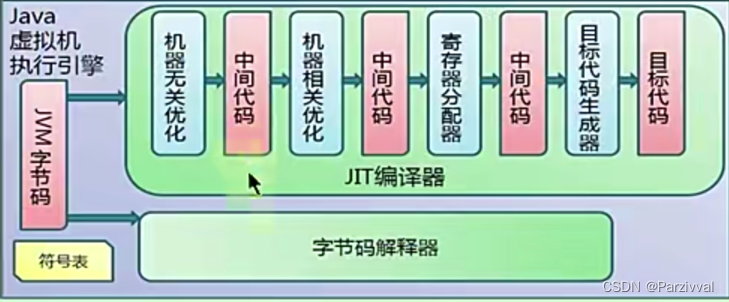
目录
1. 谁标记数据集
2. 数据集的来源
3.数据预处理
4. 标记数据集的方法
5. 数据多样性
6. 这样标记的数据的不足之处
名词解释
1. 谁标记数据集
OpenAI 公司在Upwork平台上和Scale AI公司聘请了大约 40 名承包商为他们标记数据,通过筛选测试(screening test)来判断承包商识别和响应敏感提示的能力,以及承包商与研究人员在带有详细说明的标签任务上的一致率。保持承包商团队小规模的目的是助于与一小部分全职执行任务的承包商进行更方便的通信。
2. 数据集的来源
InstructGPT模型中的提示数据集主要包含提交给 OpenAI API 的文本提示,特别是那些使用早期版本的 InstructGPT 模型(通过在范例数据的子集上有监督训练)在 Playground 界面上。使用 Playground 的客户是通过多次通知被告知他们的数据可能随时用于训练 InstructGPT 模型。 没有使用来自使用 API 的客户的数据。
3.数据预处理
通过检查共享长期共同点的提示来启发式地删除重复提示前缀,他们将提示的数量限制为每个用户 ID 200。 为了让验证集和测试集不包含用户在训练集中的数据,他们基于用户 ID 把数据集拆分成训练集,验证集和测试集。 为了避免模型学习潜在敏感的客户详细信息,他们在训练集上过滤掉可以获取个人身份信息 (PII)的提示(prompts)。
4. 标记数据集的方法
为了训练第一个 InstructGPT 模型,他们要求贴标签者自己编写提示(prompts)。 这是因为他们需要一个类似指令的提示(instruction-like prompts.)的初始来源来引导这个过程,而这些类型的提示并不经常提交给 OpenAI API 上的常规 GPT-3 模型。 他们要求贴标签者写出三种提示:
- Plain:他们只是要求标记者提出一个任意任务,同时确保任务具有足够的多样性。
- Few-shot:他们要求标注者提出一条指令,以及该指令的多个查询/响应(query/response)对。
- User-based:他们在 OpenAI API 的候补名单申请中陈述了许多用例。 我们要求标签商提出与这些用例相对应的提示。
根据这些提示,他们生成了三个用于微调过程的不同数据集( SFT 数据集, RM 数据集, PPO 数据集):
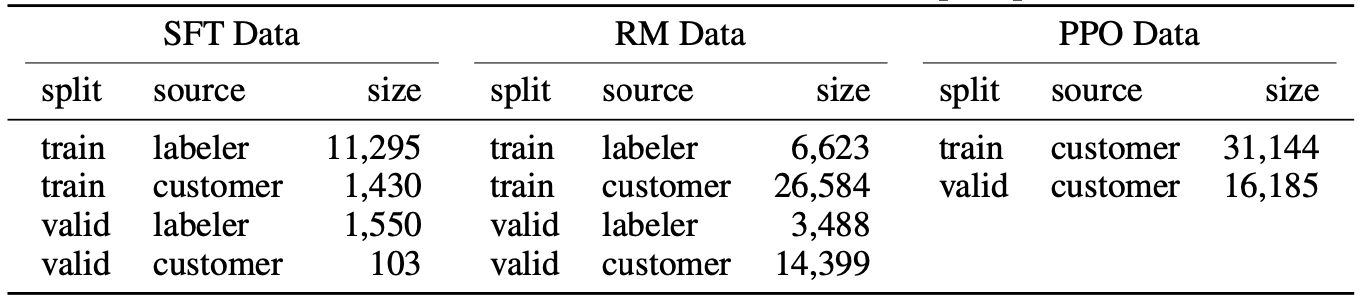
上表展示了用于训练/验证 SFT、RM 和 RL 模型的数据集的大小,以及提示是标签承包商编写的还是来自OpenAI API。
(1) SFT 数据集,用于训练SFT 模型的打标签者范例数据,SFT 数据集包含大约 13k 个训练提示(来自 API 和 labeler-written),对于 SFT,请注意,标签商编写的提示比客户提示多得多,这是因为,在项目开始时,标签商编写带有用户界面的说明,要求他们提供总体模板说明以及一些 - 该指令的示例。 他们通过对不同的小样本样本集进行采样,从同一指令综合构建了多个 SFT 数据点。
(2) RM 数据集,带有用于训练的模型输出的标签器排名 我们的 RM, RM 数据集有 33k 个训练提示(来自 API 和 labeler-written),对于 RM,每个提示,他们收集了 K 个输出(从 4 到 9)的排名,并在所有的上训练模型,所以他们训练模型的排名对的数量是一个顺序2个数量级大于提示的数量。
(3) PPO 数据集,没有任何人工标签,用作 RLHF 微调的输入。PPO 数据集有 31k 个训练提示(仅来自 API)。 上表中提供了有关数据集大小的更多详细信息。
5. 数据多样性
他们收集的数据涵盖广泛的类别和用例。 他们的 RM 训练和验证数据集中由承包商标记的类别的多样性。 PPO 数据集的类别分布相似。 他们还在表 7 中显示了他们标记的提示元数据的一个子集。请注意,注释字段在项目过程中发生了变化,因此并非每个提示都对每个字段进行了注释。





