查找的基本概念
**查找:**在数据集合中寻找满足某种条件数据元素的过程,称之为查找。
- 查找的结果 分别两种:
- 查找成功 即在数据集合中找到了满足条件的数据元素。查找结果给出整个记录的信息,或者改记录在查找表中的位置。
- 查找失败 查找记录给出空指针或空记录。
查找表(查找结构):是由同一类型的数据元素(或记录)组成,可以是一个数组或链表…
- 由于”集合“中的元素之间存在着松散的关系(没有严格的前取后继关系),因此查找表是一种应用灵活的结构。
关键字:数据元素中唯一标识该元素的某个数据项的值,使用基于关键字的查找,查找结果应该是唯一的。
例如:在有一个学生元素构成的数据集合中,学生元素中“学号”这一数据项的值唯一的标识一名学生。
-
次关键字:反之:用以识别若干记录的关键字是次关键字。
例如:用张三这个名字查找,可能有好几个同学
查找的目的:(一般操作)
- 查询:查询某个特定的数据元素是否在查找表中。
- 检索:检索某个特定的数据元素的各种属性。
- 插入:在查找表中插入一个数据元素。
- 删除:删除查找表中的某个数据元素。
动态查找表和静态查找表:
- 静态:若一个查找表的操作致设计上述目的中的1和2,则无须动态的修改查找表,此类查找表成为静态查找表。
- 动态:与此对应,需要动态地修改查找表,称为动态查找表。
另外,适合静态查找表的查找方式有顺序查找,折半查找,散列查找等;
适合动态查找表的查找方式有二叉排序树的查找,散列查找等。
**平均查找长度:**即所有查找过程中进行关键字的比较次数的平均值,英文表示为ASL(Average Search Length),其数学定义为:
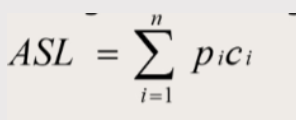
其中,ASL 值 ↓,时间效率 ↑。
- n:查找表中,总共有多少个数据记录。
- pi:每一条数据记录可能被查找到的概率(通常认为 pi = 1/n)
- ci:找到第 i 个数据元素所需要的比较次数。
平均查找长度是衡量查找算法效率的最主要的指标。
线性表的查找
顺序查找(线性查找)
应用范围:
- 顺序查找适用于顺序表或线性链表表示的静态查找表。
- 表内元素之间可以是无序的,即查找表中元素的排列顺序并不影响查找过程。
- 顺序查找在小规模数据集和查找表结构不明确的情况下可能是一个合适的选择。
ADT:
- 数据元素类型定义:
typedef struct {
KeyType key; // 关键字域
InfoType otherinfo; // 其他域
} ElemType;
- 顺序表定义:
// 顺序表结构类型定义
typedef struct {
ElemType* R; // 存储空间基地址
int length; // 记录当前表中有多少个数据元素
} SSTable; // Sequential Search Table
- 顺序查找算法实现:
// 顺序查找(线性查找)算法实现
int SequentialSearch(SSTable ST, KeyType key) {
// 在顺序表St中查找关键字为key的元素,若找到则返回位置,否则返回-1
ST.elem[0] = key; // 设置哨兵
int i;
for (i = ST.length; ST.elem[i] != key; --i); //从后往前找,注意这里没有循环体,是空语句。
return i; // 若表中不存在关键字key的元素,将查找到i为0退出for循环
}
**引入哨兵的作用:**上述算法中,将ST.elem[0]称为哨兵,引入它的目的是使得Search_Seq内的循环不必判断数组是否越界。算法从尾部开始查找,若找到ST.elem[i]==key则返回 i 值,查找成功。否则一定在查找到ST.elem[0]==key时跳出循环,此时返回的是0,查找失败。在程序中引入“哨兵”并不是这个算法独有的,引入“哨兵”可以避免很多不必要的判断语句,从而提高程序效率。
对于有n个元素的表,给定值key与表中第 i 个元素相等,即定位第 i 个元素时,需进行 n-i+1 次关键字的比较,即Ci = n-i+1。查找成功时,顺序查找的平均长度为:ASL成功= ∑ i = 1 n \sum_{i=1}^n ∑i=1nPi(n-i+1)
当每个元素的查找概率相等,即Pi =1/n时,有:ASL成功= ∑ i = 0 n \sum_{i=0}^n ∑i=0nPi(n-i+1)= n + 1 2 \frac{n+1}{2} 2n+1
查找不成功时,与表中各关键字的比较次数显然是n+1次,即ASL不成功=n+1
通常,查找表中记录的查找概率并不相等。若能预先得知每个记录的查找概率,则应先对记录的查找概率进行排序,使表中记录按查找概率由大至小重新排列。
顺序查找算法的时间复杂度为O(n),其中n表示查找表的元素个数。在最好的情况下,需要查找1次即可找到目标元素;在最坏的情况下,需要查找n次。由于顺序查找的实现较简单,所以在小规模数据集或查找表结构不明确的情况下,顺序查找可能是一个合适的选择。然而,在大规模数据集或有序查找表的情况下,其他高效的查找方法(如二分查找、插值查找、哈希查找等)可能更为合适。
问题:
- 记录的查找概率不相等时,如何提高查找概率?
