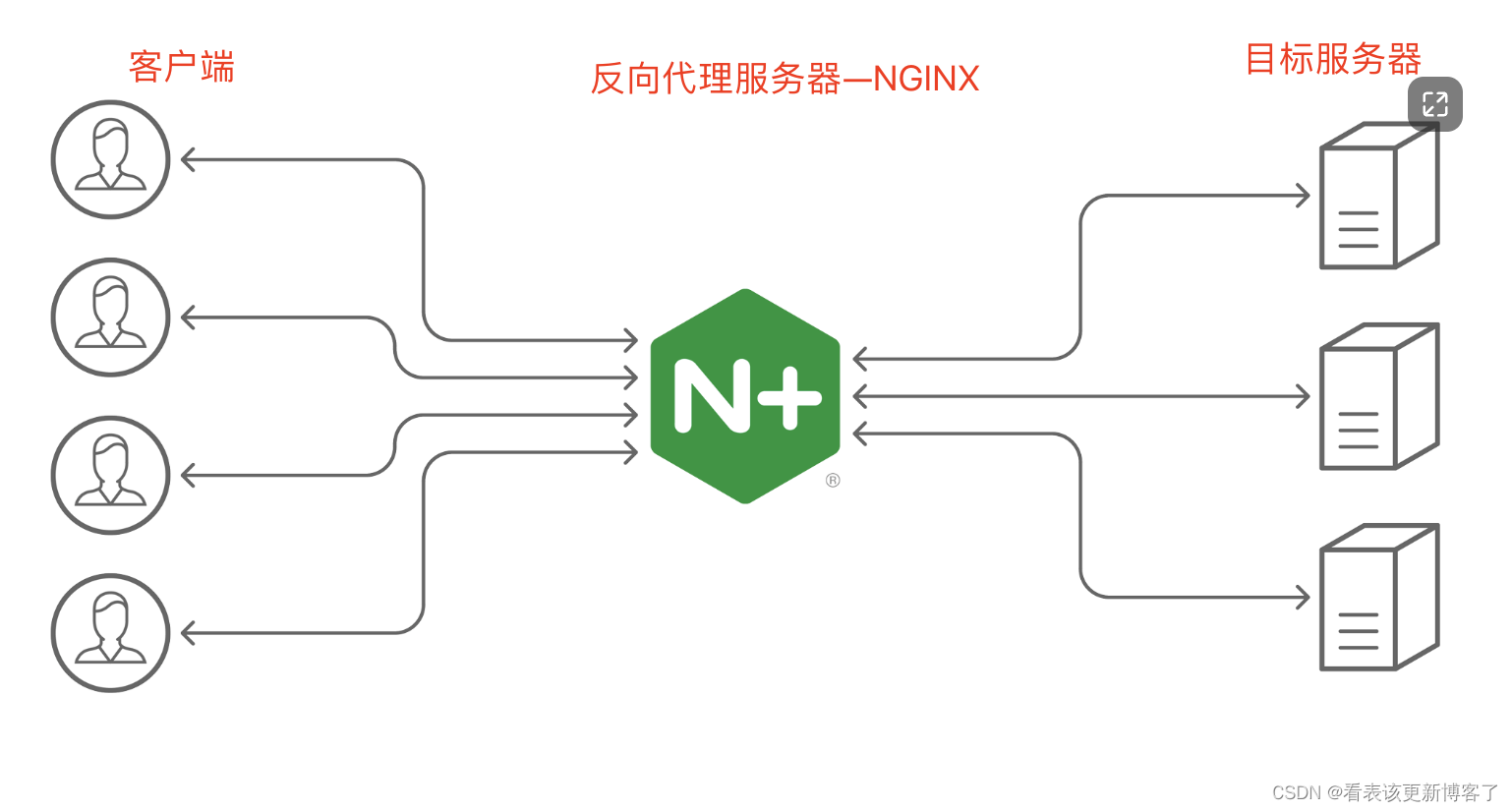
【VQGAN论文精读】Taming Transformers for High-Resolution Image Synthesis
- 0、前言
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Approach
- 3.1. Learning an Effective Codebook of Image Constituents for Use in Transformers学习一个有效的图像成分的Codebook为了在Transformers中使用
- 3.1.1Learning a Perceptually Rich Codebook
- 3.2. Learning the Composition of Images with Transformers
- 3.2.1 Latent Transformers
- 3.2.2Conditioned Synthesis
- 3.2.3Generating High-Resolution Images
- 4. Experiments
- 4.1. Attention Is All You Need in the Latent Space
- 4.2. A Unified Model for Image Synthesis Tasks
- 4.3. Building Context-Rich Vocabularies
- 4.4. Quantitative Comparison to Existing Models
- 5. Conclusion
0、前言
论文地址:Taming Transformers for High-Resolution Image Synthesis
这篇博客首先分析VQGAN的论文方法,下期分享VQGAN的代码原理。
VQGAN是StableDiffusion作者的前期论文,希望大家对于表征学习、GAN以及Transformer自回归建模(GPT)的理解有一定的帮助。
分享的这篇文章综合了CNN的局部建模优势与Transformer的全局建模优势,并且基于VQVAE,具体如下:
- 首先是利用CNN(包括编码器和解码器)来学习一个有效的codebook来表示图片(VQVAE)。然而使用transformers将图像表示为潜在图像成分的分布,需要我们突破压缩的极限。这里就增加了基于patch的鉴别器和感知损失,提出了VQGAN,以在增加压缩率的情况下保持良好的感知质量keep good perceptual quality at increased compression rate.(自然也就用到了注意力机制,具体参考下文)
- 那么Transformer如何应用到图像生成呢?之前说道VQVAE其实就是找到对应codebook中的索引,由索引找到codebook中的向量就可以轻松重建图像。这里Transformer就是自回归的进行下一个索引的预测 p ( s ) = ∏ i p ( s i ∣ s < i ) p(s) =\prod_i p(s_i|s_{<i}) p(s)=∏ip(si∣s<i)。
