Attention和Visual Transformer
- Attention和Transformer
- 为什么需要Attention
- Attention机制
- Multi-head Attention
- Self Multi-head Attention,SMA
- Transformer
- Visual Transformer,ViT
Attention和Transformer
Attention机制在相当早的时间就已经被提出了,最先是在计算机视觉领域进行使用,但是始终没有火起来。Attention机制真正进入主流视野源自Google Mind在2014年的一篇论文"Recurrent models of visual attention"。在该文当中,首次在RNN上使用了Attention进行图像分类 。
然而,Attention真正得到广泛应用是在NLP领域,大量的方法在RNN/CNN模型上使用Attention机制进行各种任务。在2017年,Google的《Attention is all you need》中首次使用自注意力机制和多头注意力机制进行翻译任务,并提出了Transformer架构,取得了十分优异的性能,成为NLP领域的大爆点。
在2021年,Google Research发布了论文《AN IMAGE IS WORTH 16X16 WORDS:
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》,将在NLP领域取得巨大成功的Transformer引入计算机视觉领域,并提出了Visual Transformer架构,其性能接近或超过了此前传统的卷积网络。
为什么需要Attention
在Attention真正得到应用的时候(其实现在也是),神经网络的发展面临着两个问题:
- 计算能力的不足。随着模型的深度和宽度的不断增加,模型需要记住的“知识”越来越多。模型整体会变得愈发复杂,其训练和推理都会对计算能力提出很高的要求。
- 优化算法的限制。池化、BatchNorm和LayerNorm等操作可以让模型的优化变得相对简单容易,但对于高度复杂的模型,目前的优化算法或多或少存在难以优化的问题。比如,在RNN中存在的长程梯度消失问题。在进行机器翻译的时候,将长句子转换为长向量会使得模型变得很难优化,在训练过程中会出现信息损失的问题。
Attention解决以上两个问题的想法是,将模型当中的信息进行权重区分,对重要的部分进行重点关注,而忽略不是那么重要的部分。以一个翻译的例子来说,给出这样一句话
To be or not to be, that is the question.