- 查找表存储记录原则——按查找概率从高到低存储。
- 查找概率越高,比较次数越少。
- 查找概率越低,比较次数越高。
- 查找表存储记录原则——按查找概率从高到低存储。
- 记录的查找概率无法测定时如何提高查找概率?
- 方法——按查找概率动态调整记录顺序:
- 在每个记录中设一个访问频率域
- 始终保持记录按非递增有序的次序排列
- 每次查找后均将刚查到的记录直接移值表头。
- 方法——按查找概率动态调整记录顺序:
顺序查找的特点
- 优点:算法简单,逻辑次序无要求,且不同存储结构均适用(顺序/链式存储均可)。
- 缺点:平均查找长度 ASL 太长,时间效率很低。
折半查找(二分查找)
二分查找(折半查找 ),它的主要思想是每次将待查记录所在区间缩小一半。该算法仅适用于已排序的数据。
非递归算法
查找过程:
-
设置查找区间的初始值:low 指向第一个元素,high 指向最后一个元素。
-
当 low <= high 时,执行以下操作:
a. 计算中间值 mid:mid = (low + high) / 2
b. 比较待查找关键字与 mid 位置的值:
- 如果关键字等于 mid 位置的值,查找成功。
- 如果关键字小于 mid 位置的值,更新 high = mid - 1,缩小查找范围到 mid 左边。
- 如果关键字大于 mid 位置的值,更新 low = mid + 1,缩小查找范围到 mid 右边。
-
当 high < low 时,查找结束,表示查找失败。
二分查找的性能分析:
- 查找成功时的比较次数等于路径上的节点数,可以用二叉树来描述。
- 查找不成功时的比较次数等于路径上的内部节点数,最大次数为 log₂n + 1。
- 平均查找长度 ASL(成功时)表示查找成功时的平均比较次数。
二分查找的特点:
优点:查找效率高于顺序查找。 缺点:
- 只适用于有序表。
- 限于顺序存储结构(对线性链表无效)。
代码实现
#include <stdio.h>
// 二分查找函数
// 参数:arr - 已排序的整数数组,n - 数组长度,key - 要查找的关键字
// 返回值:如果找到关键字,返回对应的数组下标;否则返回 -1
int binary_search(int arr[], int n, int key) {
int low = 0; // 查找区间的下限,初始化为数组首元素下标
int high = n - 1; // 查找区间的上限,初始化为数组末元素下标
int mid; // 中间位置下标
// 当 low <= high 时,继续查找
while (low <= high) {
mid = (low + high) / 2; // 计算中间位置下标
// 比较关键字与中间位置的值
if (key == arr[mid]) {
return mid; // 查找成功,返回对应下标
} else if (key < arr[mid]) {
high = mid - 1; // 更新上限,缩小查找范围到 mid 左边
} else {
low = mid + 1; // 更新下限,缩小查找范围到 mid 右边
}
}
// 查找失败,返回 -1
return -1;
}
int main() {
int arr[] = {1, 3, 5, 7, 9, 11, 13, 15}; // 已排序的整数数组
int n = sizeof(arr) / sizeof(arr[0]); // 计算数组长度
int key = 7; // 要查找的关键字
int result = binary_search(arr, n, key); // 调用二分查找函数
if (result != -1) {
printf("找到关键字 %d 在数组中的下标为 %d\n", key, result);
} else {
printf("未找到关键字 %d\n", key);
}
return 0;
}
折半查找(二分查找)性能分析——判定树
折半查找过程可以用二叉树来判断
