OS_Lab1_Experimental report
湖南大学信息科学与工程学院
计科 210X wolf (学号 202108010XXX)
为了实现 lab1 的目标,lab1 提供了 6 个基本练习和 1 个扩展练习,要求完成实验报告。
对实验报告的要求:
基于 markdown 格式来完成,以文本方式为主。
填写各个基本练习中要求完成的报告内容。
完成实验后,请分析 ucore_lab 中提供的参考答案,并请在实验报告中说明你的实现与参考答案的区别。
列出你认为本实验中重要的知识点,以及与对应的 OS 原理中的知识点,并 简要说明你对二者的含义,关系,差异等方面的理解(也可能出现实验中的知识点没有对应的原理知识点)。
列出你认为 OS 原理中很重要,但在实验中没有对应上的知识点。

目录
实验内容
实验环境
练习1:理解通过 make 生成执行文件的过程
(1)操作系统镜像文件 ucore.img 是如何一步一步生成的?(需要比较详细地解释 Makefile 中每一条相关命令和命令参数的含义,以及说明命令导致的结果)
(2)一个被系统认为是符合规范的硬盘主引导扇区的特征是什么?
练习2:使用qemu执行并调试lab1中的软件
(1) 从CPU加电后执行的第一条指令开始,单步跟踪BIOS的执行。
(2) 在初始化位置0x7c00设置实地址断点,测试断点正常。
(3) 从0x7c00开始跟踪代码运行,将单步跟踪反汇编得到的代码与bootasm.S和 bootblock.asm进行比较。
(4) 自己找一个bootloader或内核中的代码位置,设置断点并进行测试。
练习3:分析bootloader 进入保护模式的过程
(1) 一些准备工作
(2) 为何要开启A20
(3) 如何开启A20
(4) 初始化GDT表
(5) 如何使能与进入保护模式
(6) 进入32位模式
(7) 调用bootmain函数
练习4:分析bootloader加载ELF格式的OS的过程
(1) bootloader如何读取硬盘扇区
(2)bootloader是如何加载ELF格式的OS
(3)bootmain.c代码解读
练习5:实现函数调用堆栈跟踪函数
(1) 函数调用堆栈相关知识
(2)实现函数print_stackframe
(3)函数print_stackframe解析
(4)最后一行结果的解析
练习6:完善中断初始化和处理
(1)中断描述符表中一个表项占多少字节?其中哪几位代表中断处理代码的入口?
(2) 请编程完善kern/trap/trap.c中对中断向量表进行初始化的函数idt_init
(3) 请编程完善trap.c中的中断处理函数trap,在对时钟中断进行处理的部分填写trap函数
(4) 执行程序
扩展练习Challenge1
(1) 中断及特权保护机制
(2) Ucore如何处理中断
(3)补全代码
(4)执行程序,验证结果
扩展练习Challenge2
参考答案对比
重要知识点和对应原理
实验内容
阅读 uCore 实验项目开始文档 (uCore Lab 0),准备实验平台,熟悉实验工具。
uCore Lab 1:系统软件启动过程
- 编译运行 uCore Lab 1 的工程代码;
- 完成 uCore Lab 1 练习 1-4 的实验报告;
- 尝试实现 uCore Lab 1 练习 5-6 的编程作业;
- 思考如何实现 uCore Lab 1 扩展练习 1-2。
实验环境
- 架构:Intel x86_64 (虚拟机)
- 操作系统:Ubuntu 20.04
- 汇编器:gas (GNU Assembler) in AT&T mode
- 编译器:gcc
练习1:理解通过 make 生成执行文件的过程
列出本实验各练习中对应的 OS 原理的知识点,并说明本实验中的实现部分如何对应和体现了原理中的基本概念和关键知识点。
在此练习中,大家需要通过静态分析代码来了解:
(1)操作系统镜像文件 ucore.img 是如何一步一步生成的?(需要比较详细地解释 Makefile 中每一条相关命令和命令参数的含义,以及说明命令导致的结果)
在 labcodes/lab1/Makefile 文件中,我们可以找到创建 ucore.img 的代码段

下面将逐句解释其含义。
①UCOREIMG := $(call totarget,ucore.img)
UCOREIMG := $(call totarget,ucore.img)表示调用call函数生成UCOREIMG,
其中call为调用call函数的标记,
其中totarget可以在tools/function.mk中找到,它被定义为 otarget = $(addprefix $(BINDIR)$(SLASH),$(1))。在这之中,addprefix代表在前面加上,$(BINDIR)代表 bin,$(SLASH)代表/。
综上所述,totarget,ucore.img的意思就是在ucore.img前面加上bin/,调用 call 函数生成的 UCOREIMG 即为bin/ucore.img。
②$(UCOREIMG): $(kernel) $(bootblock)
这一行表示UCOREIMG生成所需的依赖文件为kernel和bootblock这两个文件,我们将分别解读这两个文件。
③kernel文件
- 代码理解
在makefile文件中找到注释为kernal的代码段
# kernel
KINCLUDE += kern/debug/ \
kern/driver/ \
kern/trap/ \
kern/mm/
KSRCDIR += kern/init \
kern/libs \
kern/debug \
kern/driver \
kern/trap \
kern/mm
KCFLAGS += $(addprefix -I,$(KINCLUDE))
$(call add_files_cc,$(call listf_cc,$(KSRCDIR)),kernel,$(KCFLAGS))
KOBJS = $(call read_packet,kernel libs)- 一开始的KINCLUDE和KSRCDIR处的代码将kern目录的前缀定义为kinclude和ksrcdir
- KCFLAGS += $(addprefix -I,$(KINCLUDE))表示将kinclude的目录前缀加上-I选项,提供交互模式
- $(call add_files_cc,$(call listf_cc,$(KSRCDIR)),kernel,$(KCFLAGS))生成kern目录下的.o文件,这些.o文件生成时使用的具体命令的参数和方式都差不多。
- KOBJS = $(call read_packet,kernel libs)表示使用call函数链接read_packet和kernel libs给KOBJS
# create kernel target
kernel = $(call totarget,kernel)
$(kernel): tools/kernel.ld
$(kernel): $(KOBJS)
@echo + ld $@
$(V)$(LD) $(LDFLAGS) -T tools/kernel.ld -o $@ $(KOBJS)
@$(OBJDUMP) -S $@ > $(call asmfile,kernel)
@$(OBJDUMP) -t $@ | $(SED) '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > $(call symfile,kernel)
$(call create_target,kernel)- kernel = $(call totarget,kernel)代表表示调用call函数生成kernel,实际为文件bin/kernel。
- 接下来的两行$(kernel)表示生成kernel文件需要依赖的三个文件tools、kernel.ld链接配置文件、KOBJS文件。
- @echo + ld $@中的echo表示显示内容,ld代表链接,$@代表目标文件,语句代表将下面的文件和目标文件链接起来,同时打印kernel目标文件名
- $(V)$(LD) $(LDFLAGS) -T tools/kernel.ld -o $@ $(KOBJS)代表使用kernel.ld作为连接器脚本,链接的文件有obj/libs/和obj/kernel/下的所有的obj文件生成kernel文件,关键参数为-T <scriptfile>,代表让连接器使用指定的脚本,这里即使用kernel.ld这个脚本。
- @$(OBJDUMP) -S $@ > $(call asmfile,kernel)代表使用objdump工具对kernel文件进行反汇编,便于调试,-S选项为交替显示C源码和汇编代码。
- @$(OBJDUMP) -t $@ | $(SED) '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > $(call symfile,kernel)代表使用objdump工具通过解析kernel文件从而能得到符号表。
- $(call create_target,kernel)生成kernel直接返回
- 查看make执行的命令
以上为对代码的逐字理解,我们还可以输入make "V=",较为清晰地查看生成kernel文件的具体过程:

