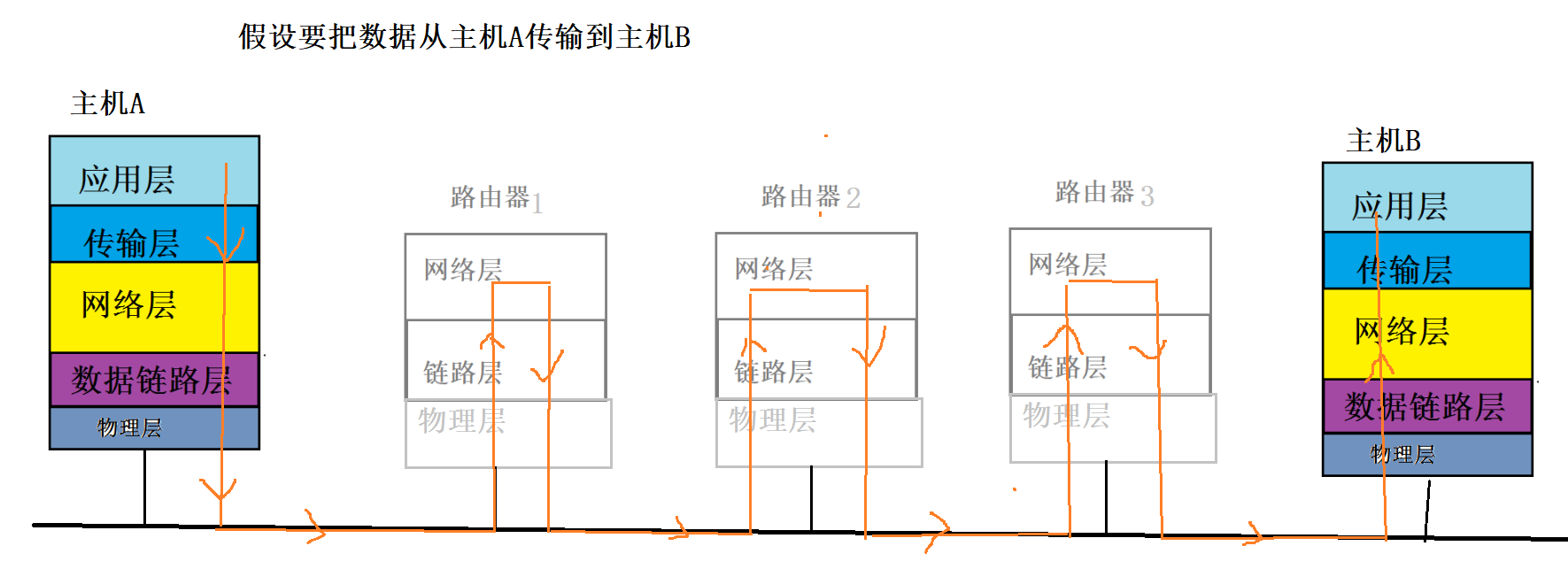
RNN
也是一种Seq2Seq网络
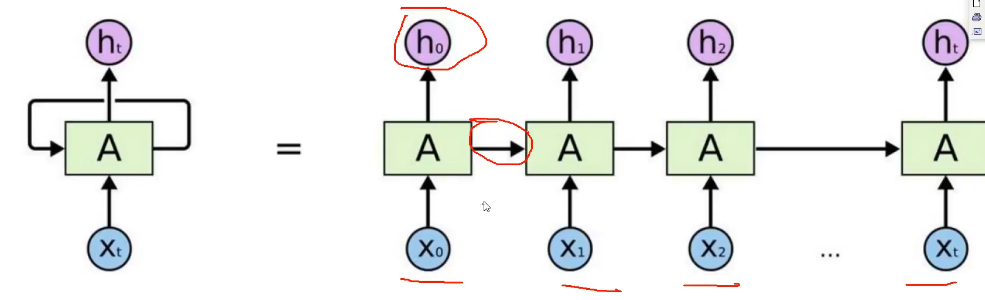
