- 手撕BP神经网络
- 手写Bert和Transformer(BERT很细节的地方,比如文字标签CLS,par)
- 学习pytorch,tensorflow
AI算法岗位
可看网站
- 牛客网站
面经回复
- github

项目连接
算法工程师岗位必备知识
- 问答
- ELMO、GPT、BERT三者之间的区别
- 特征提取器:elmo采用LSTM进行提取,GPT和BERT采用Transformer进行提取。很多任务中Tranformer特征提取能力强于LSTM,elmo采用1层静态向量+2层lSTM,多层提取能力有限,而GPT和BERT中的Transformer可采用多层,并行计算能力强;单、双向语言模型:GPT采用单向语言模型,elmo和bert采用双向语言模型,但是elmo实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力弱。GPT和BERT都采用Transformer,Transformer是encoder-decoder结构,GPT的单向语言模型采用decoder部分,decoder的部分见到的都是不完整的句子;bert的双向语言模型则采用encoder部分。
- GloVe的训练过程是怎样的
- 实质还是监督学习,虽然Glove不需要人工标注,为无监督学习,但实质上还是需要定义label;向量w和w_为学习参数,本质上与监督学习的训练方法一样,采用了AdaGrad的梯度下降算法,对矩阵X中的所有非零元素进行随机采样,学习曲率设为0.05,在Vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。最终学习的是两个词向量是w和
- sigmoid函数
- 和正余弦函数比较像,虽然坐标区间是负无穷到正无穷,但是值域是-1,1(开区间),连续光滑函数,其是处处可导的
- 频率学派和贝叶斯学派的区别
- 频率学派认为研究的参数是固定的,数据是无限的,可以从无限的抽样里获取有限的结果,其不存在先验概率;贝叶斯学派认为世界是变化的,只有数据是固定的,参数是会变化的,其后验概率是先验概率的修正。(p(A交B)=P(B)*P(B|A))
- SGD和Adam原理
- SGD叫做随机梯度下降,它每次迭代计算mini-batch数据集的梯度,然后更新参数;Adam利用梯度的一阶矩估计和二阶矩估计动态更新参数的学习率,然后通过偏置矫正,最终的达到一个学习率的随机范围,使得参数趋于平稳
- L1不可导时怎么做
- 坐标轴下降法避免参数不可导。因为损失函数是按照负梯度下降的方式进行,而坐标轴下降法是按照坐标轴进行。比如有m个特征值,先固定m-1个特征值,使得某个特征先求得局部最优解来避免损失函数不可导的问题
- 最大似然估计和最大后验概率的区别
- 最大似然估计是利用观察数据进行计算的,而且最大似然估计中的采样满足所有采样,都是独立同分布的假设;而最大后验概率是利用经验数据来获得观察点估计,它融入了先验规律,可以看做是完全规则化的最大似然估计
- Transformer是如何训练的?测试阶段如何进行测试呢?
- Transformer训练过程与Seq2seq类似,首先Encoder端得到输入的encoding表示,并将其输入到decoder端做交互式attention,之后再Decoder端接收其相应的输入,经过多头self-attention模块之后,结合Encoder端的输出,再经过FFN,得到Decoder端的输出之后,最后经过一个线性全连接层,就可以通过softmax来预测下一个单词(token),然后根据softmax多分类的损失函数,将loss反向传播即可,所以从整体上来说,Transformer训练过程就相当于一个有监督的多分类问题。需要注意的是,Encoder端可以并行计算,一次性将输入序列全部encoding出来,但Encoder端不是一次性把所有单词(token)预测出来的,而是像seq2seq一样一个接着一个预测。而对于测试阶段,其与训练阶段唯一不同的是Decoder端最底层的输入。
- BERT模型可以使用无监督的方法做文本相似度任务?
- 首先一点是在不finetune的情况下,cosine similairty绝对值没有实际意义,bert pretrain计算的cosine similairty都是很大的。如果直接以cosine similarity>0.5之类的阈值来判断相似不相似,效果肯定很差。如果用作排序,也就是cosine(a,b)>cosine(a,c)->b相较于c和a更相似,是可以用的。使用auc作为评价的标准。
- 短文本(新闻标题)语义相似度任务用先进的word embedding(英文 fasttext/glove, 中文tencent embedding) mean pooling后的效果就已经不错;而对于长文本用simhash这种纯词频统计的完全语言模型的简单方法也OK
- bert pretrain模型直接拿来用作sentence embedding效果不如word embedding, cls的embedding效果最差(也就是pooled output)。把所有普通token embedding做pooling勉强能用
- 用siamese的方式训练bert,上层通过cosine做判别,能够让bert学习到以中适用于cosine作为最终相似度判别的sentence embedding,效果优于word embedding. 但因为缺少sentence pair之间的特征交互,比原始bert sentence pair fine tune还是要差些
- word2vec和NNLM对比有什么区别?
- 其本质可以看做是语言模型;词向量不过是NNLM的一个产物,word2vec虽然其本质是语言模型,但是其专注于词向量本身,因此做了许多优化来提高计算效率;与NNLM相比,词向量直接sum,不在拼接,并舍弃隐层,考虑到softmax归一化需要遍历整个词汇表,采用hierarchical softmax 和negatice sampling进行优化,hierarchical softmax实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路径变小;negative sampling更为直接,实质上对每一个样本中每一个词都进行负例采样
- Transformer如何并行化的?