可见,要得到一个kernel文件,需要链接以下这些文件:kernel.ld init.o stdio.o readline.o panic.o kdebug.o kmonitor.o clock.o console.o picirq.o intr.o trap.o vectors.o trapentry.o pmm.o string.o printfmt.o
其中kernel.ld已经存在,而生成kernel时,makefile中带@的前缀的指令都不是必需的,
编译选项中:
- ld表示链接
- -m表示模拟指定的连接器
- -nostdlib表示不使用标准库
- -T表示让连接器使用指定的脚本
- tools/kernel.ld是指定连接器脚本
- -o表示指定输出文件的名称
不难发现,依赖的.o文件生成时使用的具体命令的参数和方式都差不多。
以pmm.o,string.o,printf.o这三个为例。

可以总结出以下要点:
- -I<dir>如-Ikern/mm/、-Ikern/debug/等表示给搜索头文件添加路径
- -march=i686表示指定CPU架构为i686
- -fno-builtin表示除非使用__builtin_前缀,否则不优化builtin函数
- -fno-PIC表示生成位置无关代码
- -Wall表示开启所有警告
- -ggdb表示生成gdb可以使用的调试信息,便于使用qemu和gdb来进行调试
- -m32表示生成在32位环境下适用的代码,因为ucore是32位的软件
- -gstabs表示生成stabs格式的调试信息,便于monitor显示函数调用栈信息
- -nostdinc表示不使用标准库,因为OS内核是提供服务的,不依赖其它服务
- -fno-stack-protector表示不生成检测缓冲区溢出部分的代码
④查看bootblock文件
- 代码理解
在makefile文件中找到注释为bootblock的代码段
# create bootblock
bootfiles = $(call listf_cc,boot)
$(foreach f,$(bootfiles),$(call cc_compile,$(f),$(CC),$(CFLAGS) -Os -nostdinc))
bootblock = $(call totarget,bootblock)
$(bootblock): $(call toobj,$(bootfiles)) | $(call totarget,sign)
@echo + ld $@
$(V)$(LD) $(LDFLAGS) -N -e start -Ttext 0x7C00 $^ -o $(call toobj,bootblock)
@$(OBJDUMP) -S $(call objfile,bootblock) > $(call asmfile,bootblock)
@$(OBJCOPY) -S -O binary $(call objfile,bootblock) $(call outfile,bootblock)
@$(call totarget,sign) $(call outfile,bootblock) $(bootblock)
$(call create_target,bootblock)- bootfiles = $(call listf_cc,boot)中使用call调用listf_cc函数过滤对应目录下的.c和.S文件,用boot替换listf_cc里面的变量,将listf_cc的返回值赋给bootfiles
- $(foreach f,$(bootfiles),$(call cc_compile,$(f),$(CC),$(CFLAGS) -Os -nostdinc))编译bootfiles生成.o文件,其中-Os参数表示为减小代码大小而进行优化
- 上面两行代码用来生成bootasm.o,bootmain.o,实际的代码是由宏批量生成。
- bootblock = $(call totarget,bootblock)表示bootblock实际为文件bin/bootblock
- $(bootblock): $(call toobj,$(bootfiles)) | $(call totarget,sign)其中的toobj表示给输出参数加上前缀obj/,文件后缀名改为.o,语句表示bootblock依赖于obj/boot/*.o与bin/sign文件
- @echo + ld $@代表将下面的文件和目标文件链接起来,同时打印kernel目标文件名
- $(V)$(LD) $(LDFLAGS) -N -e start -Ttext 0x7C00 $^ -o $(call toobj,bootblock)表示链接所有.o文件生成obj/bootblock.o文件,其中-N代表设置代码段和数据段均可读写,-e start代表指定入口为start,-Ttext 0x7C00代表代码段开始位置为0x7C00
- @$(OBJDUMP) -S $(call objfile,bootblock) > $(call asmfile,bootblock)表示使用objdump工具对obj/bootblock.o文件进行反汇编得到obj/bootblock.asm文件,便于调试,-S选项为交替显示C源码和汇编代码。
- @$(OBJCOPY) -S -O binary $(call objfile,bootblock) $(call outfile,bootblock)表示使用objcopy工具将obj/bootblock.o拷贝到obj/bootblock.out文件,其中-S选项代表移除所有符号和重定位信息,-O binary选项代表指定输出格式为二进制
- @$(call totarget,sign) $(call outfile,bootblock) $(bootblock)表示使用bin/sign工具将之前的obj/bootblock.out用来生成bin/bootblock目标文件
- $(call create_target,bootblock)直接返回
- 查看make执行的命令
输入make "V=",查看生成bootblock文件的具体过程:

相关参数含义在之前已经展示过,这里不再赘述。这里仅仅补充之前未出现过的。
- -N代表设置代码段和数据段均可读写
- -e <entry>代表指定入口,这里是start
- -Ttext代表代码段开始位置,这里是0x7C00
从这里我们可以看出,生成bootblock文件所需要的依赖文件是bootasm.o bootmain.o sign这三个文件,我们可以分别查看生成它们三个文件的具体过程。

这里特别出现了一个新的参数。
- -Os参数表示为减小代码大小而进行优化,因为主引导扇区只有512字节,其中最后两位已被占用,最后写出的bootloader不能大于510字节。
我们可以查看sign.o是怎么生成的。