在进行翻译的时候,对于that这个词的含义,我们显然回去更关注千年的To be or not to be,而不是is或者the。又或者,我们在看一幅图片的时候

我们显然会首先关注照片中的香蕉,进而认为这是一幅香蕉的照片。而非重点关注香蕉下面的桌子,或者后面的背景。
Attention机制的核心思想就是这样。
Attention机制
Attention的实现基于Key-Value的模型。模型的输入作为Query,与Key、Value进行计算后得到一个Attention的结果。比较抽象的图如下面所示
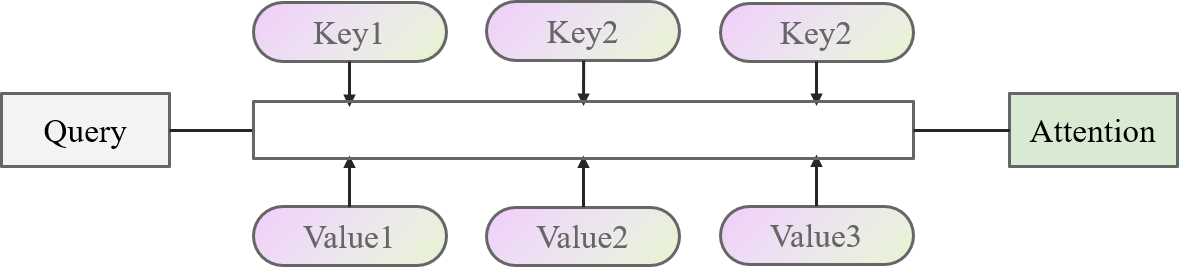
举个简单的例子来说,现在要去图书馆学习深度学习相关的知识,深度学习作为(Query)。在图书馆中,有很多类别(Key)的图书(Value),包括PyTorch与Python、数理统计、微积分、计算机组成原理、数据库等等。这些类别的图书与学习的目标有些很符合(数理统计、PyTorch),有些相关性很小(数据库、计算机组成原理)。那么,一种高效的学习方法就是重点去学习相关性很大的书籍,便可以计算深度学习(Query)和类别(Key)之间的相关性,让后根据相关性的大小学习这些书(Value),最后加起来得到学习到的知识(Attention)。
Attention的核心思想,用“加权求和”四个字就可以概括。大道至简,大爱无疆,大音希声,大象无形。加的权就是Query和Key的相关度(或者交相似性),求得和就是各个Value之间的求和。
基于此,我们再去理解一下上面的图,将上面的图展开一点。
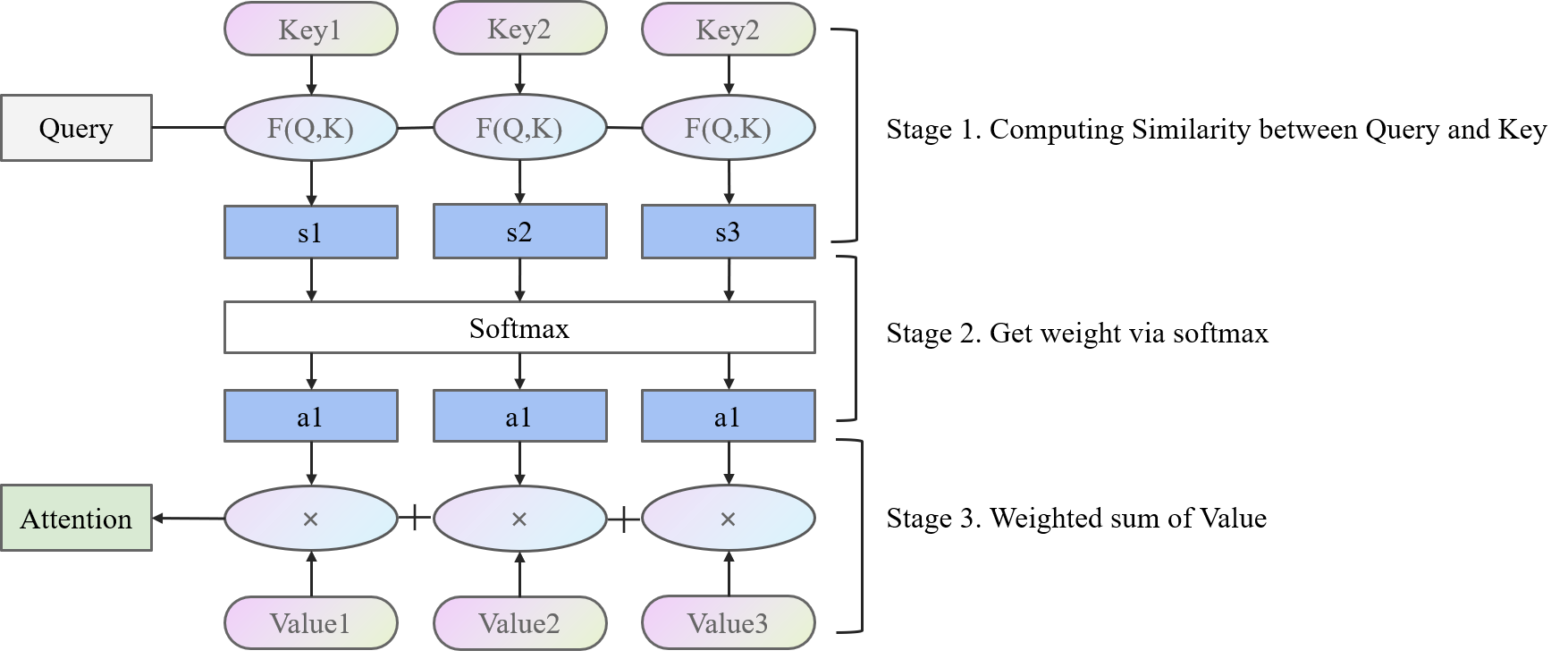
在计算Attention的时候
- 第一阶段用F(Q,K)计算Query和各个Key的相似度
- 第二阶段用softmax操作将相似度变成可以使用的权重
- 第三阶段用对应的权重乘以对应的Value,加起来得到Attention结果。
在《Attention is all you need》这篇文章中,作者给出了一种 Scaled Dot-Product Attention的计算方式。
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
⊤
d
k
)
V
{\rm Attention}(Q,K,V)=softmax\left( \frac{QK^{\top}}{\sqrt{d_{k}}} \right)V
Attention(Q,K,V)=softmax(dkQK⊤)V
其中,
Q
Q
Q和
K
K
K都具有
d
k
d_{k}
dk的维度,
N
N
N是样本数量。
V
V
V具有
d