这种RNN就不能并行运算,且对于长句子会造成损失遗忘或者梯度爆炸
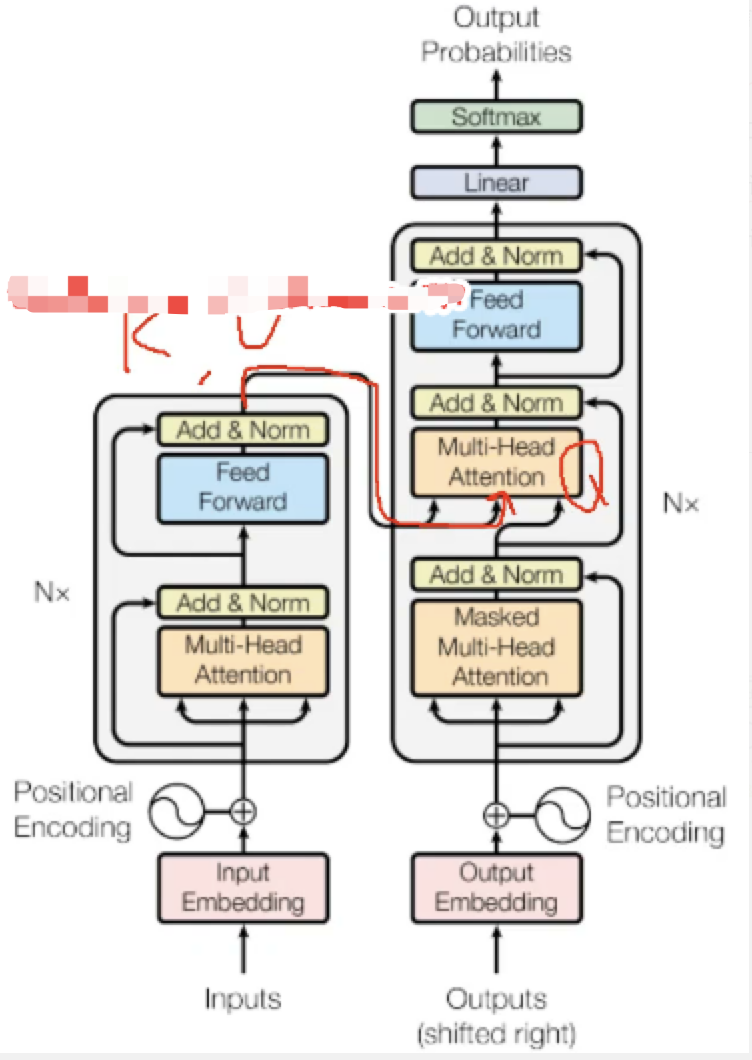
