文章目录
- 概览
- 使用
- 与ES交互
- 索引创建
- 索引查询
- 索引删除
- 文档创建修改
- 文档局部修改
- 文档查询
- 文档删除
- 全查询
- 整合SpringBoot
- pom依赖
- application.yml
- ElasticsearchAutoConfiguration
- ElasticsearchProperties
- ElasticsearchConstant
- Person
- SearchPageHelper
- PersonService
- BaseElasticsearchService
- PersonServiceImpl
- ElasticsearchApplicationTests
- 集群架构
- 搭建集群
- 分布式架构原理
- 故障转移
- 分片控制
- 写数据流程
- 读数据流程
- 搜索数据过程
- 更新流程
- 原理
- 倒排索引
- 分析器
- 文档搜索
- 近实时搜索
- 优化
- 合理设置分片数
- 文件缓冲区
- 数据预热
- 冷热分离
- document模型设计
概览
Elasticsearch,简称为 ES, ES是一个开源的高扩展的分布式全文搜索引擎, 是整个 ElasticStack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
Elastic Stack, 包括 Elasticsearch、 Kibana、 Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比,如图:
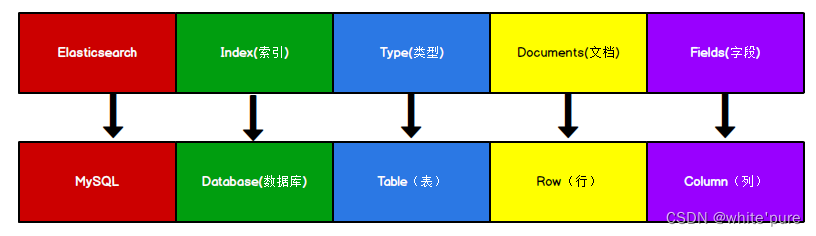
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。
官网下载地址: https://www.elastic.co/cn/downloads/past-releases
使用
与ES交互
索引创建
发送put请求
http://127.0.0.1:9200/_indexname
索引查询
发送get请求,查询单条
http://127.0.0.1:9200/_indexname
查询所有索引,发送get请求
http://127.0.0.1:9200/_cat/indices
索引删除
发送delete请求
http://127.0.0.1:9200/_indexname
文档创建修改
发送post请求,第一次为创建,再一次发送为修改
http://127.0.0.1:9200/_indexname/_docname/idstr
请求参数
{
"title":"华为手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
文档局部修改
发送post请求
http://127.0.0.1:9200/_indexname/_update/idstr
请求参数
{
"doc": {
"title":"小米手机",
"category":"小米"
}
}
文档查询
发送get请求,查询单条
http://127.0.0.1:9200/_indexname/_docname/idstr
文档删除
发送delete请求
http://127.0.0.1:9200/_indexname/_docname/idstr
全查询
发送get请求,能看到全部数据
http://127.0.0.1:9200/_indexname/_search
url带参查询,发get请求
http://127.0.0.1:9200/_indexname/_search?q=category:小米
请求体带参查询,发送get请求
http://127.0.0.1:9200/_indexname/_search
查询category是华为和小米的,price大于2000,只显示title,显示第一页,每页显示两个,根据price降序
{
"query": {
"bool": {
"should": [{
"match": {
"category": "小米"
}
},
{
"match": {
"category": "华为"
}
}]
},
"filter": {
"range": {
"price": {
"gt": 2000
}
}
}
},
"_source": ["title"],
"from": 0,
"size": 2,
"sort": {
"price": {
"order": "desc"
}
}
}
整合SpringBoot
pom依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.5.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.5.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.5.2</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
application.yml
demo:
data:
elasticsearch:
cluster-name: elasticsearch
cluster-nodes: [127.0.0.1:1001,127.0.0.1:1002,127.0.0.1:1003]
index:
number-of-replicas: 0
number-of-shards: 3
ElasticsearchAutoConfiguration
/**
* ElasticsearchAutoConfiguration
*
* @since 2019-09-15 22:59
*/
@Configuration
@RequiredArgsConstructor(onConstructor_ = @Autowired)
@EnableConfigurationProperties(ElasticsearchProperties.class)
public class ElasticsearchAutoConfiguration {
private final ElasticsearchProperties elasticsearchProperties;
private List<HttpHost> httpHosts = new ArrayList<>();
@Bean
@ConditionalOnMissingBean
public RestHighLevelClient restHighLevelClient() {
List<String> clusterNodes = elasticsearchProperties.getClusterNodes();
clusterNodes.forEach(node -> {
try {
String[] parts = StringUtils.split(node, ":");
Assert.notNull(parts, "Must defined");
Assert.state(parts.length == 2, "Must be defined as 'host:port'");
httpHosts.add(new HttpHost(parts[0], Integer.parseInt(parts[1]), elasticsearchProperties.getSchema()));
} catch (Exception e) {
throw new IllegalStateException("Invalid ES nodes " + "property '" + node + "'", e);
}
});
RestClientBuilder builder = RestClient.builder(httpHosts.toArray(new HttpHost[0]));
return getRestHighLevelClient(builder, elasticsearchProperties);
}
/**
* get restHistLevelClient
*
* @param builder RestClientBuilder
* @param elasticsearchProperties elasticsearch default properties
* @return {@link org.elasticsearch.client.RestHighLevelClient}
* @author fxbin
*/
private static RestHighLevelClient getRestHighLevelClient(RestClientBuilder builder, ElasticsearchProperties elasticsearchProperties) {
// Callback used the default {@link RequestConfig} being set to the {@link CloseableHttpClient}
builder.setRequestConfigCallback(requestConfigBuilder -> {
requestConfigBuilder.setConnectTimeout(elasticsearchProperties.getConnectTimeout());
requestConfigBuilder.setSocketTimeout(elasticsearchProperties.getSocketTimeout());
requestConfigBuilder.setConnectionRequestTimeout(elasticsearchProperties.getConnectionRequestTimeout());
return requestConfigBuilder;
});
// Callback used to customize the {@link CloseableHttpClient} instance used by a {@link RestClient} instance.
