文章目录
- 一、Sqoop安装与使用
- 1、简介
- 2、Sqoop安装
- 3、Sqoop实例
- 3.1 Mysql导入Hadoop
- 3.2 Hadoop导出到Mysql
- 二、DataX概述与入门
- 1、DataX概述
- 1.1 简介
- 1.2 框架设计
- 1.3 运行原理
- 2、DataX与 Sqoop 的对比
- 3、快速入门
- 三、DataX常用入门案例
- 1、从stream 流读取数据并打印到控制台
- 2、读取 MySQL 中的数据存放到 HDFS
- 2.1 查看官方模板
- 2.2 数据准备与配置
- 2.3 执行与结果
- 3、读取 HDFS 数据写入 MySQL
- 4、其他数据库
- 四、DataX源码分析
- 1、总体执行流程
- 2、程序入口
- 3、Task 切分逻辑
- 4、调度
- 5、数据传输
- 五、DataX 使用优化
- 1、关键参数
- 2、优化 1:提升每个 channel 的速度
- 3、优化 2:提升 DataX Job 内 Channel 并发数
- 3.1 配置全局 Byte 限速以及单 Channel Byte 限速
- 3.2 配置全局 Record 限速以及单 Channel Record 限速
- 3.3 直接配置 Channel 个数
- 4、优化 3:提高 JVM 堆内存
一、Sqoop安装与使用
1、简介
Sqoop全称是 Apache Sqoop(现已经抛弃),是一个开源工具,能够将数据从数据存储空间(数据仓库,系统文档存储空间,关系型数据库)导入 Hadoop 的 HDFS或列式数据库HBase,供 MapReduce 分析数据使用。数据传输的过程大部分是通过 MapReduce 过程来实现,只需要依赖数据库的Schema信息Sqoop所执行的操作是并行的,数据传输性能高,具备较好的容错性,并且能够自动转换数据类型。
Sqoop是一个为高效传输海量数据而设计的工具,一般用在从关系型数据库同步数据到非关系型数据库中。Sqoop专门是为大数据集设计的。Sqoop支持增量更新,将新记录添加到最近一次的导出的数据源上,或者指定上次修改的时间戳。
2、Sqoop安装
https://sqoop.apache.org/
# 这里我使用了1.4.6为例子,1.4.7还需要common包
wget http://archive.apache.org/dist/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/
cd /opt/module
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
# 修改配置文件
# 进入到/opt/module/sqoop/conf目录,重命名配置文件
mv sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
# 添加如下内容
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf
# 拷贝JDBC驱动
cp mysql-connector-java-5.1.48.jar /opt/module/sqoop/lib/
# 验证Sqoop
bin/sqoop help
# 测试Sqoop是否能够成功连接数据库
bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password 123456
3、Sqoop实例
3.1 Mysql导入Hadoop
# /opt/module/sqoop/bin
# ======================数据导入到HDFS====================
sqoop import \
--connect jdbc:mysql://hadoop102/datax \
--username root \
--password 123456 \
--table student \
--target-dir /tmp/root/111 \
--fields-terminated-by ',' \
-m 1
# table <table name>抽取mysql数据库中的表
# --target-dir <path>指定导入hdfs的具体位置。默认生成在为/user/<user>//目录下
# -m <数值>执行map任务的个数,默认是4个
# -m 参数可以指定 map 任务的个数,默认是 4 个。如果指定为 1 个 map 任务的话,最终生成的 part-m-xxxxx 文件个数就为 1。在数据充足的情况下,生成的文件个数与指定 map 任务的个数是等值的
# =====================数据导入到Hive中======================
sqoop import \
--connect jdbc:mysql://10.6.6.72:3309/hive \
--username root \
--password root123 \
--hive-import \
--table ROLES \
--hive-database default \
--hive-table roles_test \
--fields-terminated-by ',' \
-m 1
# --hive-import将表导入Hive中
# -m 参数可以指定 map 任务的个数,默认是 4 个。如果指定为 1 个 map 任务的话,最终生成在 /warehouse/tablespace/managed/hive/roles_test/base_xxxx 目录下的 000000_x 文件个数就为 1 。在数据充足的情况下,生成的文件个数与指定 map 任务的个数是等值的
# ==================据导入到HBase中============================
sqoop import \
--connect jdbc:mysql://10.6.6.72:3309/hive \
--username root \
--password root123 \
--table ROLES \
--hbase-table roles_test \
--column-family info \
--hbase-row-key ROLE_ID \
--hbase-create-table \
--hbase-bulkload