树中的每一个结点对应表中的一个记录,但结点值不是记录的关键字,而是记录在表中的位置序号(或者是一份有序的关键字的值),树中最下面叶节点都是方形的,它表示查找不成功的情况。把当前查找区间的中间位置作为根,左子表和右子表分别作为根的左子树和右子树,由此得到的二叉树称为折半查找的判定树。结点所在层数表示该位置的元素需要比较多少次。若有序列表中有n个元素,则对应的判定树有n个圆形非叶节点和n+1个方形的叶节点。显然,判定树是一颗平衡二叉树。
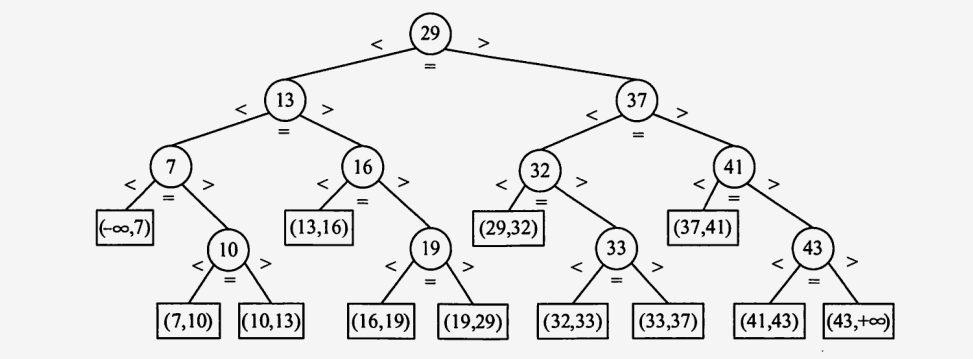
查找成功时,比较次数等于路径上的结点数,或者等于结点所在的层数。查找不成功时,比较次数等于路径上的内部结点数,且比较次数小于等于log2 n +1。(其中n为表中元素的总数)
假设每个元素的查找概率相等,求查找成功时的平均查找长度。所有元素的比较次数相加然后除以结点数。
平均查找长度ASL成功
设表长 n = 2h-1, 则h = log2(n+1)(此时,判定树的深度为j的满二叉树),且表中每个记录的查找概率相等:Pi=1/n。
折半查找特点:
优点:折半查找的效率较高,比顺序查找快。
缺点:
- 只适用于有序表,对无序表不适用。
- 限于顺序存储结构,对线性链表无效。
代码实现
判定树的二分查找是用于解释和分析二分查找过程的一种模型。在实际编程中,我们并不会显式地构建一个判定树,而是使用类似于上述非递归算法代码示例中的算法逻辑来实现二分查找。
判定树是一个概念性的工具,帮助我们理解二分查找的性质和性能,例如查找成功时的平均查找长度 (ASL)。在实际的算法实现中,我们依然会使用简单的循环结构和边界更新逻辑,而不是创建一个真实的判定树数据结构。
分块查找
分块查找,它将数据集分为多个较小的块,并对每个块建立索引。该方法旨在提高查找效率,同时便于插入和删除操作。分块查找的过程包括以下几个步骤:
- 数据分块:首先,将数据集分成若干个较小的块。每个块内的元素可以是有序的,也可以是无序的。如果每个块内的元素是无序的,我们称之为分块有序。这意味着块与块之间是有序的,而块内的元素是无序的。
- 建立索引表:为了快速定位待查找元素所在的块,需要建立一个索引表。索引表中的每个记录包含该块中的最大关键字以及该块中第一个元素的位置。索引表本身应该是有序的,以便于在查找过程中使用顺序查找或二分查找。
- 查找过程:分块查找的过程分为两个阶段。首先,在索引表中确定待查找元素所在的块。这可以通过顺序查找或二分查找实现。然后,在确定的块内进行查找。由于块内元素可能是无序的,通常采用顺序查找方法。
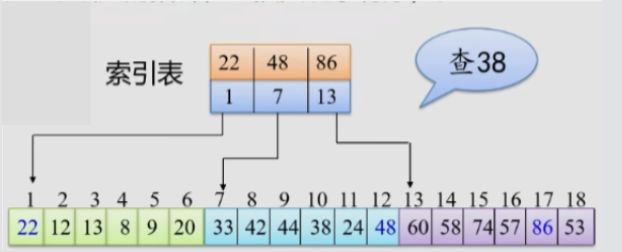
分块查找的平均查找次数取决于索引表的查找次数(Lb)和块内查找的次数(Lw)。整体而言,分块查找的效率通常高于顺序查找,但略低于二分查找。然而,分块查找在处理动态变化的数据时具有优势,因为插入和删除操作比较容易实现,无须进行大量的元素移动。对于分块查找的缺点也很明显,分块查找需要增加一个索引表的存储空间并对初识索引表进行排序运算。
- 索引表的查找次数(Lb):假设数据集中共有 n 个元素,每个块包含 s 个元素,那么索引表中有 n/s 个记录。在查找过程中,我们可以使用顺序查找或二分查找来查找索引表。以二分查找为例,索引表的平均查找次数为 Lb = log₂(n/s + 1)。
- 块内查找的次数(Lw):在确定待查找元素所在的块之后,需要在块内进行查找。由于块内元素可能是无序的,通常采用顺序查找方法。对于顺序查找,平均查找长度为 Lw = s/2。
代码实现
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define MAX 100
/* block search algorithm implementation */
// define the data structure
typedef struct {
int key;
}ElemType;
typedef struct {
ElemType *elem;
int length;
}SSTable;
typedef struct {
int key;
int start;
}Idx;
// Init the SSTable
void createTable(SSTable *ST,int a[],int n)
{
// allocate the spece for the elem