- 知道了如何生成的,那么下面的问题就是如何进行条件生成的呢?给定一个条件c,需要计算的就是 p ( s ∣ c ) = ∏ i p ( s i ∣ s < i , c ) p(s|c) =\prod_i p(s_i|s_{<i},c) p(s∣c)=∏ip(si∣s<i,c),如果条件信息c有空间范围,我们首先学习另一个VQGAN,利用transformer的自回归结构,用新获得的codebook Z C \mathcal{Z}_C ZC再次获得一个基于索引的表示 r ∈ { 0 , … , ∣ Z c ∣ − 1 } h c × w c r∈\{0,…, |Zc|−1\}^{hc×wc} r∈{0,…,∣Zc∣−1}hc×wc,然后我们可以简单地将r预置prepend到s(s是图像codebook索引),并将负对数似然的计算限制在条目 p ( s ∣ s < i , r ) p(s | s_{<i},r) p(s∣s<i,r)。
- 那么高分辨率的图像如何生成呢?transformer的注意机制限制了其输入s的序列长度h·w。虽然我们可以调整我们的VQGAN的下采样块数m来将大小为H×W的图像缩小到 h = H / 2 m × w = W / 2 m h=H/2^m×w=W/2^m h=H/2m×w=W/2m,但我们观察到超过临界值m的重建质量下降,这取决于所考虑的数据集。因此,为了生成百万像素的图像,我们必须进行分块patch-wise和裁剪,在训练期间将s的长度限制在最大可行的大小。为了对图像进行采样,我们以
滑动窗口的方式使用transformer,如图所示 3.生成的高分辨率图像如下:

在前言的最后放上论文中一些比较难翻译的词:
Position-wise: 顾名思义,就是对每个position采用相同的操作。
quadratically:二次方
albeit:conj.虽然;即使;
Abstract
设计用于学习序列数据的长期交互作用,transformers继续在各种各样的任务中显示最先进的结果。
与CNNs相比,它们不包含优先考虑本地交互的归纳偏见。这使得它们具有表现力,但对于长序列,如高分辨率图像,计算也不可行。
我们演示了如何将CNNs的诱导偏差的有效性与transformers的表达能力相结合,使它们能够建模,从而合成高分辨率图像。
我们展示了如何(i)使用CNNs来学习图像成分的上下文词汇表,反过来(ii)利用transformers在高分辨率图像中有效地建模它们的组成。
我们的方法很容易应用于条件合成任务,其中非空间信息(如对象类)和空间信息(如分割)都可以控制生成的图像。
特别地,我们提出了用transformers对百万像素图像进行语义引导合成的第一个结果。项目页面在https://git.io/JLlvY
1. Introduction
Transformers正在崛起–它们现在是语言任务的事实上的标准架构,并越来越多地被应用于其他领域,如音频[12]和视觉[8,15]。
与占主导地位的视觉结构卷积神经网络(CNNs)不同,transformer结构不包含对相互作用局部性的内置归纳先验,因此可以自由地学习其输入之间的复杂关系。
然而,这种共性也意味着它必须学习所有的关系,而CNNS被设计用来利用图像中强局部相关性的先验知识。
因此,由于所有的两两相互作用都被考虑在内,transformer的表现力的增加伴随着计算成本的二次增长。 由此产生的能量和时间需求的最先进的transformer模型,因此提出了基本的问题,如何将他们扩展到拥有数百万级像素的高分辨率图像。
transformers倾向于学习卷积结构[15]的观察由此提出了一个问题:每次训练视觉模型时,我们是否必须从头开始重新学习我们所知道的关于图像的局部结构和规则性的一切,或者我们能否在保持transformers灵活性的同时有效地对归纳图像偏差进行编码?
我们假设,底层图像结构可以通过局部连接(即卷积结构)很好地描述,而这种结构假设在更高的语义级别上不再有效。