# --column-family <family>设置导入的目标列族
# --hbase-row-key <col>指定要用作行键的输入列;如果没有该参数,默认为mysql表的主键
# --hbase-create-table 如果执行,则创建缺少的HBase表
# --hbase-bulkload 启用批量加载
# 总结:roles_test 表的 row_key 是源表的主键 ROLE_ID 值,其余列均放入了 info 这个列族中
3.2 Hadoop导出到Mysql
Sqoop export 工具将一组文件从 HDFS 导出回 Mysql 。目标表必须已存在于数据库中。根据用户指定的分隔符读取输入文件并将其解析为一组记录。默认操作是将这些转换为一组INSERT将记录注入数据库的语句。在“更新模式”中,Sqoop 将生成 UPDATE 替换数据库中现有记录的语句,并且在“调用模式”下,Sqoop 将为每条记录进行存储过程调用,将 HDFS、Hive、HBase的数据导出到 Mysql 表中,都会用到下表的参数:
| 参数 | 描述 |
|---|---|
| –table <table name> | 指定要导出的mysql目标表 |
| –export-dir <path> | 指定要导出的hdfs路径 |
| –input-fields-terminated-by <char> | 指定输入字段分隔符 |
| -m <数值> | 执行map任务的个数,默认是4个 |
# =======================HDFS数据导出至Mysql========================
# 首先在 test 数据库中创建 roles_hdfs 数据表
sqoop export \
--connect jdbc:mysql://10.6.6.72:3309/test \
--username root \
--password root123 \
--table roles_hdfs \
--export-dir /tmp/root/111 \
--input-fields-terminated-by ',' \
-m 1
# 执行数据导入过程中,会触发 MapReduce 任务。任务成功之后,前往 mysql 数据库查看是否导入成功
# =======================Hive数据导出至Mysql=======================
sqoop export \
--connect jdbc:mysql://10.6.6.72:3309/test \
--username root \
--password root123 \
--table roles_hive \
--export-dir /warehouse/tablespace/managed/hive/roles_test/base_0000001 \
--input-fields-terminated-by ',' \
-m 1
# =====================HBase数据不支持导出至Mysql==================
其他具体可以参考:sqoop学习,这一篇文章就够了 / Sqoop1.4.7实现将Mysql数据与Hadoop3.0数据互相抽取
二、DataX概述与入门
1、DataX概述
https://github.com/alibaba/DataX
1.1 简介
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路, DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。DataX 目前已经有了比较全面的插件体系,主流的RDBMS 数据库、NOSQL、大数据计算系统都已经接入
1.2 框架设计
- Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework
- Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端
- Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题
1.3 运行原理
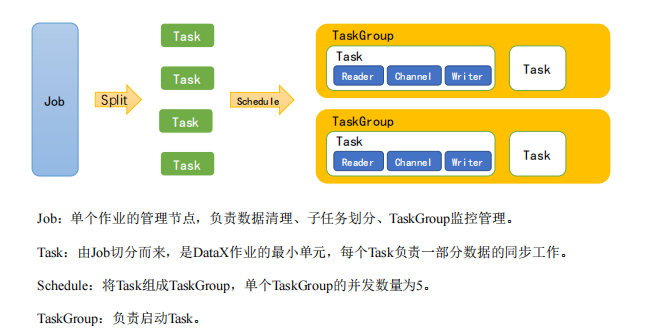
举例来说,用户提交了一个 DataX 作业,并且配置了 20 个并发,目的是将一个 100 张分表的 mysql 数据同步到 odps 里面。 DataX 的调度决策思路是:
- DataXJob 根据分库分表切分成了 100 个 Task
- 根据 20 个并发,DataX 计算共需要分配 4 个 TaskGroup
- 4 个 TaskGroup 平分切分好的 100 个 Task,每一个 TaskGroup 负责以 5 个并发共计运行 25 个 Task
2、DataX与 Sqoop 的对比
sqoop参考文档:https://juejin.cn/post/6994768829163241479
Sqoop已经被apache丢弃,后面建议都用datax
| 功****能 | DataX | Sqoop |
|---|---|---|
| 运行模式 | 单进程多线程 | MR |
| MySQL 读写 | 单机压力大; 读写粒度容易控制 | MR 模式重,写出错处理麻烦 |
| Hive 读写 | 单机压力大 | 很好 |
| 文件格式 | orc 支持 | orc 不支持,可添加 |
| 分布式 | 不支持,可以通过调度系统规避 | 支持 |
| 流控 | 有流控功能 | 需要定制 |
| 统计信息 | 已有一些统计,上报需定制 | 没有,分布式的数据收集不方便 |
| 数据校验 | 在 core 部分有校验功能 | 没有,分布式的数据收集不方便 |
| 监控 | 需要定制 | 需要定制 |
| 社区 | 开源不久,社区不活跃 | 一直活跃,核心部分变动很少 |
3、快速入门
# 需要jdk和python
wget https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202303/datax.tar.gz
tar -zxvf datax.tar.gz -C /opt/module/
# 运行自检脚本
cd /opt/module/datax/bin/
python datax.py /opt/module/datax/job/job.json
三、DataX常用入门案例
1、从stream 流读取数据并打印到控制台
# 会显示出模板
cd /opt/module/datax/bin/
python datax.py -r streamreader -w streamwriter
