鲲鹏devkit性能分析工具介绍(三)
本篇主要讲解鲲鹏devkit性能分析工具的访存分析功能
访存分析
访存统计分析基于CPU访问缓存和内存的PMU事件,分析存储的访问次数、命中率、带宽等情况。
Miss事件分析基于ARM SPE(Statistical Profiling Extension)的能力实现。SPE针对指令进行采样,同时记录一些触发事件的信息,包括精确的PC指针信息。利用SPE能力可以对业务进行LLC Miss,TLB Miss,Remote Access,Long Latency Load等Miss类事件分析,并精确的关联到造成该事件的代码。用户可以有针对性地修改自己的程序,降低Miss事件发生的几率,提高程序处理性能。
伪共享分析基于ARM SPE(Statistical Profiling Extension)的能力实现。SPE针对指令进行采样,同时记录一些触发事件的信息,包括精确的PC指针信息。利用SPE能力进行伪共享分析,可以得到发生伪共享的次数和比例、指令地址和代码行号、NUMA节点等信息。基于这些信息,用户可以有针对性地修改自己的程序,降低发生伪共享的几率,提高程序处理性能。
NUMA精细化分析基于ARM SPE(Statistical Profiling Extension)能力实现。SPE针对指令进行采样,同时记录一些触发事件的信息,包括精确的PC指针信息。利用SPE能力可以用于收集系统中所有进程的NUMA性能,找到Top N (e.g. N = 10) NUMA性能最差的进程及这些进程中的内存热区,各NUMA节点间内存访问统计矩阵,识别节点间内存访问不平衡状态,并得到相关优化建议。
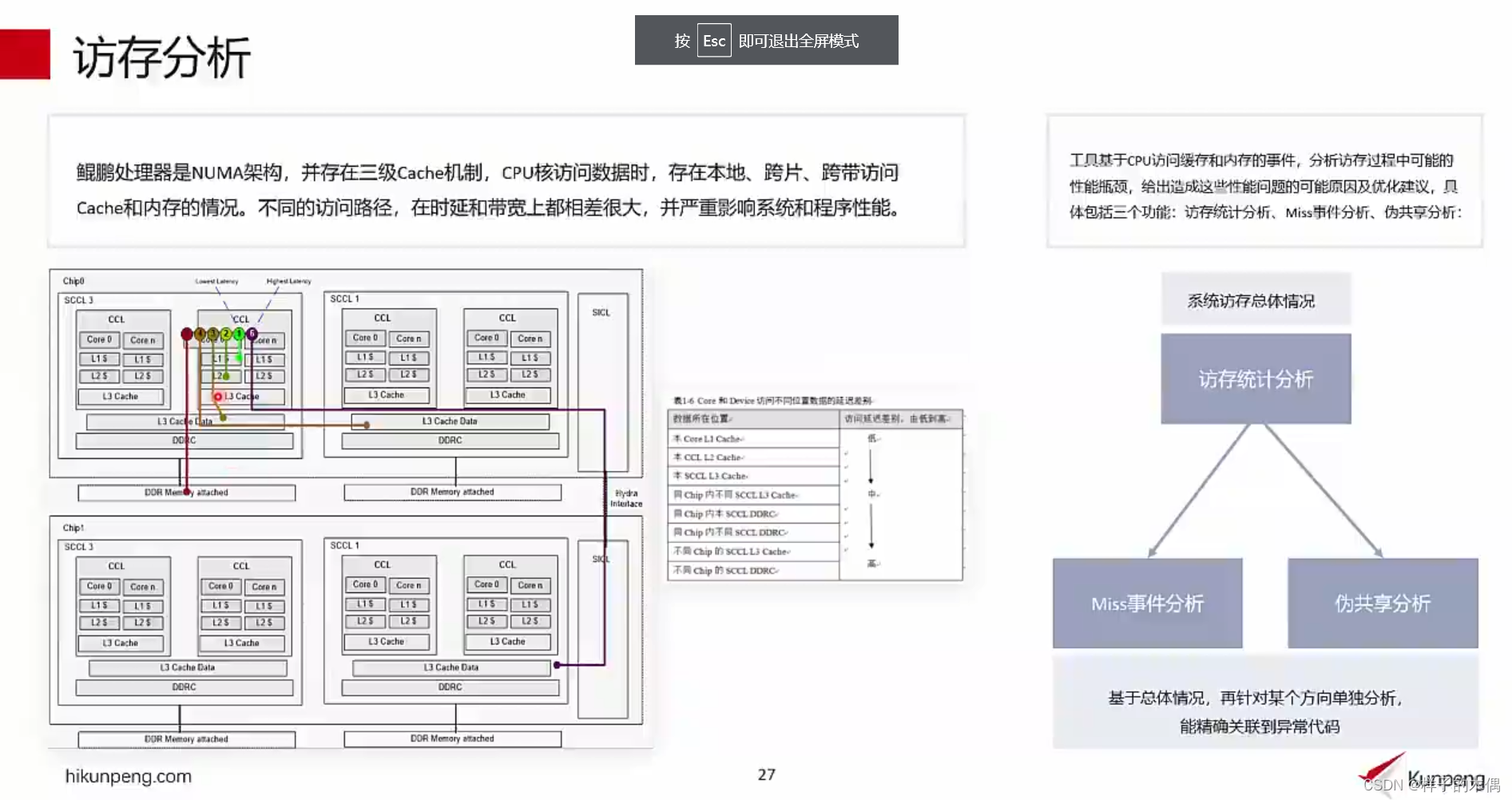
视频中以鲲鹏处理器为例,因为鲲鹏处理器是NUMA架构,并存在Cache机制,cpu核方位数据时,存在本地跨带访问Cache和内存的情况,不同的访问路径,在时延和带宽上都相差很大,并严重影响系统和程序性能。
一般出处理方法有一下几种
几种简单的访存优化方法
- 减少不必要的内存引用
- 按顺序访问数据
- 按顺序存储同时要访问的数据
