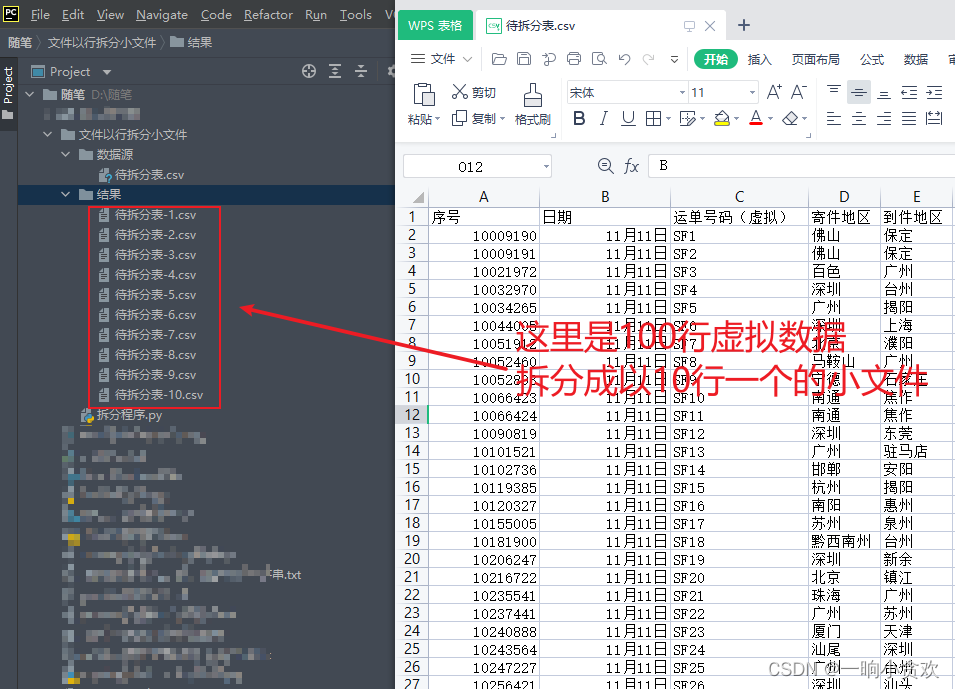
最近接到一个需求,就是把非常大的CSV文件,电脑根本打不开(或者打开也不能完全展现所有的数据),以每 80万(不够80万行的也独自成为一个单独的文件) 行进行拆分成一个小文件,各位小伙伴在日常工作中有没有遇到呢,怎么解决,我当然首选Python
目录-本文章是CSV版(excel版同理)
- 最近接到一个需求,就是把非常大的CSV文件,电脑根本打不开(或者打开也不能完全展现所有的数据),以每 80万(不够80万行的也独自成为一个单独的文件) 行进行拆分成一个小文件,各位小伙伴在日常工作中有没有遇到呢,怎么解决,我当然首选Python
- 1、准备下载的库
- 2、目录结构
- 2、奉上代码与注释
- 希望对大家有帮助
- 致力于办公自动化的小小程序员一枚
- 致力于写出清楚的博客
- 都看到这了,关注+点赞+收藏=不迷路!!
1、准备下载的库
import os (内置库)
import pandas
pip install pandas
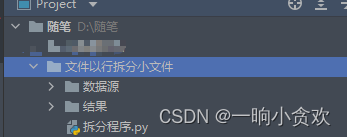
2、目录结构
1、文件夹:数据源:准别好待拆分的CSV(EXCEL)文件,可以存多个,会依次拆分
2、结果:保存的结果存放地
2、奉上代码与注释
import os
import pandas
for f in os.listdir("./数据源/"): # 读取【数据源】文件夹内所有的文件
df_head = pandas.read_csv("./数据源/" + f, dtype=str, keep_default_na="",encoding='gbk',index_col=False).head(0) # 获取表头
head = list(df_head)
df1 = pandas.read_csv("./数据源/"+f,dtype=str,keep_default_na="",encoding='gbk',index_col=False) # 读取每个文件数据
df2 = df1.values.tolist()# 转化列表
n = 10 #指定行数
count = 0
for df2 in [df2[i:i + n] for i in range(0, len(df2), n)]:
data = df2
data2 = pandas.DataFrame(data,index=None,columns=None)
# print(data2)
count+=1
data2.to_csv("./结果/"+"结果"+str(count)+".csv",index=False) # 保存