文章目录
- 【小样本分割 2022 ECCV】DCAMA
- 摘要
- 1. 简介
- 2. 网络
- 2.1 整体架构
- 2.2 特征提取与掩模制备
- 2.3 多尺度多层交叉注意加权掩码聚合。
- 2.4 掩码特性混合器。
- 3. 代码
【小样本分割 2022 ECCV】DCAMA
论文题目:Dense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation
中文题目:用于小样本分割的密集交叉查询和支持度加权注意力掩模聚合
论文链接:https://arxiv.org/abs/2207.08549
论文代码:https://github.com/pawn-sxy/DCAMA.git
论文团队:北京大学&东南大学&腾讯
发表时间:2022年7月
DOI:
引用:Shi X, Wei D, Zhang Y, et al. Dense cross-query-and-support attention weighted mask aggregation for few-shot segmentation[C]//Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XX. Cham: Springer Nature Switzerland, 2022: 151-168.
引用数:8【截止时间:2023年5月1号】
摘要
小样本分割(FSS)的研究引起了极大的关注,其目标是分割一个查询图像中的目标对象,仅给出几个标注的目标类支持图像。这个具有挑战性的任务的关键是充分利用信息的支持图像,通过利用细粒度的查询和支持图像之间的相关性。然而,大多数现有的方法要么将支持信息压缩到几个类的原型中,要么使用部分支持信息(例如。例如,在一个实施例中,仅前景),导致不可忽略的信息损失。
在本文中,我们提出了密集像素级交叉查询和支持关注加权掩码聚合(DCAMA),通过配对查询和支持特征之间的多级像素级关联,充分利用前景和背景支持信息。
DCAMA在Transformer体系结构中利用点积关注度实现,将每个查询像素视为一个令牌,计算其与所有支持像素的相似性,并将其分割标记预测为所有支持像素标记的加法聚合–根据相似性加权。 基于DCAMA的独特公式,我们进一步提出了有效的N镜头分割的一次推理,即同时收集所有支持图像的像素进行掩模聚合。
1. 简介
近年来,深度神经网络(deep neural networks,DNNs)在语义分割方面取得了显著进展。
然而,深度神经网络的成功在很大程度上依赖于大规模的数据集,在这些数据集中,每个目标类都可以获得丰富的训练图像来进行分割。