Transfomer
Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
解决的问题有2个:
- 1)并行计算要求
- 2) 解决RNN中 对远距离的词记忆效果弱
总体结构
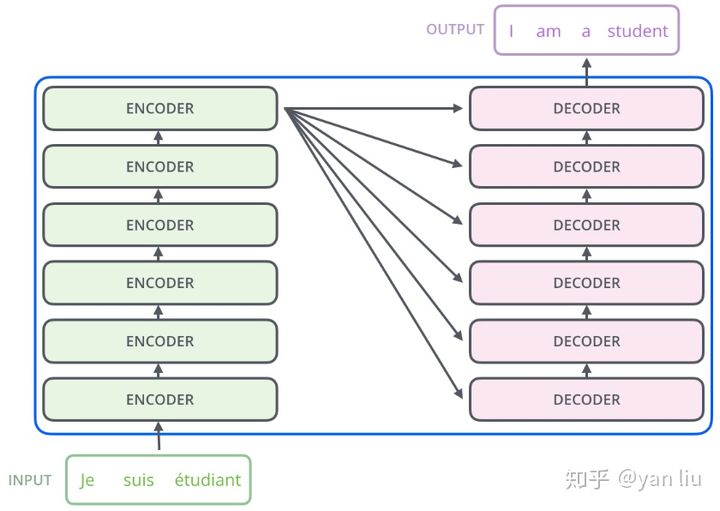
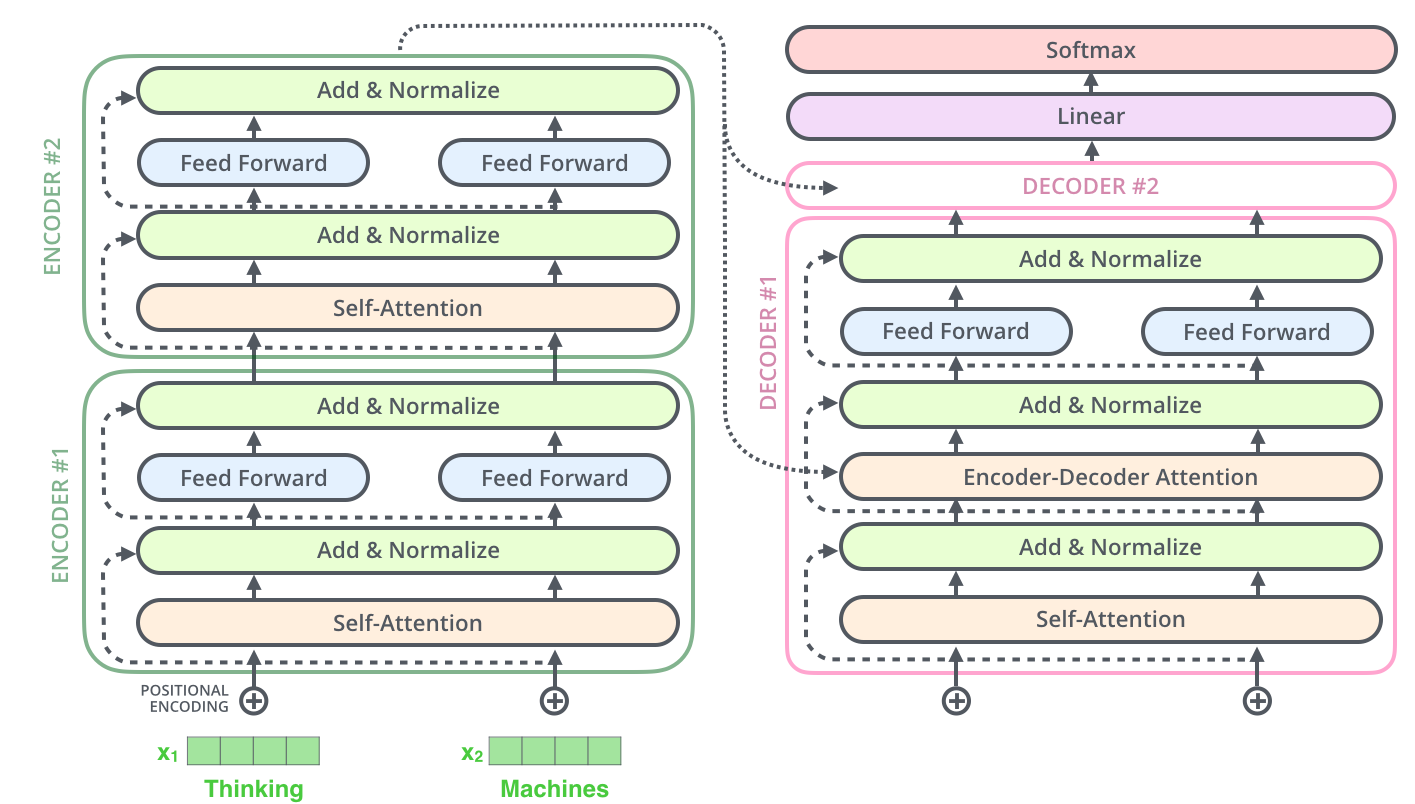
