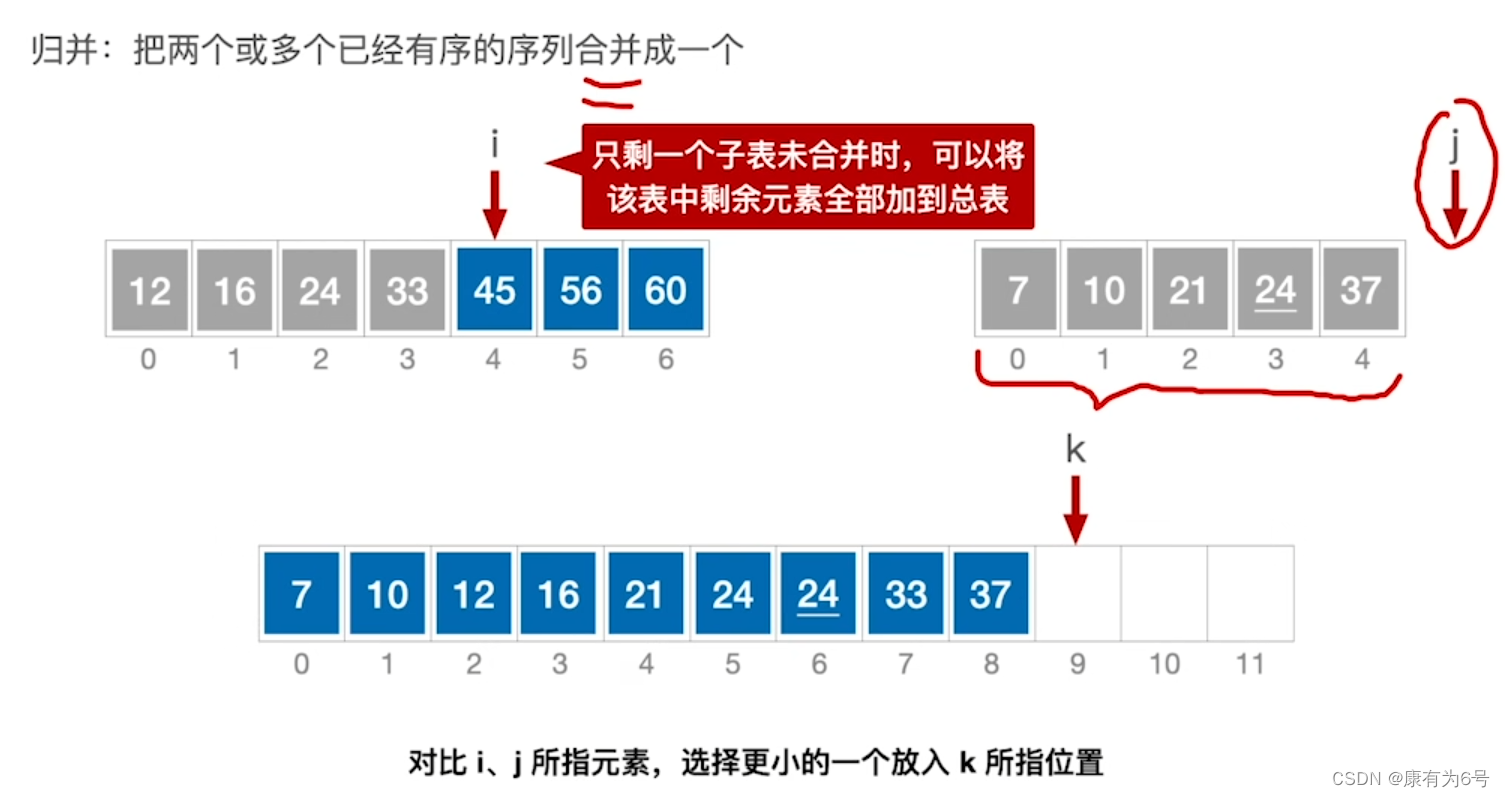
前言:即使你对文中提及的技术不大了解,你也可以毫无压力地看完这篇描述如何更好地获得 ChatGPT 生成内容的文章。因为我也是利用 Azure OpenAI 等认知服务来学习,然后就这样写出来的。所以,舒服地坐下来,慢慢看吧~
相信看到标题点进来的你,已经试过跟 ChatGPT 聊天了。我猜,要么你曾惊叹于人工智能的强大,要么,你嘲笑过这是“人工智障”……
为什么有时候 GPT 会有看着很傻的回复呢?有没有一种可能,是我们问问题的方式不对?
请和我一起确认,你提问时是否有如下几种情况:
-
是否试过在提示中提供示例?
-
是否试过使用角色扮演提问?
-
是否不让 ChatGPT 去猜猜猜?
如果你的回答是“否”,那请允许我为人工智能申个冤——是的,问对问题,人工智能会表现的更好。这也是提示工程(prompt engineering)的重要性所在。接下来,我们花点时间来搞清楚为什么问对问题很重要,以及怎样问问题更好。
微软MVP实验室研究员