builder.setHttpClientConfigCallback(httpClientBuilder -> {
httpClientBuilder.setMaxConnTotal(elasticsearchProperties.getMaxConnectTotal());
httpClientBuilder.setMaxConnPerRoute(elasticsearchProperties.getMaxConnectPerRoute());
return httpClientBuilder;
});
// Callback used the basic credential auth
ElasticsearchProperties.Account account = elasticsearchProperties.getAccount();
if (!StringUtils.isEmpty(account.getUsername()) && !StringUtils.isEmpty(account.getUsername())) {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(account.getUsername(), account.getPassword()));
}
return new RestHighLevelClient(builder);
}
}
ElasticsearchProperties
/**
* ElasticsearchProperties
*
* @version v1.0
* @since 2019-09-15 22:58
*/
@Data
@Builder
@Component
@NoArgsConstructor
@AllArgsConstructor
@ConfigurationProperties(prefix = "demo.data.elasticsearch")
public class ElasticsearchProperties {
/**
* 请求协议
*/
private String schema = "http";
/**
* 集群名称
*/
private String clusterName = "elasticsearch";
/**
* 集群节点
*/
@NotNull(message = "集群节点不允许为空")
private List<String> clusterNodes = new ArrayList<>();
/**
* 连接超时时间(毫秒)
*/
private Integer connectTimeout = 1000;
/**
* socket 超时时间
*/
private Integer socketTimeout = 30000;
/**
* 连接请求超时时间
*/
private Integer connectionRequestTimeout = 500;
/**
* 每个路由的最大连接数量
*/
private Integer maxConnectPerRoute = 10;
/**
* 最大连接总数量
*/
private Integer maxConnectTotal = 30;
/**
* 索引配置信息
*/
private Index index = new Index();
/**
* 认证账户
*/
private Account account = new Account();
/**
* 索引配置信息
*/
@Data
public static class Index {
/**
* 分片数量
*/
private Integer numberOfShards = 3;
/**
* 副本数量
*/
private Integer numberOfReplicas = 2;
}
/**
* 认证账户
*/
@Data
public static class Account {
/**
* 认证用户
*/
private String username;
/**
* 认证密码
*/
private String password;
}
}
ElasticsearchConstant
/**
* ElasticsearchConstant
*
* @version v1.0
* @since 2019-09-15 23:03
*/
public interface ElasticsearchConstant {
/**
* 索引名称
*/
String INDEX_NAME = "person";
/**
* 文档名称(字段名称)
*/
String COLUMN_NAME_1 = "column_1";
String COLUMN_NAME_2 = "column_2";
String COLUMN_NAME_3 = "column_3";
String COLUMN_NAME_4 = "column_4";
String COLUMN_NAME_5 = "column_5";
/**
* 高亮标签
*/
String TAG_HIGH_LIGHT_START = "<label style='color:red'>";
String TAG_HIGH_LIGHT_END = "</label>";
}
Person
/**
* Person
*
* @version v1.0
* @since 2019-09-15 23:04
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Person implements Serializable {
private static final long serialVersionUID = 8510634155374943623L;
/**
* 主键
*/
private Long id;
/**
* 名字
*/
private String name;
/**
* 国家
*/
private String country;
/**
* 年龄
*/
private Integer age;
/**
* 生日
*/
private Date birthday;
/**
* 介绍
*/
private String remark;
}
SearchPageHelper
/**
* @author: whitepure
* @date: 2023/1/6 11:25
* @description: SearchPageHelper
*/
@Data
@Accessors(chain = true)
public class SearchPageHelper<E> {
private Long current;
private Long pageSize;
private Long total;
private List<E> records;
}
PersonService
/**
* PersonService
*
* @version v1.0
* @since 2019-09-15 23:07
*/
public interface PersonService {
/**
* create Index
*
* @param index elasticsearch index name
* @author fxbin
*/
void createIndex(String index);
/**
* delete Index
*
* @param index elasticsearch index name
* @author fxbin
*/
void deleteIndex(String index);
/**
* insert document source
*
* @param index elasticsearch index name
* @param list data source
* @author fxbin
*/
void insert(String index, List<Person> list);
/**
* update document source
*
* @param index elasticsearch index name
* @param list data source
* @author fxbin
*/
void update(String index, List<Person> list);
/**
* delete document source
*
* @param person delete data source and allow null object
* @author fxbin
*/
void delete(String index, @Nullable Person person);
/**
* search all doc records
*
* @param index elasticsearch index name
* @return person list
* @author fxbin
*/
List<Person> searchList(String index);
/**
* 分页查询
*
* @param searchRequest search condition
* @return search list
*/
SearchPageHelper<Person> searchPage(SearchRequest searchRequest);
}
BaseElasticsearchService
/**
* BaseElasticsearchService
*
* @version 1.0v
* @since 2019-09-16 15:44
*/
@Slf4j
public abstract class BaseElasticsearchService {
@Resource
protected RestHighLevelClient client;
@Resource
private ElasticsearchProperties elasticsearchProperties;
protected static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// 默认缓冲限制为100MB,此处修改为30MB。
builder.setHttpAsyncResponseConsumerFactory(new HttpAsyncResponseConsumerFactory.HeapBufferedResponseConsumerFactory(30 * 1024 * 1024));
COMMON_OPTIONS = builder.build();
}
/**
* create elasticsearch index (asyc)
*
* @param index elasticsearch index
* @author fxbin
*/
protected void createIndexRequest(String index) {
try {
CreateIndexRequest request = new CreateIndexRequest(index);
// Settings for this index
request.settings(Settings.builder().put("index.number_of_shards", elasticsearchProperties.getIndex().getNumberOfShards()).put("index.number_of_replicas", elasticsearchProperties.getIndex().getNumberOfReplicas()));