此外,CNNs不仅表现出强烈的局部性偏差,而且通过在所有位置使用共享权值,还表现出对空间不变性的偏差。如果需要对输入有更全面的理解,这将使它们无效。
我们获得一个有效且富有表现力的模型的关键观点是,卷积和transformer架构结合在一起,可以对我们的视觉世界[44]的组成本质进行建模:我们使用卷积方法来高效地学习包含上下文丰富的视觉部分的codebook,然后学习它们的全局组成的模型。
这些组合中的长期交互需要一个具有表达能力的transformer体系结构来对其组成的可视化部分进行分布建模。
此外,我们使用一种对抗的方法来确保局部部件的字典捕获感知上重要的局部结构,以减轻使用transformer体系结构建模低级统计的需要。
让transformers专注于其独特的强度——模拟远程关系——使它们能够生成如图1所示的高分辨率图像,这是以前无法实现的壮举。
我们的公式直接通过有关所需对象类或空间布局的条件信息来控制生成的图像。
最后,实验证明,我们的方法保留了transformers的优势,优于以往codebook-based的最先进的基于卷积体系结构的方法。
2. Related Work
- The Transformer Family
首先介绍了Transformer的原理机制,其次引出现有的问题即:
虽然考虑所有元素之间的交互作用的能力是transformers有效学习远程交互作用的原因,但这也是transformers迅速变得不可行的原因,特别是在图像上,其中序列长度本身与分辨率成二次比例。
最后是说明了现有降低transformers计算复杂度的方法,要么不合理,要么还是不可行。 - Convolutional Approaches
图像的二维结构表明,局部相互作用尤为重要。
CNNs利用这个结构,将输入变量之间的交互限制为一个由卷积核的核大小定义的局部邻域。
因此,应用一个kernel会导致成本与整个序列长度(图像中的像素数)成线性比例,并与内核大小成二次比例,在现代CNN架构中,内核大小通常固定为一个小常数,例如3×3。这种对局部相互作用的归纳偏向导致了高效的计算,但在CNNs中引入了广泛的专门层来处理不同的合成任务,这表明这种偏向往往过于限制性。
卷积体系结构已被用于图像的自回归建模,但对于低分辨率图像,之前的研究表明,transformers的性能始终优于卷积体系。我们的方法使我们能够高效地用transformers建模高分辨率图像,同时保留了它们相对于最先进的卷积方法的优势。 - Two-Stage Approaches
与我们的方法最接近的是两阶段方法,首先学习数据编码,然后在第二阶段学习这种编码的概率模型。
[13]证明了先用变分自编码器(VAE)学习数据表示[34,54],然后再用VAE学习数据表示的分布的优点,同时也证明了理论和经验证据。
[17,68]在第二阶段使用无条件归一化流时证明了类似的增益,[55,56]在使用条件归一化流时证明了类似的增益。
为了提高生成对抗网络(Generative Adversarial Networks, GANs)的训练效率,[39]在自动编码器表示和[20]在低分辨率小波系数上学习GAN[19],然后用学习过的生成器将这些小波系数解码为图像。
VQVAE提出了矢量量化变分自编码器(VQVAE),一种学习图像离散表示的方法,并使用卷积结构自回归建模它们的分布。
VQVAE-2扩展了这种方法,以使用学习到的表示的层次结构。
然而,这些方法仍然依赖于卷积密度估计,这使得在高分辨率图像中捕获远程交互变得困难。