访存统计分析
查看分析报告通过报告可以查看访存信息
当L1C/L2C/L3c命中率较低时,说明CPu需要花费更多时间去内存读取数据,此时需要排查程序优化内存访问,如:数据访问负荷cache的时间和空间局部性、大数据结构cache line对齐、多线程编程时避兔falsesharing等等。TLB命中率较低时,可以调大页表大小。

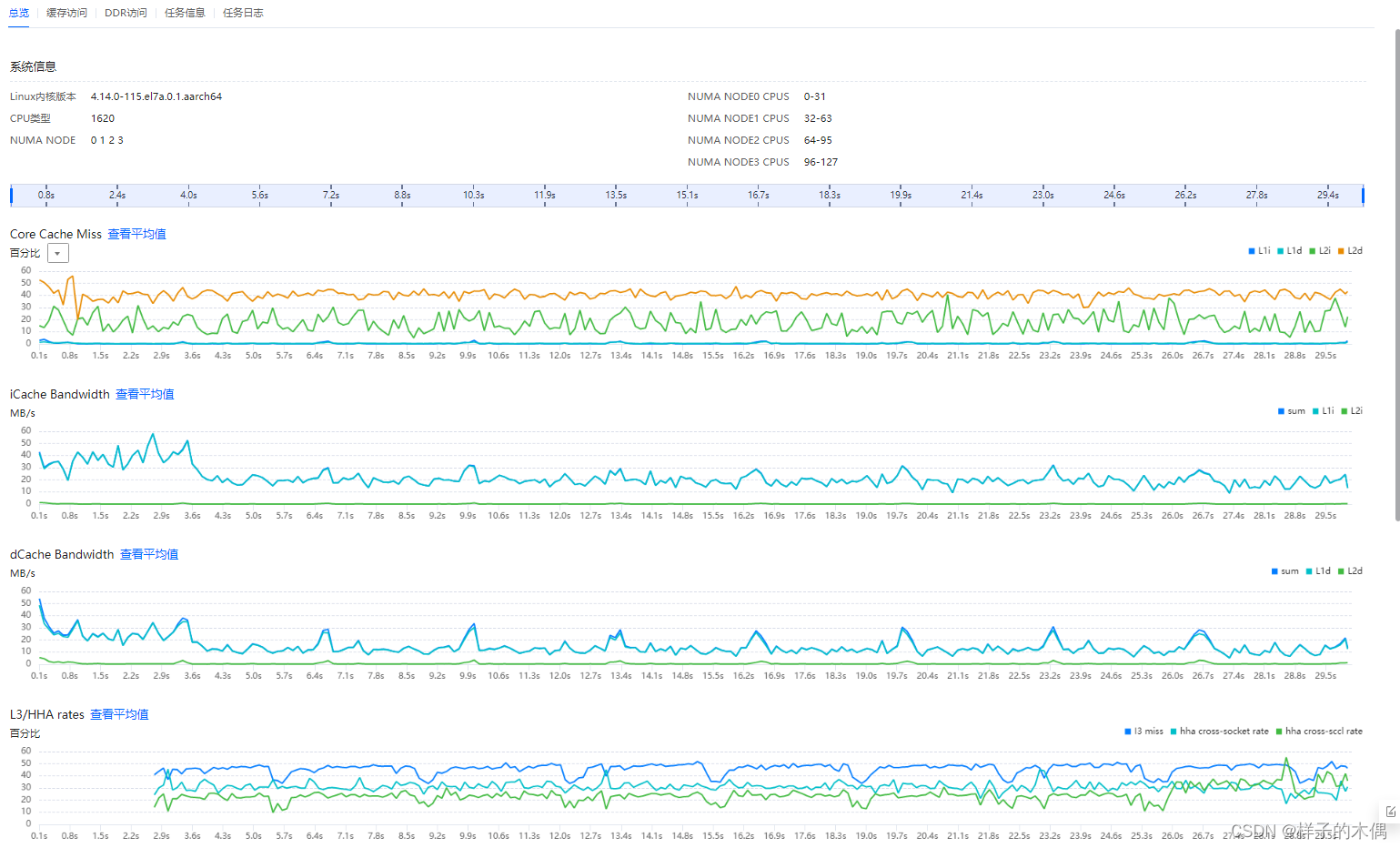
如果出现大量的跨DIE访问或跨片访问,需要考虑对相关进程/线程进行绑核操作。
通过核绑操作可以直接避免跨区的现象发生,也正是因为这样,对鲲鹏处理器上的应用进行访存分析是十分有必要的
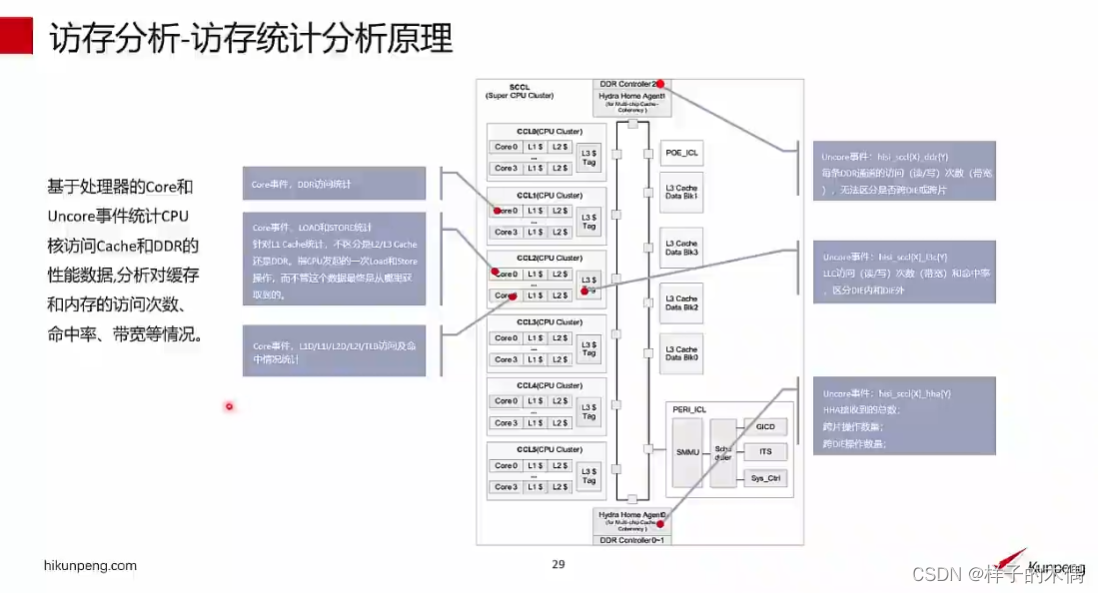
访存统计分析原理
原理:
基于处理器的core和Uncore事件统计CPU核访问cache和DDR的性能数据,分析对缓存和内存的访问次数.命中率、带宽等情况。
uncore 事件采集的硬件实现与通用实现类似,都是通过一对对事件选择寄存器和事件计数寄存器来实现的。具体细节可查看 Intel 手册
