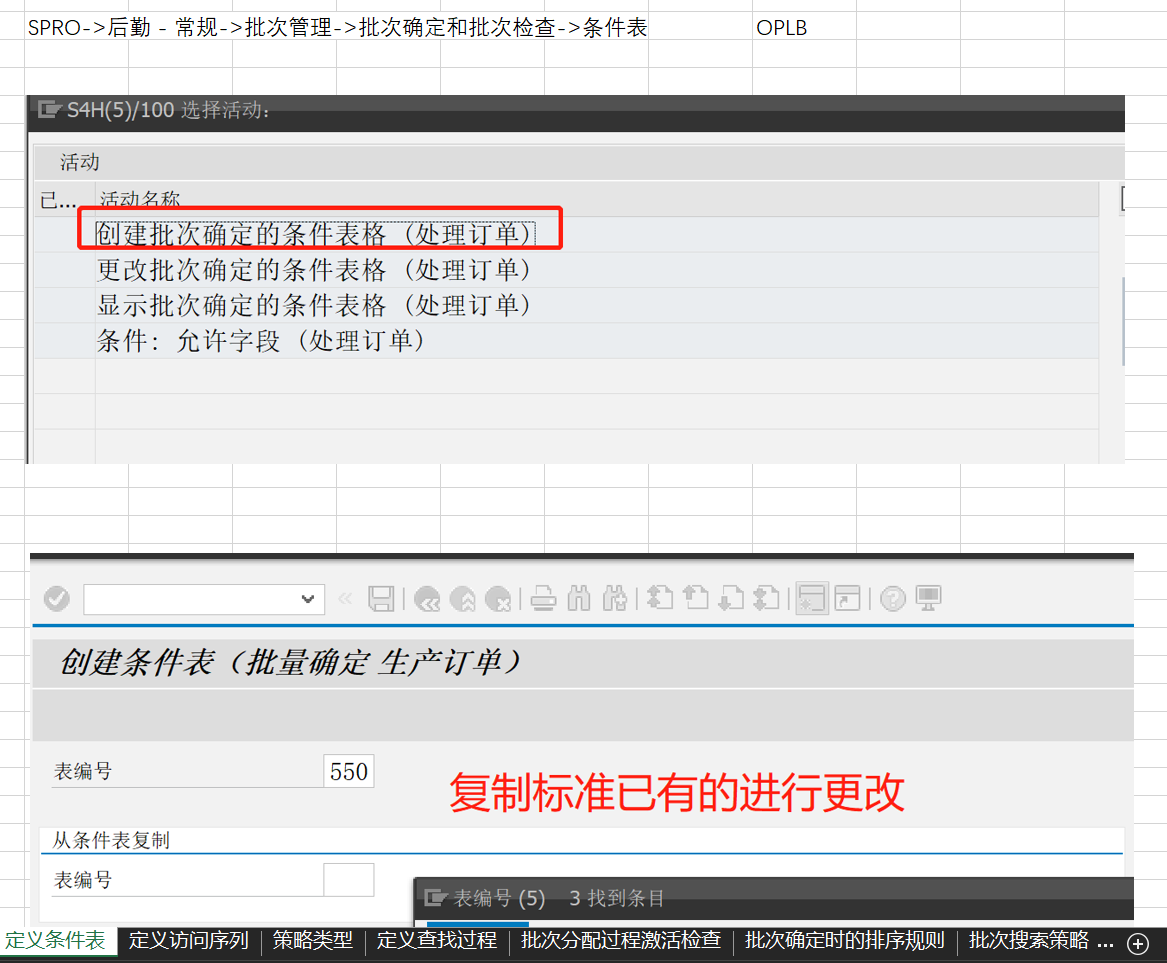
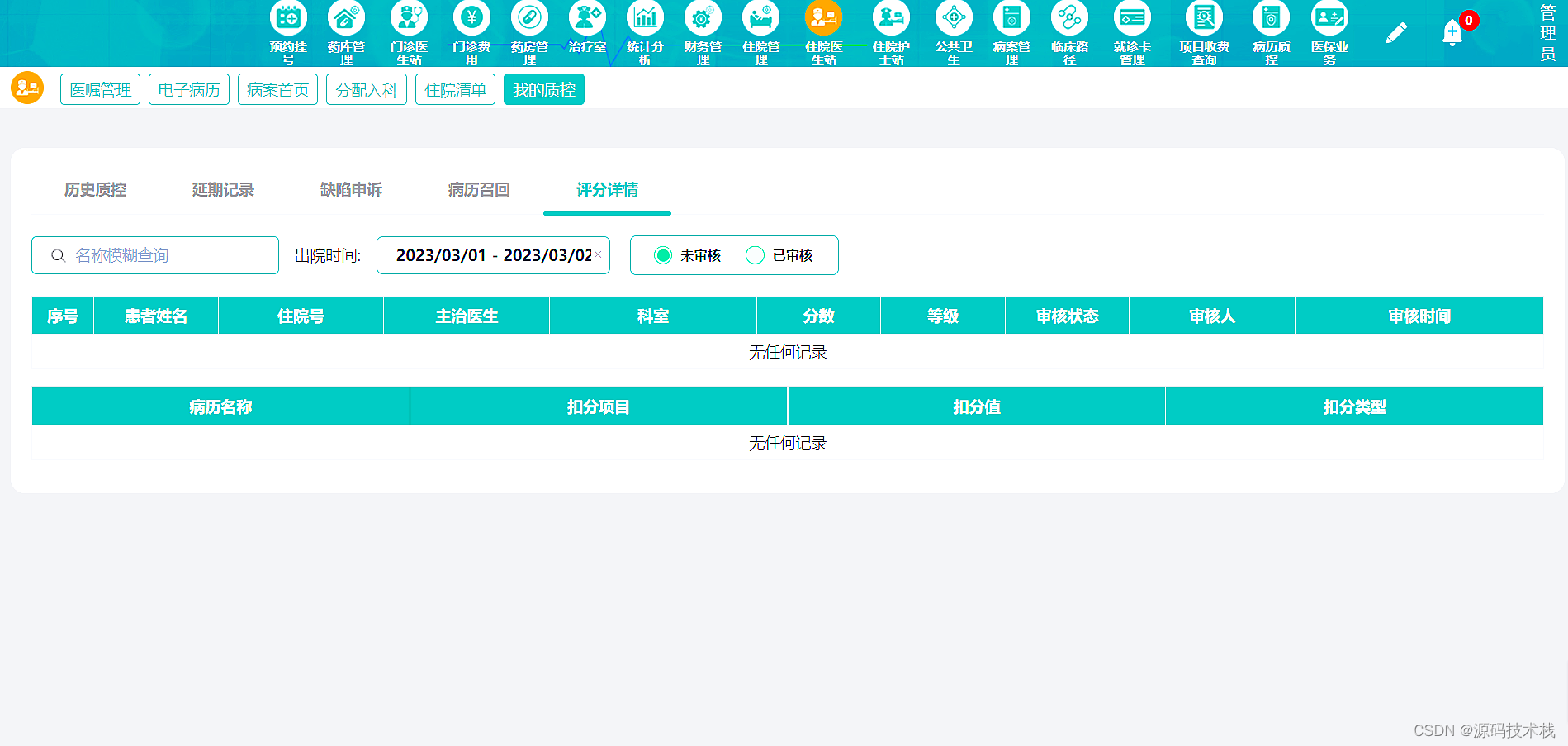
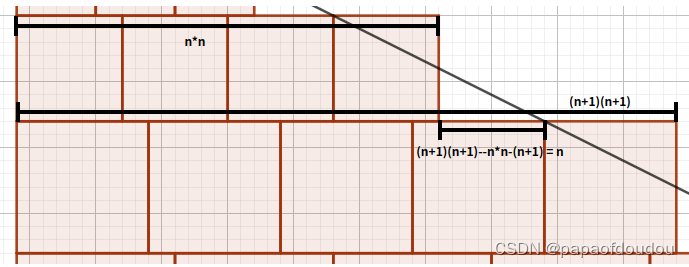
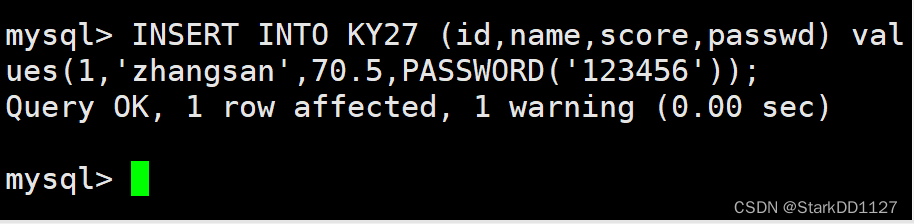
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹)

目录
无重复字符的最长子串
题目:
代码思路:
代码表示:
无重复字符的最长子串
题目:
给定一个字符串
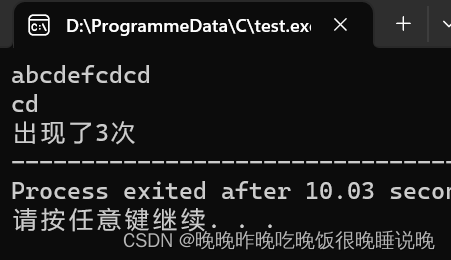
s,请你找出其中不含有重复字符的 最长子串 的长度。示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
代码思路:
以字符串 pwwkew 为例,我们可以用for循环从左到右依次查找,本题有两个难点
如何才能判断重复出现的字符?
可以创建一个数组,将每一个字符存入数组中,将数组初始化为0,先判断是否重复,然后再将每一个字符赋值,大小为其对应的下标。随着for循环的推移,后一个字符对应的数组值一定大于前一个,当字符重复出现时,后一个字符对应的数组值一定大于前一个,这样就可以判断重复了。
如何才能输出子串的长度?
可以创建两个变量length和max 在每一次判断重复后,记录length的大小,并与max比较,确保max的值最大,在for循环完以后,还需要再一次记录length的大小,与之前出现重复时的max大小做比较,最后返回即可
代码表示:
int lengthOfLongestSubstring(char* s)
{
int start = 0, length=0,max=0;
int a[200] = { 0 };
for (int i = 0; s[i] != '\0'; i++)
{
if (a[s[i]] > start)
{
length = i - start;
start = a[s[i]];
if (length > max)
{
max = length;
}
}
a[s[i]] = i + 1;
}
length = strlen(s);
length = length - start;
if (length > max)
{
return length;
}
else
return max;
}





![[AION]我眼中的《永恒之塔私服》](https://img-blog.csdnimg.cn/61cf26f896e2461090297b31288bc25d.jpeg)