MapReduce
MapReduce分布式处理技术、分布式的文件系统GFS、结构化的BigTable存储系统是Google的三个核心技术。
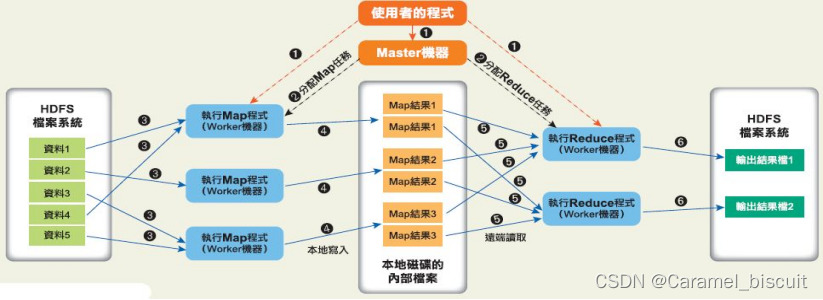
Map-Reduce:用于大规模数据集的并行计算。
(分而治之)将要执行的问题拆解成Map(映射)和Reduce(化简)的方式,先通过Map程序将数据切割成不相关的区块,分配给大量计算机处理达到分布运算的效果,再通过Reduce程序将结果汇整,输出开发者需要的结果。
MapReduce分布式处理技术——Map端
map: (k1, v1) → list(k2, v2)
- 输入:键值对(k1,v1)表示的数据
- 处理:文档数据记录将以“键值对”形式传入map函数;map将处理这些键值对,并以另一种键值对形式输出处理的一组键值对中间结果list(k2,v2)。
- 输出:键值对(k2, v2)表示的一组中间数据
- 备注: list(k2, v2) 表示有一个或多个键值对组成的列表
各个map函数对所划分的数据并行处理,从不同的输入数据产生不同的中间结果输出。
各个reduce各自并行计算,各自负责处理不同的中间结果数据集合;
进行reduce之前,须等到所有的map函数做完,并且在进入reduce前会对map的中间结果数据进行整理(Shuffle),保证将map的结果发送给对应的reduce。
最终汇总所有reduce的输出结果即可获得最终结果。

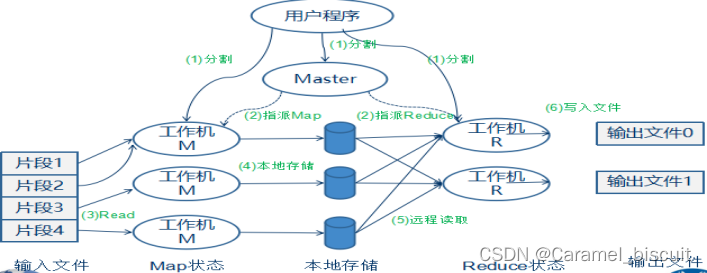
MapReduce框架由一个单独运行在主节点上的JobTracker 和运行在每个集群从节点上的TaskTracker组成。
主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前失败的任务。
Hadoop
在Google发表MapReduce后,2004年开源社群用Java搭建出一套Hadoop框架,用于实现MapReduce 算法,能够把应用程序分割成许多很小的工作单元,每个单元可以在任何集群节点上执行或重复执行。
此外,Hadoop 还提供一个分布式文件系统GFS(Google file system),支持大型、分布式大数据量的读写操作,其容错性较强。而分布式数据库(BigTable)是一个有序、稀疏、多维度的映射表,有良好的伸缩性和高可用性,用来将数据存储或部署到各个计算节点上。
在架构中MapReduce API提供Map和Reduce处理、GFS分布式文件系统和BigTable分布式数据库提供数据存取。基于Hadoop可以非常轻松和方便完成处理海量数据的分布式并行程序,并运行于大规模集群上。

数据一致性理论
CAP理论
- 强一致性(Consistency):系统在执行某项操作后仍然处于一致状态。在分布式系统中,更新操作执行成功后所有用户都应该读取到最新的值,这样的系统被认为具有强一致性。
- 可用性(Availability):每一个操作总是能够在一定的时间内返回结果。
- 分区容错性(Partition Tolerance):分区容错性可以理解为系统在存在网络分区的情况下仍然可以接受请求(满足一致性和可用性)。
CAP理论是在分布式环境中设计和部署系统时需要考虑的三个重要的系统需求。根据CAP理论,数据共享系统只能满足这三个特性中的两个,而不能同时满足三个条件。因此系统必须在这三个特性之间做出权衡。
最终一致性模型
分布式系统一般通过复制数据来提高系统的可靠性和容错性,并且将数据的不同副本存放在不同的机器上。由于维护数据副本一致性代价很高,许多系统采用弱一致性来提高性能。
不同的一致性模型:强一致性、弱一致性、最终一致性。
- 强一致性:要求无论更新操作在哪个数据副本上执行,之后所有的读操作都要获得最新的数据。对于单副本数据来说,读写操作在同一数据上执行,容易保证强一致性。对于多副本数据来说,需要使用分布式事物协议(如Paxos)。
- 弱一致性:在这种一致性下,用户读到某一操作对系统特定数据的更新需要一段时间。这段时间成为“不一致性窗口”。
- 最终一致性:是弱一致性的一种特例,在这种一致性下系统保证用户最终能够读取到某操作对系统特定数据的更新。
此种情况下,“不一致性窗口”的大小依赖于交互延迟、系统负载,以及复制技术中replica的个数(可以理解为master/slave模式中,slave的个数)。