- Transformer的并行化我认为主要体现在self-attention模块,在Encoder端Transformer可以并干性处理整个序列,并得到整个输入序列经过Encoder端的输出,在self-attention模块,对某个序列x1,x2,x3…,self-attention模块可以直接计算xi,xj的点乘结果,而RNN系列的模型就必须按照顺序从x1计算到xn
- glove和word2vec、LSA对比有什么区别?
- glove vs LSA: LSA(Latent Semantic Analysis)可以基于co-occurance matrix 构建词向量,实质上是基于全局语料采进行矩阵分解,然而SVD计算复杂度高,glove可看做是对LSA一种优化的高效矩阵分解算法,采用Adagrad对最小平方损失进行优化
- word2vec vs LAS:两个方法最大的差别是模型本身,LSA是一种基于概率图模型的生成式模型,其似然函数可以写为若干条件概率连乘的形式,其中包含需要推测的隐含变量(即主题);词嵌入模型一般表示为神经网络的形式,似然函数定义在网络的输出之上。需要学习网络的权重来得到单词的稠密向量表示。
- word2vec vs glove: word2vec是局部语料库训练的,其特征提取是基于滑窗的
- 如何对PTMs进行迁移学习?
- 选择合适的与训练任务:语言模型是PTM是最为流行的预训练任务,同类的预训练任务有其自身的偏置,并且对不同的任务会产生不同的效果。例如,NSP任务可以使诸如问答(QA)和自然语言推论(NLI)之类的下游任务收益;选择合适的模型架构:例如BERT采用的MLM策略和Transformer-Encoder结构,导致其不适合直接处理生成任务;选择合适的数据集,下游任务的数据应该近似于PTMs的与训练任务,现在有很多现成的ptms可以方便地用于各种特定领域或特定语言的下游任务;选择合适的layers进行transfer:主要包括Embedding迁移、top layer迁移和all layer迁移。如word2vec和Glove可采用Embedding迁移,BERT可采用top layer迁移,Elmo可采用all layer迁移,BERT可采用top layer迁移,Elmo可采用all layer迁移。
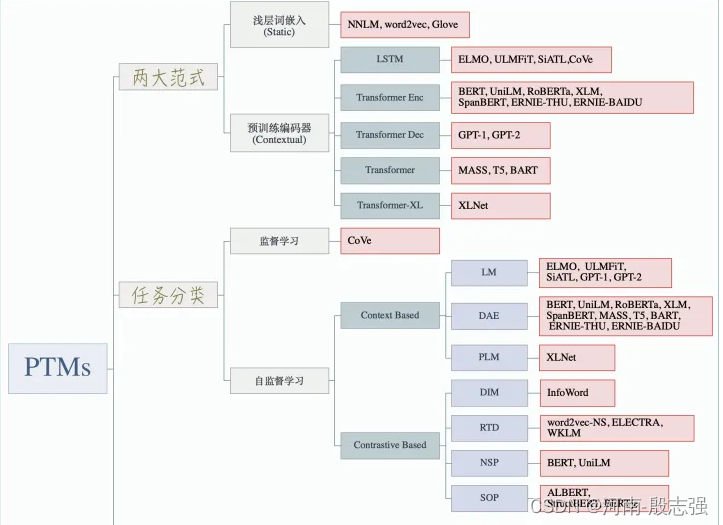
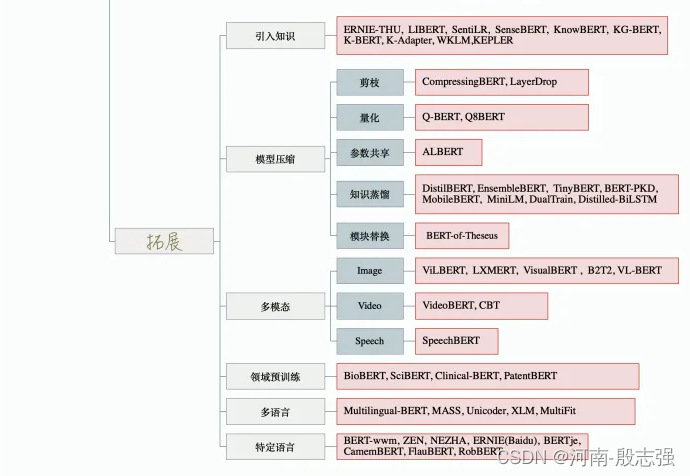
- 选择合适的与训练任务:语言模型是PTM是最为流行的预训练任务,同类的预训练任务有其自身的偏置,并且对不同的任务会产生不同的效果。例如,NSP任务可以使诸如问答(QA)和自然语言推论(NLI)之类的下游任务收益;选择合适的模型架构:例如BERT采用的MLM策略和Transformer-Encoder结构,导致其不适合直接处理生成任务;选择合适的数据集,下游任务的数据应该近似于PTMs的与训练任务,现在有很多现成的ptms可以方便地用于各种特定领域或特定语言的下游任务;选择合适的layers进行transfer:主要包括Embedding迁移、top layer迁移和all layer迁移。如word2vec和Glove可采用Embedding迁移,BERT可采用top layer迁移,Elmo可采用all layer迁移,BERT可采用top layer迁移,Elmo可采用all layer迁移。