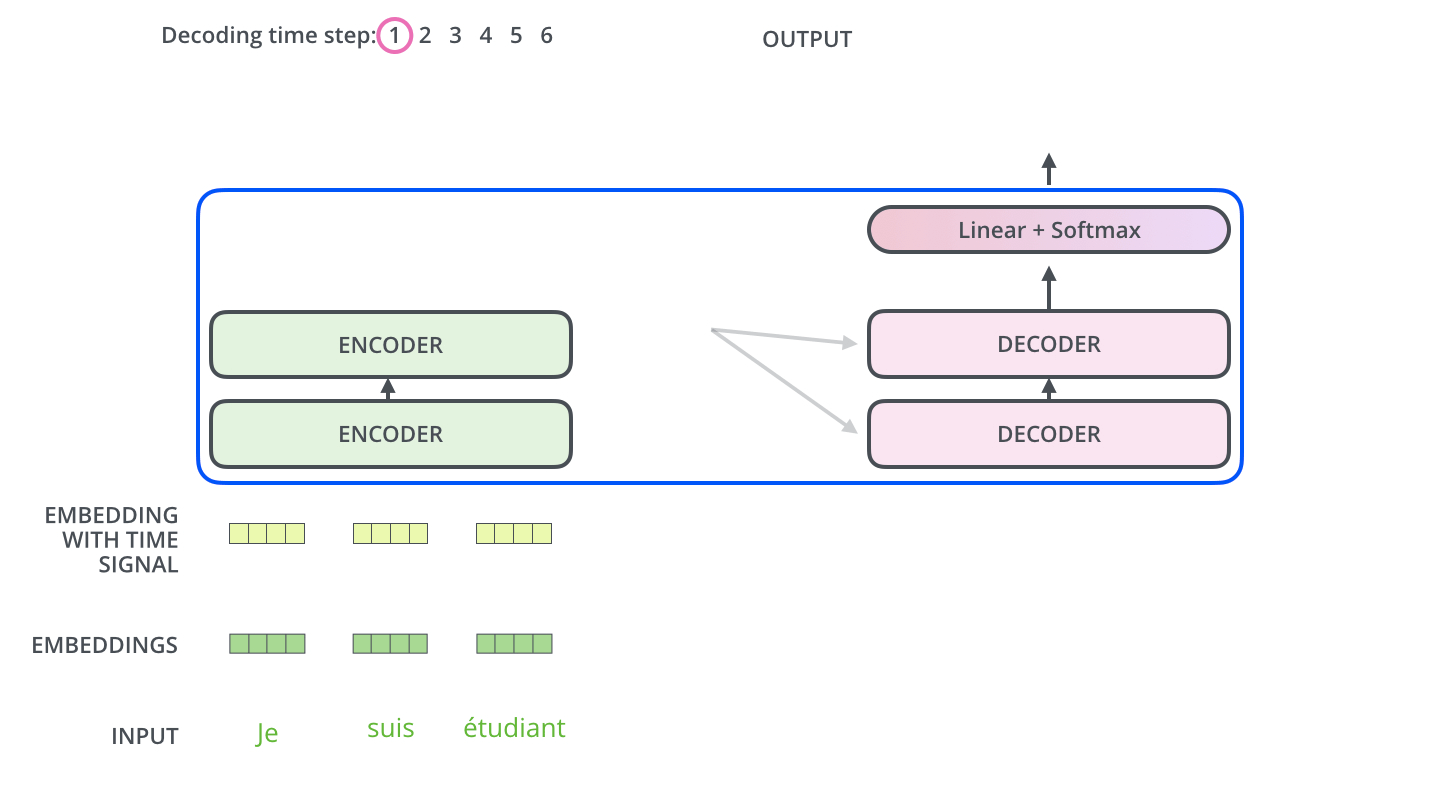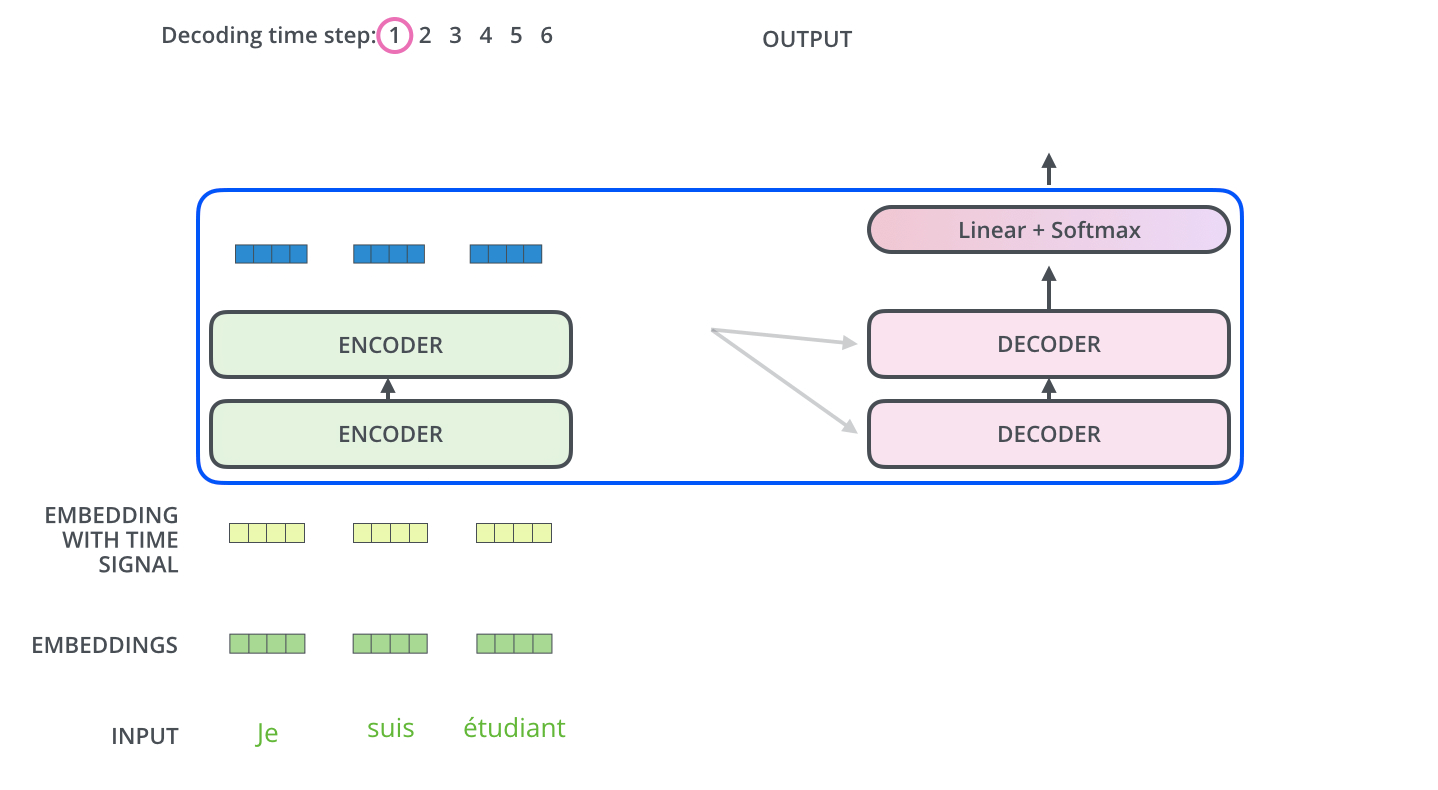