v
d_{v}
dv的维度。
Q
K
⊤
QK^{\top}
QK⊤使用点积计算两个向量的相似度,同时除以
d
k
\sqrt{d_{k}}
dk保证数值的稳定性。这是因为,在维度过高的时候,向量内积的数值差距会变的很大,如果直接进行softmax,会使得分布趋近1和0,当对softmax求导的时候,导数会接近0,在优化过程中很难优化。
Multi-head Attention
在SDP中,计算Attention时没有什么可以计算的参数,可以先把原本的向量,通过线性层隐射到多个低维的空间,然后再并行地进行SDP Attention操作,在concat起来,可以取得更好的效果。这类似于CNN中的多通道机制。一个向量先隐射成多个更低维的向量,相当于分成了多个视角,然后每个视角都去进行Attention,这样模型的学习能力和潜力就会大大提升,另外由于这里的降维都是参数化的,所以让模型可以根据数据来学习最有用的视角。
在Attention文章中,作者提出了一种多头注意力机制Multi-head Attention,MA。其计算如下:
M
u
i
l
t
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
i
,
…
,
h
e
a
d
h
)
W
O
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
{\rm MuiltHead}(Q,K,V)={\rm Concat(head_{i},\dots,head_{h})}W^{O} \\ {\rm head_{i}=Attention}(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V})
MuiltHead(Q,K,V)=Concat(headi,…,headh)WOheadi=Attention(QWiQ,KWiK,VWiV)
这里,使用一个线性变换操作Q,K,V矩阵,同时在最后进行一次线性变换,得到Attention结果。整个结构如下图。

Self Multi-head Attention,SMA
自注意力机制Self Attention,将Q、K、V矩阵都变成相同的,即都是输入本身。自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性,从自注意力机制出发,衍生出了SMA。具体流程如下所示。
首先,从Input X计算得到Q,K,V

然后进行注意力机制计算,这里以一个Head为例

Transformer
在了解了Attention相关的机理之后,就可以研究一下火到爆的变形金刚(不是)Transformer了。
