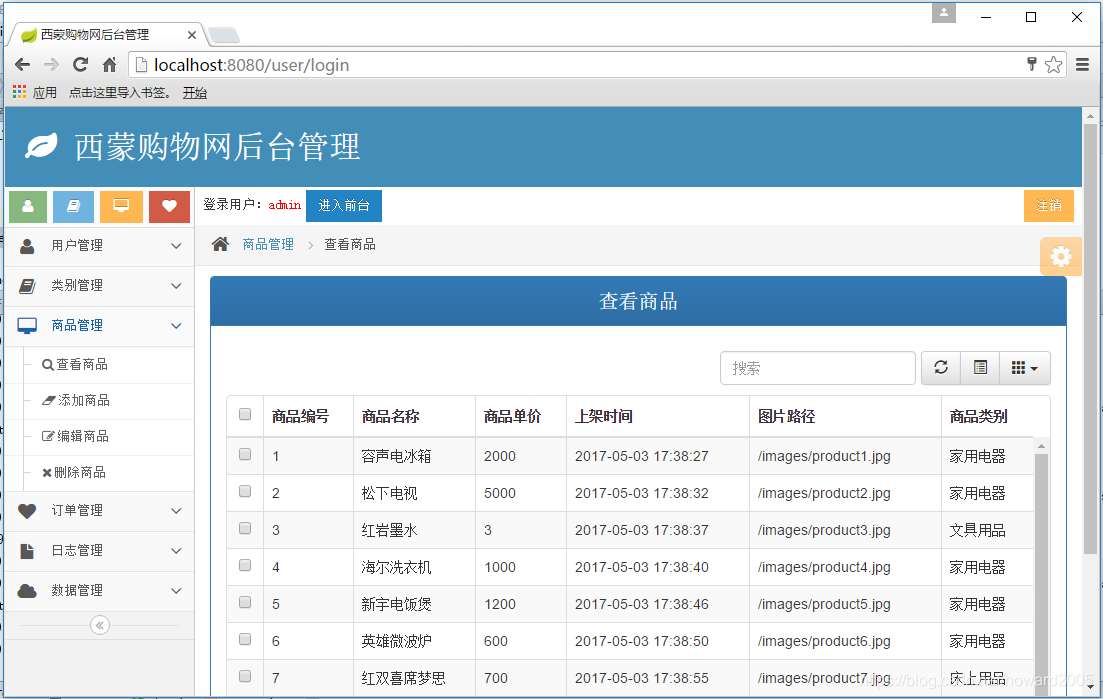
在对代码进行开源时,我们往往并不希望代码开发过程中的提交记录被其他人看到,因为提交的过程中往往会涵盖一些敏感信息。因此会存在 将仓库中所有 commit 合成一个 的需求。
直觉上,往往会用 rebase 和 squash 或 reset,不过我尝试了一下存在问题,会出现最后仍然剩两个 commit 的情况。
接下来分享三种可用的方式,并简单介绍一下为什么不用 rebase。
文章目录
- 方式一:git commit --amend(官方建议)
- 方式二:新建本地的 git 仓库
- 方式三:新建空白的子分支
- 为什么不建议用 rebase 进行该合并操作?
方式一:git commit --amend(官方建议)
这一种方式意思就是追加提交,最符合 git 的使用原则,也最轻量。我建议使用这种方式,这也是 git 官方建议的方式。
首先在 github 网页上或者使用 git log 查看第一个 commit 的 id,然后运行:
git reset --soft <第一个 commit 的 id>
git commit --amend
这两行指令的含义是:
- 将当前分支的状态切换到第一个提交中,并保留本地的修改以及暂存区的设置;
- 将现在的暂存区的内容直接 amend 到前一个提交(在这里指的就是第一个 commit)。
运行这两行指令之后,将会弹出一个新的编辑框,要求填写 commit message。默认的 commit message 就是你的第一个提交的 commit 信息,如果你需要修改,就修改一下。
方式二:新建本地的 git 仓库
这种方式是最直观直接的,新建了当然什么都没有了咯。
不过操作起来比较麻烦,需要删除文件夹、调整当前的目录。
# 1. 删除当前目录的 .git/ 文件夹
# 2. 新建 git 仓库
git init
# 3. 建立当前 git 目录与远端仓库的关系
git remote add origin git@github.com:user/repo
# 4. 重新添加所有文件并提交
git add .