[8]使用transformers自回归地对图像进行建模,以评估生成式预训练对下游任务学习图像表示的适用性。由于32×32像素的输入分辨率仍然是相当昂贵的计算[8],所以使用VQVAE将图像编码到192 × 192的分辨率。为了使学习的离散表示尽可能保持相对于像素的空间不变,我们使用了一个具有小接收域receptive field的shallow VQVAE。
相比之下,我们证明了一个强大的第一阶段,即在学习的表示中捕获尽可能多的上下文,是实现transformers高效高分辨率图像合成的关键。
3. Approach

我们的目标是开发Transformer模型[64]的非常有前途的学习能力,并将其引入到高达百万像素范围的高分辨率图像合成中。
以前的工作[48,8]将transformers应用于图像生成,对大小为64×64像素的图像证明了有希望的结果,但是由于序列长度的二次增长成本,不能简单地缩放到更高的分辨率。
高分辨率图像合成需要一个能够理解图像全局组成的模型,使其能够生成局部逼真和全局一致的模式。
因此,我们不是用像素来表示图像,而是将其表示为来自codebook的感知丰富的图像成分的组合。 (即latent space)
通过学习有效的code,如SEC3.1中所述。 我们可以显著地减少构图的描述长度,这使得我们可以用SEC3.2.中描述的transformer结构有效地建模它们在图像中的全局相互关系。
这种方法,在图2总结,能够在无条件和有条件的情况下生成逼真一致的高分辨率图像。
3.1. Learning an Effective Codebook of Image Constituents for Use in Transformers学习一个有效的图像成分的Codebook为了在Transformers中使用
为了利用具有高度表现力的transformer结构进行图像合成,我们需要以sequence的形式表示图像的组成部分。而且这里是在codebook中表示图片而不是在像素空间中,一个等价的表示是h·w索引序列indices,它指定了学习到的codebook中各自的项。
为了有效地学习这样的离散空间codebook,我们提出直接吸收CNNs的归纳偏差inductive biases,并吸收神经离散表示学习的思想[63]。
首先,我们学习一个由编码器E和解码器G组成的卷积模型,这样,把它们放在一起,它们学习用来自一个已经学习的离散codebook
Z
=
{
z
k
}
k
=
1
K
\mathcal{Z}=\{z_k\}_{k=1}^{K}
Z={zk}k=1K的编码来表示图像(概述见图2)。
更准确地说,就是类似与VQVAE,我们输入图片x之后得到一个
z
q
z_q
zq通过解码器来获得图片的表示,即
x
^
=
G
(
z
q
)
\hat{x}=G(z_q)
x^=G(zq)。而
z
q
z_q
zq来自于codebook,具体计算过程是利用编码器的输出
z
^
=
E
(
x
)
∈
R
h
×
w
×
n
z
\hat{z}=E(x)\in \mathbb{R}^{h\times w\times n_z}
z^=E(x)∈Rh×w×nz与codebook中的每一个code计算一个argmin来得到,这一步也称quantization缩写为
q
(
z
^
)
\mathcal{q}(\hat{z})
q(z^)

通过Eq.(3)中不可微量化运算的反向传播是通过一个直接的梯度估计器来实现的,梯度估计器简单地将梯度从解码器复制到编码器[3],这样就可以通过损失函数端到端地训练模型和codebook。
