选取间隔。
#索引是通过下标取某一个元素
#切片是通过下标取某一段元素
#格式:字符串变量[start:end]
#字符串变量[start : end : step] 默认是从左向右一个一个取元素
#step:
# 1.步长
# 2.方向 step为正数时,从左向右取数
step为负数时,从右向左取数
s = 'Hello world'
print(s)
print(s[4]) # o字符串里的第4个元素
print(s[3:7]) # lo w 包含下标3,不含下标7
print(s[:]) # Hello world取出所有元素(没有起始和结束位之分),默认步长为1
print(s[1:]) # ello world从下标为1开始,取出 后面所有的元素(没有结束位)
print(s[:4]) # Hell 从起始位置开始,取到 下标为4的前一个元素(不包括结束位本身)
print(s[:-1]) # Hello worl 从起始位置开始,取到 倒数第一个元素(不包括结束位本身)
print(s[-4:-1]) # orl 从倒数第4个元素开始,取到 倒数第1个元素(不包括结束位本身)
print(s[1:5:2]) # el 从下标为1开始,取到下标为5的前一个元素,步长为2(不包括结束位本身)
print(s[7:2:-1]) # ow ol 从下标为7的元素开始(包含下标为7的元素),倒着取到下标为2的元素(不包括下标为2的元素)
# python 字符串快速逆置w
print(s[::-1]) # dlrow olleH 从后向前,按步长为1进行取值4 字符串的常见操作
字符串的常见操作包括
| 获取长度 | len |
| 查找内容 | find,index,rfind,rindex |
| 判断 | startswith,endswith,isalpha,isdigit,isalnum,isspace |
| 计算出现次数 | count |
| 替换内容 | replace |
| 切割字符串 | split,rsplit,splitlines,partition,rpartition |
| 修改大小写 | capitalize,title,upper,lower |
| 空格处理 | ljust,rjust,center,lstrip,rstrip,strip |
| 字符串拼接 | join |
注意:在python中,字符串是不可变的!所有的字符串相关方法,都不会改变原有的字符串,都是返回一个结果,在这个新的返回值里,保留了执行后的结果!
4.1 len函数
len函数可以获取字符串的长度。
mystr = '你最近过得好嘛!我过的超级好丫!!!'
print(len(mystr)) # 获取字符串的长度为184.2 查找
4.2.1 find
find:从左向右查找,只要遇到一个符合要求的则返回位置,如果没有找到任何符合要求的则返回 -1
#取出e564de54s4e5496sed4f98e46as4f648.gif
path = 'https://www.baidu.com/img/dong_e564de54s4e5496sed4f98e46as4f648.gif'
i = path.find('_')
print(i) #打印下划线所在的位置
image_name = path[i+1:]
print(image_name)
i = path. Find('#')
print(i)运行结果:

4.2.2 rfind
rfind从右向左查找,只要遇到一个符合要求的则返回位置,如果没有找到任何符合要求的则返回-1
#rfind
#快速取出.gif
path = 'https://www.baidu.com/img/dong_e564de54s4e5496sed4f98e46as4f648.gif'
i = path.rfind('.')
zhui = path[i:]
print(zhui)4.2.3 count
count:统计指定字符的个数
'''
查找字符串中有几'.'
'''
path = 'https://www.baidu.com/img/dong_e564de54s4e5496sed4f98e46as4f648.gif'
n = path. Count('.')