胡浩
多年从事基础架构相关工作,熟悉全栈虚拟化、终端用户和边缘计算等,对多个技术方向有所涉猎。乐于学习并分享 Azure 和 AI,曾在很多大型研讨会演讲,如微软的 TechEd、MEDC、Tech Summit、Ignite,威睿的 VMworld、vForum、ENPOWER,以及苹果、戴尔等技术会议。同时也是很多社区大会如 Global AI Bootcamp、Global Azure Bootcamp、Global M365 Bootcamp 等活动的组织者和演讲者。
对话上下文
首先,ChatGPT 是可以使用上下文来持续优化语言理解和生成内容输出的。为了便于确定和理解,我选择了同源(使用相同的 API)的 Azure OpenAI 服务 [1]作为样例,因为在 Azure OpenAI Studio 里,你可以很容易地通过示例代码或 JSON 数据观察到来往你和模型之间的文本。
我们先看看使用 GPT-3 中 text-davinci-003 模型的对话样例。

GPT 这个大语言模型(LLM),从全局上下文模型 Transformer [2]发展而来,而没有使用局部上下文的传统长短期模型(LSTM [3])。上下文对模型能够准确了解提问和提供回答非常重要。因此每次通过 API 提交完成(Completion)请求的时候,我们能看到就连之前的交互文本,都被提交到了 API 接口。
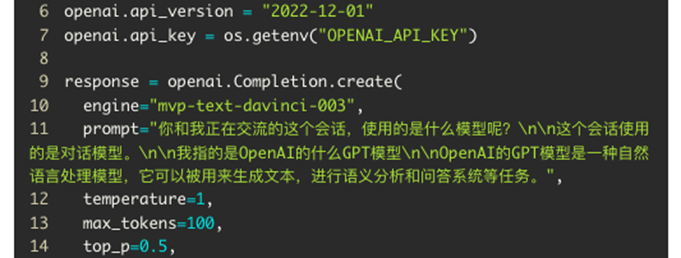
这样,GPT 就能够根据之前的对话内容,生成更加相关的回复。
也许你已经知道,和 GPT 模型交互有个重要的概念,就是 token。我自己把它理解为“语素”,即构成词语的组成部分,按照通常计算,大约4个英文字符为1个 token。我们和 GPT 的交互,就需要消耗 token 并受到 token 数量的限制。
随着 GPT-3.5 和 GPT-4 的推出,新的模型调用 API 接口从 Completion [4]逐步转向 ChatCompletion [5](GPT-3.5 可以使用 Compleition 但必须提交 ChatML,GPT-4 只支持 ChatCompletion)。新的接口要求提交的 prompt 从以往的字符串改为包含系统(system)、用户(user)和助手(assistant)三种角色消息的数组。其中系统角色消息只需要在最开始声明一次即可,后面我们也会讨论这个有趣的设定。

通过这个样例,就可以看到具体三种角色消息的表现形式。我们打开“查看代码”,就能够很方便地看到这三种角色的消息数组是如何发送到 API 接口的。

那么我们的问题就来了——即使我们使用 GPT-4 的 8K 或 32K 模型,不断地发送整个会话,token 也有用完的时候吧?那是不是意味着 GPT 就会“失忆”?
理论上是的。人类也不可能记得对话的全部信息啊~那怎么解决这个问题呢?一般人我不告诉 Ta~ 我们完全可以对之前的对话内容进行小结,然后将小结作为后续会话的开始。
你问我怎么小结对话?问 GPT 啊!
不如来一发
有几个概念伴随 LLM 的流行为更多人所知:Zero Shot、One Shot 和 Few Shot。这几个概念或许可以翻译为零样本学习、单样本学习和少样本学习。
零样本学习、单样本学习和少样本学习某种意义上有相同的好处——模型不再需要进行繁杂的训练,就可以对新的类别进行识别判断。某些方面上,这其实和我们期待的人工智能有点类似,看上去具备了举一反三的能力。在机器学习的领域里,相关的词汇有模型泛化和迁移学习等,意味着从某些类别或样例的训练中,具备了将获得的推理扩展到其他类别或样例上的能力。
考虑到监督机器学习时需要的标签,这是一项包含巨大成本(人力和经济)的工作——也许你已经听说过数据标记师和数据标记工作的传闻,更别说标签有时无法提供合适的数据进行训练,比如样本分布或样本过少导致的偏差等等。
这也许就是大模型的威力:算力的强大使得巨量的语料数据能够进行无监督学习,由此产生了对语义的概率性推断,再体现到对输入的语义理解和内容生成,不断发展的神经网络(连接派)强大之后,却发现了对“意思”(符号派)的更好识别,简直是华山气宗和剑宗的殊途同归,扯远了,后续再写一篇聊这个吧!
我们从少样本学习到零样本学习一个一个聊。开始说这几个之前,先回顾一下以往的监督学习。在如下的 ImageNet 示例中,模型就是使用不同的狗狗的照片来训练,从而提取分辨狗狗的特征,作为判断今后图片中是否存在狗狗的依据。
是的,你得为狗狗的照片提供标签,说明这些训练数据(图片)是狗狗。这个训练过程你很容易通过 Azure 认知服务中的自定义机器视觉来体验和理解——你甚至不需要懂得写代码或配置模型,图形界面的工作室里提供图片和批量设置标签即可完成训练。