在内核接口上,uncore 性能事件已经不是原本 core 上的 pmu 设备了,所以原有的 perf 接口并不知道用户采集哪个 CBox 上的性能数据,所以 perf_event 在原有的基础上在 type 参数上进行扩展接口(换句话说 uncore 事件都是需要单独的内核驱动的)。
好在内核在 /sys/devices/uncore_*/type 文件直接暴露了该参数,在接口和工具的使用过程中,可以直接读取该文件的值
想来应该是通过这些数据进行分析显示到分析报告中的
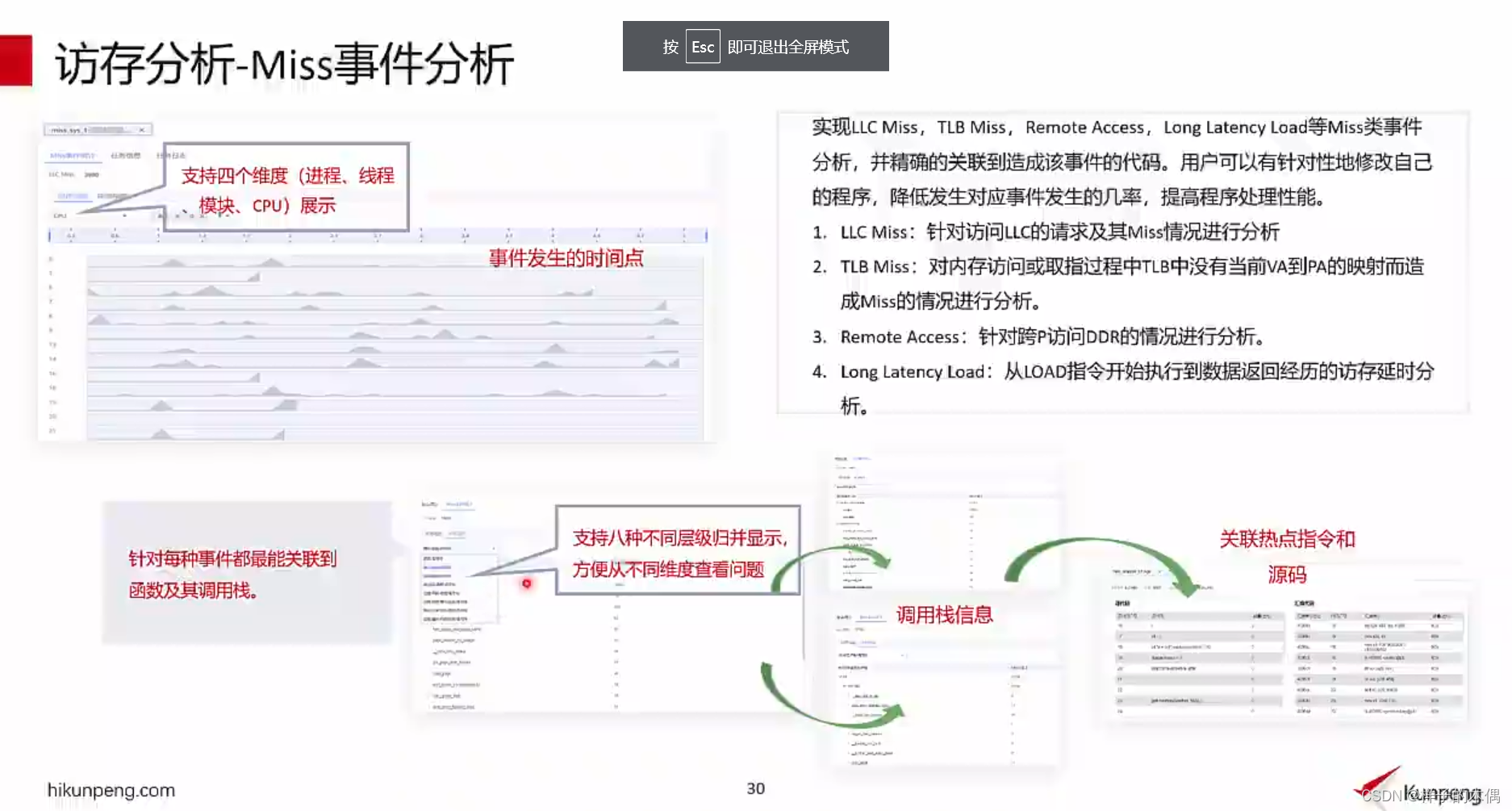
访存分析——Miss事件分析
实现LLC Miss,TLB Miss,Remote Access,Long Latency Load等Miss类事件分析。并精确的关联到造成该事件的代码。用户可以有针对性地修改自己的程序,降低发生对应事件发生的几率,提高程序处理性能。
- LLC Miss:针对访问uLc的请求及其Miss情况进行分析
