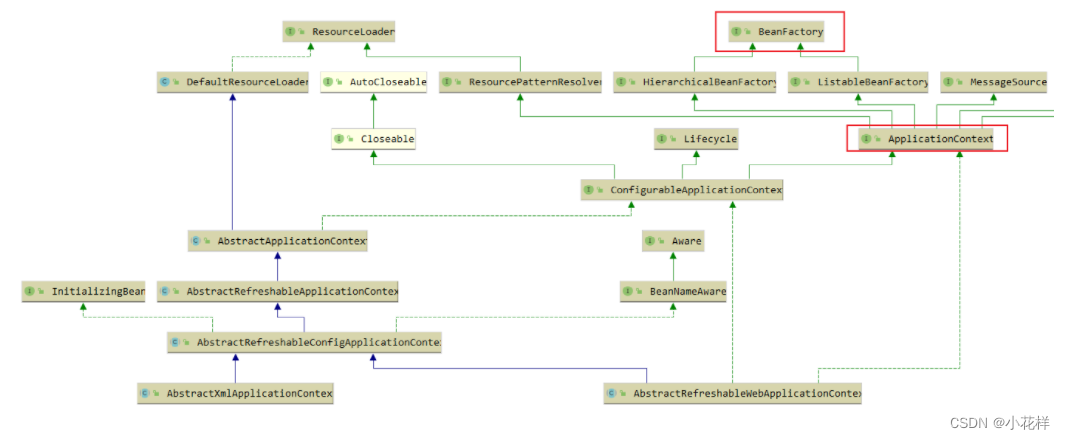
原文链接和代码链接A Self-Attentive model for Knowledge Tracing | Papers With Code
motivation:传统方法面临着处理稀疏数据时不能很好地泛化的问题。
本文提出了一种基于自注意力机制的知识追踪模型 Self Attentive Knowledge Tracing (SAKT)。其本质是用 Transformer 的 encoder 部分来做序列任务。具体从学生过去的活动中识别出与给定的KC相关的KC,并根据所选KC相对较少的KC预测他/她的掌握情况。由于预测是基于相对较少的过去活动,它比基于RNN的方法更好地处理数据稀疏性问题。
模型结构

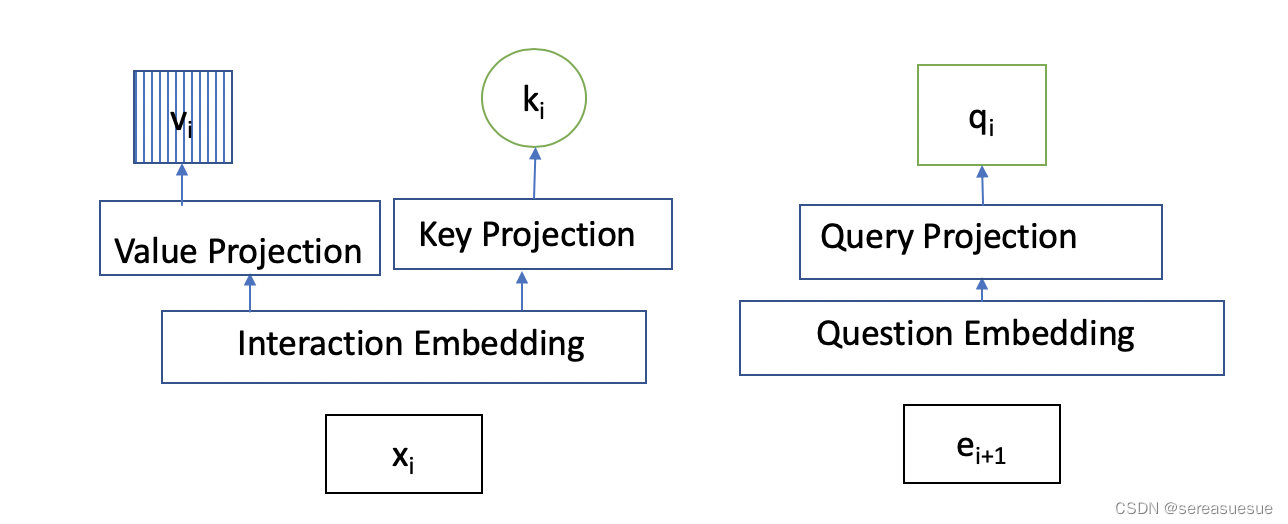

输入编码
交互信息 通过公式
转变成一个数字,总量为 2E。
我们 用Interaction embedding matrix 训练一个交互嵌入矩阵,
被用来为序列中的每个元素
Exercise 编码 利用 exercise embedding matrix训练练习嵌入矩阵,,每行代表一个题目ei
Position Encoding
自动学习,n 是序列长度。
最终编码层的输出如下