# 根据模板编写配置文件,在job目录下编码
vim stream2stream.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
# 执行
/opt/module/datax/bin/datax.py /opt/module/datax/job/stream2stream.json
2、读取 MySQL 中的数据存放到 HDFS
2.1 查看官方模板
# https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
# https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
# MySQL的模板
python /opt/module/datax/bin/datax.py -r mysqlreader -w hdfswriter


2.2 数据准备与配置
mysql> create database datax;
mysql> use datax;
mysql> create table student(id int,name varchar(20));
mysql> insert into student values(1001,'zhangsan'),(1002,'lisi'),(1003,'wangwu');
vim /opt/module/datax/job/mysql2hdfs.json这里我配置了ha
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/datax"
],
"table": [
"student"
]
}
],
"username": "root",
"password": "123456"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://testDfs",
"fieldDelimiter": "\t",
"fileName": "student.txt",
"fileType": "text",
"path": "/",
"writeMode": "append",
"hadoopConfig":{
"dfs.nameservices": "testDfs",
"dfs.ha.namenodes.testDfs": "namenode1,namenode2,namenode3",
"dfs.namenode.rpc-address.aliDfs.namenode1": "hadoop102:8020",
"dfs.namenode.rpc-address.aliDfs.namenode2": "hadoop103:8020",
"dfs.namenode.rpc-address.aliDfs.namenode3": "hadoop104:8020",
"dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
2.3 执行与结果
python /opt/module/datax/bin/datax.py /opt/module/datax/job/mysql2hdfs.json
# 注意:HdfsWriter 实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名
3、读取 HDFS 数据写入 MySQL
https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.md
# 改名
hadoop fs -mv /student.txt* /student.txt
# 查看官方模板
python bin/datax.py -r hdfsreader -w mysqlwriter
创建配置文件vim job/hdfs2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader", "parameter": {
"column": ["*"],
"defaultFS": "hdfs://hadoop102:8020",
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"fileType": "text",
"path": "/student.txt"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id", "name"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["student2"]
}
],
"password": "123456",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
对于hadoop高可用的配置
"hadoopConfig":{
"dfs.nameservices": "testDfs",
"dfs.ha.namenodes.testDfs": "namenode1,namenode2",
"dfs.namenode.rpc-address.aliDfs.namenode1": "",
"dfs.namenode.rpc-address.aliDfs.namenode2": "",
"dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
然后在 MySQL 的 datax 数据库中创建 student2
mysql> use datax;
mysql> create table student2(id int,name varchar(20));
开始执行python bin/datax.py job/hdfs2mysql.json
4、其他数据库
详见官网:https://github.com/alibaba/DataX
四、DataX源码分析
1、总体执行流程
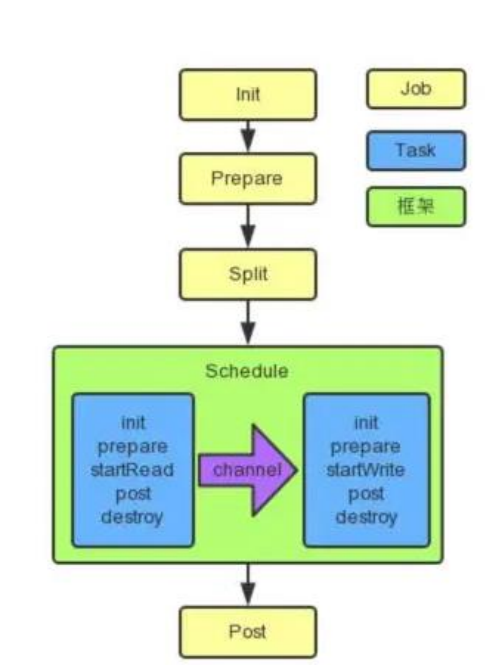
2、程序入口
datax.py
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (DEFAULT_PROPERTY_CONF, CLASS_PATH)
// 找到入口类com.alibaba.datax.core.Engine,搜索main方法
public void start(Configuration allConf) {
......