(就是因为argmin操作不可导,这里直接将解码器的输入梯度复制到编码器的输出。具体操作感兴趣的同学可以看看我之前的博客(VQVAE的代码实战)

ok,到这里其实就是一个VQVAE。
3.1.1Learning a Perceptually Rich Codebook
使用transformers将图像表示为潜在图像成分的分布,需要我们突破压缩的极限,学习丰富的codebook。
为此,我们提出了VQGAN(原VQVAE的一种变体),并使用鉴别器和感知损失[36,26,35,16],以在增加压缩率的情况下保持良好的感知质量。
值得注意的是,这与之前的工作形成了鲜明的对比,之前的工作只在一个浅层量化模型上应用基于像素的[63,53]和基于transformer的自回归模型[8]。
更具体地说,我们将原VQVAE中用于
L
r
e
c
\mathcal{L}_{rec}
Lrec的
L
2
L_2
L2损失替换为感知损失,并引入一种对抗训练过程,该过程使用基于patch的鉴别器D[25],旨在区分真实图像和重建图像:

其中
Z
\mathcal{Z}
Z是codebook,其中
L
r
e
c
\mathcal{L}_{rec}
Lrec为感知重构损失[71],
∇
G
L
[
⋅
]
∇_{G_L}[·]
∇GL[⋅]表示其输入的梯度w.r.t,解码器的最后一层L,
δ
=
1
0
−
6
δ = 10^{−6}
δ=10−6用于数值稳定性。
为了聚合来自各处的上下文,我们在最低分辨率上应用单一的注意层。
这个训练过程在展开潜码时显著地减少了序列长度,从而使强大的transformer模型的应用成为可能。
3.2. Learning the Composition of Images with Transformers
3.2.1 Latent Transformers
有了E和G,我们现在就可以用它们的编codebook索引codebook-indices来表示图像。更准确地说,图像x的量化编码是由
z
q
=
q
(
E
(
x
)
)
∈
R
h
×
w
×
n
z
z_q = q(E(x))∈R^{h×w×n_z}
zq=q(E(x))∈Rh×w×nz给出的,它等价于codebook的索引序列
s
∈
{
0
,
…
,
∣
Z
∣
−
1
}
h
×
w
s∈\{0,…, |Z|−1\}^{h×w}
s∈{0,…,∣Z∣−1}h×w,获得方式是将每个code替换为其在codebook
Z
\mathcal{Z}
Z中的索引:

通过将序列的索引映射回它们对应的codebook条目,
z
q
=
(
z
s
i
j
)
z_q =(z_{s_{ij}})
zq=(zsij)很容易被恢复并解码为
x
^
=
G
(
z
q
)
\hat{x} = G(z_q)
x^=G(zq)的图像。
因此,选择s中索引的某些排序后,图像生成可以表示为自回归的下一个索引的预测:给定索引
s
<
i
s_{<i}
s<i,transformer学习预测可能的下一个索引的分布,即
p
(
s
i
∣
s
<
i
)
p(s_i|s_{<i})
p(si∣s<i),以计算
p
(
s
)
=
∏
i
p
(
s
i
∣
s
<
i
)
p(s) =\prod_i p(s_i|s_{<i})
p(s)=∏ip(si∣s<i)的完整表示的似然。这允许我们直接最大化数据表示的对数似然:

3.2.2Conditioned Synthesis
在许多图像合成任务中,用户需要通过提供额外的信息来控制生成过程。这个信息,我们称之为c,可以是描述整个图像类的一个标签,甚至是另一个图像本身。接下来的任务是在给定信息c的情况下学习序列的似然:

如果条件信息c有空间范围,我们首先学习另一个VQGAN,利用transformer的自回归结构,用新获得的codebook
Z
C
\mathcal{Z}_C
ZC再次获得一个基于索引的表示
r
∈
{
0
,
…
,
∣
Z
c
∣
−
1
}
h
c
×
w
c
r∈\{0,…, |Zc|−1\}^{hc×wc}
r∈{0,…,∣Zc∣−1}hc×wc,然后我们可以简单地将r预置prepend到s,并将负对数似然的计算限制在条目
p
(
s
∣
s
<
i
,
r
)
p(s | s_{<i},r)
p(s∣s<i,r)。 这种“只使用解码器”的策略也被成功地用于文本摘要任务[40]。(用另一个VQVAE的codebook去表示条件信息c,然后将得到的索引r加到原来的索引s上面)
3.2.3Generating High-Resolution Images
transformer的注意机制限制了其输入s的序列长度h·w。
虽然我们可以调整我们的VQGAN的下采样块数m来将大小为H×W的图像缩小到
h
=
H
/
2
m
×
w
=
W
/
2
m
h=H/2^m×w=W/2^m
h=H/2m×w=W/2m,但我们观察到超过临界值m的重建质量下降,这取决于所考虑的数据集。
因此,为了生成百万像素的图像,我们必须进行分块patch-wise和裁剪,在训练期间将s的长度限制在最大可行的大小。
为了对图像进行采样,我们以滑动窗口的方式使用transformer,如图所示 3.
我们的VQGAN确保,只要数据集的统计信息是近似空间不变的,或者空间条件信息是可用的,可用的上下文仍然足以忠实地对图像建模。
在实践中,这并不是一个限制性要求,因为当它被违反时,即在对齐数据上的无条件图像合成,我们可以简单地以图像坐标为条件,类似于[38]。

4. Experiments
本节评估我们的方法的能力,在整合卷积体系结构的有效性以实现高分辨率图像合成(4.2节)的同时,保留transformers相对于其卷积对等物的优势(4.1节)。
此外,在4.3节中,我们将研究codebook质量如何影响我们的方法。
在第4.4节中,我们通过对大量现有的生成图像合成方法进行定量比较来结束分析。
根据初始实验,我们通常设置
∣
Z
∣
=
1024
|\mathcal{Z}|= 1024
∣Z∣=1024,然后训练所有后续的transformers模型预测长度为16·16的序列,因为这是在12GB VRAM的GPU上训练GPT2-medium架构(307 M参数)[51]的最大可行长度。关于架构和超参数的更多细节可以在附录中找到(表6和表7)。
4.1. Attention Is All You Need in the Latent Space
这里比较的是transformers方法与卷积方法PixelSNAIL。这就提出了一个问题,我们的方法是否保留了transformers优于卷积方法的优势。
为了回答这个问题,我们使用了各种条件任务和无条件任务,并比较了基于transformers的方法和卷积方法的性能。
对于每个任务,我们用m = 4个下采样块训练一个VQGAN,如果需要,还训练另一个用于条件信息的下采样块,然后在相同的表示上训练transformers和PixelSNAIL[10]模型,后者已经在之前的最先进的两阶段方法[53]中使用。
为了更深入的比较,我们在85M和310M参数之间改变模型容量,并调整每个模型的层数以相互匹配。我们观察到PixelSNAIL的训练速度大约是transformers的两倍,因此,为了进行公平的比较,同样的训练时间(P-SNAIL时间)和同样的训练步骤(P-SNAIL步骤)都报告了负的对数似然。