- -g代表在编译的时候加入调试信息
- -O2代表开启O2编译优化
⑤dd指令
使用make V=可以看到后续dd指令的具体操作

dd指令的作用是使用指定⼤⼩的块拷贝⼀个⽂件,并在拷贝的同时进⾏指定的转换。
if参数指定了源⽂件,of参数指定了⽬标⽂件;要从源⽂件拷贝到⽬标⽂件。
①dd if=/dev/zero of=bin/ucore.img count=10000
这条命令的作⽤是拷贝10000个全部为0的块,存放到bin⽬录下新建的ucore.img⽂件之
中;dev/zero提供⼀个零设备,⽤于提供⽆数个零。
②dd if=bin/bootblock of=bin/ucore.img conv=notrunc
这条命令的作⽤是将bootblock中的内容写⼊ucore.img之中,从第⼀个块开始写。
③dd if=bin/kernel of=bin/ucore.img seek=1 conv=notrunc
这条命令的作⽤是将kernel中的内容写⼊ucore.img之中,由于seek为1,跳过了第⼀个块,
从第⼆个快开始写。由于bootblock占⽤的空间为512个字节,可以想见,ucore.img的
10000个块中,第⼀个块存放bootblock程序,剩下的存放kernel程序。
⑥磁盘镜像相关原理
磁盘镜像是⼀个模拟的磁盘,计算机启动时需要从这里读取数据。首先,需要执
⾏BIOS程序,这个程序会对CPU进⾏⼀定程度的初始化,并从磁盘的第⼀个块(也就是主
引导扇区)⾥加载bootblock进⼊内存;bootblock程序的作用是修改CPU从实模式变为保护模式,同时加载磁盘中剩余块里的kernel内核代码。bootblock对应的是所谓加载程序,没有它就⽆法从磁盘中获取实现操作系统功能的内核代码;kernel是真正的操作系统内核程序,bootblock将它加载⼊内存后,就将控制权转移给它并开始运⾏操作系统。
(2)一个被系统认为是符合规范的硬盘主引导扇区的特征是什么?
在sign.c文件中,我们可以找到这一段核心代码

可以看到,代码中char buf[512],buf[510] = 0x55,buf[511] = 0xAA,说明一个被系统认为是符合规范的硬盘主引导扇区的特征是:
- 一共512个字节
- 倒数第二个字节是0x55,倒数第一个字节是0xAA
练习2:使用qemu执行并调试lab1中的软件
为了熟悉使用qemu和gdb进行的调试工作,我们进行如下的小练习:
- 从CPU加电后执行的第一条指令开始,单步跟踪BIOS的执行。
- 在初始化位置0x7c00设置实地址断点,测试断点正常。
- 从0x7c00开始跟踪代码运行,将单步跟踪反汇编得到的代码与bootasm.S和 bootblock.asm进行比较。
- 自己找一个bootloader或内核中的代码位置,设置断点并进行测试。
下面我将逐步操作
1.从CPU加电后执行的第一条指令开始,单步跟踪BIOS的执行。
根据附录所示,将lab1/tools/gdbinit替换为如下代码,
file bin/kernel
set architecture i8086
target remote :1234
break kern_init
continue
实际上就是加入了set architecture i8086这一行。
以上5行代码的含义实际上是
①首先进⾏gdb bin/kernel,加载内核程序(但是还不会执行)
②然后建立与qemu的连接,指定i8086架构。
③随后用b *0x7c00指定了断点。这个位置是bootloader引导加载程序的第一条指令的地址。
④设置断点后执⾏continue,就会运⾏程序并停在0x7c00处。
⑤然后用x /2i $pc,查看内存中从当前pc指令寄存器中开始的两条指令。
然后在lab1的目录下输入make debug,出现gdb调试界面之后,输入si单步跟踪BIOS的执行,通过语句x /2i $pc可以显示当前eip处的汇编指令,查看BIOS的代码。

可以看到,这时gdb停在BIOS的第一条指令处。此时如果输入si,就可以看到gdb跳转到下一地址处,按照这种方式就可以单步跟踪BIOS了。
输入x /2i $pc会显示当前eip处的汇编指令。例如输入x /2i 0xffff0即可查看0xffff0处以及往下的一行代码。

2.在初始化位置0x7c00设置实地址断点,测试断点正常。
设置断点有多种方式,在lab1/tools/gdbinit文件中加入b *0x7c00或在gdb输入框输入b *0x7c00,都可以在0x7c00设置断点。我这里选择第二种方式。

可以发现,输入c使程序继续运行后,程序在0x7c00处停下,断点正常。
3.从0x7c00开始跟踪代码运行,将单步跟踪反汇编得到的代码与bootasm.S和 bootblock.asm进行比较。
可以单步跟踪,但这里我采取直接查看地址的方式。

可以查看到从0x7c00开始的10行汇编代码

以下为bootasm.S

以下为bootblock.asm

可以发现,反汇编得到的代码与bootasm.S和bootblock.asm基本相同。
4.自己找一个bootloader或内核中的代码位置,设置断点并进行测试。
我在0x7c04,0x7c06,0x7c08三处设置断点,进行测试。

练习3:分析bootloader 进入保护模式的过程
BIOS将通过读取硬盘主引导扇区到内存,并转跳到对应内存中的位置执行bootloader。请分析bootloader是如何完成从实模式进入保护模式的。
提示:需要阅读小节“保护模式和分段机制”和lab1/boot/bootasm.S源码,了解如何从实模式切换到保护模式,需要了解:
- 为何开启A20,以及如何开启A20
- 如何初始化GDT表
- 如何使能和进入保护模式
在结合提示以及阅读了lab1/boot/bootasm.S源码以及注释后。我们大概能够知道bootloader是通过修改A20地址线来完成从实模式进入保护模式的。接下来我将具体地呈现这一过程以及解答上述的一些疑惑。
1.一些准备工作