//JobContainer会在schedule后再行进行设置和调整值
int channelNumber =0;
AbstractContainer container;
long instanceId;
int taskGroupId = -1;
......
container.start();
}
//JobContainer.java
/**
* jobContainer主要负责的工作全部在start()里面,包括init、prepare、split、scheduler、
* post以及destroy和statistics
*/
@Override
public void start() {
LOG.info("DataX jobContainer starts job.");
boolean hasException = false;
boolean isDryRun = false;
try {
this.startTimeStamp = System.currentTimeMillis();
isDryRun = configuration.getBool(CoreConstant.DATAX_JOB_SETTING_DRYRUN, false);
if(isDryRun) {
LOG.info("jobContainer starts to do preCheck ...");
this.preCheck();
} else {
userConf = configuration.clone();
LOG.debug("jobContainer starts to do preHandle ...");
//Job 前置操作
this.preHandle();
LOG.debug("jobContainer starts to do init ...");
//初始化 reader 和 writer
this.init();
LOG.info("jobContainer starts to do prepare ...");
//全局准备工作,比如 odpswriter 清空目标表
this.prepare();
LOG.info("jobContainer starts to do split ...");
//拆分 Task
this.totalStage = this.split();
LOG.info("jobContainer starts to do schedule ...");
this.schedule();
LOG.debug("jobContainer starts to do post ...");
this.post();
LOG.debug("jobContainer starts to do postHandle ...");
this.postHandle();
LOG.info("DataX jobId [{}] completed successfully.", this.jobId);
this.invokeHooks();
......
}
3、Task 切分逻辑
/**
* 执行reader和writer最细粒度的切分,需要注意的是,writer的切分结果要参照reader的切分结果,
* 达到切分后数目相等,才能满足1:1的通道模型,所以这里可以将reader和writer的配置整合到一起,
* 然后,为避免顺序给读写端带来长尾影响,将整合的结果shuffler掉
*/
private int split() {
this.adjustChannelNumber();
......
List<Configuration> readerTaskConfigs = this
.doReaderSplit(this.needChannelNumber);
int taskNumber = readerTaskConfigs.size();
List<Configuration> writerTaskConfigs = this
.doWriterSplit(taskNumber);
......
}
//并发数的确定
private void adjustChannelNumber() {
int needChannelNumberByByte = Integer.MAX_VALUE;
int needChannelNumberByRecord = Integer.MAX_VALUE;
boolean isByteLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 0) > 0);
if (isByteLimit) {
long globalLimitedByteSpeed = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 10 * 1024 * 1024);
// 在byte流控情况下,单个Channel流量最大值必须设置,否则报错!