- TLB Miss:对内存访问或取指过程中TLB中没有当前VA到PA的映射而造 成Miss的情况进行分析。
- Long Latency Load:从LOAD指令开始执行到数据返回经历的访存延时分析
Miss事件分析原理
Miss事件分析基于ARM SPE (Statistical Profiling Extension))能力实现。SPE是针对指令进行采样,同时记录一些触发事件的信息,包括精确的Pc指针信息。利用该项能力可以用于对应用程序进行lLC Miss,TLB Miss,Remote Access,Long Latency Load等Miss类事件分析,并精确的关联到造成该事件的代码。

相对于PMU事件,SPE可以解决PMU事件无法精确对应到PC指针的问题。
访存分析——伪共享分析
首先我们先看看什么是伪共享:
伪共享就是多线程操作位于同一缓存行的不同变量时,由于缓存失效而引发性能下降的问题
伪共享的出现也是我们需要调优的一个方向
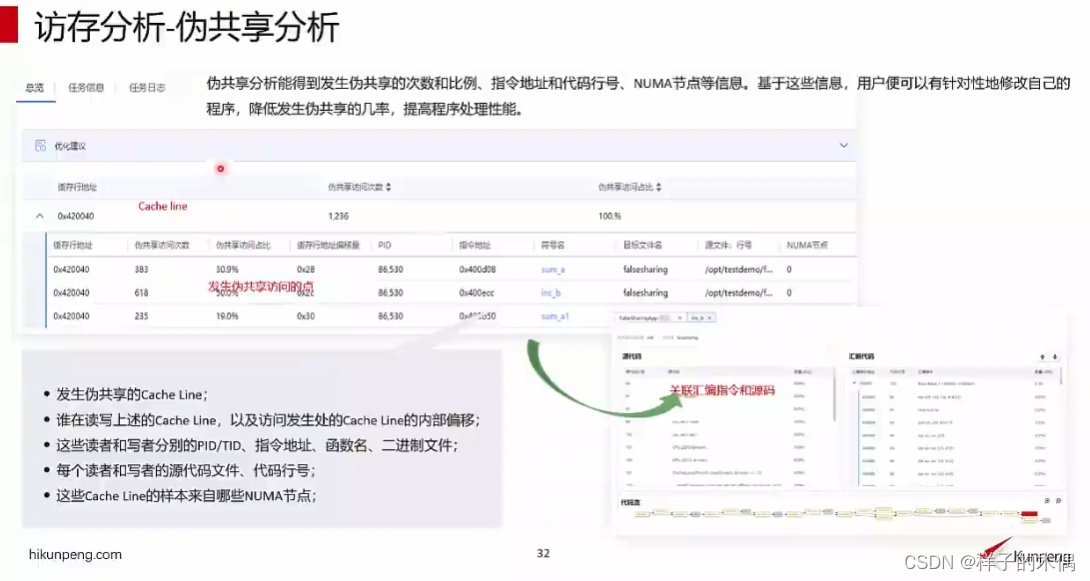
鲲鹏devkit性能分析工具可以呈现出检查出发生共享的地方,同时能够调出其共享的代码块,和其读写操作相关的源文件
其完整的功能有如下几种:
- 发生伪共享的Cache Line;
- 谁在读写上述的Cache Line,以及访问发生处的Cache Line的内部偏移;
- 这些读者和写者分别的PID/TID、指令地址、函数名、二进制文件;
- 每个读者和写者的源代码文件、代码行号;
- 这些Cache Line的样本来自哪些NUMA节点
详细的数据报告,和清晰的图标展现能够帮助开发者更加高效的进行性能调优
伪共享分析原理
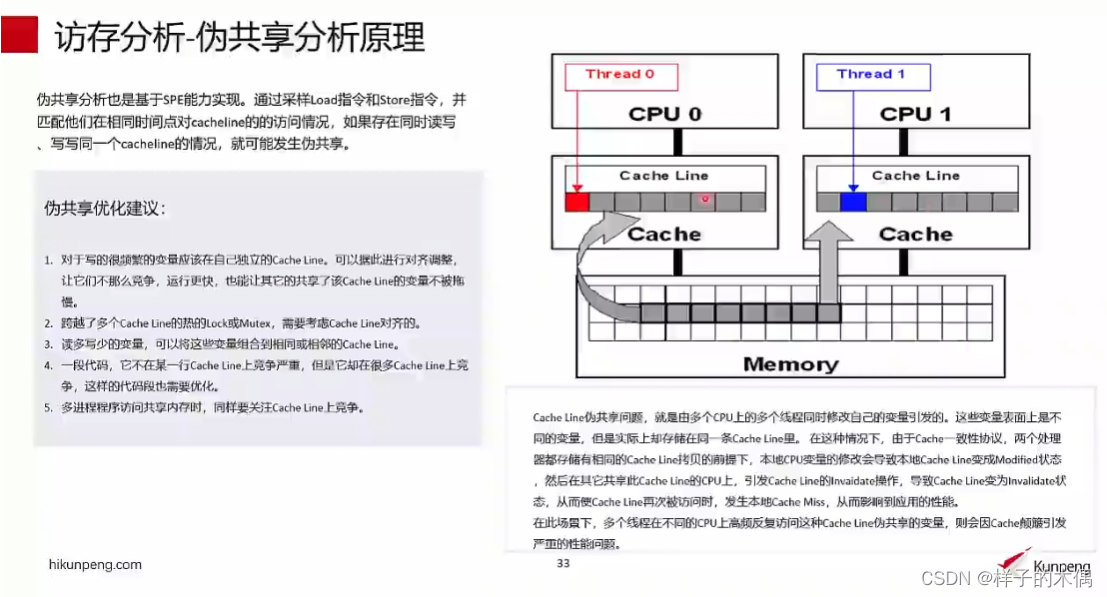
上面我们讲到伪共享就是多线程操作位于同一缓存行的不同变量时,由于缓存失效而引发性能下降的问题
所以这里我们的工具就是通过对load指令和store指令进行采样,通过采样信息与他们在相同时间点对cacheline的访问情况进行匹配,如果存在同时进行读写、写写同一个cacheline的情况,那么这里就有可能出现伪共享