CreateIndexResponse createIndexResponse = client.indices().create(request, COMMON_OPTIONS);
log.info(" whether all of the nodes have acknowledged the request : {}", createIndexResponse.isAcknowledged());
log.info(" Indicates whether the requisite number of shard copies were started for each shard in the index before timing out :{}", createIndexResponse.isShardsAcknowledged());
} catch (IOException e) {
throw new ElasticsearchException("创建索引 {" + index + "} 失败");
}
}
/**
* delete elasticsearch index
*
* @param index elasticsearch index name
* @author fxbin
*/
protected void deleteIndexRequest(String index) {
DeleteIndexRequest deleteIndexRequest = buildDeleteIndexRequest(index);
try {
client.indices().delete(deleteIndexRequest, COMMON_OPTIONS);
} catch (IOException e) {
throw new ElasticsearchException("删除索引 {" + index + "} 失败");
}
}
/**
* build DeleteIndexRequest
*
* @param index elasticsearch index name
* @author fxbin
*/
private static DeleteIndexRequest buildDeleteIndexRequest(String index) {
return new DeleteIndexRequest(index);
}
/**
* build IndexRequest
*
* @param index elasticsearch index name
* @param id request object id
* @param object request object
* @return {@link org.elasticsearch.action.index.IndexRequest}
* @author fxbin
*/
protected static IndexRequest buildIndexRequest(String index, String id, Object object) {
return new IndexRequest(index).id(id).source(BeanUtil.beanToMap(object), XContentType.JSON);
}
/**
* exec updateRequest
*
* @param index elasticsearch index name
* @param id Document id
* @param object request object
* @author fxbin
*/
protected void updateRequest(String index, String id, Object object) {
try {
UpdateRequest updateRequest = new UpdateRequest(index, id).doc(BeanUtil.beanToMap(object), XContentType.JSON);
client.update(updateRequest, COMMON_OPTIONS);
} catch (IOException e) {
throw new ElasticsearchException("更新索引 {" + index + "} 数据 {" + object + "} 失败");
}
}
/**
* exec deleteRequest
*
* @param index elasticsearch index name
* @param id Document id
* @author fxbin
*/
protected void deleteRequest(String index, String id) {
try {
DeleteRequest deleteRequest = new DeleteRequest(index, id);
client.delete(deleteRequest, COMMON_OPTIONS);
} catch (IOException e) {
throw new ElasticsearchException("删除索引 {" + index + "} 数据id {" + id + "} 失败");
}
}
/**
* 查询全部
*
* @param indices elasticsearch 索引名称
* @return {@link SearchResponse}
*/
protected SearchResponse search(String... indices) {
SearchRequest searchRequest = new SearchRequest(indices);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchRequest.source(searchSourceBuilder);
return search(searchRequest);
}
/**
* 查询全部
*
* @param searchRequest 查询条件
* @return {@link SearchResponse}
*/
protected SearchResponse search(SearchRequest searchRequest) {
SearchResponse searchResponse;
try {
searchResponse = client.search(searchRequest, COMMON_OPTIONS);
} catch (IOException e) {
throw new org.elasticsearch.ElasticsearchException("查询索引 %s 失败" , e, Arrays.toString(Arrays.stream(searchRequest.indices()).toArray()));
}
return searchResponse;
}
}
PersonServiceImpl
/**
* PersonServiceImpl
*
* @version v1.0
* @since 2019-09-15 23:08
*/
@Service
public class PersonServiceImpl extends BaseElasticsearchService implements PersonService {
@Override
public void createIndex(String index) {
createIndexRequest(index);
}
@Override
public void deleteIndex(String index) {
deleteIndexRequest(index);
}
@SneakyThrows
@Override
public void insert(String index, List<Person> list) {
for (Person person : list) {
IndexRequest request = buildIndexRequest(index, String.valueOf(person.getId()), person);
client.index(request, COMMON_OPTIONS);
}
}
@Override
public void update(String index, List<Person> list) {
list.forEach(person -> updateRequest(index, String.valueOf(person.getId()), person));
}
@Override
public void delete(String index, Person person) {
if (ObjectUtils.isEmpty(person)) {
// 如果person 对象为空,则删除全量
searchList(index).forEach(p -> {
deleteRequest(index, String.valueOf(p.getId()));
});
}
deleteRequest(index, String.valueOf(person.getId()));
}
@Override
public List<Person> searchList(String index) {
return toSearchList(search(index));
}
@Override
public SearchPageHelper<Person> searchPage(SearchRequest searchRequest) {
SearchResponse searchResponse = search(searchRequest);
TotalHits totalHits = searchResponse.getHits().getTotalHits();
return new SearchPageHelper<Person>()
.setTotal(totalHits == null ? 0 : totalHits.value)
.setRecords(toSearchList(searchResponse))
.setPageSize(20L);
}
private List<Person> toSearchList(SearchResponse searchResponse) {
SearchHit[] hits = searchResponse.getHits().getHits();
List<Person> searchList = new ArrayList<>();
Arrays.stream(hits).forEach(hit -> {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
// 处理高亮数据
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
highlightFields.forEach((k, v) -> {
if (v != null && v.getFragments().length > 0) {
sourceAsMap.put(k, StrUtil.strip(Arrays.toString(v.getFragments()), "[]"));
}
}
);