git commit -m 'message'
# 6. 对远端仓库强制更新
git push -f origin master
方式三:新建空白的子分支
这种方式也很直观,就是新建空白子分支,再将子分支直接命名为原来的主分支,李代桃僵。
不过在推送时有点邪门,弄不好也容易出错,不建议使用,不过可以用来了解一下 orphan 参数。
# 1. 新建一个空白分支
git checkout --orphan <分支名> # orphan 代表这个分支是一个初始提交
# 2. 重新添加所有文件并提交
git add .
git commit -m "new"
# 3. 删除原来的主分支
git branch -D master
# 4. 将新建的空白分支的名称改成master
git branch -m master
# 5. 对远端仓库强制更新
git push -f origin master --set-upstream
注意,主分支有可能叫做 main,也有可能叫做 master。
为什么不建议用 rebase 进行该合并操作?
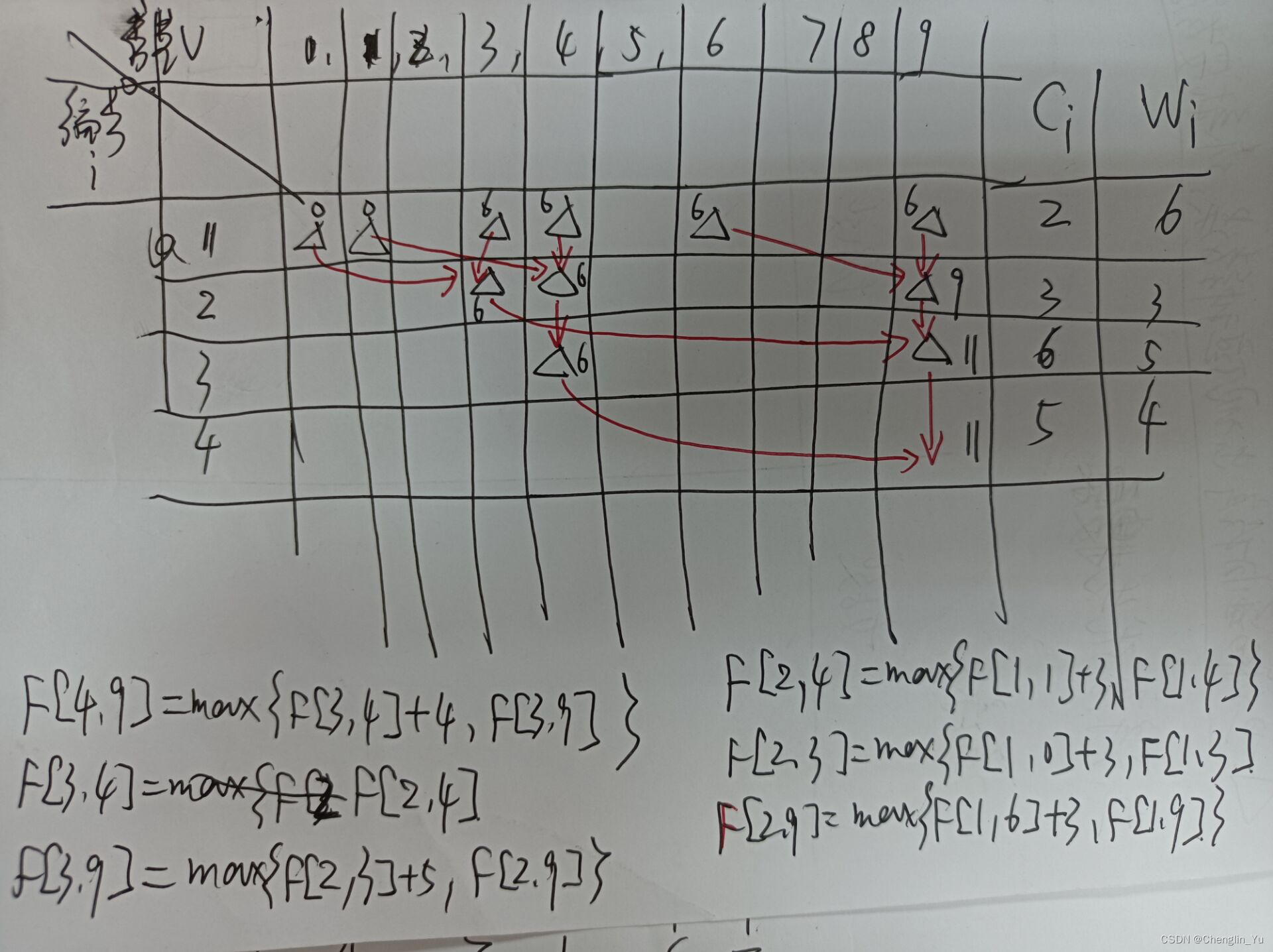
rebase 用于压缩 commit 的时候,往往是这样的过程:
git rebase -i HEAD~n,其中n是需要合并的 commit 数量;- 弹出新的编辑窗口,选择(pick)一个分支,压缩(squash)其他分支:
pick commitid s commitid1 s commitid2 - 保存并退出。
rebase 这个 git 指令仅看名字,意思大概是重新设置一下 base commit。因此它在使用时,是需要有一个 base commit 的,它的 pick、squash 等操作,都是基于这个 base 去做的。