Long channelLimitedByteSpeed = this.configuration
.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_BYTE);
if (channelLimitedByteSpeed == null || channelLimitedByteSpeed <= 0) {
throw DataXException.asDataXException(
FrameworkErrorCode.CONFIG_ERROR,
"在有总bps限速条件下,单个channel的bps值不能为空,也不能为非正数");
}
needChannelNumberByByte =
(int) (globalLimitedByteSpeed / channelLimitedByteSpeed);
needChannelNumberByByte =
needChannelNumberByByte > 0 ? needChannelNumberByByte : 1;
LOG.info("Job set Max-Byte-Speed to " + globalLimitedByteSpeed + " bytes.");
}
boolean isRecordLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 0)) > 0;
if (isRecordLimit) {
long globalLimitedRecordSpeed = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 100000);
Long channelLimitedRecordSpeed = this.configuration.getLong(
CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_RECORD);
if (channelLimitedRecordSpeed == null || channelLimitedRecordSpeed <= 0) {
throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,
"在有总tps限速条件下,单个channel的tps值不能为空,也不能为非正数");
}
needChannelNumberByRecord =
(int) (globalLimitedRecordSpeed / channelLimitedRecordSpeed);
needChannelNumberByRecord =
needChannelNumberByRecord > 0 ? needChannelNumberByRecord : 1;
LOG.info("Job set Max-Record-Speed to " + globalLimitedRecordSpeed + " records.");
}
// 取较小值
this.needChannelNumber = needChannelNumberByByte < needChannelNumberByRecord ?
needChannelNumberByByte : needChannelNumberByRecord;
// 如果从byte或record上设置了needChannelNumber则退出
if (this.needChannelNumber < Integer.MAX_VALUE) {
return;
}
boolean isChannelLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL, 0) > 0);
if (isChannelLimit) {
this.needChannelNumber = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL);
LOG.info("Job set Channel-Number to " + this.needChannelNumber
+ " channels.");
return;
}
throw DataXException.asDataXException(
FrameworkErrorCode.CONFIG_ERROR,
"Job运行速度必须设置");
}
4、调度
//JobContainer.java
/**
* schedule首先完成的工作是把上一步reader和writer split的结果整合到具体taskGroupContainer中,
* 同时不同的执行模式调用不同的调度策略,将所有任务调度起来
*/
private void schedule() {
/**
* 这里的全局speed和每个channel的速度设置为B/s
*/
int channelsPerTaskGroup = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);
int taskNumber = this.configuration.getList(
CoreConstant.DATAX_JOB_CONTENT).size();
//确定的 channel 数和切分的 task 数取最小值,避免浪费
this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);
PerfTrace.getInstance().setChannelNumber(needChannelNumber);
/**
* 通过获取配置信息得到每个taskGroup需要运行哪些tasks任务
*/
List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,
this.needChannelNumber, channelsPerTaskGroup);
......
scheduler.schedule(taskGroupConfigs);
......
}
/**
* 公平的分配 task 到对应的 taskGroup 中。
* 公平体现在:会考虑 task 中对资源负载作的 load 标识进行更均衡的作业分配操作。
* TODO 具体文档举例说明
*/
public static List<Configuration> assignFairly(Configuration configuration, int channelNumber, int channelsPerTaskGroup) {
Validate.isTrue(configuration != null, "框架获得的 Job 不能为 null.");
List<Configuration> contentConfig = configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT);
Validate.isTrue(contentConfig.size() > 0, "框架获得的切分后的 Job 无内容.");
Validate.isTrue(channelNumber > 0 && channelsPerTaskGroup > 0,
"每个channel的平均task数[averTaskPerChannel],channel数目[channelNumber],每个taskGroup的平均channel数[channelsPerTaskGroup]都应该为正数");
//TODO 确定 taskgroup 的数量
int taskGroupNumber = (int) Math.ceil(1.0 * channelNumber / channelsPerTaskGroup);
......
/**
* 需要实现的效果通过例子来说是:
* a 库上有表:0, 1, 2
* b 库上有表:3, 4
* c 库上有表:5, 6, 7
*
* 如果有 4个 taskGroup
* 则 assign 后的结果为:
* taskGroup-0: 0, 4,
* taskGroup-1: 3, 6,
* taskGroup-2: 5, 2,
* taskGroup-3: 1, 7
*/
List<Configuration> taskGroupConfig = doAssign(resourceMarkAndTaskIdMap, configuration, taskGroupNumber);
// 调整 每个 taskGroup 对应的 Channel 个数(属于优化范畴)
adjustChannelNumPerTaskGroup(taskGroupConfig, channelNumber);
return taskGroupConfig;
}
//AbstractScheduler.java
public void schedule(List<Configuration> configurations) {
......