ST->elem = (ElemType *)malloc((n+1)*sizeof(ElemType));
// assign the ST length
ST->length = n;
// put the data into the elem
for(int i=1;i<=n;i++)
{
ST->elem[i].key = a[i-1];
}
}
// Init the index table
void createIndex(Idx index[],SSTable ST, int s)
{
int i,n=ST.length/s;
// if not divisible,please add a new index
if(ST.length%s)
n++;
// create the index table
for(i=0;i<n;i++)
{
// record the every block start position
index[i].start = i*s+1;
// record the every block max value
index[i].key = ST.elem[i*s+1].key;
}
}
// block search algorithm
int blockSearch(SSTable ST, Idx index[], int key, int s)
{
int i,j,n=ST.length/s;
// if not divisible,please add a new index
if(ST.length%s)
n++;
/* first step ---- search to key from index table to find the location of the block in which the key resides*/
for(i=0;i<n && index[i].key<key;i++);
// if the key is not in the table,return 0
if(i>=n) return 0;
/* second step ---- search to key in within the corresponding block*/
// get the start position of the block
int start = index[i-1].start;
// search
for(j=start;j<start+s && ST.elem[j].key!=key;j++);
// if the key is not in the table,return 0
if(j>=start+s) return 0;
// if the key is in the table,return the position
return j;
}
int main() {
// 初始化有序数组
int a[] = {3, 8, 15, 23, 37, 49, 56, 62, 73, 88};
int n = sizeof(a) / sizeof(a[0]);
// 创建有序表
SSTable ST;
createTable(&ST, a, n);
// 计算块大小
int s = sqrt(n);
// 创建索引表
Idx index[MAX];
createIndex(index, ST, s);
// 要查找的元素
int key = 49;
// 调用分块查找函数
int pos = blockSearch(ST, index, key, s);
// 输出查找结果
if (pos != -1) {
printf("Find %d at position %d.\n", key, pos);
} else {
printf("Not found %d.\n", key);
}
return 0;
}
三种线性表的查找的比较
| 顺序查找 | 折半查找 | 分块查找 | |
|---|---|---|---|
| ASL | 最大 | 最小 | 中间 |
| 表结构 | 有序表、无须表 | 有序表 | 分块有序 |
| 存储结构 | 顺序表、线性链表 | 顺序表 | 顺序表、线性链表 |