结果:
表1报告了在ImageNet (IN)[14]、Restricted ImageNet (RIN)[57](包括来自ImageNet的动物类子集)LSUN church and Towers (LSUN- CT)上进行无条件图像建模。
对[52]方法获得的深度图条件下的RIN (D-RIN)和[7]方法获得的基于语义布局条件下的Flickr景观图像(S-FLCKR)进行条件图像建模。
注意,对于语义布局,由于其离散性,我们使用交叉熵重构损失来训练第一阶段。
结果表明,当训练相同的时间时,transformer在所有任务上的表现都优于PixelSNAIL,而当训练相同的步数时,差距甚至进一步增大。
这些结果表明,transformers的增益延续到我们提出的两级设置。

4.2. A Unified Model for Image Synthesis Tasks
transformer结构的通用性和通用性使其成为图像合成的一个有前途的候选者。在有条件的情况下,使用额外的信息c,如类标签或分割映射,目标是学习图像的分布,如式(10)所述。使用与4.1节相同的设置(即图像大小256 × 256,潜在大小16 × 16),我们进行各种条件图像合成实验:
(i):语义图像合成,其中我们以ADE20K[72]的语义分割蒙版、web抓取的景观数据集(S-FLCKR)和COCO-Stuff[6]为条件。结果如图4、5、6所示。
(ii):结构到图像,其中我们使用深度或边缘信息来合成来自RIN和IN的图像(见4.1节)。得到的深度到图像和边缘到图像的翻译如图4和图6所示。
(iii):姿势引导合成:没有使用分割或深度图的语义丰富信息,图4显示,可以使用与之前实验相同的方法,在DeepFashion[41]数据集上构建形状条件生成模型。
(iv):随机超分辨率,以低分辨率图像为条件信息,上采样。我们在ImageNet上将模型的上采样因子训练为8,结果如图6所示。
(v):类条件图像合成:这里条件信息c是描述感兴趣的类标签的单一指标。对RIN数据集进行条件抽样的结果如图4所示。
所有这些例子都使用了相同的方法。transformer不需要特定于任务的体系结构或模块,它的灵活性允许我们为每个任务学习适当的交互,而VQGAN——可以在不同的任务之间重用——导致了较短的序列长度。综上所述,该方法可被理解为一种有效的、通用的条件图像合成机制。请注意,每个实验的附加结果可在附录C节中找到。



High-Resolution Synthesis:
第3.2节中介绍的滑动窗口方法可以实现超过256 × 256像素分辨率的图像合成。
我们评估了LSUN-CT和FacesHQ上的无条件图像生成(见4.3节)和DRIN、COCO-Stuff和S-FLCKR上的条件合成,结果如图1、6和补充图(图17-27)所示。
注意,这种方法原则上可以用于生成任意比例和大小的图像,前提是感兴趣的数据集的图像统计信息是近似空间不变的或空间信息是可用的。
将这种方法应用到S-FLCKR上的语义布局图像生成中,可以获得令人印象深刻的结果,其中,m = 5可以学习到一个强VQGAN,因此它的codebook和条件信息为transformer提供了足够的上下文,以便在兆像素范围内生成图像。(这里的m是上面提到的VQGAN的下采样块。)
4.3. Building Context-Rich Vocabularies
上下文丰富的词汇有多重要?