在极低数据的情况下,由于泛化能力差,深度神经网络的性能可能会在以前没有看到的类上迅速下降,只有很少的例子。 相比之下,人类能够利用从生活经验中积累的先验知识,在低数据量的情况下迅速学习新的任务[16]。
小样本学习(FSL)[11,12]是一种机器学习范式,旨在模仿人类学习者的这种泛化能力,在这种能力下,一个模型可以快速适应只给出几个例子的新任务。
具体来说,给出了一个包含新类和有限样本的支持集用于模型自适应,然后在包含相同类样本的查询集上对支持集进行评估。 FSL在计算机视觉领域进行了积极探索,如图像分类[42]、图像检索[39]、图像字幕和视觉问答、语义分割等。 在本文中,我们研究了小样本语义分割(FSS)问题。
FSS的关键挑战是充分利用包含在小支持集中的信息。 以前的大多数工作都遵循原型化的概念[33],其中支持图像中包含的信息通过类平均池[44,48,50]或聚类[20,45]抽象成类原型,根据这些原型匹配查询特征进行分割标签预测。 然而,原型方法最初是用于图像分类任务的,当应用于小样本分割任务时,可能会导致本已稀缺的样本中所包含的宝贵信息的大量丢失。 鉴于分割任务的密集性,[24,43,47]最近提出探索查询特征和前景支持特征之间的像素级相关性,避免了原型中的信息压缩。 然而,这些方法完全忽略了支持图像背景区域所包含的丰富信息。
张等人[49]在计算像素级相关性时也考虑了背景支持特征; 然而,他们只考虑了均匀采样支持像素的稀疏相关性,造成了另一种潜在的信息损失。
因此,以前的工作没有充分研究查询特征与FSS的前景和背景支持特征之间的密集像素相关性。
在这项工作中,我们提出了一种基于密集像素的交叉查询支持注意力加权掩码聚合(DCAMA)算法,该算法充分利用了支持图像中所有可用的前景和背景特征。
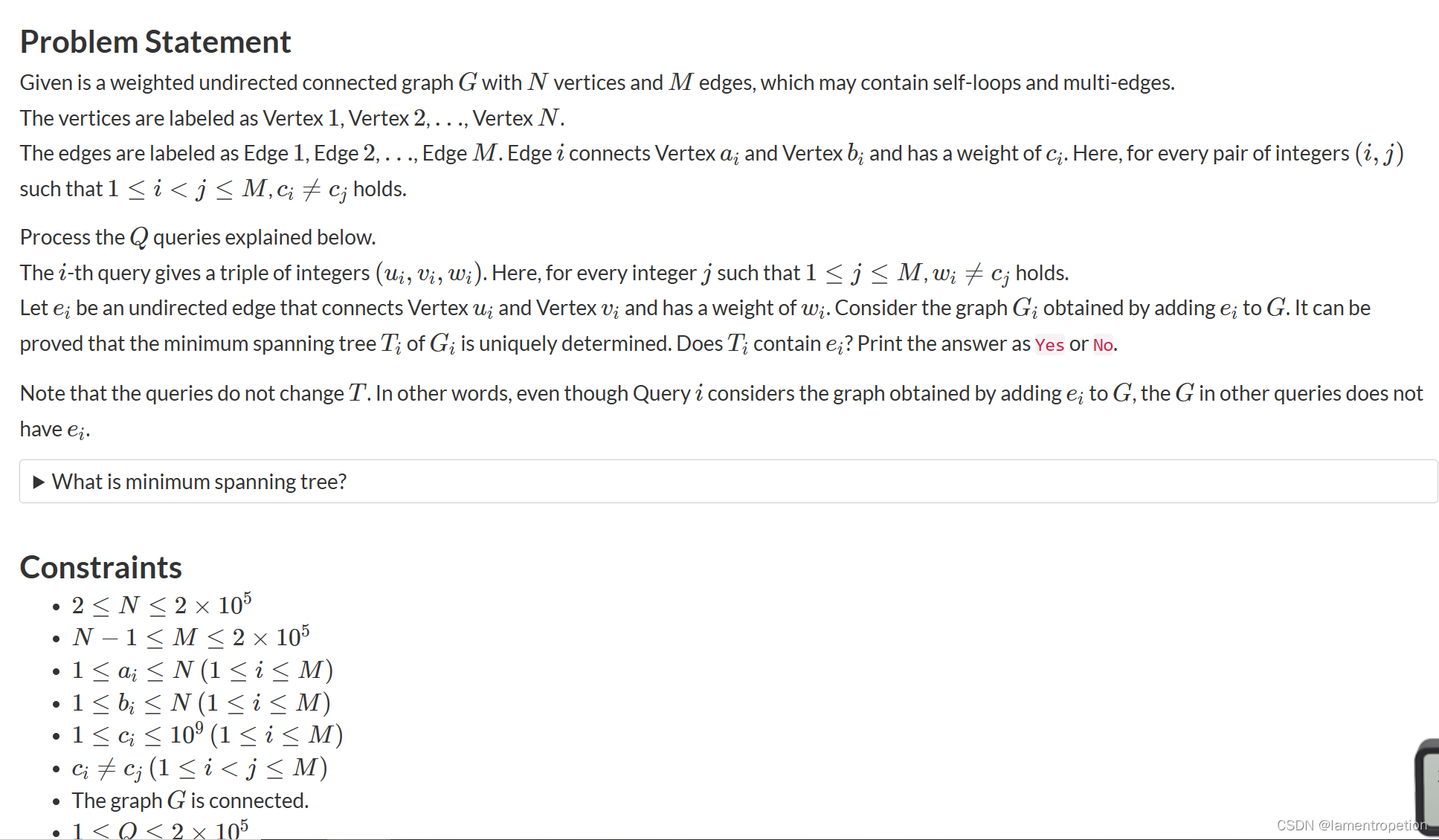
如图所示 1.我们观察到,查询像素的掩码值可以通过支持掩码值的加法聚合来预测,并根据其与相应支持图像像素(包括前景和背景)的相似性按比例加权。 这是直观的:如果查询像素在语义上接近前景支持像素,后者将投票给前景作为前者的掩码值,反之亦然–度量学习的一个实施例[15]。
另外,我们注意到,对于一个查询图像的所有像素的DCAMA计算流水线可以很容易地用Transformer体系结构[40]中的点积关注机制来实现,其中每个像素都被视为一个令牌,
所有查询像素的拉平特征组成查询矩阵Q,
所有支持图像像素的拉平特征组成关键矩阵K,
支持掩码像素的拉平标记值组成值矩阵V。
然后,查询掩码可以通过 s o f t m a x ( Q K T ) V \mathrm{softmax}(Q K^{T})V softmax(QKT)V方便有效地计算。
对于实际实现,我们遵循多头关注[40],以及多尺度[18]和多层[24]特征关联的常见做法;