我们从NLP领域的Transformer开始说起。在进行NLP任务时,Transformer使用了非常流行的编码器-解码器结构。Transformer的核心架构就是上面说的SMA。
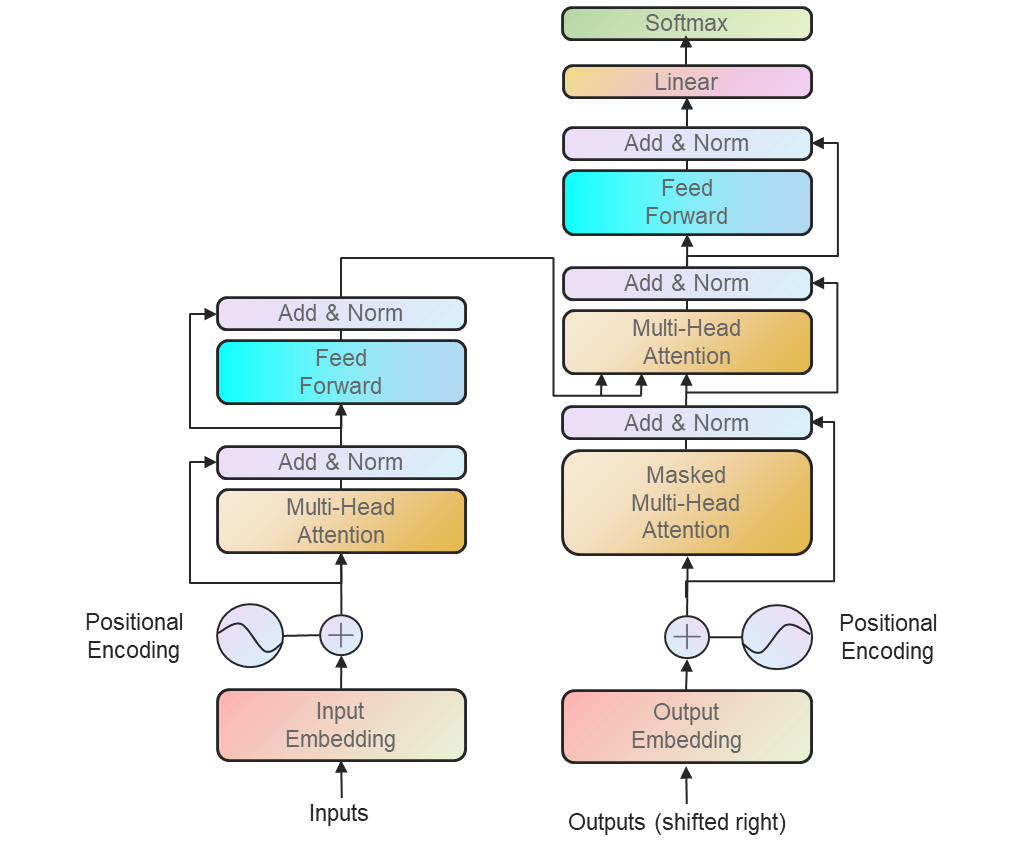
接下来我们对着这张图一步步描述Transformer的架构,这里主要描述一下编码器结构,解码器跟编码器差不多。
- Input Embedding,这部分没什么特别可说的,就是将输入变成嵌入向量。
- Positional Embedding。由于Transformer的结构完全基于Attention机制,所以对比传统RNN和CNN,模型没有办法利用输入序列的位置信息。所以,作者在这里用了一个Embedding来为模型的注入位置信息(相对或者绝对位置)。在原文中,作者给了两种进行Positional Embedding的方法,其中一种是直接对位置进行编码

其中 p o s pos pos是位置, i i i是维度。也就是说,位置编码的每个维度都对应于一个正弦曲线。选择这个函数是因为它允许模型容易地学习相对位置,因为对于任何固定偏移, P E p o s + PE_{pos+} PEpos+可以表示为 P E p o s PE_{pos} PEpos的线性函数。另一种embedding方法就简便的多,直接将embedding信息变为可学习的参数。 - 接下来的结构是两个残差的结构。在通过SMA之后进行进行残差操作,并进行一次LayerNorm,随后进入一个MLP进行相似的操作。这个模块在网络实现中是具有多个的,而非图中示意的一个。
- MLP。MLP模块中包含了两个线性层,以及一个GELU激活层。
Visual Transformer,ViT
这是一个小甜甜变牛夫人再变小甜甜的故事。最初在计算机视觉领域提出的Attention当年在视觉领域没有激起什么波澜,反而后来在NLP领域借助Transformer爆火,然后CV里面的人才想起来能不能把Transformer用到视觉领域呢?
于是乎谷歌继Attention文章之后,又提出了Visual Transformer,将Transformer的旗帜正式插到了CV领域。
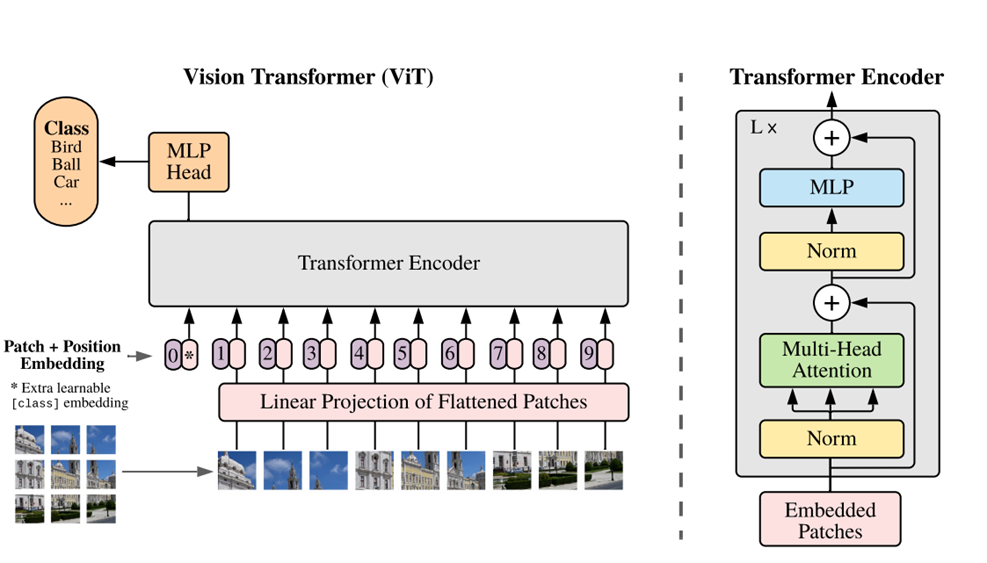
在ViT中,仅仅使用了Transformer中的编码器结构。然而,由于原始Transformer是为NLP任务设计的,是一个Sequence2Sequence的模型,这里必须将一幅图像变成Sequence的形式输入网络。接下来从头开始疏离一下ViT的结构。
