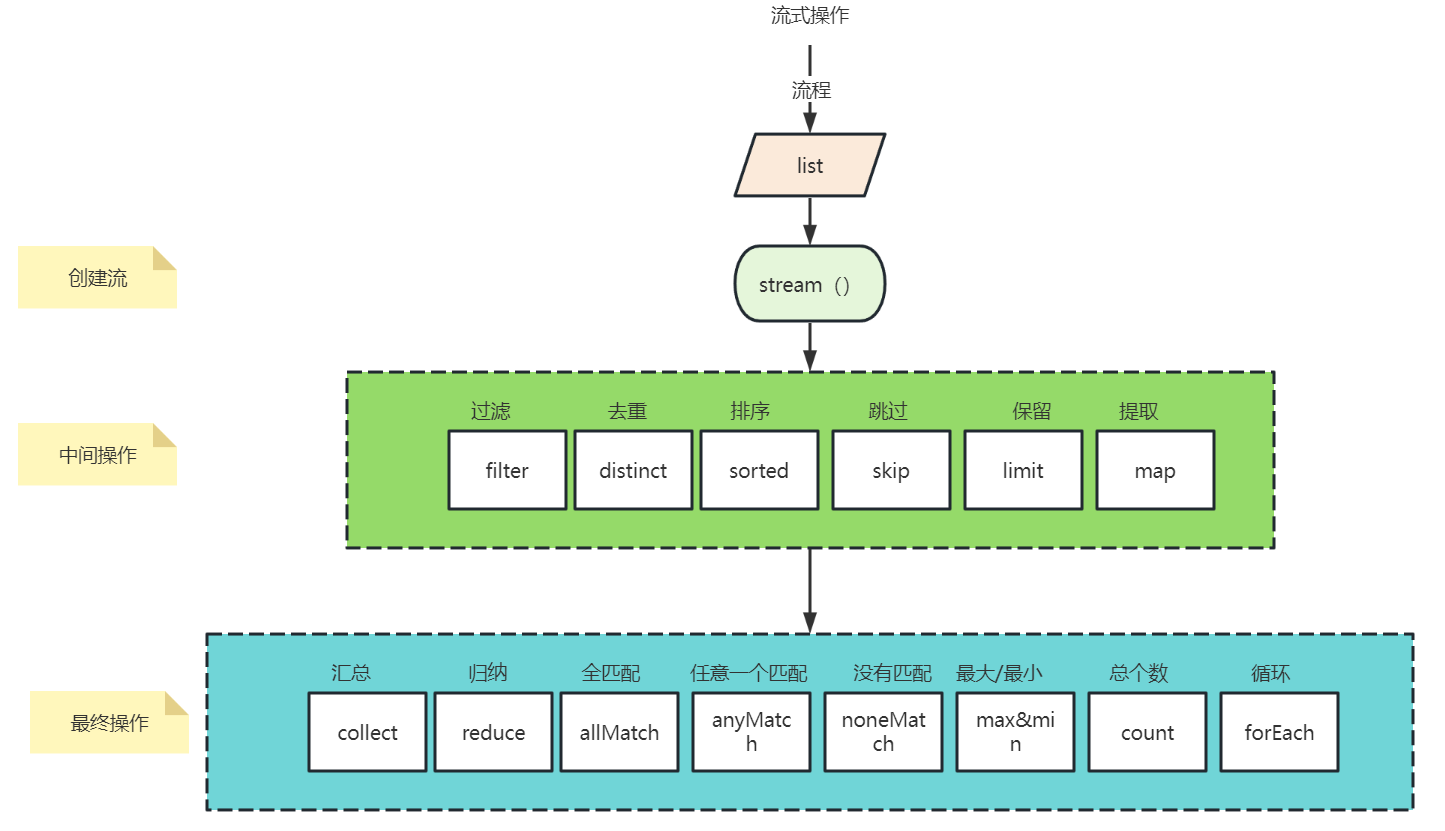
在Java8中提供了新特性—流式操作,通过流式操作可以帮助我们对数据更快速的进行一些过滤、排序、去重、最大、最小等等操作并且内置了并行流将流划分成多个线程进行并行执行,提供更高效、快速的执行能力。接下来我们一起看看Java8为我们新增了哪些便捷呢?