就拿上述所说的过程中的第二步解释,在这一步中,其 base commit 其实是 commitid 的 parent commit,它实际上做的操作,是先切换到 parent commit,然后再在 parent commit 里去进行 cherry-pick、squash 操作。然后再重新提交。
而你无法使用 rebase 去合并仓库中的所有 commit 的原因,也仅仅是因为它的机制:
- 最初的那个 commit,它没有它的 base commit。所以你无法使用 rebase 去 pick 第一个 commit。
- 当你每个 commit 都不 pick 的时候,压缩完了的 commit 将会不知道存给哪个 commit。
所以如果要使用 rebase 里提供的 squash(压缩)对所有分支进行压缩,压缩成唯一的一个 commit,那 rebase 操作时,要么无法找到 base commit 从而指令直接运行出错,要么你压缩完成之后 commit 不知道存给谁就报错。
而这些报错在处理起来,对于一个只想简单交个代码的人来说是比较难懂的。
如果你不相信,我这边提供一个例子。
假如现在总共有 3 个 commit,其中第一个 commit 的 id 是 d2d48778,如下所示:
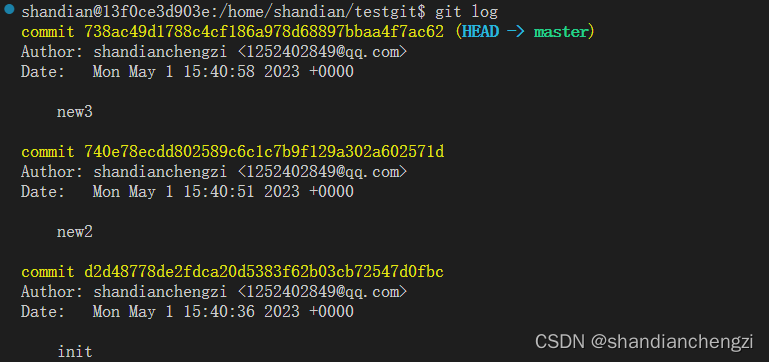
用 rebase 进行合并的时候,只能对最后两个 commit 进行操作。
如果你强行操作 3 个,运行的是如下指令:
git rebase -i HEAD~3
那你将会得到报错的结果fatal: invalid upstream 'HEAD~3':

如果你运行 git rebase -i HEAD~2,那么将一切正常。
而如果你发觉不对劲,因此干脆直接去 rebase 第一个 commit,运行了如下指令:
git rebase -i d2d48778