此外,聚合掩码与跳过连接支持和查询特征相结合,用于精细的查询标签预测。 我们将表明,所提出的方法不仅产生了优于以前最好的方法[24]的性能,而且在训练中表现出更高的效率。
此外,以往采用像素级相关流水线的工作很少关注从1-shot 到小样本分割的扩展:它们要么进行单独的1-shot推理,然后进行集成[24],要么使用一致采样的支持像素子集进行推理[49]。
这两种解决方案都导致了像素级信息的丢失,这是由于分别在集成和删除潜在有用像素之前进行了独立的推断。 相反,我们充分利用支持集,利用所有支持图像的所有像素和掩码分别组成K矩阵和V矩阵。
同时,我们使用相同的1-shot训练模型在不同的小样本设置下进行测试。 这不仅在计算上是经济的,而且是合理的,因为模型实际上从训练中学到的是一个用于交叉查询和支持关注的度量空间。 只要很好地学习了度量空间,从1-shot 扩展到few-shot 只是从更多支持像素聚合查询掩码。
我们方法的概念概述。 查询掩码通过支持掩码值的按像素的加法聚合直接预测,该加法聚合由密集的交叉查询和支持关注加权。
2. 网络
2.1 整体架构
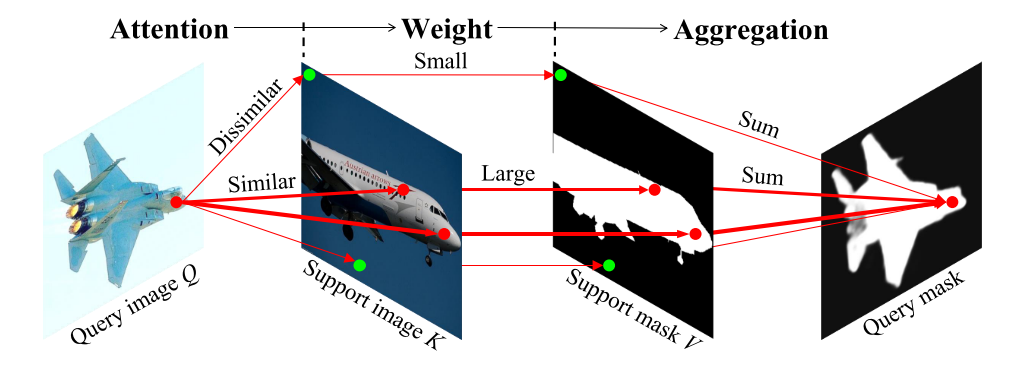
提出的框架的流水线,显示在1-shot设置。 DCAMA:密集交叉查询和支持注意力加权掩码聚合。
我们的DCAMA框架的概述显示在图 2. 为了简单起见,
框架的输入是查询图像、支持图像和掩码。
- 首先,通过预先训练的特征提取器对查询和支持图像进行处理,得到多尺度的查询和支持特征。 同时,支持掩模被下采样到与图像特征匹配的多个尺度。
- 其次,每个尺度上的查询特征、支持特征和支持掩码被输入到与Q、K和V相同尺度的多层DCAMA块,用于多头关注[40]和查询掩码的聚合。 在多个尺度上聚合的查询掩码被处理并与卷积、上采样(如果需要)和元素添加相结合。
- 第三,前一阶段的输出(多尺度DCAMA)通过跳过连接与多尺度图像特征连接,然后通过混合器混合生成最终的查询掩码。 在下面,我们依次描述这三个阶段中的每一个阶段,重点放在第二个阶段–这是我们的主要贡献。
2.2 特征提取与掩模制备
首先,将查询图像和支持图像输入到预先训练的特征提取器中,以获得它们的多尺度多层特征映射 { F i , l q } \{F_{i,l}^q\} {Fi,lq}和 { F i , l s } \{F_{i,l}^s\} {Fi,ls}的集合,其中 i i i是特征映射相对于输入图像的尺度,对于我们所使用的特征提取器来说, i i i是 { 1 4 , 1 8 , 1 16 , 1 32 } \{\frac{1}{4},\frac{1}{8},\frac{1}{16},\frac{1}{32}\} {41,81,161,321},而 l ∈ { 1 , … , L i } l\in\{1,\ldots,L_i\} l∈{1,…,Li}是特定尺度 i i i的所有层的索引。