2.为何要开启A20
或许这个问题我们可以从附录中窥见一点答案。
Intel早期的8086 CPU提供了20根地址线,可寻址空间范围即0~2^20(00000H~FFFFFH)的 1MB内存空间。但8086的数据处理位宽位16位,无法直接寻址1MB内存空间,所以8086提供了段地址加偏移地址的地址转换机制。
PC机的寻址结构超过了20位地址线的物理寻址能力。所以当寻址到超过1MB的内存时,会发生“回卷”(不会发生异常)。但下一代的基于Intel 80286 CPU的PC AT计算机系统提供了24根地址线,这样CPU的寻址范围变为 2^24=16M,同时也提供了保护模式,可以访问到1MB以上的内存了,此时如果遇到“寻址超过1MB”的情况,系统不会再“回卷”了,这就造成了向下不兼容。
为了保持完全的向下兼容性,IBM决定在PC AT计算机系统上加个硬件逻辑,来模仿以上的回绕特征,于是出现了A20 Gate。他们的方法就是把A20地址线控制和键盘控制器的一个输出进行AND操作,这样来控制A20地址线的打开(使能)和关闭(屏蔽/禁止)。
一开始时A20地址线控制是被屏蔽的(总为0),直到系统软件通过一定的IO操作去打开它(参看bootasm.S)。
很显然,在实模式下要访问高端内存区,这个开关必须打开,在保护模式下,由于使用32位地址线,如果A20恒等于0,那么系统只能访问奇数兆的内存,即只能访问0--1M、2-3M、4-5M......,这样无法有效访问所有可用内存。所以在保护模式下,这个开关也必须打开。
为了与最早的PC机向后兼容,物理地址行20被限制在低位,因此高于1MB的地址默认为零。此代码将撤消此操作,通过打开A20,将键盘控制器上的A20线置于高电位,就能使全部32条地址线可用,可以访问4G的内存空间。
总结来说,如果不打开A20,就会保留回卷机制,禁止访问大于1MB的空间,从而实现向下兼容,保留在实模式;而打开A20,就会撤销回卷机制,允许访问大于1MB的空间。
为了能访问更多的空间,打开A20是一个必须的操作。
3.如何开启A20
在这之前,我们需要了解8042芯片的一些属性。
8042键盘控制器的IO端口是0x60~0x6f,实际上IBM PC/AT使用的只有0x60和0x64两个端口(0x61、0x62和0x63用于与XT兼容目的)。8042通过这些端口给键盘控制器或键盘发送命令或读取状态。输出端口P2用于特定目的。位0(P20引脚)用于实现CPU复位操作,位1(P21引脚)用户控制A20信号线的开启与否。系统向输入缓冲(端口0x64)写入一个字节,即发送一个键盘控制器命令。可以带一个参数。参数是通过0x60端口发送的。 命令的返回值也从端口 0x60去读。
8042有2个端口地址与4个功能
- 读60h端口,读output buffer
- 写60h端口,写input buffer
- 读64h端口,读Status Register
- 操作Control Register,首先要向64h端口写一个命令(20h为读命令,60h为写命令),然后根据命令从60h端口读出Control Register的数据或者向60h端口写入Control Register的数据(64h端口还可以接受许多其它的命令)。
8042有4个寄存器
- 1个8-bit长的Input buffer;Write-Only;
- 1个8-bit长的Output buffer; Read-Only;
- 1个8-bit长的Status Register;Read-Only;
- 1个8-bit长的Control Register;Read/Write
程序可通过60h和64h端口操作寄存器。
- 直接读60h端口,可以获得output buffer寄存器中的内容;
- 直接写60h端口,可以写⼊input buffer寄存器内容。
- 直接读64h端口,可以读Status Register寄存器的内容。
对Outport Port的操作及端口定义
- 读Output Port:向64h发送0d0h命令,然后从60h读取Output Port的内容
- 写Output Port:向64h发送0d1h命令,然后向60h写入Output Port的数据
- 禁止键盘操作命令:向64h发送0adh
- 打开键盘操作命令:向64h发送0aeh
理论上讲,我们只要操作8042芯片的输出端口(64h)的bit 1,就可以控制A20 Gate,但实际上,当你准备向8042的输入缓冲区里写数据时,可能里面还有其它数据没有处理,所以,我们要首先禁止键盘操作,同时等待数据缓冲区中没有数据以后,才能真正地去操作8042打开或者关闭A20 Gate。打开A20 Gate的具体步骤大致如下(参考bootasm.S):
- 等待8042 Input buffer为空;
- 发送Write 8042 Output Port (P2)命令到8042 Input buffer;
- 等待8042 Input buffer为空;
- 将8042 Output Port(P2)得到字节的第2位置1,然后写入8042 Input buffer;
下面的代码分为两部分,两部分代码都要通过读0x64端口的第2位确保8042的输入缓冲区为空后再进行操作。

在seta20.1中,首先把数据0xd1写入端口0x64,发送消息给CPU准备往8042芯片的P2端口写数据;
在seta20.2中,首先把数据0xdf写入端口0x60,从而将8042芯片的P2端口的A20地址线设置为1。
4.初始化GDT表
在上一步,我们开启了A20并切换了保护模式,接下来需要启动分段机制。

在kern/mm/pmm.c文件中可以找到gdt的初始化函数,通过这段代码完成gdt的初始化。

而在bootasm.S文件中,可以看到。

其中SEG_ASM可以在asm.h中找到,

可以看到,SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff)和SEG_ASM(STA_W, 0x0, 0xffffffff)把数据段和代码段的base设为0,lim即limit设置为4G,数据段可读可执行,代码段可写,这样就可以使逻辑地址对应于线性地址。
因为一个简单的GDT表和其描述符已经静态储存在引导区中,所以直接使用lgdt命令初始化后,将gdt的desc段表示内容加载到gdt就行。也就是代码lgdt gdtdesc
5.如何使能与进入保护模式
将cr0寄存器的PE位置即最低位设置为1,就可以打开使能位,进入保护模式。
6.进入32位模式
接着,通过长跳转使cs的基地址得到更新,将cs修改为32位段寄存器,此时CPU进入32位模式。设置段寄存器ds、es、fs、gs、ss,并建立堆栈的帧指针和栈指针。

7.调用bootmain函数
调用bootmain函数,bootloader从实模式进入保护模式。bootmain函数将从磁盘中读取kernel内核代码,进行下一步的操作。
练习4:分析bootloader加载ELF格式的OS的过程
通过阅读bootmain.c,了解bootloader如何加载ELF文件。通过分析源代码和通过qemu来运行并调试bootloader&OS,
- bootloader如何读取硬盘扇区的?
- bootloader是如何加载ELF格式的OS?
提示:可阅读“硬盘访问概述”,“ELF执行文件格式概述”这两小节。
由提示,我们不难发现,其实bootloadder加载ELF格式的OS的过程大致应该分为读取磁盘扇区、ELF格式加载这两个过程。我们将逐步渐进讨论。
(1)bootloader如何读取硬盘扇区
bootloader让CPU进入保护模式后,下一步的工作就是从硬盘上加载并运行OS。考虑到实现的简单性,bootloader的访问硬盘都是LBA模式的PIO(Program IO)方式,即所有的IO操作是通过CPU访问硬盘的IO地址寄存器完成。
一般主板有2个IDE通道,每个通道可以接2个IDE硬盘。访问第一个硬盘的扇区可设置IO地址寄存器0x1f0-0x1f7实现的,具体参数见下表。一般第一个IDE通道通过访问IO地址0x1f0-0x1f7来实现,第二个IDE通道通过访问0x170-0x17f实现。每个通道的主从盘的选择通过第6个IO偏移地址寄存器来设置。
注意:第6位:为1=LBA模式;0 = CHS模式 第7位和第5位必须为1
以下为磁盘IO地址和对应功能
| IO地址 | 功能 |
| 0x1f0 | 读数据,当0x1f7不为忙状态时,可以读。 |
| 0x1f2 | 要读写的扇区数,每次读写前,你需要表明你要读写几个扇区。最小是1个扇区 |
| 0x1f3 | 如果是LBA模式,就是LBA参数的0-7位 |
| 0x1f4 | 如果是LBA模式,就是LBA参数的8-15位 |
| 0x1f5 | 如果是LBA模式,就是LBA参数的16-23位 |
| 0x1f6 | 第0~3位:如果是LBA模式就是24-27位 第4位:为0主盘;为1从盘 |
| 0x1f7 | 状态和命令寄存器。操作时先给命令,再读取,如果不是忙状态就从0x1f0端口读数据 |
当前 硬盘数据是储存到硬盘扇区中,一个扇区大小为512字节。读一个扇区的流程(可参看boot/bootmain.c中的readsect函数实现)大致如下:
- 等待磁盘准备好
- 发出读取扇区的命令
- 等待磁盘准备好
- 把磁盘扇区数据读到指定内存
(2)bootloader是如何加载ELF格式的OS
在阅读材料“ELF执行文件格式概述”中,表明了bootloader是如何加载ELF格式的OS。
ELF header在文件开始处描述了整个文件的组织。ELF的文件头包含整个执行文件的控制结构,其定义在elf.h中:

program header描述与程序执行直接相关的目标文件结构信息,用来在文件中定位各个段的映像,同时包含其他一些用来为程序创建进程映像所必需的信息。可执行文件的程序头部是一个program header结构的数组, 每个结构描述了一个段或者系统准备程序执行所必需的其它信息。
目标文件的 “段” 包含一个或者多个 “节区”(section) ,也就是“段内容(Segment Contents)” 。程序头部仅对于可执行文件和共享目标文件有意义。可执行目标文件在ELF头部的e_phentsize和e_phnum成员中给出其自身程序头部的大小。程序头部的数据结构如下表所示:

根据elfhdr和proghdr的结构描述,bootloader就可以完成对ELF格式的ucore操作系统的加载过程(参见boot/bootmain.c中的bootmain函数)。
(3)bootmain.c代码解读
①宏定义
#define SECTSIZE 512
#define ELFHDR ((struct elfhdr *)0x10000) // scratch space
②waitdisk()函数:等待磁盘就绪
这段代码实际上不断查询0x1F7寄存器的最高两位,当最高两位为01,即磁盘空闲时,才允许程序继续运行。
③readsect函数、

这个函数的作用是从设备的第secno个扇区的文章读取数据到dst内存中。
④readseg函数

调用readsect函数实现从设备中读取任意长度内容。
⑤bootmain函数

该函数主要完成以下任务
1、首先从磁盘的第一个扇区中将ELF文件bin/kernel的内容读取出来
代码:readseg((uintptr_t)ELFHDR, SECTSIZE * 8, 0);
2、接下来检验ELF头部的e_magic变量判断是不是ELF文件
if (ELFHDR->e_magic != ELF_MAGIC) {
goto bad;若不是,跳转至后面处理
}
3、读取ELF头部的e_phoff变量得到描述表的头地址。表示ELF文件应该加载到内存的什么位置
代码:struct proghdr *ph, *eph;
ph = (struct proghdr *)((uintptr_t)ELFHDR + ELFHDR->e_phoff);
4、读取ELF头部的e_phnum变量,得到描述表的元素数目。
代码:eph = ph + ELFHDR->e_phnum;
5、按照描述表将ELF文件中数据按照偏移、虚拟地址、长度等信息载入内存
for (; ph < eph; ph ++) {
readseg(ph->p_va & 0xFFFFFF, ph->p_memsz, ph->p_offset);
}
6、通过ELF头部的e_entry变量储存的入口信息,找到内核的入口地址,并开始执行内核代码
((void (*)(void))(ELFHDR->e_entry & 0xFFFFFF))();
⑥总结
总结来说,bootloader加载ELF格式的OS的大致过程是先等待磁盘准备就绪,然后先读取ELF的头部判断是否合法,接着读取ELF内存位置的描述表,然后按照描述表的内容,将ELF文件中的数据载入内存,根据ELF头部的入口信息找到内核入口执行内核代码。
练习5:实现函数调用堆栈跟踪函数
这一题我们需要先复习函数调用时栈的变化,并结合该部分知识完成代码补全
1.函数调用堆栈相关知识
为了实现函数堆栈跟踪函数,首先需要比较清楚地掌握函数调用时栈相关的变化。
(这一部分的知识看可以参考CS计算机系统)
栈帧寄存器是ebp,栈顶寄存器是esp。栈是向下增长的,每次放⼊数据,esp里的值都会减小。
①调用
假设在main函数⾥通过call指令调用add函数,则main会先在自己的栈帧中保存即将传递给过程的参数以及返回地址(call指令负责将返回地址保存到栈之中)。
在call之后,add会首先保存main的ebp值,其地址比栈中保存返回地址的位置更⼩;然后把此时esp的值赋值给ebp,这样⼀来ebp就变成了add函数的栈帧,它直接指向main函数的旧ebp值,它加4的结果就是返回地址,再往上就是函数参数。
接下来把esp进⾏自减并对齐,就可以开辟属于add函数的栈空间。
②返回
等函数执行完毕,先把返回值保存在eax寄存器之中,再给esp赋值此时ebp的值使得add函数的栈顶指针和栈帧指针一致(即将esp指针撤回至ebp的位置);接着弹出栈顶的旧ebp值给ebp寄存器,恢复main函数的栈帧;
之后,ret指令把新的栈顶元素也就是保存的返回地址交给eip,从而转交回控制权。
③地址关系
对于被调用者而言,[ebp]处为保存的调用者的旧ebp值;[ebp+4]处为返回地址,[ebp+8]处为第⼀个参数值(最后⼀个⼊栈的参数值,此处假设其占⽤4字节内存)。
由于ebp中的地址处总是"上⼀层函数调用时的ebp值”,⽽在每⼀层函数调用中,都能通过当时的ebp值"向上(栈底方向)“能获取返回地址、参数值,“向下(栈顶方向)"能获取函数局部变量值。如此形成递归,直至到达栈底。
(2)实现函数print_stackframe
我们需要在lab1中完成kdebug.c中函数print_stackframe的实现,可以通过函数print_stackframe来跟踪函数调用堆栈中记录的返回地址。
打开/labcodes/lab1/kern/debug/kdebug.c,关注到待补全部分。按照注释信息,比较容易地完成待补全部分的代码。

根据附录指示,如果能够正确实现此函数,可在lab1中执行 “make qemu”后,在qemu模拟器中得到类似如下的输出:

在本地进行make qemu后,得到如下所示输出。

可以发现,其输出与给定参考大致一致。则代码补全正确。
(3)函数print_stackframe解析
从注释中我们可以发现,内联函数read_ebp()可以告诉我们当前ebp的值。而非内联函数read_eip()也很有用,它可以读取当前eip的值,因为在调用此函数时,read_eip()可以轻松地从堆栈中读取调用⽅的eip。因此前两行的作用就是读取初始的ebp与eip。
接着我们从第1层遍历到STACKFRAME_DEPTH层,STACKFRAME_DEPTH这表示我们需要回溯的调用嵌套个数。
对于每一次遍历,我们首先打印该层的ebp与eip的值,然后通过地址来寻找调用者向本层传递的参数值信息。
这里需要注意,ebp指针指向的位置是旧的ebp值,(ebp)+4指向的位置是返回值,(ebp)+8指向的位置开始才是真正的参数。
由于unint32_t*类型指针占据4个字节,所以(unint32_t *)ebp+2对应的地址值就是(ebp)+8,这里涉及到指针的加法,指针自增加上的是该单个类型数据的字节数。
通过(unint32_t *)ebp+2将call_args指针指向第一个参数的地址。从这个地址开始以及往后的三个,也就是call_args[0], call_args[1], call_args[2], call_args[3]这四个分别表示(ebp)+8,(ebp)+12,(ebp)+16,(ebp)+20,这就是来自调用者传递的4个参数。
接着按照注释要求,调⽤print_debuginfo(eip-1),打印相关信息。
最后是回溯一步,将此时的ebp值与eip值回溯到本层的调用者,相当于是上溯一层。这样可以实现递归的具体实现过程。
(4)最后一行结果的解析
附录要求我们解释最后一行的输出结果。
ebp:0x00007bf8 eip:0x00007d74 args:0xc031fcfa 0xc08ed88e 0x64e4d08e 0xfa7502a8
<unknow>: -- 0x00007d73 --
可以看到,最后⼀⾏的ebp值最大,意味着它是最初的函数,是刚刚一切函数嵌套调用的源头。结合前面的bootloader相关问题的探讨,若不考虑BIOS程序段,在保护模式中第一个执行的函数是bootloader。bootloader程序是从从0x7c00开始的,在0x7d70处使用call指令进⾏了第⼀次嵌套调用,call指令将下一条指令的地址也就是0x7d72保存在栈中。而这恰好就是我们这里最后一行所示调用的源头。
练习6:完善中断初始化和处理
请完成编码工作和回答如下问题:
- 中断描述符表(也可简称为保护模式下的中断向量表)中一个表项占多少字节?其中哪几位代表中断处理代码的入口?
- 请编程完善kern/trap/trap.c中对中断向量表进行初始化的函数idt_init。在idt_init函数中,依次对所有中断入口进行初始化。使用mmu.h中的SETGATE宏,填充idt数组内容。每个中断的入口由tools/vectors.c生成,使用trap.c中声明的vectors数组即可。
- 请编程完善trap.c中的中断处理函数trap,在对时钟中断进行处理的部分填写trap函数中处理时钟中断的部分,使操作系统每遇到100次时钟中断后,调用print_ticks子程序,向屏幕上打印一行文字”100 ticks”。
【注意】
除了系统调用中断(T_SYSCALL)使用陷阱门描述符且权限为用户态权限以外,其它中断均使用特权级(DPL)为0的中断门描述符,权限为内核态权限;而ucore的应用程序处于特权级3,需要采用int 0x80指令操作(这种方式称为软中断,软件中断,Tra中断,在lab5会碰到)来发出系统调用请求,并要能实现从特权级3到特权级0的转换,所以系统调用中断(T_SYSCALL)所对应的中断门描述符中的特权级(DPL)需要设置为3。
提示:可阅读小节“中断与异常”。
(1)中断描述符表中一个表项占多少字节?其中哪几位代表中断处理代码的入口?
在中断向量表中,一个表项会占8个字节,其中第0-1和第6-7字节组合在一起表示偏移量,第2~3字节表示段选择的编号,在选择的段中,计算偏移量后得到的位置,就是中断处理代码的入口。

此外,可以通过查看下列文件中lab1/kern/mm/mmu.h
比较清晰地看出来。

(2)请编程完善kern/trap/trap.c中对中断向量表进行初始化的函数idt_init
根据注释完成代码。
首先关注到第一段注释:
“每个中断服务例程(ISR)的⼊口地址在哪里?(只有找到中断地址,才能初始化IDT
表)所有ISR的地址都存储在_vectors中。uintptr_t___vectors[ ]在哪里?__vectors[ ]位于kern/trap/vector.S中,由tools/vector.c生成(在lab1中尝试“make”命令,然后在kern/trap DIR中找到vector.S)您可以使用“extern uintptr_t ____vectors[ ];”来定义此extern变量(外部变量,意味着这个数组是其他文件夹里的,只不过本⽂件中的函数需要使用它来初始化idt表。),该变量将在后头用到。”
从这一段注释里,我们可以看到首先我们需要定义一个extern uintptr_t类型变量__vectors[],用来存放256个在vectors.S定义的中断处理例程的入口地址。
接下来关注到第二段注释:
“现在您应该在中断描述符表(IDT)中设置ISR(各个中断门)条目。你能在这个文件中看到idt[256]吗?是的,这个数组就是IDT中断描述符表(只要给这个数组赋值就可以初始化IDT表了)!您可以使用SETGATE宏设置IDT的各个条目。”
使用SETGATE宏,通过循环语句对中断描述符表中的每一个表项进行设置,其中SETGATE宏可以在mmu.h中找到:#define SETGATE(gate, istrap, sel, off, dpl)
其参数含义如下
- 宏的参数gate代表选择的idt数组的项,是处理函数的入口地址
- 参数istrap为1时代表系统段,为0时代表中断门
- 参数sel是中断处理函数的段选择子,GD_KTEXT代表是.text段
- 参数off是__vectors数组内容,在vector.S中,有256个中断处理例程
- 参数dpl是优先级,宏定义DPL_KERNEL是0代表内核级,宏定义DPL_USER是3代表用户级。
- 宏定义T_SWITCH_TOK是用于用户态切换到内核态的中断号。
故这里一一对应即可完成补全。
最后是第三段注释:
“设置IDT的内容后,您将使用“lidt”指令让CPU知道IDT在哪里。你不知道这个说明的意思吗?只需谷歌⼀下!并查看libs/x86.h以了解更多信息。注意:lidt的参数是idt_pd。试着找到它!”
由于lidt的参数为指针,故这里需要以指针的形式传入。
最终完成的代码如下。

其中,较为关键的是最后一行的DPL_USER,表示在用户态下就可以完成对于内核态的访问。
(3)请编程完善trap.c中的中断处理函数trap,在对时钟中断进行处理的部分填写trap函数
这一问主要是向终端输出一些信息。
先看注释:
“(1)计时器中断后,应使⽤全局变量(增加它)记录此事件,如kern/driver/clock.c中的ticks *(2)每个TICK_NUM周期,您都可以使用⼀个函数打印⼀些信息,例如使用 print_ticks()函数”
故只要写一个ticks变量自增以及满100输出一次即可。
代码如下。