DNS系统是在最终一致性方面最出名的系统,当更新一个域名的IP以后,根据配置策略以及缓存控制策略的不同,最终所有客户都会看见最新值。
最终一致性模型分类:
- 因果一致性(Causal Consistency):假如有相互独立的A、B、C三个进程对数据进行操作。进程A对某数据进行更新后并将该操作通知给B,那么B接下来的读操作能够读到A更新的数据值。但是由于A没有将该操作通知给C,那么系统将不保证C一定能够读取到A更新的数据。
- 读自写一致性(Read Your Own Writes Consistency):用户更新某个数据后,读取该数据时能够获取其更新后的值,而其他用户读取该数据时则不能保证读取到最新值。
- 会话一致性(Session Consistency):指读自写一致性被限制在一个会话范围内,也就是说提交更新操作的用户在同一个会话里读取该数据时能够保证数据是最新的。
- 单调读一致性(Monotonic Read Consistency):指用户读取某个数据值,后续操作不会读取到该数据更早版本的值。
- 时间轴一致性(Timeline Consistency):要求数据的所有副本以相同顺序执行所有更新操作,也称为单调写一致性(Monotonic Write Consistency)。
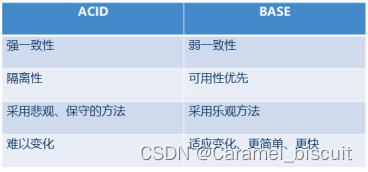
事务是用户定义的一个数据库操作序列,这些操作要么全不做,要么全做,是一个不可分割的单位,ACID是事务所具有的特性:
原子性(Atomicity):事务中的操作要么都做,要么都不做。
一致性(Consistency):系统必须始终处于强一致状态下。
隔离性(Isolation):一个事务的执行不能被其他事务所干扰。
持续性(Durability):一个已提交的事务对数据库中数据的改变是永久性的。
ACID特性是传统关系型数据库中事务管理的重要任务,也是恢复和并发控制的基本单位。
BASE方法通过牺牲一致性和孤立性来提高可用性和系统性能,其中BASE分别代表:
基本可(Basically Availability):系统基本能够运行、一直提供服务。
软状态(Soft-state):系统不要求保持强一致性。
最终一致性(Eventually consistency):系统需要在某一刻后达到一致性要求。
数据一致性实现技术
分布式系统在不同节点的数据采用什么技术保证一致性,取决于应用对系统一致性的需求,在关系型数据管理系统中一般会采用悲观的方法(如加锁),这些方法代价比较高、对系统性能影响较大,而在一些强调性能的系统中则会采用乐观的方法。
Quorum系统NWR策略
对于数据在不同副本中的一致性,此策略采用类似于Quorum系统的一致性协议实现。这个协议有三个关键值N、R、W。
N表示数据所有副本数。
R表示完成读操作所需要读取的最小副本数,即一次读操作所需参与的最小节点数目。
W表示完成写操作所需要写入的最小副本数,即一次写操作所需参与的最小节点数目。
该策略中,只需要保证R+W>N,就可以保证强一致性。
两阶段提交协议
两阶段提交协议(Two Phase Commit Protocol,2PC协议)可以保证数据的强一致性,许多分布式关系型数据库管理系统采用此协议完成分布式事务。
两阶段提交协议系统一般包含两类节点:一类为协调者,通常一个系统中只有一个;另一类为事务参与者,一般包含多个,在数据存储系统中可以理解为数据副本的个数。
时间戳策略
基于时间戳,可为每一份数据附加一个时间戳标记,在进行数据版本比较或数据同步的时候只需要比较其时间戳就可以区分它们的版本。
改进时间戳,不依赖单个机器,也不依赖物理时钟同步。该时间戳为逻辑上的时钟。
逻辑时间戳用来确定分布式系统中事件的先后关系。假设发送或接收进程中的一个事件,分布式系统中事件的先后关系可用“->”来表示,例如:若事件a发生在事件b之前,则a->b。该关系满足:
如果事件a和事件b是同一进程中的事件,并且a在b之前发生,那么a->b。
如果事件a是某消息发送方进程中的事件,事件b是该消息接收方进程中接收该消息的事件,那么a->b。
对于事件a、事件b和事件c,如果有a->b和b->c,那么a->c。
如果两个不同的事件a和事件b,既不能得出a->b也不能得出b->a,那么逻辑上认为事件a和事件b同时发生。