不同于以往的大多数工作只使用每个尺度的最后一层特征图,即 F i , L i F_{i,L_i} Fi,Li,我们遵循Min等人。 [24]也充分利用所有中间层特性。 同时,通过双线性插值生成不同尺度的支持掩码 { M i s } \{M_i^s\} {Mis}。
查询特征、支持特征和尺度为 { 1 4 , 1 8 , 1 16 , 1 32 } \{\frac{1}{4},\frac{1}{8},\frac{1}{16},\frac{1}{32}\} {41,81,161,321}的支持掩码被输入到多层DCAMA块2中,如下所述。
2.3 多尺度多层交叉注意加权掩码聚合。
缩放的点积关注是Transformer[40]体系结构的核心,它被表述为:
Attn
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
/
d
)
V
\operatorname{Attn}(Q,K,V)=\operatorname{softmax}\left(QK^T/\sqrt{d}\right)V
Attn(Q,K,V)=softmax(QKT/d)V
其中,q、k、v是打包到矩阵中的查询、键和值向量的集合,d是查询和键向量的维数。 在本工作中,我们采用EQN。 (1)计算整个查询和支持特征的密集像素关注度,然后用关注度值从支持掩码中权衡查询掩码聚集过程。
在不丧失通用性的前提下,我们用一对泛型查询和支持特征映射 F q , F s ∈ R h × w × c F^q,F^s\in\mathbb{R}^{h\times w\times c} Fq,Fs∈Rh×w×c,其中H,W和C分别为高度,宽度和通道数,以及一个相同大小的泛型支持掩码 M s ∈ R h × w × 1 M^{s}\in{\mathbb{R}}^{h\times w\times1} Ms∈Rh×w×1来描述该机制。 如图所示 3.
首先对二维输入进行拉平处理,将每个像素都看作一个令牌,然后对拉平后的 F q F^q Fq和 F s F^s Fs进行位置编码和线性投影,生成Q和K矩阵。
我们沿用原来的变压器[40]使用不同频率的正弦和余弦函数进行位置编码,并采用多头注意。
对于支撑掩模,只需对其进行展平即可构造V,然后在公式1 中给出标准缩放的点积注意事项。方便地计算每一个头。
最后,对每个令牌的多个头的输出进行平均,并将张量重塑为2D,得到 M ^ q ∈ R h × w × 1 \hat{M}^{q}\in{\mathbb{R}}^{h\times w\times1} M^q∈Rh×w×1,即聚合查询掩码。
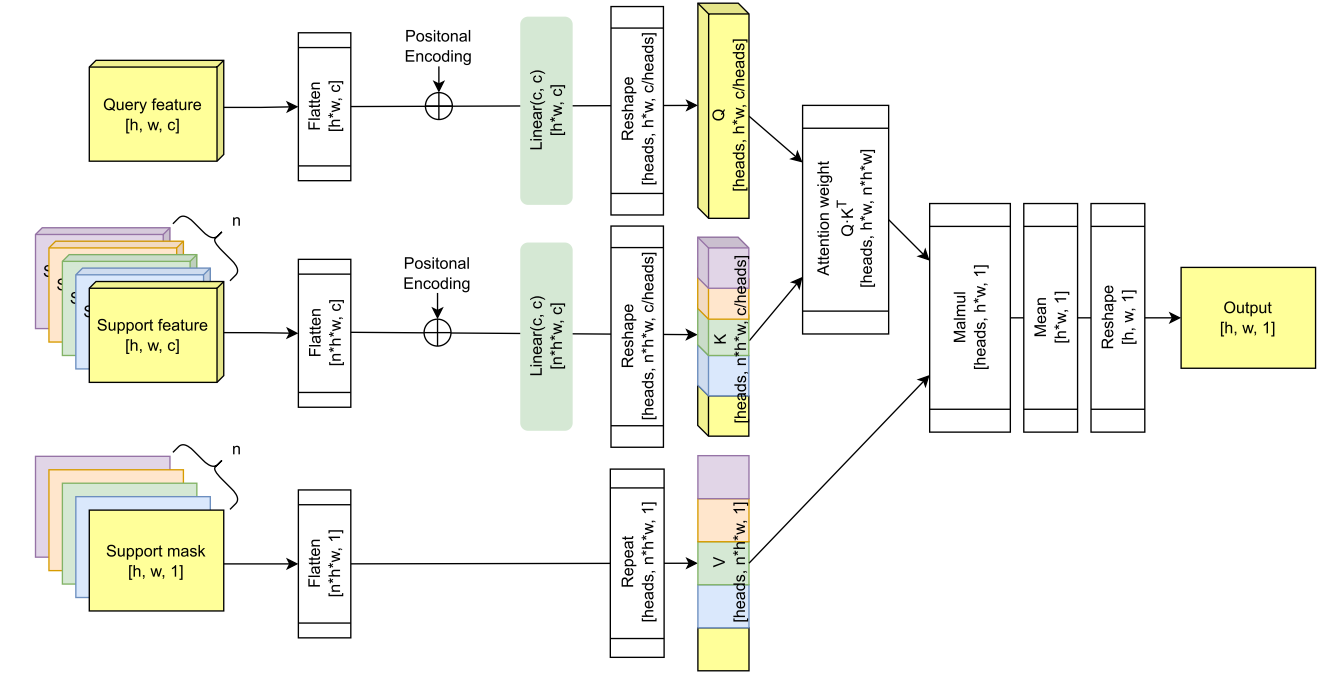