为了研究这个问题,我们进行了实验,在实验中,transformer架构保持固定,而编码到第一阶段表示中的上下文数量通过我们的VQGAN的下采样块的数量而变化。
我们以图像输入和结果表示之间边长的约简因子来指定上下文编码的数量,即将大小为H ×W的第一阶段图像编码为大小为H/f×W/f的离散编码用因子f表示。对于f = 1,我们重现了[8]的方法,用k = 512的RGB值的k-means聚类来替换我们的VQGAN。
在训练过程中,我们一直使用裁剪图像来为transformer获取尺寸为16 × 16的输入,即在第一阶段用因子f对图像建模时,我们使用尺寸为16f × 16f的裁剪。为了从模型中取样,我们总是按照第3节所述的滑动窗口方式应用它们。
Results:图7显示了在FacesHQ上无条件合成人脸的结果(为CelebA-HQ[27]和FFHQ[29]的结合)。
它通过增加transformer的有效接收域,清楚地证明了强大的vqgan的好处。
对于小的接收域,或等价的小f,模型不能捕获相干结构。
当中间值f = 8时,图像的整体结构可以近似化,但面部特征(如半胡须脸)和图像不同部分的视角会出现不一致。
只有我们完整设置的f = 16才能合成高保真度样本。
对于S-FLCKR条件设置的类似结果,我们参考附录(图10和第B节)。
为了定量地评估我们的方法的有效性,我们比较了直接在像素上训练transformer的结果,以及在给定固定的计算预算下,在f = 2的VQGAN潜码上训练它的结果。
同样,我们遵循[8],在CIFAR10上学习一个包含512个RGB值的字典,直接在像素空间上操作,并在我们的VQGAN上用16 × 16 = 256的潜在代码训练相同的transformer架构。
我们观察到FIDs提高了18.63%,图像采样速度提高了14.08倍。

4.4. Quantitative Comparison to Existing Models
在本节中,我们研究如何定量地比较我们的方法与现有的生成图像合成模型。
特别是,我们评估了我们的模型在FID方面的性能,并与各种已建立的模型(GANs, VAEs, Flows, AR, Hybrid)进行了比较
(i) 表2中的语义合成(其中我们与[46,65,31,9]进行了比较)
和(ii)表3中的无条件人脸合成。
此外,为了与原始的VQVAE-2模型[53]进行直接比较,我们使用dim
Z
\mathcal{Z}
Z = 16384, f = 16的VQGAN对256 × 256的图像训练一个类条件ImageNet transformer,并与表4中的BigGAN[4]和MSP[18]进行比较。
请注意,我们的模型使用的参数比VQVAE-2少10倍, VQVAE-2的估计参数计数为13.5B(基于https://github.com/rosinality/ vq-vae-2-pytorch的估计)。
虽然一些任务专门化GAN模型报告了更好的FID分数,但我们的方法提供了一个统一的模型,在广泛的任务中工作良好,同时保留了编码和重建图像的能力。
因此,它弥合了纯粹对抗性办法和基于似然的办法之间的差距。图11、12、13、14中含有定性样品,对应于表4中定量分析的结果。



How good is the VQGAN?:
通过codebook获得的重构FID提供了在其上训练的生成模型的可实现FID的下界。
为了量化VQGAN在VQVAE2上的性能增益,我们在ImageNet上评估这个指标,并在表5中报告结果。
我们的VQGAN性能优于VQVAE-2,同时提供了更多的压缩(seq。长度256 vs. 5120 = 322 + 642)。
正如预期的那样,VQGAN的更大版本(更大的代codebook大小或更长的code长度)进一步提高了性能。
在我们的模型中使用与VQVAE-2中相同的分层codebook设置可以提供最好的重构FID,尽管代价是一个非常长的、因此不实用的序列。
此外,从图9可以定性地看出,标准VQVAE无法实现这种压缩;对应的reconstruction-FIDs read:VQVAE 254.4;Vqgan 5.7。从该VQVAE采样不能达到低于254.4的FIDs,而我们的VQGAN在使用PixelSNAIL时达到21.93,在使用transformer时达到11.44(见表3)。

5. Conclusion
这篇论文解决了以前transformers仅限制于使用低分辨率图像的基本挑战。
我们提出了一种方法,将图像表示为感知丰富的图像成分的组合,从而克服了直接在像素空间建模图像时的不可行的二次复杂度。(降低复杂度)
用CNN架构建模的成分和用transformer架构建模的成分充分发挥了它们互补优势的潜力,从而允许我们用transformer-based的架构来表示高分辨率图像合成的第一个结果。
在实验中,我们的方法通过合成百万像素范围的图像,并优于最先进的卷积方法,证明了卷积归纳偏差的效率和transformers的表达能力。
它配备了一个通用的条件合成机制,为新的神经渲染方法提供了许多机会。