目录
什么是集合的流式操作?
对集合做流式操作的三个步骤?
映射
flatMap:相同元素合并或拆分h1
map:将源数据转换成需要的数据类型或者进行指定的操作
toMap:转换成需要的map集合
并行流
什么是并行流?
为什么需要并行流?
parallel():并行流
findAny和findFirst的区别是什么?
findAny:最先抢到cpu时间片的线程它所处理的数据段中的第一个数据,串行流结果等同于findFirst
findFirst:流中的第一个元素(指集合中的第一个),并行流或串行流结果一致
什么是集合的流式操作?
流式操作:不是一个数据结构,不负责任何的数据存储
更像是一个迭代器,有序的获取到数据源中的每一个数据,并且可以对这些数据进行一些操作
流失操作的每一个方法,返回值都是返回的流本身
翻译:可以把流比作一个管道,管道中有很多过滤网
对集合做流式操作的三个步骤?
获取数据源:集合、数组
对数据进行处理的过程:过滤、排序、映射……(中间操作)
对流中数据的整合:转成集合、数量(最终操作)
映射
方法
- flatMap:相同元素合并或拆分h1
- map:将源数据转换成需要的数据类型或者进行指定的操作
- toMap:转换成需要的map集合
实践说明
-
flatMap:相同元素合并或拆分h1
-
map:将源数据转换成需要的数据类型或者进行指定的操作
要求输出内容:h,e,l,l,o,w,o,r,l,d
public static void main(String[] args) {
String[] array = {"hello", "world"};
System.out.println(Arrays.stream(array).map(ele -> ele.split("")).flatMap(Arrays::stream).collect(Collectors.toList()));
}参考博客:
flatMap():Java8 FlatMap的使用_java flatmap_杨幂等的博客-CSDN博客
Map():这么简单,还不会使用java8 stream流的map()方法吗?_stream流的map方法_欧子有话说的博客-CSDN博客
toMap:转换成需要的map集合
public static void main(String[] args) {
Stream<Person> stream = Data.getData().stream();
Map<String, Integer> maps = stream.collect(Collectors.toMap(Person::getName, Person::getScore));
System.out.println(maps);
}并行流
什么是并行流?
把流分成多个块,并行操作
为什么需要并行流?
集合做重复的操作,如果使用串行执行会相当耗时,因此一般会采用多线程来加快, Java8的提供了并发执行能力
方法
-
parallel():并行流
-
findAny:最先抢到cpu时间片的线程它所处理的数据段中的第一个数据,串行流结果等同于findFirst
-
findFirst:流中的第一个元素(指集合中的第一个),并行流或串行流结果一致
实战说明
parallel():并行流
import com.example.Data;
import java.util.Arrays;
import java.util.stream.Collectors;
import java.util.stream.LongStream;
/**
* @BelongsProject: StreamOperate
* @BelongsPackage: PACKAGE_NAME
* @CreateTime: 2023-05-01 21:12
* @Description: TODO
* @Version: 1.0
*/
public class ParalleStream {
public static void main(String[] args) {
long start = System.currentTimeMillis();
LongStream.rangeClosed(0L, 50000000000L).parallel().reduce(Long::sum);
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}参考博客:Java 8 并行流(Parallel Stream) 介绍 - 简书
findAny和findFirst的区别是什么?
-
findAny:最先抢到cpu时间片的线程它所处理的数据段中的第一个数据,串行流结果等同于findFirst
-
findFirst:流中的第一个元素(指集合中的第一个),并行流或串行流结果一致
对于并行流中,findAny比findFirst效率更高
import com.example.Data;
import java.util.Arrays;
import java.util.stream.Collectors;
import java.util.stream.LongStream;
/**
* @BelongsProject: StreamOperate
* @BelongsPackage: PACKAGE_NAME
* @CreateTime: 2023-05-01 21:12
* @Description: TODO
* @Version: 1.0
*/
public class ParalleStream {
public static void main(String[] args) {
System.out.println(Data.getData().parallelStream().findFirst());
System.out.println(Data.getData().stream().findFirst());
System.out.println(Data.getData().stream().findAny());
System.out.println(Data.getData().parallelStream().findAny());
}
}