// 丢线程池运行
startAllTaskGroup(configurations);
......
}
5、数据传输
找到TaskGroupContainer.start()—> taskExecutor.doStart()
public void doStart() {
this.writerThread.start();
// reader 没有起来,writer 不可能结束
if (!this.writerThread.isAlive() || this.taskCommunication.getState() == State.FAILED) {
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
this.taskCommunication.getThrowable());
}
this.readerThread.start();
......
}
//可以看看 generateRunner()
public void run() {
......
taskReader.init();
......
taskReader.prepare();
......
taskReader.startRead(recordSender);
......
taskReader.post();
......
super.destroy();
......
}
比如看 MysqlReader 的 startReader 方法
-》CommonRdbmsReaderTask.startRead()
-》transportOneRecord()
-》sendToWriter()
-》BufferedRecordExchanger. flush()
-》Channel.pushAll()
-》Channel.statPush()
五、DataX 使用优化
1、关键参数
- job.setting.speed.channel : channel 并发数
- job.setting.speed.record : 全局配置 channel 的 record 限速
- job.setting.speed.byte:全局配置 channel 的 byte 限速
- core.transport.channel.speed.record:单个 channel 的 record 限速
- core.transport.channel.speed.byte:单个 channel 的 byte 限速
2、优化 1:提升每个 channel 的速度
在 DataX 内部对每个 Channel 会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是 1MB/s,可以根据具体硬件情况设置这个 byte 速度或者 record 速度,一般设置 byte 速度,比如:我们可以把单个 Channel 的速度上限配置为 5MB
3、优化 2:提升 DataX Job 内 Channel 并发数
并发数 = taskGroup 的数量 * 每个 TaskGroup 并发执行的 Task 数 (默认为 5)。提升 job 内 Channel 并发有三种配置方式:
3.1 配置全局 Byte 限速以及单 Channel Byte 限速
Channel 个数 = 全局 Byte 限速 / 单 Channel Byte 限速
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": 1048576
}
}
}
},
"job": {
"setting": {
"speed": {
"byte" : 5242880
}
},
......
}
}
core.transport.channel.speed.byte=1048576,job.setting.speed.byte=5242880,所以 Channel个数 = 全局 Byte 限速 / 单 Channel Byte 限速=5242880/1048576=5 个
3.2 配置全局 Record 限速以及单 Channel Record 限速
Channel 个数 = 全局 Record 限速 / 单 Channel Record 限速
{
"core": {
"transport": {
"channel": {
"speed": {
"record": 100
}
}
}
},
"job": {
"setting": {
"speed": {
"record" : 500
}
},
......
}
}
core.transport.channel.speed.record=100 , job.setting.speed.record=500, 所 以 配 置 全 局Record 限速以及单 Channel Record 限速,Channel 个数 = 全局 Record 限速 / 单 ChannelRecord 限速=500/100=5
3.3 直接配置 Channel 个数
只有在上面两种未设置才生效,上面两个同时设置是取值小的作为最终的 channel 数
{
"job": {
"setting": {
"speed": {
"channel" : 5
}
},
......
}
}
直接配置 job.setting.speed.channel=5,所以 job 内 Channel 并发=5 个
4、优化 3:提高 JVM 堆内存
当提升 DataX Job 内 Channel 并发数时,内存的占用会显著增加,因为 DataX 作为数据交换通道,在内存中会缓存较多的数据。例如 Channel 中会有一个 Buffer,作为临时的数据交换的缓冲区,而在部分 Reader 和 Writer 的中,也会存在一些 Buffer,为了防止 OOM 等错误,调大 JVM 的堆内存。
建议将内存设置为 4G 或者 8G,这个也可以根据实际情况来调整。调整 JVM xms xmx 参数的两种方式:一种是直接更改 datax.py 脚本;另一种是在启动的时候,加上对应的参数,如下:
python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" XXX.json







![[AION]我眼中的《永恒之塔私服》](https://img-blog.csdnimg.cn/61cf26f896e2461090297b31288bc25d.jpeg)