(4)执行程序
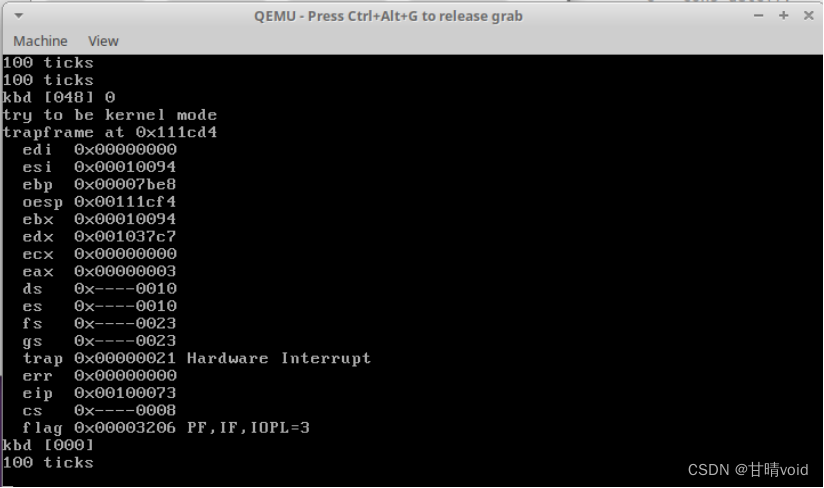
在完成(2)(3)段代码之后,在lab1目录下执行程序,即可看到每100次时钟中断终端上输出一行。执行截图如下。

如图是我快速按下asdfg的终端显示

可以看到,大概每1秒输出一次“100 ticks”文字,而且按下的键也会在屏幕上显示。
扩展练习Challenge1
扩展proj4,增加syscall功能,即增加一用户态函数(可执行一特定系统调用:获得时钟计数值),当内核初始完毕后,可从内核态返回到用户态的函数,而用户态的函数又通过系统调用得到内核态的服务。
提示:
规范一下 challenge 的流程。
kern_init 调用 switch_test,该函数如下:

switchto* 函数建议通过 中断处理的方式实现。主要要完成的代码是在 trap 里面处理 T_SWITCH_TO* 中断,并设置好返回的状态。
在 lab1 里面完成代码以后,执行 make grade 应该能够评测结果是否正确。
(1)中断及特权保护机制
中断发生后,首先获取中断向量;然后,以中断向量为索引,去中断描述符表IDT(IDT的位置和⼤⼩存放在寄存器IDTR中,可以从这个寄存器器读出IDT处于什么地址)中获得中断描述符(中断描述符分为段选择子、段偏移量两个部分,其中段选择子部分含有⼀个RPL请求特权级。注意,当前执行代码有⼀个CPL当前程序特权级,存放在特定寄存器中),依据中断描述符的段选择子找到GDT中的段描述符(里面有段的访问特权级DPL),而后可以根据段基址和段偏移量,获得中断服务例程的位置,并跳转到那里执行。
特权级的实现:
特权级在ucore中分为0和3,3表⽰用户态的特权级,0表示内核态的特权级;只能被内核态访问的数据不能被用户态的特权级访问,内核态特权级可以访问任意特权级的数据,因为数字越⼩特权级的级别越高。
每一个段都有自己专有的特权级称为DPL,它被保存在GDT段表的段描述符中,表示访问这个段所需的最低特权级(只有数字值⼩于等于它的、特权级更高的特权级才能访问);
每一段正在执⾏的代码有自己的特权级CPL,保存在CS和SS的第0位和第1位上,表⽰代码所在的特权级——当程序转移到不同特权级的代码段时,CPL将被改变,表示程序本身的特权级在用户态和内核态之间切换。
中断描述符的段选择⼦中含有的特权级RPL是请求特权级,表示当前代码段发出了⼀个特定特权级的请求。⽐如说,⼀个CPL为3的⽤户态的程序,需要执行软中断,所以发出了一个内核态的请求,则其RPL就将是0。一般,访问段时,会取CPL和DPL中较低的特权级⽤来与DPL进行比对,从而判断能否访问特定段。
但在系统调用中,系统调用的过程发生了特权级的变化,为了执行系统调用,CPL需要从用户态升级为内核态,数字由3变成0。
内核态和用户态使用不同的栈来执操作,因此特权级切换的本质就是使用内核态的栈⽽不是用户态的栈,同时保存用户态栈的相关信息便于在中断完成后恢复到用户。
CPU会根据CPL和DPL判断需要进⾏特权级转换(从⽤户态升级为内核态)。⼀旦发⽣,需要从TR寄存器中获得当前程序的TSS信息的地址,从TSS信息中获得内核栈地址,然后将⽤户态的栈地址信息(SS和ESP值)保存到内核栈中。中断打断了⽤户态的程序,所以还要把⽤户态程序的eflags、cs、eip,乃⾄于可能存在的errorCode信息都压⼊内核栈之中。
中断结束后,使用iret指令可以弹出内核栈中的eflags;如果中断时有特权级切换,说明内核栈中还有用户栈的SS和ESP信息,iret会把它们也弹出,以便恢复到⽤户态。
(2)Ucore如何处理中断
在lab1的代码中,vector.S⽂件中保存了各个中断向量(中断号)所对应的中断服务例程入口。以部分中断向量(实际上这里有很多,我们只截取部分示例)的相应处理⽰意如下:

可以看出,上述中断向量对应的操作,是向栈中压⼊0,然后压⼊中断号,接着跳转到
__alltraps(位于trapentry.S⽂件中)中断处理函数,其内容如下:

从注释可以看出,它专门处理从vector.S发出的中断请求。为了执行中断,他会将诸多寄存器保存在栈中,如ds到gs;接着,直接调用call指令,使用trap函数继续进⾏处理。
trap函数进⼀步调用trap_dispatch函数,它在练习6中被补充,从⽽可以对时钟ticks计数和输出相应信息。实际上,trap_dispatch函数会根据tf中保存的中断信息(特别是中断号)来进⾏真正的中断服务。
中断服务结束后,会依赖tp中保存的环境信息恢复到中断前的状态。因此,实现扩展练习1的⽅式就是在中断响应函数trap_dispatch中响应关于申请状态切换的中断请求,响应方式就是修改tp信息,也就是修改中断结束后需要赖以恢复的状态信息。
操作系统加载后,会首先执行kern_init函数进⾏内核初始化。使这个函数得以调用 switch_test。这个函数的作用,是先执行switch_to_user(); 切换到用户态,然后执行 switch_to_kernel();切换到内核态。实现这两个函数,本质上就是让它们发出中断申请——分别用于申请切换为用户态和申请切换为内核态。
(3)补全代码
首先,根据注释,在init.c文件的kern_init()函数里面,将原先被注释掉的代码lab1_switch_test()去掉注释,变成可以执行的语句。这一段十分重要,如果没有去掉注释,会造成最后的make grade不通过。
关注到下面的这两个函数是待实现的。函数及截图如下。
static void lab1_switch_to_user(void)和static void lab1_switch_to_kernel(void)