self.qa_embedding = nn.Embedding(
2 * n_skill + 2, self.qa_embed_dim, padding_idx=2 * n_skill + 1
)
self.pos_embedding = nn.Embedding(self.max_len, self.pos_embed_dim)
#定义
#计算
qa = self.qa_embedding(qa)
pos_id = torch.arange(qa.size(1)).unsqueeze(0).to(self.device)
pos_x = self.pos_embedding(pos_id)
qa = qa + pos_x注意力机制
Self-attention layer采用scaled dotproduct attention mechanism。
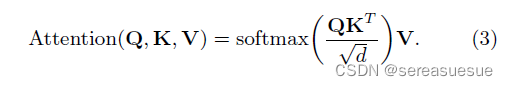
Self-attention的query、key和value分别为:

self.multi_attention = nn.MultiheadAttention(
embed_dim=self.embed_dim, num_heads=self.num_heads, dropout=self.dropout
)
attention_out, _ = self.multi_attention(q, qa, qa, attn_mask=attention_mask)
Causality:因果关系也是mask 避免未来交互对现在的
Feed Forward layer
用一个简单的前向传播网络将self-attention的输出进行前向传播。
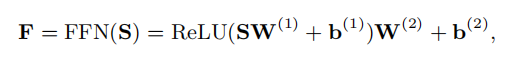
class FFN(nn.Module):
def __init__(self, state_size=200, dropout=0.2):
super(FFN, self).__init__()
self.state_size = state_size
self.dropout = dropout
self.lr1 = nn.Linear(self.state_size, self.state_size)
self.relu = nn.ReLU()
self.lr2 = nn.Linear(self.state_size, self.state_size)
self.dropout = nn.Dropout(self.dropout)
def forward(self, x):
x = self.lr1(x)
x = self.relu(x)
x = self.lr2(x)
return self.dropout(x)剩余连接:剩余连接[2]用于将底层特征传播到高层。因此,如果低层特征对于预测很重要,那么剩余连接将有助于将它们传播到执行预测的最终层。在KT的背景下,学生尝试练习属于某个特定概念的练习来强化这个概念。因此,剩余连接有助于将最近解决的练习的嵌入传播到最终层,使模型更容易利用低层信息。在自我注意层和前馈层之后应用剩余连接。
层标准化:在[1]中,研究表明,规范化特征输入有助于稳定和加速神经网络。我们在我们的架构中使用了层规范化目的层在自我注意层和前馈层也应用了归一化。
attention_out = self.layer_norm1(attention_out + q)# Residual connection ; added excercise embd as residual because previous ex may have imp info, suggested in paper.
attention_out = attention_out.permute(1, 0, 2)
x = self.ffn(attention_out)
x = self.dropout_layer(x)
x = self.layer_norm2(x + attention_out)# Layer norm and Residual connectionPrediction layer
self-attention的输出经过前向传播后得到矩阵F,预测层是一个全连接层,最后经过sigmod激活函数,输出每个question的概率
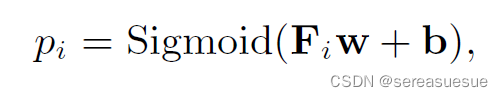
模型的目标是预测用户答题的对错情况,利用cross entropy loss计算(y_true, y_pred)