Person search = BeanUtil.mapToBean(sourceAsMap, Person.class, true);
searchList.add(search);
});
return searchList;
}
}
ElasticsearchApplicationTests
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElasticsearchApplicationTests {
@Autowired
private PersonService personService;
/**
* 测试删除索引
*/
@Test
public void deleteIndexTest() {
personService.deleteIndex(ElasticsearchConstant.INDEX_NAME);
}
/**
* 测试创建索引
*/
@Test
public void createIndexTest() {
personService.createIndex(ElasticsearchConstant.INDEX_NAME);
}
/**
* 测试新增
*/
@Test
public void insertTest() {
List<Person> list = new ArrayList<>();
list.add(Person.builder().age(11).birthday(new Date()).country("CN").id(1L).name("哈哈").remark("test1").build());
list.add(Person.builder().age(22).birthday(new Date()).country("US").id(2L).name("hiahia").remark("test2").build());
list.add(Person.builder().age(33).birthday(new Date()).country("ID").id(3L).name("呵呵").remark("test3").build());
personService.insert(ElasticsearchConstant.INDEX_NAME, list);
}
/**
* 测试更新
*/
@Test
public void updateTest() {
Person person = Person.builder().age(33).birthday(new Date()).country("ID_update").id(3L).name("呵呵update").remark("test3_update").build();
List<Person> list = new ArrayList<>();
list.add(person);
personService.update(ElasticsearchConstant.INDEX_NAME, list);
}
/**
* 测试删除
*/
@Test
public void deleteTest() {
personService.delete(ElasticsearchConstant.INDEX_NAME, Person.builder().id(1L).build());
}
/**
* 测试查询
*/
@Test
public void searchListTest() {
List<Person> personList = personService.searchList(ElasticsearchConstant.INDEX_NAME);
System.out.println(personList);
}
/**
* 测试分页查询
*/
@Test
public void searchPageTest(){
int current = 1;
int pageSize = 20;
int maxCurrent = 500;
// 此处最大页数设置为500 为es浅分页; 如需深度分页需更换分页方法并移除此条件
if (current > maxCurrent) {
return;
}
// 构造查询条件
SearchRequest searchRequest = new SearchRequest(ElasticsearchConstant.INDEX_NAME);
searchRequest.source(new SearchSourceBuilder()
.trackTotalHits(true)
// 查询条件
.query(
QueryBuilders.boolQuery()
// and
.must(QueryBuilders.termQuery(ElasticsearchConstant.COLUMN_NAME_2, true))
// or
.must(
QueryBuilders.boolQuery()
.should(QueryBuilders.matchQuery(ElasticsearchConstant.COLUMN_NAME_1, 1))
.should(QueryBuilders.matchQuery(ElasticsearchConstant.COLUMN_NAME_2, 2))
.should(QueryBuilders.matchQuery(ElasticsearchConstant.COLUMN_NAME_3, 3))
)
)
// 分页
.from((current - 1) * pageSize)
.size(pageSize)
// 相关度排序: SortBuilders.scoreSort()
.sort(
// 字段排序 可根据时间
SortBuilders
.fieldSort(ElasticsearchConstant.COLUMN_NAME_2)
.order(SortOrder.DESC)
)
// 高亮字段
.highlighter(new HighlightBuilder()
.requireFieldMatch(true)
.preTags(ElasticsearchConstant.TAG_HIGH_LIGHT_START)
.field(ElasticsearchConstant.COLUMN_NAME_1)
.field(ElasticsearchConstant.COLUMN_NAME_2)
.field(ElasticsearchConstant.COLUMN_NAME_3)
.postTags(ElasticsearchConstant.TAG_HIGH_LIGHT_END)
));
SearchPageHelper<Person> personSearchPageHelper = personService.searchPage(searchRequest);
System.out.println(personSearchPageHelper);
}
}
集群架构
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。 当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为主节点时, 它将负责管理集群范围内的所有变更,例如增加、 删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回给客户端。
搭建集群
- 创建 elasticsearch-cluster 文件夹,在内部复制三个 elasticsearch 服务。
-
修改节点配置; config/elasticsearch.yml 文件
- node-1001 节点
#集群名称,节点之间要保持一致 cluster.name: my-elasticsearch #节点名称,集群内要唯一 node.name: node-1001 node.master: true node.data: true #ip 地址 network.host: localhost #http 端口 http.port: 1001 #tcp 监听端口 transport.tcp.port: 9301 #discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"] #discovery.zen.fd.ping_timeout: 1m #discovery.zen.fd.ping_retries: 5 #集群内的可以被选为主节点的节点列表 #cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #跨域配置 #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*" - node-1002 节点
#集群名称,节点之间要保持一致 cluster.name: my-elasticsearch #节点名称,集群内要唯一 node.name: node-1002 node.master: true node.data: true #ip 地址 network.host: localhost #http 端口 http.port: 1002 #tcp 监听端口 transport.tcp.port: 9302 discovery.seed_hosts: ["localhost:9301"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 #集群内的可以被选为主节点的节点列表 #cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #跨域配置 #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*" - node-1003 节点
#集群名称,节点之间要保持一致 cluster.name: my-elasticsearch #节点名称,集群内要唯一 node.name: node-1003 node.master: true node.data: true #ip 地址 network.host: localhost #http 端口 http.port: 1003 #tcp 监听端口 transport.tcp.port: 9303 #候选主节点的地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["localhost:9301", "localhost:9302"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 #集群内的可以被选为主节点的节点列表 #cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #跨域配置 #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*"
- node-1001 节点
-
启动集群; 点击 bin\elasticsearch.bat
如果启动不起来可能原因是分配内存不足,需要修改 config\jvm.options 文件中的内存属性
启动之后使用ES可视化工具查看,可使用elasticsearch-head,ElasticHD
分布式架构原理
ElasticSearch 设计的理念就是分布式搜索引擎,底层其实还是基于 lucene 的。核心思想就是在多台机器上启动多个 ES 进程实例,组成了一个 ES 集群。
ES分布式架构实际上就是对index的拆分,将index拆分成多个分片(shard),将分片分别放到不同的ES上实现集群部署.