接下来我将分别讲解。
①static void lab1_switch_to_user(void)函数
对于static void lab1_switch_to_user(void),这个函数的功能是从内核态返回到用户态,需要调用T_SWITCH_TOU中断,在函数中使用内联汇编实现:

在调用中断之前首先需要使用语句"pushl %%ss \n""和pushl %%esp \n"提前将ss、esp压入栈,因为当切换优先级时,中断返回时iret指令会额外弹出ss和esp两位,但使用"int %0 \n"语句调用T_SWITCH_TOU中断时并不会产生特权级的切换,因此不用压入ss和esp,所以要先将栈压两位,预先留出空间,在中断返回后使用"movl %%ebp, %%esp" : : "i"(T_SWITCH_TOU)语句恢复栈指针,修复esp。
②static void lab1_switch_to_kernal(void)函数
对于函数static void lab1_switch_to_kernal(void),实现的功能是从用户态切换回内核态,需要调用T_SWITCH_TOK中断,在函数中使用内联汇编实现:

从用户态切换到内核态时,由于用户态使用"int %0 \n"语句调用T_SWITCH_TOU中断时会自动切换到内核态,不会另外弹出ss、esp两位,中断返回时,esp仍在堆栈中,在中断返回后要使用 "movl %%ebp, %%esp \n" : : "i"(T_SWITCH_TOK)语句恢复栈指针,修复esp。
③case T_SWITCH_TOU与case T_SWITCH_TOK
在trap.c文件中,找到trap_dispatch()函数中等待完成的case T_SWITCH_TOU和case T_SWITCH_TOK,先定义一个struct trapframe类型的变量switchktou和一个struct trapframe *类型的指针变量switchutok。

(4)执行程序,验证结果
实现后,在终端使用make grade检验实现效果,得分如下。

扩展练习Challenge2
用键盘实现用户模式内核模式切换。具体目标是:“键盘输入3时切换到用户模式,键盘输入0时切换到内核模式”。 基本思路是借鉴软中断(syscall功能)的代码,并且把trap.c中软中断处理的设置语句拿过来。
注意:
1.关于调试工具,不建议用lab1_print_cur_status()来显示,要注意到寄存器的值要在中断完成后tranentry.S里面iret结束的时候才写回,所以再trap.c里面不好观察,建议用print_trapframe(tf)
2.关于内联汇编,最开始调试的时候,参数容易出现错误,可能的错误代码如下

要去掉参数int %0 \n这一行
3.软中断是利用了临时栈来处理的,所以有压栈和出栈的汇编语句。硬件中断本身就在内核态了,直接处理就可以了。
首先在trap.c文件中找到与键盘中断返回有关的代码,即case IRQ_OFFSET + IRQ_KBD,在其中加入一个感知键盘输入数组的条件判断语句,如果输入是3则进入用户模式,如果输入是0则进入内核模式。因为在内核态进入到用户态的过程中,iret指令中断返回时会额外弹出两位,所以为了保护堆栈上的信息,可以将trapframe的地址保存到一个变量中,当键盘输入3准备从内核模式切换到用户模式时,可以可以从这个变量中获取正确的trapframe的地址,恢复栈指针,修复esp。
而因为用户态进入到内核态的过程中,因为iret指令调用中断时是系统默认的从权限较低的模式转换到权限较高的模式,所以中断时会自动切换到内核态,堆栈不会再弹出另外的两位,所以当键盘输入0准备从用户模式切换到内核模式,实现中断返回时,原来的esp还在堆栈中,所以需要把ebp的值传送给esp,恢复栈指针,修复esp。
代码实现如下。

下面进行验证。
在内核态下输入“3”。可以发现程序执行尝试返回用户态。

在用户态下输入“3”,可以发现由于已经在用户态,不作切换。

在用户态下输入“0”,可以发现程序执行尝试切换至内核态。
以上,可以较为清晰地展示功能实现。
参考答案对比
练习1:
在实验报告中采取的思路是从⽣成ucore.img的makefile命令倒推实现过程,逐步展示,条理和层次不像参考答案中那么清晰;分别从makefile依赖的两个关键的文件kernal与bootblock分析了生成文件的指令部分,并对dd指令与参数部分进行了更加详细一些的分析。
练习2:
本题与参考答案的实现区别不是很大,从以下四个角度进行分析。从CPU加电后执行的第一条指令开始,单步跟踪BIOS的执行。在初始化位置0x7c00设置实地址断点,测试断点正常。从0x7c00开始跟踪代码运行,将单步跟踪反汇编得到的代码与bootasm.S和 bootblock.asm进行比较。自己找一个bootloader或内核中的代码位置,设置断点并进行测试。
练习3:
介绍思路和顺序和答案基本一致,但是补充了一些对应的原理知识点,并对各条指令的内涵做出了自己能基本理解的详细解释。如为什么要开启A20以及如何开启A20的部分。再如调用bootmain函数的部分,都有较为详细的说明。
练习4:
结合实验指导书提供的资料、具体的代码注释信息,对每一部分的原理和实现机制做出了比参考答案详细得多的说明。如bootloader如何读取硬盘扇区以及ELF格式的OS,再如bootmain.c的代码的解读和其中的多个函数(waitdisk、readsect、readseg、bootmain等)的实现都有更为详细的说明。
练习5:
实现机制和参考答案思路基本⼀致。此外,对栈机制的使用做出了自己的解释和详细说明。特别是对于c指针加法的说明以及传递变量地址的说明。
练习6:
进行中断初始化的⽅法和参考答案基本一致,主要增加了自己对相应中断原理的理解并做出注释。对于编程完善的部分也有较为独到的见解。
扩展练习1
基本和参考答案⼀致,通过设置tf信息来完成状态切换,同时用⾃学的相关知识进行了理解和剖析,参考了学堂在线教学视频的指导。在补全代码的部分有较为清晰的说明。
扩展练习2
参考答案未提供参考,依靠自学交流以及CSDN学习完成。由于较为简单,没有过多的说明与解释。
重要知识点和对应原理
1、实验中的重要知识点
- makefile书写格式和实现⽅法
- GCC基本内联汇编语法
- linux gdb调试基础
- BIOS启动过程
- bootloader启动过程
- 关于保护模式的硬件实现
- 分段机制的实现原理(含特权级)
- 硬盘访问实现机制
- ELF⽂件格式概述
- 操作系统基本启动⽅式
- 函数堆栈调用的内部原理
- 中断机制的实现(含特权级)
2、对应的OS原理知识点
- 虚拟内存的实现
- 分段保护机制
- 过程调用与中断实现
- 内存访问机制
3、⼆者关系:
- 本实验设计的知识是对OS原理的具体实现,在细节上很复杂。
4、未对应的知识点
- 进程调度管理
- 分页管理与页调度
- 并发实现机制
参考文献
https://blog.csdn.net/StuGeek/article/details/118708567