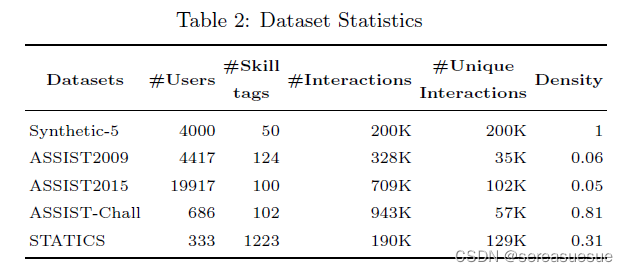
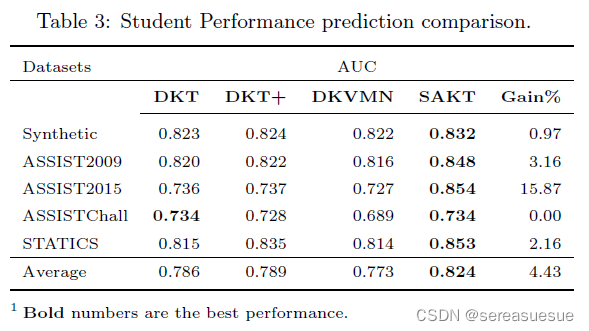
实验
# -*- coding:utf-8 -*-
"""
Reference: A Self-Attentive model for Knowledge Tracing (https://arxiv.org/abs/1907.06837)
"""
import torch
import torch.nn as nn
import deepkt.utils
import deepkt.layer
def future_mask(seq_length):
mask = np.triu(np.ones((seq_length, seq_length)), k=1).astype("bool")
return torch.from_numpy(mask)
class FFN(nn.Module):
def __init__(self, state_size=200, dropout=0.2):
super(FFN, self).__init__()
self.state_size = state_size
self.dropout = dropout
self.lr1 = nn.Linear(self.state_size, self.state_size)
self.relu = nn.ReLU()
self.lr2 = nn.Linear(self.state_size, self.state_size)
self.dropout = nn.Dropout(self.dropout)
def forward(self, x):
x = self.lr1(x)
x = self.relu(x)
x = self.lr2(x)
return self.dropout(x)
class SAKTModel(nn.Module):
def __init__(
self, n_skill, embed_dim, dropout, num_heads=4, max_len=64, device="cpu"
):
super(SAKTModel, self).__init__()
self.n_skill = n_skill
self.q_embed_dim = embed_dim
self.qa_embed_dim = embed_dim
self.pos_embed_dim = embed_dim
self.embed_dim = embed_dim
self.dropout = dropout
self.num_heads = num_heads
self.max_len = max_len
self.device = device
self.q_embedding = nn.Embedding(
n_skill + 1, self.q_embed_dim, padding_idx=n_skill
)
self.qa_embedding = nn.Embedding(
2 * n_skill + 2, self.qa_embed_dim, padding_idx=2 * n_skill + 1
)
self.pos_embedding = nn.Embedding(self.max_len, self.pos_embed_dim)
self.multi_attention = nn.MultiheadAttention(
embed_dim=self.embed_dim, num_heads=self.num_heads, dropout=self.dropout
)
self.key_linear = nn.Linear(self.embed_dim, self.embed_dim)
self.value_linear = nn.Linear(self.embed_dim, self.embed_dim)
self.query_linear = nn.Linear(self.embed_dim, self.embed_dim)
self.layer_norm1 = nn.LayerNorm(self.embed_dim)
self.layer_norm2 = nn.LayerNorm(self.embed_dim)
self.dropout_layer = nn.Dropout(self.dropout)
self.ffn = FFN(self.embed_dim)
self.pred = nn.Linear(self.embed_dim, 1, bias=True)
def forward(self, q, qa):
qa = self.qa_embedding(qa)
pos_id = torch.arange(qa.size(1)).unsqueeze(0).to(self.device)
pos_x = self.pos_embedding(pos_id)
qa = qa + pos_x
q = self.q_embedding(q)
q = q.permute(1, 0, 2)
qa = qa.permute(1, 0, 2)
attention_mask = future_mask(q.size(0)).to(self.device)
attention_out, _ = self.multi_attention(q, qa, qa, attn_mask=attention_mask)
attention_out = self.layer_norm1(attention_out + q)# Residual connection ; added excercise embd as residual because previous ex may have imp info, suggested in paper.
attention_out = attention_out.permute(1, 0, 2)
x = self.ffn(attention_out)
x = self.dropout_layer(x)
x = self.layer_norm2(x + attention_out)# Layer norm and Residual connection
x = self.pred(x)
return x.squeeze(-1), None