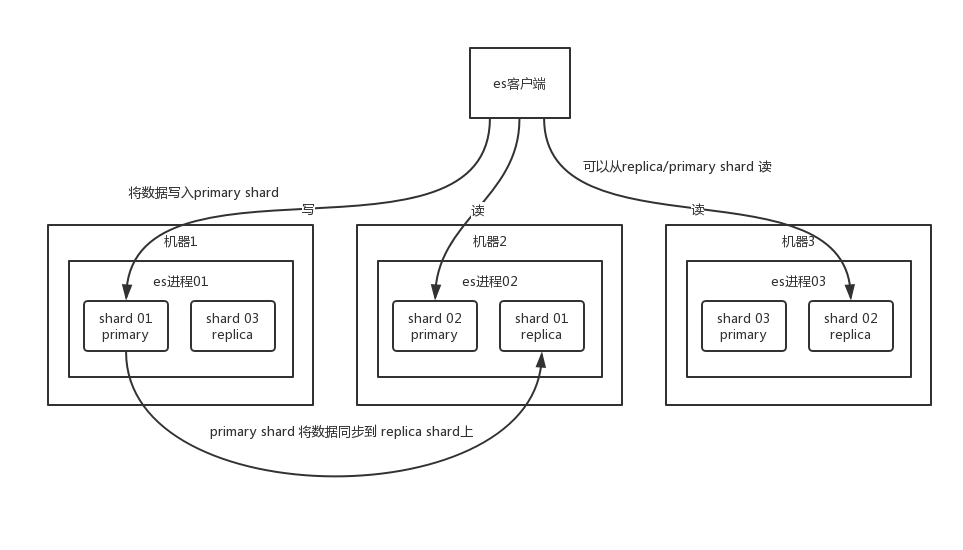
分片优点:
- 支持横向扩展: 比如你数据量是 3T,3 个 shard,每个 shard 就 1T 的数据,若现在数据量增加到 4T,怎么扩展,很简单,重新建一个有 4 个 shard 的索引,将数据导进去;
- 提高性能: 数据分布在多个 shard,即多台服务器上,所有的操作,都会在多台机器上并行分布式执行,提高了吞吐量和性能;
分片的数据实际上是有多个备份存在的,会存在一个主分片,还有几个副本分片. 当写入数据的时候先写入主分片,然后并行将数据同步到副本分片上;当读数据的时候会获取到所有分片,负载均衡轮询读取.
当某个节点宕机了,还有其他分片副本保存在其他的机器上,从而实现了高可用. 如果是非主节点宕机了,那么会由主节点,让那个宕机节点上的主分片的数据转移到其他机器上的副本数据。接着你要是修复了那个宕机机器,重启了之后,主节点会控制将缺失的副本数据分配过去,同步后续修改的数据之类的,让集群恢复正常. 如果是主节点宕机,那么会重新选举一个节点为主节点.
故障转移
在一个网络环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片。
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。 幸运的是,我们只需再启动一个节点即可防止数据丢失。当你在同一台机器上启动了第二个节点时,只要它和第一个节点有同样的 cluster.name 配置,它就会自动发现集群并加入到其中。
ES最好部署3个以上的节点,并且配置仲裁数大于一半节点,防止master选举的脑裂问题。
- 当一个节点掉线,如果该节点是master节点,则通过比较node ID,选择较小ID的节点为master;
- 然后由master节点决定分片如何重新分配。同理,新加入节点也是由master决定如何分配分片;
关于master的选举:
主要是由ZenDiscovery模块负责,包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含-一个主机列表以控制哪些节点需要ping通)这两部分.
首先对所有可以成为master的节点(可以配置)根据nodeId排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个,暂且认为它是master节点
如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件
ES在主节点上产生分歧,产生多个主节点,从而使集群分裂,使得集群处于异常状态。这个现象叫做脑裂。脑裂问题其实就是同一个集群的不同节点对于整个集群的状态有不同的理解,导致操作错乱,类似于精神分裂。
分片控制
当写入一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 集群如何知道一个文档应该存放到哪个分片中呢?
Elasticsearch 集群路由计算公式:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这也就是创建索引的时候主分片的数量永远也不会改变的原因,如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了.