- Patch。在ViT中,就如同文章标题An Image Is Worth 16X16 Words中说的一样,作者将一幅图像变成了一块一块的patch并Flatten,然后用一个线性映射做Embedding。
- Positional Embedding。和Attention文章不一样,在ViT中作者用了可学习的嵌入表示。
- Class token。作者说加入这个操作的想法来自BERT的token。简单来说,就是在Patch的序列中,加入一个学习的embedding参数,在最后用这个embedding代表整个序列进入MLP分类器作为分类。(另一种想法是序列中的所有patch就均值)
- Transformer Encoder。和Transformer基本相同,都适用MSA。
- MLP head。包含一个线性层,做分类器使用。
在看过Transformer的文章后,理解ViT其实没有难度。ViT在做实验的时候,使用在大规模数据集上的预训练模型做下游任务的fine-tuning,与先进的卷积方法达到了接近的性能。并且训练成本很低。
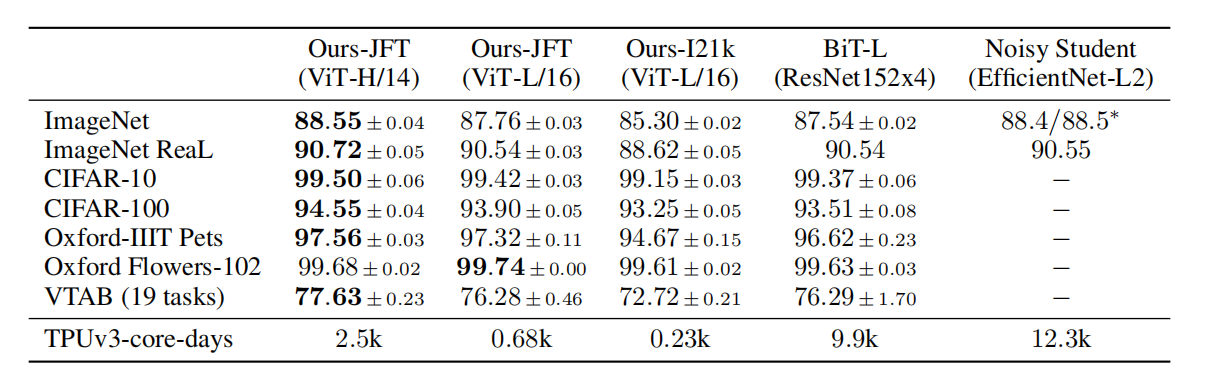
然而,在从头开始训练的时候,ViT的性能在中小规模的数据集上(ImageNet、ImageNet-21k)却不如卷积网络。如下图所示,只有在 大规模的数据集上(谷歌自家的JFT-300M),ViT的性能才表现的比卷积好。

作者在在文章中也说了,ViT缺乏一些CNN的归纳偏置(先验知识)。例如
- 局部性Locality。CNN以滑动窗口的形式工作,这假设相邻的位置特征往往相同,例如一个桌子的左边和右边的特征差不多。
- 平移不变性。translation equivariance。图像不论是先做卷积还是先平移,因为只要相同的部分遇到同一个卷积核,输出是一样的。在图像上就表现为桌子在图像上部还是下部是一样的。
ViT没有卷积操作,就缺乏了这两个先验知识。唯一的先验来自于position embedding,这其实也是逐渐学习到的。
作者还给了一些可视化的操作,例如,
给patch做embedding的结果

position embedding的可视化,可以看到虽然用的是1d的embedding,但是ViT学习到了很好的2d位置信息,比如4行4列的patch,他的poison embedding和自己的最相近,同时越和他靠近的相似性越高。而且表现出了一些行列的信息在里面。

每个注意力头的平均注意距离。平均注意距离就是两个像素点间的实际距离乘上二者之间的注意力权重。虽然在刚开始的时候有些注意力头的平均注意距离比较小(类似于卷积只利用局部信息),但到后期的注意力头已经可以注意到全局的范围上的信息了。