他们使用轻量级分类器 (langid.py) 对数据集中所有指令的语言进行分类。 根据他们的经验,数据集(110k 数据点)中约有 96% 被归类为英语,但由于分类器的不准确性,估计实际分数可能为 99% 或更高。
除英语外,还发现了至少 20 种其他语言的一小部分提示:西班牙语、法语、德语、葡萄牙语、意大利语、荷兰语、罗马尼亚语、加泰罗尼亚语、中文、日语、瑞典语、波兰语、丹麦语、土耳其语、印度尼西亚语、捷克语、挪威语 、韩语、芬兰语、匈牙利语、希伯来语、俄语、立陶宛语、世界语、斯洛伐克语、克罗地亚语、斯瓦希里语、爱沙尼亚语、斯洛文尼亚语、阿拉伯语、泰语、越南语、马拉雅拉姆语、希腊语、阿尔巴尼亚语和藏语。
表 8 显示了每个客户为数据集贡献的平均提示数。 在表 9 中,报告了用于训练各种模型的提示长度(以令牌为单位)的描述性统计信息,在表 10 中,按用例细分了令牌长度。 最后,还在表 11 中报告了用于我们的 SFT 模型的承包商编写的演示的长度,包括承包商编写的和标签商编写的提示。
6. 这样标记的数据的不足之处
InstructGPT 模型的行为部分取决于从我们的承包商那里获得的人工反馈。 一些标记任务依赖于价值判断,这些判断可能会受到他们承包商的身份、他们的信仰、文化背景和个人历史的影响。 他们聘请了大约 40 名承包商,以他们在筛选测试中的表现为指导,筛选测试旨在判断他们识别和响应敏感提示的能力,以及他们与研究人员在带有详细说明的标签任务上的一致率。 他们让他们的承包商团队保持小规模,因为这有助于与一小部分全职执行任务的承包商进行高带宽通信。 然而,这个群体显然不能代表将使用我们部署的模型并受其影响的所有人群。 举个简单的例子,我们的贴标签者主要是说英语的,我们的数据几乎完全由英文说明组成。他们还有很多方法可以改进我们的数据收集设置。 例如,出于成本原因,大多数比较仅由 1 个承包商标记。 多次标记示例可以帮助确定我们的承包商不同意的领域,因此单个模型不太可能与所有这些领域保持一致。 在出现分歧的情况下,可能不需要与平均标签偏好保持一致。 例如,当生成不成比例地影响少数群体的文本时,我们可能希望属于该群体的标签者的偏好得到更大的权重。
名词解释
| 缩写名词 | 全称 | 注解 |
| RLHF | Reinforcement Learning from Human Feedback | |
| GPT | Generative Pre-Trained Transformer | |
| LMs | Lanaguage Models | |
| SFT | Supervised fine-tuning on human demonstrations | |
| PPO | proximal policy optimization | Proximal Policy Optimization (PPO) is presently considered state-of-the-art in Reinforcement Learning. The algorithm, introduced by OpenAI in 2017 |
| FLAN | Finetuned Language Net. | FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS https://arxiv.org/pdf/2109.01652.pdf |
| T0 | T0 is an encoder-decoder model that consumes textual inputs and produces target responses | |
| RM | reward model | |




![[oeasy]python0145_版本控制_git_备份还原](https://img-blog.csdnimg.cn/img_convert/af1665be24a9537f9a9bec1c4b2da1d8.png)

![[计算机图形学]相机与透镜(前瞻预习/复习回顾)](https://img-blog.csdnimg.cn/55ce0064aa1b4ac2ac9166dca4d818c1.png)