print(n)4.2.4 index
index与find的区别:index也表示查找,但是如果找不到会报错
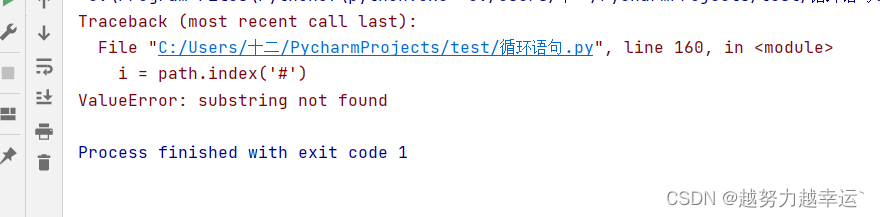
path = 'https://www.baidu.com/img/dong_e564de54s4e5496sed4f98e46as4f648.gif'
i = path. Index('#')
print(i)运行结果
4.2.5 rindex
类似于index(),不过是从右边开始。如果找不到则会报错
4.3 判断
可以通过字符串的startswith、endswith来判断字符串是否以某个字符串开头和结尾;
还可以用is开头的方法判断字符串的特征,这些方法都返回布尔值。
1.startswith():判断字符串是否以指定的字符串开头,返回布尔值结果
2.endswith():判断字符串是否以指定的字符串结尾,返回布尔值结果
3.isdigit():判断字符串是否由数字构成,返回布尔值结果
4.isalpha():判断字符串是否以字母构成,返回布尔值结果
5.isalnum():判断字符串是否以数字和字母构成,返回布尔值结果
6.isspace():判断字符串里是否只包含空格,返回布尔值结果
7.isupper():判断是否全部都是大写字母,返回布尔值结果
8.islower():判断是否全部都是小写字母,返回布尔值结果
s1 = 'hello world!'
#startswith方法检查字符串是否以指定的字符串开头返回布尔值
print(s1.startswith('He')) #False
print(s1.startswith('hel')) #True
#endswith方法检查字符串是否以指定的字符串结尾返回布尔值
print(s1.endswith('!'))
s2 = 'abc123456'
#isdigit方法检查字符串是否由数字构成返回布尔值
print(s2.isdigit()) #False
#isalpha方法检查字符串是否以字母构成返回布尔值
print(s2.isalpha()) #False
#isalnum方法检查字符串是否以数字和字母构成返回布尔值
print(s2.isalnum()) # True
#isspace方法判断字符串里是否只包含空格
s3 = ''
print(s3.isspace()) #False s3是一个空字符串
s4 = ' '
print(s4.isspace()) #True 只有空格
s5 = ' d'
print(s5.isspace()) # False 除了空格还有其他内容
#isupper方法判断字符串是否全部都是大写字母
s6 = 'HELII'
result = s6.isupper() # 判断是否全部都是大写字母
print(result) #True
#islower判断是否全部都是小写字母
s7 = 'hello'
r = s7.islower()
print(r) #True模拟文件上传
'''
模拟文件上传,键盘输入上传文件的名称(abc.jpg),判断文件名(abc)是否大于6位以上,扩展名是否:jpg,gif,png格式
如果不是则提示上传失败,如果名字不满足条件,而扩展名满足条件则随机生成一个6位数组成的文件名,打印成功上传xxxxx.png
判断名字
'''
import random
file = input('输入图片文件全称:')
#判断扩展名
if file.endswith('jpg') or file.endswith('gif') or file.endswith('png'):
#判断文件的名字
i = file.rfind('.')
name = file[:i]
#len(name)
if len(name)<6:
#重新构建名字,产生字母和数字的组合名称
filename = ''
s = 'shSAHFWEOGHOAAEFAaoehagagh324564faljfeaeawehfiaghsajfioe123456789'
for a in range(6):
index = random.randint(0,len(s)-1) # 随机产生下标
filename += s[index] #获取下标匹配的字母
#filename 文件名 和后缀进行拼接
file = filename + file[i:]
#完整的文件全称名字
print('成功上传%s文件' %file)
else:
print('文件格式错误,上传失败!')运行结果
简单登录验证
需求:
admin123 15811119999 200325 用户名或者手机号码登录 + 密码: 用户名:全部小写,首字母不能是数字,长度必须6位以上 手机号码:纯数字 长度11位 密码必须是6位数字 以上条件符合则进入下层验证: 判断用户名+密码 是否是正确的,正确则成功,否则登录失败
flag = True
while flag:
name = input('用户名/手机号码:')
#判断
if (name.islower() and not name[0].isdigit() and len(name) >= 6) or (name.isdigit() and len(name) == 11):
# 继续输入密码,密码输入错误允许多次输入
while True:
password = input('密码:')
#判断是否是6位数字
if len(password) == 6 and password.isdigit():
#验证name + 密码,正确性
if (name == 'admin123' or name == '15811119999') and password=='200325':
print('用户登录成功!')
flag = False
break
else:
print('用户名或者密码有误!')
break
else:
print('密码必须是6位数字')
else:
print('用户名或手机号码格式错误!')