用户可以访问任何一个节点获取数据,因为存放的规则一致(副本和主分片存放的数据一致),这个节点称之为协调节点.如果当前节点访问量较大可能被转到其他节点上,所以当发送请求的时候,为了扩展负载,更好的做法是轮询集群中所有的节点.
写数据流程
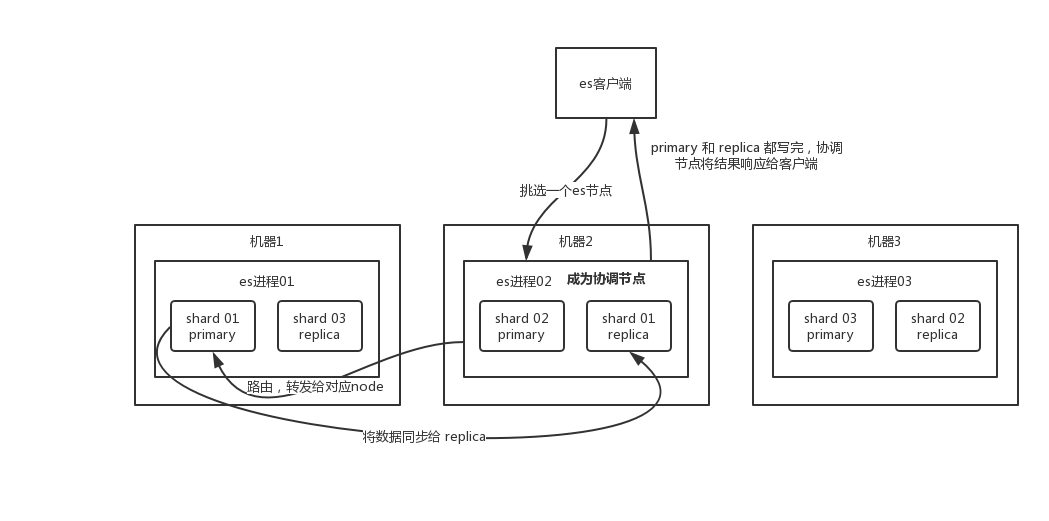
- 客户端请请求任意集群节点(协调节点);
- 协调节点将请求转换到指定节点(路由计算);
- 主分片需要将数据保存;
- 主分片将保存数据的请求发送到各个副本;
- 各个副本保存后,进行响应;
- 主分片进行响应;
- 客户端获取响应;
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。有一些可选的请求参数允许您影响这个过程,可能以数据安全为代价提升性能。
设置 consistency 参数值会影响写入操作.consistency 参数的值可以设为:
- one :只要主分片状态 ok 就允许执行写操作;
- all:必须要主分片和所有副本分片的状态没问题才允许执行写操作;
- quorum:默认值为quorum , 即大多数的分片副本状态没问题就允许执行写操作;
当consistency值设置为quorum时,如果没有足够的副本分片Elasticsearch 会等待.默认情况下,它最多等待 1 分钟,可以使用timeout参数使它更早终止.
读数据流程
- 客户端发送查询请求到协调节点;
- 协调节点计算数据所在的分片及全部的副本位置,为了能负载均衡要轮询所有的分片;
- 将请求转发给具体的节点;
- 节点返回查询结果,将结果返回给客户端;
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。在文档被检索时,已经保存的数据可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
搜索数据过程
- 客户端发送请求到一个协调节点;
- 协调节点计算数据所在的分片及全部的副本位置;
- 每个分片将自己的搜索结果(其实就是一些 doc id )返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果;
- 接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端;
更新流程
- 客户端向某一节点发送更新请求;
- 将请求转发到主分片所在的节点;
- 从主分片检索文档,修改_source字段中的JSON,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤3 ,超过retry_on_conflict次后放弃;
- 如果主节点成功地更新文档,它将新版本的文档并行转发到副本分片,重新建立索引。一旦所有副本分片都返回成功,主节点向协调节点也返回成功,协调节点向客户端返回成功;
在步骤4中,主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。请记住,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。 如果 Elasticsearch 仅转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档。
原理
分片是Elasticsearch最小的工作单元。传统的数据库每个字段存储单个值,但这对全文检索并不够。文本字段中的每个单词需要被搜索,对数据库意味着需要单个字段有索引多值的能力。最好的支持是一个字段多个值需求的数据结构是倒排索引。
倒排索引
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。 倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
倒排索引示例:
| value | key |
|----------|-------------------|
| my name is zhangsan | 1001 |
| key | value|
|---------|------|
| name | 1001 |
| zhang | 1001 |
| zhangsan| 1001 |
倒排索引搜索过程: 查询单词是否在词典中,如果不在搜索结束,如果在词典中需要查询单词在倒排列表中的指针,获取单词对应的文档ID,根据文档ID查询时哪一条数据
词条: 索引中最小的存储和查询单元
词典: 词条的集合;一般用hash表或B+tree存储
倒排表: 记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项.根据倒排列表,即可获知哪些文档包含某个单词.
分析器
倒排索引总是和分词分不开的,中文分词和英文分词是不一样的,所以就需要分析器.