针对一般的N shot 设置(n≥1)的密集交叉查询和支持注意力加权掩码聚合(DCAMA)。
值得解释DCAMA过程的物理意义。 对于特定的查询像素,QKT测量其与所有支持像素的相似性,随后与V的乘法从支持掩码中聚合其掩码值,并按相似性加权。 直观地说,如果它比背景像素更相似(更接近)前景,加权聚合过程将为该像素投票前景,反之亦然。 这样,我们的DCAMA利用所有支持像素–前景和背景–进行有效的度量学习。
在实际实现中,我们对特定尺度I的所有中间层和最后层的查询支持特征对 ( F i , l s , F i , l q ) (F_{i,l}^{s},F_{i,l}^{q}) (Fi,ls,Fi,lq), 分别进行DCAMA,并将独立聚合的查询掩码集串联起来,得到 M ^ i q = constat { M ^ i , l q ∣ l = 1 , … , L i } . \hat{M}_i^q=\operatorname{constat}\{\hat{M}_{i,l}^q|l=1,\ldots,L_i\}. M^iq=constat{M^i,lq∣l=1,…,Li}.。 在特定尺度的所有层特征上的DCAMA操作后加上级联构成了一个多层DCAMA块(参见图2),我们有三个这样的块,分别用于尺度 i ∈ { 1 8 , 1 16 , 1 32 } , i\in\{\frac{1}{8},\frac{1}{16},\frac{1}{32}\}, i∈{81,161,321},。
然后,用三个信道数从 L i L_i Li逐渐增加到128的conv块对 M ^ i q \hat{M}_i^q M^iq进行处理,用双线性插值上采样,用元素加法与一倍大尺度的对应体合并,再用一个恒定信道数的另外三个conv块进行处理。
前三个conv块准备 M ^ i q \hat{M}_i^q M^iq与后三个conv块的较大尺度的 M ^ i q \hat{M}_i^q M^iq进行有效的尺度间集成。
这个过程从 i = 1 32 i=\frac{1}{32} i=321一直重复到 1 8 \frac{1}{8} 81,产生一个中间查询掩码集合,将其与跳过连接的图像特征融合,用于最终预测。
2.4 掩码特性混合器。
基于一般语义分割中跳过连接设计的成功[30,52],我们还提出通过级联将图像特征跳过连接到前一阶段的输出(需要时上采样)(图2)。 具体地说,我们基于我们的经验实验(包括在补充材料中)跳过连接1-4和1-8尺度上的最后一层特征。 然后,通过三个掩码-特征混合器模块对串联的中间查询掩码和图像特征进行融合,每个混合器模块包含两系列卷积和RELU操作。 混频器块将输出通道的数目逐渐减少到2个(分别用于前景和背景)以进行单向分割,并通过两个交织的上采样操作将输出大小恢复到输入图像的大小。