So-vits-svc 基于端到端架构的VITS和soft-vc,用户只需准备几十分钟到几个小时不等的语音或歌声数据,就能制作(训练)属于自己的 AI 声库 (前提是你的显卡足够给力),将一段语音或歌声转换为你想要的音色。
获取项目
首先我们需要从github上获取项目
git clone https://github.com/svc-develop-team/so-vits-svc
声音文件
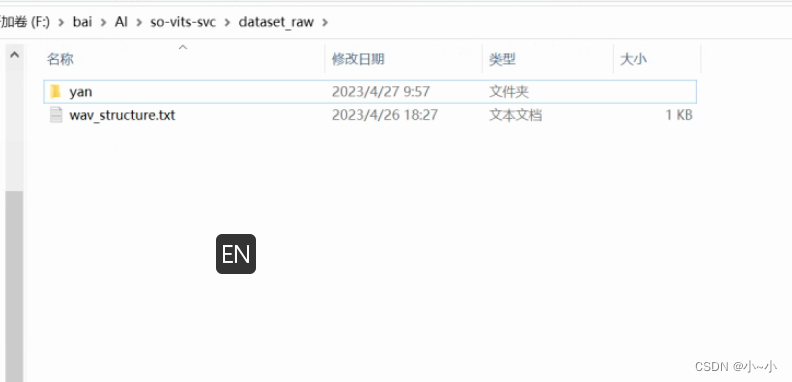
把你要训练的声音的放到dataset_raw目录下,最好切成5s - 15s的人声片段。可以使用工具进行切片
工具链接:https://github.com/flutydeer/audio-slicer/releases
如下所示,这里我把所有切片好的声音文件放到了 yan 的文件夹下,要用拼音或者英文命名。
安装依赖包
这里我使用的python3.9,可以用conda配置,
运行命令
conda create -n sovits python=3.9
这里等待 conda 安装完成后,再运行命令
conda activate sovits
配置好 python3.9的环境后进入so-vits-svc文件夹
运行命令
pip install -r requirements.txt
我在运行过程中有报错,有可能安装包的过程中有的包没有装上,我们可以在运行程序时,根据报错一步一步安装包
anaconda下载链接:https://www.anaconda.com/download/
这里有几个 conda 的常用命令
# 查看conda安装了哪些环境
conda info --env
conda info -e
#(1)创建虚拟环境,同时指定python版本
conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # 这是一行命令
#(1)创建虚拟环境,同时指定python版本
conda create -n py37 python=3.7
#(2)激活环境
activate py37
#(3) 注销or退出当前环境
conda deactivate
# (4)移除环境
conda remove -n py37 --all
至于基础模型如何下载,数据如何训练,config 文件配置请看第二篇文章