4.4 替换
替换内容replace(old,new,count) 默认全部替换,也可以通过count指定次数
s = '王五你好,张三李四可以进去吗?张三李四可以进去吗?'
result = s.replace('张三李四','****',1)
result2 = s.replace('张三李四','****')
print(result)
print(result2)运行结果

4.5 切割
4.5.1 split
以指定字符串为分隔符切片,如果 maxsplit有指定值,则仅分隔 maxsplit+1 个子字符串。返回的结果是一个列表。
mystr = '今天天气好晴朗,处处好风光呀好风光'
result = mystr.split() # 没有指定分隔符,默认使用空格,换行等空白字符进行分隔
print(result) #['今天天气好晴朗,处处好风光呀好风光'] 没有空白字符,所以,字符串未被分隔
result = mystr.split('好') # 以 '好' 为分隔符
print(result) # ['今天天气', '晴朗,处处','风光呀,'风光']
result = mystr.split("好",2) # 以 '好' 为分隔符,最多切割成3份
print(result) # ['今天天气', '晴朗,处处', '风光呀好风光']4.5.2 rsplit
用法和splti基本一致,只不过是从右往左分隔
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.rsplit('好',1)) #['今天天气好晴朗,处处好风光呀', '风光']4.5.3 splitlines
按照行分隔,返回一个包含各行作为元素的列表。
mystr = 'hello \nworld'
print(mystr.splitlines())4.5.4 partition
把mystr以str分割成三部分,str前,str和str后,三部分组成一个元组
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.partition('好')) # ('今天天气', '好', '晴朗,处处好风光呀好风光')4.5.5 rpartition
类似于 partition()函数,不过是从右边开始.
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.rpartition('好')) # ('今天天气好晴朗,处处好风光呀', '好', '风光')4.6 修改大小写
修改大小写的功能只对英文有效,主要包括,首字母大写capitalize,每个单词的首字母大写title,全小写lower,全大写upper。
4.6.1 capitalize
第一个单词的首字母大写
mystr = 'hello world'
print(mystr.capitalize()) # Hello world4.6.2 title
每个单词的首字母大写
mystr = 'hello world'
print(mystr.title()) # Hello World4.6.3 lower
所有都变成小写
mystr = 'hElLo WorLD'
print(mystr.lower()) # hello world4.6.4 upper
所有都变成大写
mystr = 'hello world'
print(mystr.upper()) #HELLO WORLD4.7 空格处理
4.7.1 ljust
返回指定长度的字符串,并在右侧使用空白字符补全(左对齐)
str = 'hello'
print(str.ljust(10)) # hello 在右边补了五个空格4.7.2 rjust
返回指定长度的字符串,并在左侧使用空白字符补全(右对齐)
str = 'hello'
print(str.rjust(10)) # hello在左边补了五个空格4.7.3 center
返回指定长度的字符串,并在两端使用空白字符串补全(居中对齐)
str = 'hello'
print(str.center(10)) # hello 两端加空格,让内容居中4.7.4 strip
strip删除两端的空白字符
s = ' helloworld@qq.com \t\r\n'
#strip方法获得字符串修剪左右两侧空格之后的字符串
print(s.strip()) # helloworld@qq.com4.7.5 lstrip
lstrip删除左边的空白字符
s = ' he llo '
print(s.lstrip())#he llo
4.7.6 rstrip
rstrip删除右边的空白字符
s = ' he llo '
print(s.rstrip()) # he llo
4.8 拼接
字符串拼接 mystr .join(iterable)
把参数进行遍历,取出参数里的每一项,然后再在后面加上mystr
mystr = 'a'
print(mystr.join('hxmdq')) #haxamadaq 把hxmd一个个取出,并在后面添加字符a. 最后的 q 保留,没有加 a
print(mystr.join(['hi','hello','good'])) #hiahelloagood作用:可以把列表或者元组快速的转变成为字符串,并且以指定的字符分隔
txt = '_'
print(txt.join(['hi','hello','good'])) #hi_hello_good
print(txt.join(('good','hi','hello'))) #good_hi_hello