这里也提供了一些伪共享优化的建议:
1、对于写的很频散的交量应该在自已独立的CacheLine。可以据此进行对齐调整让它们不那么竞争,运行更快,也能让其它的共享了该Cache Line的卖量不被施慢
2、跨越了多个Cache Line的热的Lock或Mutex,需要考虑Ceche Line对齐的。
3、读多写少的突量,可以将这些变量组合相同或相邻的Cache Line。
4、一段代码,它不在某一行Cache Line.上竞争严重,但是它却在很多Cache Line上克争,这样的代码段也需要优化。
5、多进程程序访问其享内存时,同样要关注Cache Line上竞争
访存分析举例
在本讲视频中以结构体 foo为例,当对foo读取时 线程1读取的是f x而线程2而读取的是fy,那么在这个节点就会发生伪共享
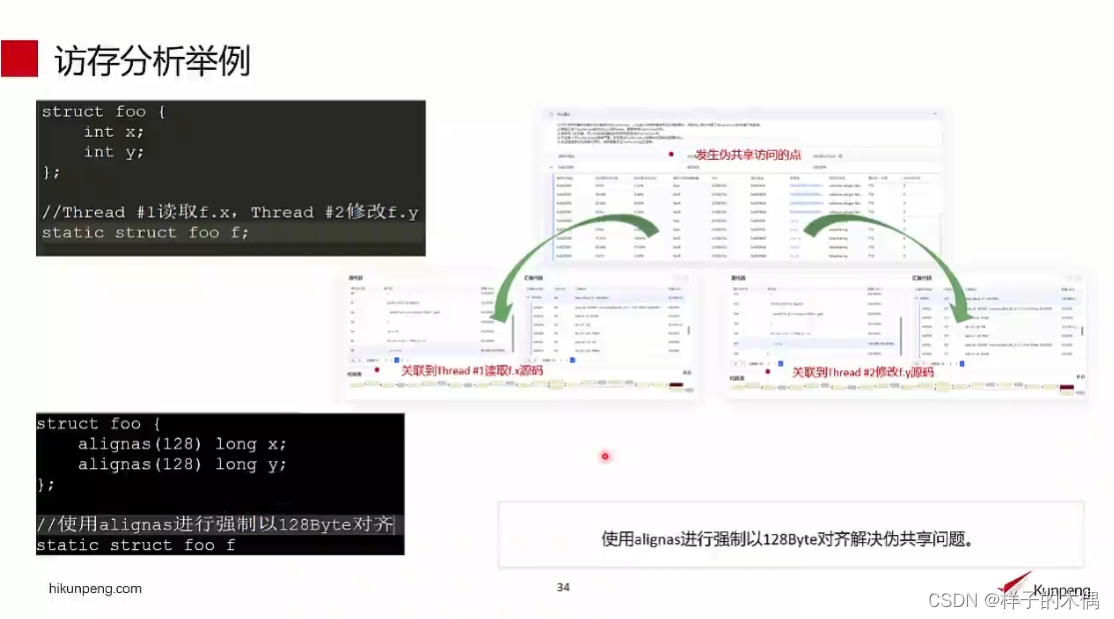
这里我们一般的解决方法是使用alignas进行强制以128B对齐的方法解决伪共享问题