分析器的主要功能是将一块文本分成适合于倒排索引的独立词条,分析器组成:
- 字符过滤器: 在分词前整理字符串,一个字符过滤器可以用来去掉 HTML,或者将 & 转化成 and;
- 分词器: 字符串被分词器分为单个的词条,一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条;
- 词单元过滤器: 按顺序通过每个过滤器,这个过程可能会改变词条(例如,小写化Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像jump和leap这种同义词);
Elasticsearch附带了可以直接使用的预包装的分析器:
- 标准分析器: 默认使用的分析器。它是分析各种语言文本最常用的选择。它根据Unicode 联盟定义的单词边界划分文本。删除绝大部分标点;
- 简单分析器: 在任何不是字母的地方分隔文本,将词条小写;
- 空格分析器: 在空格的地方划分文本;
- 语言分析器: 考虑指定语言的特点,根据语法进行分词; 例如,英语分析器附带了一组英语无用词(常用单词,例如and或者the ,它们对相关性没有多少影响),它们会被删除;
常用中文分词器: ik分词器, 将解压后的后的文件夹放入 ES 根目录下的 plugins 目录下,重启 ES 即可使用.
文档搜索
早期的全文检索会为整个文档集合建立一个很大的倒排索引并将其写入到磁盘。 被写入的索引不可变化,一旦新的索引就绪,旧的就会被其替换.如果你需要让一个新的文档可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
如何在保留不变性的前提下实现倒排索引的更新?
用更多的索引。通过增加新的补充索引来反映新的修改,而不是直接重写整个倒排索引。每一个倒排索引都会被轮流查询到,从最早的开始查询完后再对结果进行合并。
当一个文档被删除时,它实际上只是在文件中被标记删除。一个被标记删除的文档仍然可以被查询匹配到,但它会在最终结果被返回前从结果集中过滤掉。 文档更新也是类似的操作方式:当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
当一个查询被触发,所有已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,此时会将标记删除的数据真正的删除.
近实时搜索
Elasticsearch 的主要功能就是搜索,但是Elasticsearch的搜索功能不是实时的,而是近实时的,主要原因在于ES搜索是分段搜索.
ES中的每一段就是一个倒排索引,最新的数据更新会体现在最新的段中,而最新的段落盘之后ES才能进行搜索,所以磁盘性能极大影响了ES软件的搜索.ES的主要作用就是快速准确的获取想要的数据,所以降低处理数据的延迟就显得尤为重要.
ES近实时搜索实现:
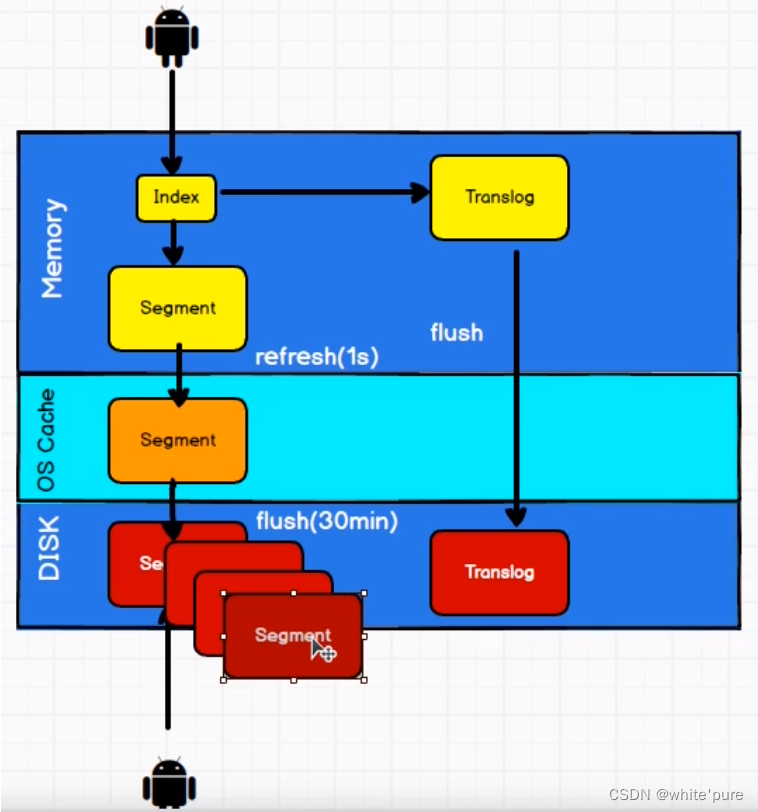
- 一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了 translog 事务日志中;(先写入索引中,再写入到日志中,目的防止数据丢失,类似数据库中的事务日志)
- 将内存缓冲区中的分片刷新到磁盘中(refresh);此时缓冲区的数据可被搜索,当完全将数据写入磁盘会清空缓冲区中的数据;
- 随着不断的刷写,磁盘中的文件会越来越多,此时需要文件段合并;当一个新的索引文件产生之后,文件的更新,删除便会体现出,此时在合并文件的时候便会真正的将数据删除;小的段被合并到大的段,然后这些大的段再被合并到更大的段;
优化
Elasticsearch 在数据量很大的情况下(数十亿级别)如何提高查询效率?
合理设置分片数
分片和副本的设计为 ES 提供了支持分布式和故障转移的特性,但并不意味着分片和副本是可以无限分配的。而且索引的分片完成分配后由于索引的路由机制,我们是不能重新修改分片数的.否则将无法找到对应的数据.