ImageNet 数据集的部分数据——狗的照片
OpenAI 通过 CLIP 模型发现了多模态模型的能力,利用互联网等语料数据集中对图片的文字描述,进行了交叉的训练,使得多模态大模型将图片的“意思”和图片的“显示”关联在一起。从而实现了对图片的无监督学习——这个过程不再需要我们给图片打标签了。这也是人工智能内容生成(AIGC)里,从文本提示自动生成图片的能力来源;亦可以说明 GPT-4 为什么懂人类在图片里玩的梗——AI 通过概率,明白了“意思”。
我们先举例来说明一下少样本学习。
▍少样本学习
一个从来没有见过无毛猫的小朋友,假设这个小朋友不是特别聪明,但已经知道通过分辨耳朵、鼻子、脸型等,分清楚是猫猫还是狗狗(比如通用预训练模型,GPT)。

有一说一,这小喵小汪真可爱
为了让他知道什么是无毛猫,我们也许需要提供以下两张照片:

然后告诉他,左边没有毛的但看得出猫脸的,是无毛猫,右边没有毛但是有狗脸的不是无毛猫。当然也许还可以再给他看几张照片加深印象。
于是,小朋友知道了,没有毛的狗,不是无毛猫;没有毛的猫,才是无毛猫。
▍单样本学习
那单样本学习的例子呢?很简单:
一个从来没有见过无毛猫的小朋友,假设这个小朋友比较聪明,我们只要给他看左边这张图,看,这只猫没有毛,它叫无毛猫。小朋友只要能认出这是猫,就认识了无毛猫。
▍零样本学习
那零样本学习的例子呢?更简单:
一个从来没有见过无毛猫的小朋友,假设这个小朋友很聪明,我们不需要给他看照片(我其实也怕吓到小朋友的),只要告诉他有一种猫没有毛。当他看到无毛猫的时候,他自己已经对猫有了概念(懂得猫的“意思”),一看没有毛,就明白了,这是你们说的无毛猫。
这个小朋友自己学习的能力,就叫做元学习。这个能力不像传统的监督学习,目标不是识别具体类别,而是学习本身——学会判断归类从未见过的对象(懂得“意思”)。
让我们倒过来想这个问题。如果一个模型还没那么聪明的时候,即使可能具备了零样本的能力,但单样本和少样本是不是也能帮助模型更好地推断、提高准确性呢?
我认为,是的。所以在 Azure OpenAI Studio 里面你能够找到这样的例子。
以下是一个例子:“通过少数的几个例子,从一句话中按照示例提取结构化的数据。

在这个对话中,通过提供两个属性的范例,实现了准确地从自然语言描述中,抽取结构化的数据以产生表格。这不就是少样本学习的例子吗?
目前,至少目前,我们还是比 AI 聪明的,比如下面这张图:

我的天呐,小喵小汪也玩《Face Off》这么神奇的吗?
当我们使用 Azure 视觉认知服务 [6]工作室来“逗”人工智能的时候,AI 就会很纠结这到底是猫是狗了。

对于全图,AI 能够一定程度上识别出狗和猫,但具体到换脸的猫,却被认成了狗。我们当然知道,它们既不是猫也不是狗,哈哈哈。
在本文的下半部分,我们将继续轻松地聊聊其他更好的 ChatGPT 聊天方式。欢迎大家持续关注!
参考链接:
[1] Azure OpenAI Service - Documentation, quickstarts, API reference - Azure Cognitive Services | Microsoft Learn[EB/OL]. [2023-04-11]. https://learn.microsoft.com/en-us/azure/cognitive-services/openai/?WT.mc_id=AI-MVP-33253.
[2] VASWANI A, SHAZEER N, PARMAR N, 等. Attention Is All You Need[M/OL]. arXiv, 2017[2023-04-11]. http://arxiv.org/abs/1706.03762.
[3] SHI X, CHEN Z, WANG H, 等. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting[M/OL]. arXiv, 2015[2023-04-11]. http://arxiv.org/abs/1506.04214.
[4] Completions - OpenAI API[EB/OL]. [2023-04-11]. https://platform.openai.com/docs/api-reference/completions.
[5] Chat - OpenAI API[EB/OL]. [2023-04-11]. https://platform.openai.com/docs/api-reference/chat.
[6] 计算机视觉文档 - 快速入门、教程和 API 参考 - Azure 认知服务 | Microsoft Learn[EB/OL]. [2023-04-11]. https://learn.microsoft.com/zh-CN/azure/cognitive-services/computer-vision/?WT.mc_id=AI-MVP-33253.