那你将不会得到报错,但会得到如下编辑框,没有第一个 commit 的 id:
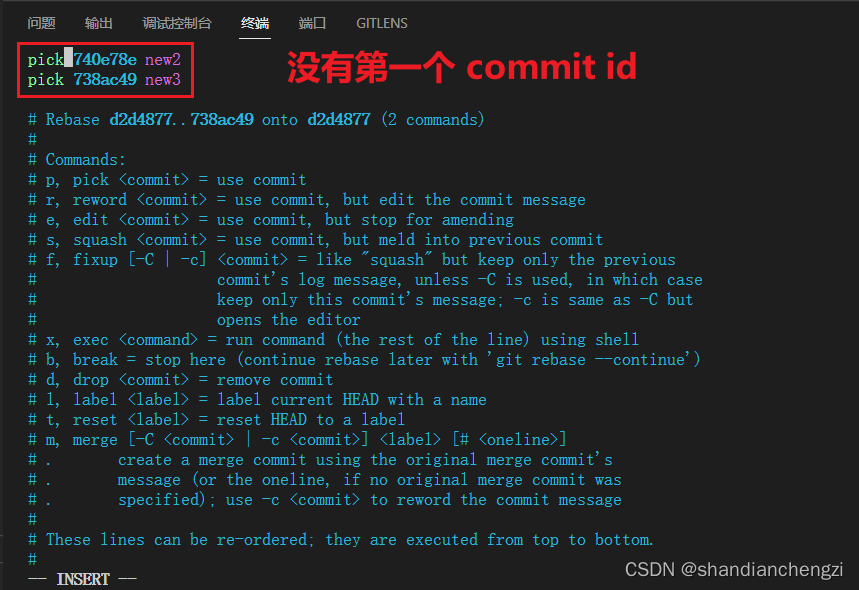
此时,直观上讲,我们肯定会不管不顾地将 pick 直接全改成 squash,期望出现奇迹。可是当我们保存并退出时,会发现出现的是报错error: cannot 'squash' without a previous commit,要求必须选择一个此前的 commit 去作为压缩的结果存储的 commit:

既然如此,干脆手动新增一行 pick 行不行呢?强行指定第一个 commit 作为存储 squash 结果的 commit,如下所示:
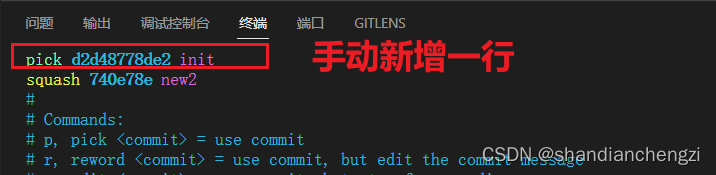
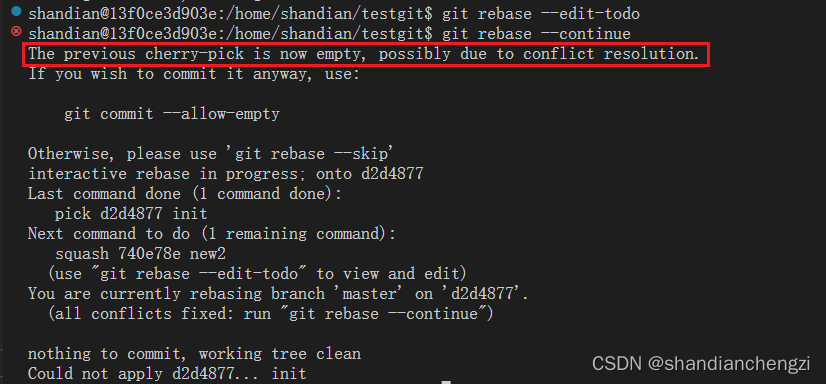
实际上,这也不行。原因就在于第一个 commit 没有前一个 commit,根本不能被 cherry-pick。如果你真的这样做了,那么你会得到一个报错The previous cherry-pick is now empty, possibly due to conflict resolution.,与我的描述一致,如下图所示:
你或许还注意到了 git 官方给出了一个解决办法,就是 git commit --allow-empty,那么,它解决的结果是什么呢?当运行了这行指令之后,弹出新的编辑框要求输入 commit message,然后查看当前 git 日志,如下两图所示:
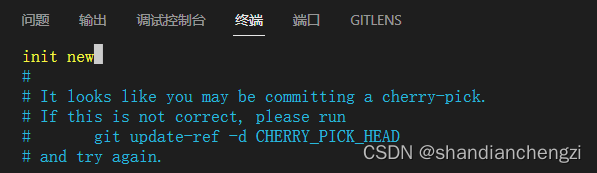
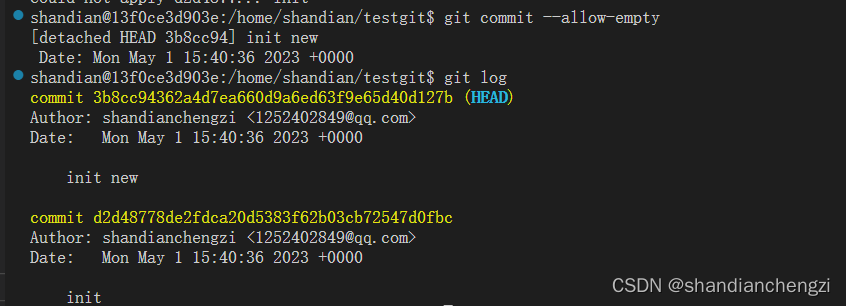
你会惊讶地发现,居然还是有两个提交。
更可怕的是,当你终于想起来去看看自己的 git 状态时,你会发现操作日志也没有了,rebase 也没执行,本地的修改也不见了。如下图所示:
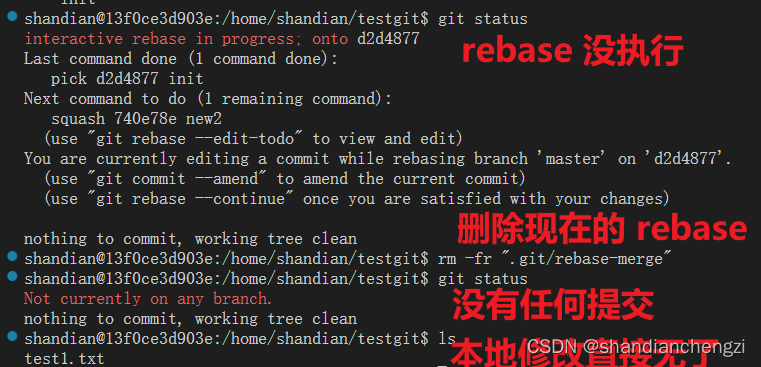
虽然实际上,本地的修改其实还在 本地的 commit 文件里,但由于你也不知道到底怎么 rebase,在百般 rebase 失败之后,你或许已经忘记了最新代码的 commitid、或者已经失手推送更新了远端仓库、或者已经忘记了自己到底要改什么东西,最后的结果可能是让人崩溃的。
其实在 git status 时,git 命令行就已经显示了这个问题的所有解决方案:
- 你可以修改你的 rebase 操作,使用
git rebase --edit-todo,让它 pick 第二个 commit、基于第一个 commit,这样起码能够保留你的代码文件,只是第一个 commit 会多余。 - 你可以使用
git commit --amend操作,只是做简单的追加操作,而不是像现在这样使用 rebase 乱来。具体可以参考本文的方式一。 - 你可以重新执行 rebase 操作,使用
git rebase --continue,如果你坚持觉得自己是正确的话。(当然,这样做只会导致继续报错罢了)
综上所述,我为了讲清楚为什么不在合并所有 commit 的时候使用 rebase,简单地思考并描述了一下 rebase 的原理和机制,希望对遇到这个问题的人有所帮助。
另外,大部分机制是直接通过操作看或猜出来的,仅结合 git 输出信息,并未结合官方的描述文档,若有错误,还请在评论区留言指正。
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_46106285/article/details/130459829。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。