- 控制每个分片占用的硬盘容量不超过 ES 的最大 JVM 的堆空间设置,因此,如果索引的总容量在 500G 左右,那分片大小在 16 个左右即可;
- 考虑一下 node 数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了 1 个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以, 一般都设置分片数不超过节点数的 3 倍;
- 主分片,副本和节点最大数之间数量,我们分配的时候可以参考: 节点数<=主分片数 *(副本数+1);
文件缓冲区
往 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 filesystem cache 里面去;ES 的搜索引擎严重依赖于底层的 filesystem cache ,你如果给 filesystem cache 更多的内存,尽量让内存可以容纳所有的 idx segment file 索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。
案例: 某个公司 ES 节点有 3 台机器,每台机器看起来内存很多,64G,总内存就是 64 * 3 = 192G 。每台机器给 ES jvm heap 是 32G ,那么剩下来留给 filesystem cache 的就是每台机器才 32G ,总共集群里给 filesystem cache 的就是 32 * 3 = 96G 内存。而此时,整个磁盘上索引数据文件,在 3 台机器上一共占用了 1T 的磁盘容量,ES 数据量是 1T ,那么每台机器的数据量是 300G 。这样性能好吗? filesystem cache 的内存才 100G,十分之一的数据可以放内存,其他的都在磁盘,然后你执行搜索操作,大部分操作都是走磁盘,性能肯定差。
归根结底,你要让 ES 性能要好,最佳的情况下,就是你的机器的内存,至少可以容纳你的总数据量的一半。
根据生产环境实践经验,最佳的情况下,是仅仅在 ES 中就存少量的数据,就是你要用来搜索的那些索引,如果内存留给 filesystem cache 的是 100G,那么你就将索引数据控制在 100G 以内,这样的话,你的数据几乎全部走内存来搜索,性能非常之高,一般可以在 1 秒以内。
比如说你现在有一行数据。 id,name,age … 30 个字段。但是你现在搜索,只需要根据 id,name,age 三个字段来搜索。如果你傻乎乎往 ES 里写入一行数据所有的字段,就会导致说 90% 的数据是不用来搜索的,结果硬是占据了 ES 机器上的 filesystem cache 的空间,单条数据的数据量越大,就会导致 filesystem cahce 能缓存的数据就越少。其实,仅仅写入 ES 中要用来检索的少数几个字段就可以了,比如说就写入 ES id,name,age 三个字段,然后你可以把其他的字段数据存在 mysql/hbase 里,我们一般是建议用 ES + hbase 这么一个架构。
写入 ES 的数据最好小于等于,或者是略微大于 ES 的 filesystem cache 的内存容量。然后你从 ES 检索可能就花费 20ms,然后再根据 ES 返回的 id 去 hbase 里查询,查 20 条数据,可能也就耗费个 30ms,可能你原来那么玩儿,1T 数据都放 es,会每次查询都是 5~10s,现在可能性能就会很高,每次查询就是 50ms。
数据预热
假如说,哪怕是你就按照上述的方案去做了,ES 集群中每个机器写入的数据量还是超过了 filesystem cache 一倍,比如说你写入一台机器 60G 数据,结果 filesystem cache 就 30G,还是有 30G 数据留在了磁盘上。
其实可以做数据预热。
举个例子,拿微博来说,你可以把一些大 V,平时看的人很多的数据,你自己提前后台搞个系统,每隔一会儿,自己的后台系统去搜索一下热数据,刷到 filesystem cache 里去,后面用户实际上来看这个热数据的时候,他们就是直接从内存里搜索了,很快。
或者是电商,你可以将平时查看最多的一些商品,比如说 iphone 8,热数据提前后台搞个程序,每隔 1 分钟自己主动访问一次,刷到 filesystem cache 里去。
对于那些你觉得比较热的、经常会有人访问的数据,最好做一个专门的缓存预热子系统,就是对热数据每隔一段时间,就提前访问一下,让数据进入 filesystem cache 里面去。这样下次别人访问的时候,性能一定会好很多。
冷热分离
ES 可以做类似于 mysql 的水平拆分,就是说将大量的访问很少、频率很低的数据,单独写一个索引,然后将访问很频繁的热数据单独写一个索引。最好是将冷数据写入一个索引中,然后热数据写入另外一个索引中,这样可以确保热数据在被预热之后,尽量都让他们留在 filesystem os cache 里,别让冷数据给冲刷掉。
假设你有 6 台机器,2 个索引,一个放冷数据,一个放热数据,每个索引 3 个 shard。3 台机器放热数据 index,另外 3 台机器放冷数据 index。然后这样的话,你大量的时间是在访问热数据 index,热数据可能就占总数据量的 10%,此时数据量很少,几乎全都保留在 filesystem cache 里面了,就可以确保热数据的访问性能是很高的。但是对于冷数据而言,是在别的 index 里的,跟热数据 index 不在相同的机器上,大家互相之间都没什么联系了。如果有人访问冷数据,可能大量数据是在磁盘上的,此时性能差点,就 10% 的人去访问冷数据,90% 的人在访问热数据,也无所谓了。
document模型设计
对于 MySQL,我们经常有一些复杂的关联查询。在 ES 里该怎么玩儿,ES 里面的复杂的关联查询尽量别用,一旦用了性能一般都不太好。
最好是先在 Java 系统里就完成关联,将关联好的数据直接写入 ES 中。搜索的时候,就不需要利用 ES 的搜索语法来完成 join 之类的关联搜索了。
document 模型设计是非常重要的,很多操作,不要在搜索的时候才想去执行各种复杂的乱七八糟的操作。ES 能支持的操作就那么多,不要考虑用 ES 做一些它不好操作的事情。如果真的有那种操作,尽量在 document 模型设计的时候,写入的时候就完成。另外对于一些太复杂的操作,比如 join/nested/parent-child 搜索都要尽量避免,性能都很差的。