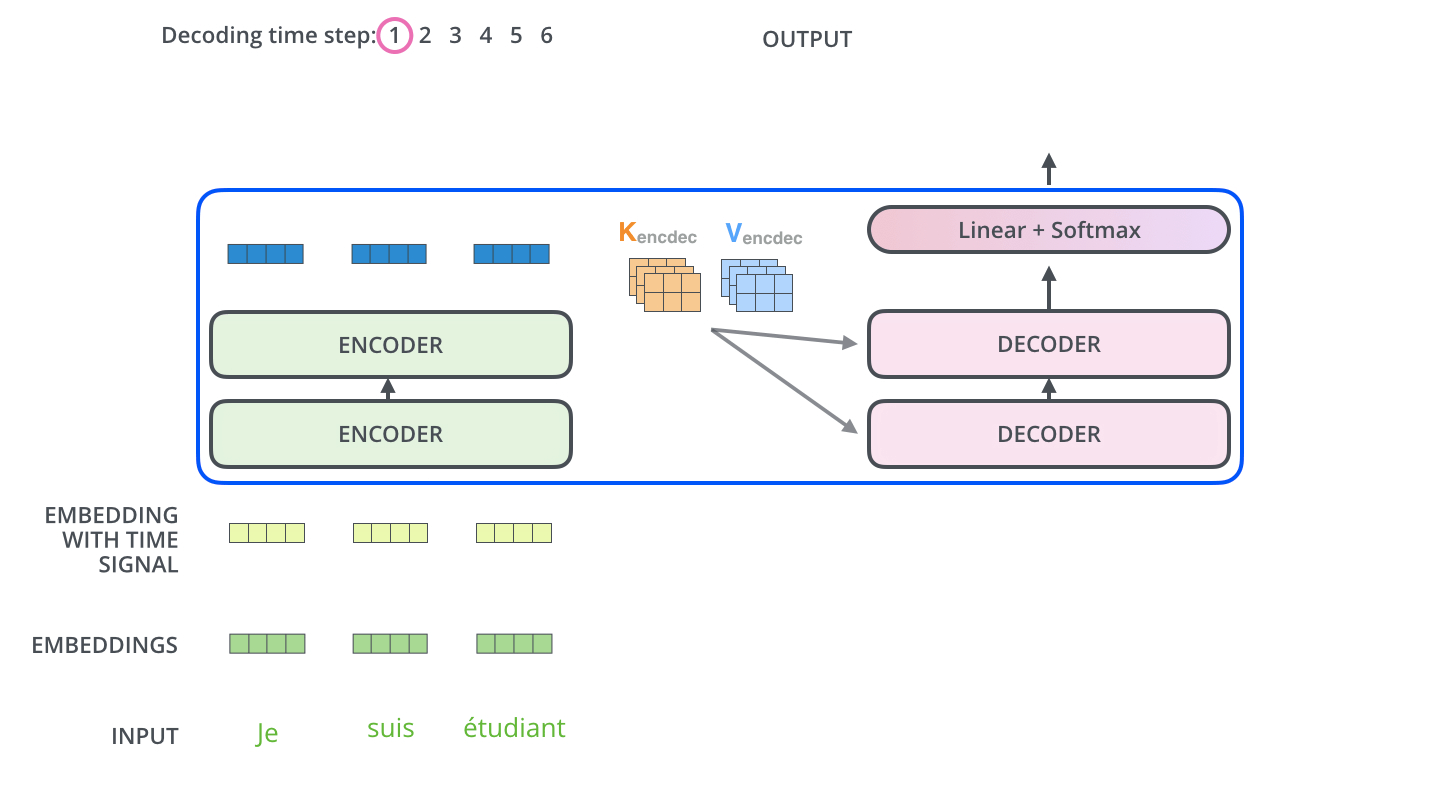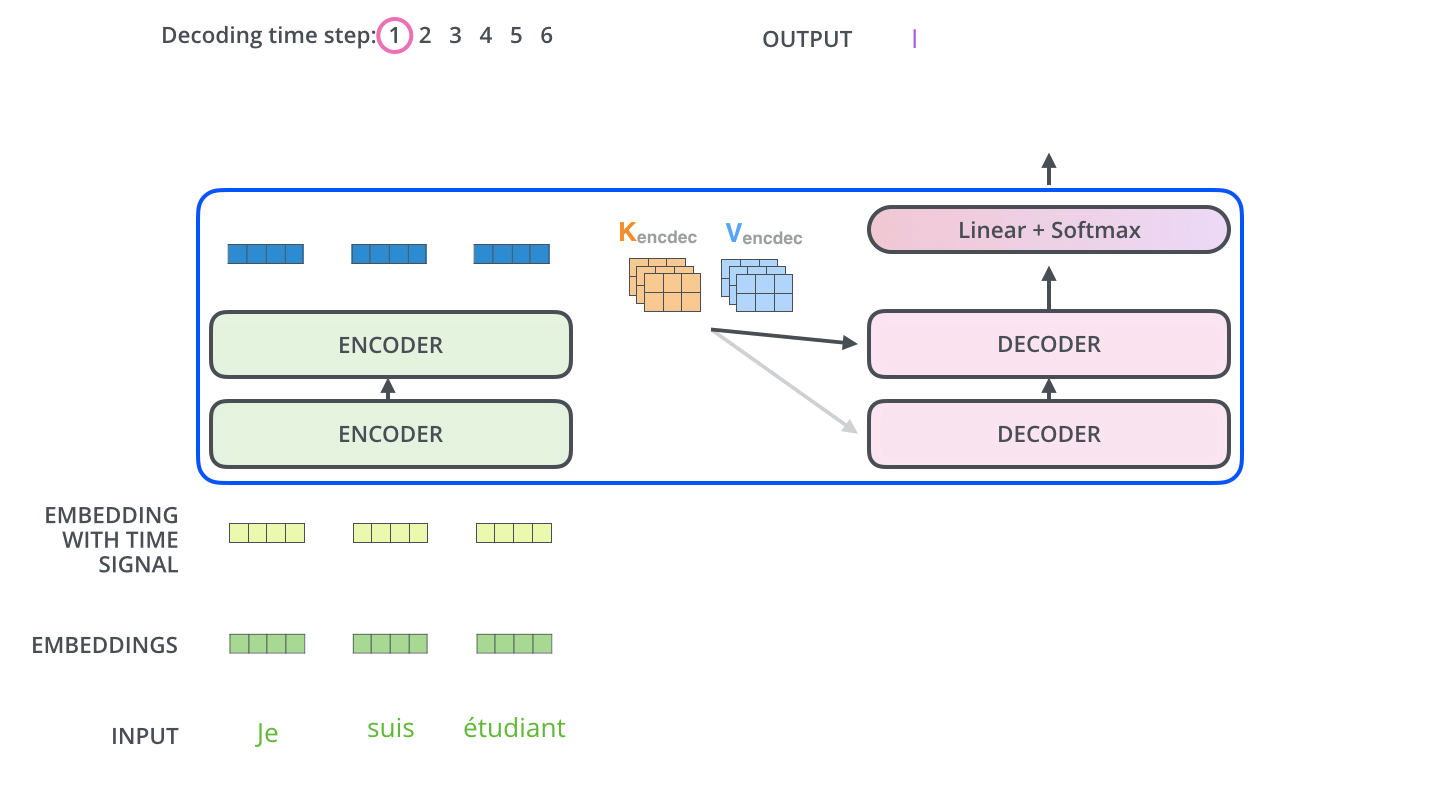
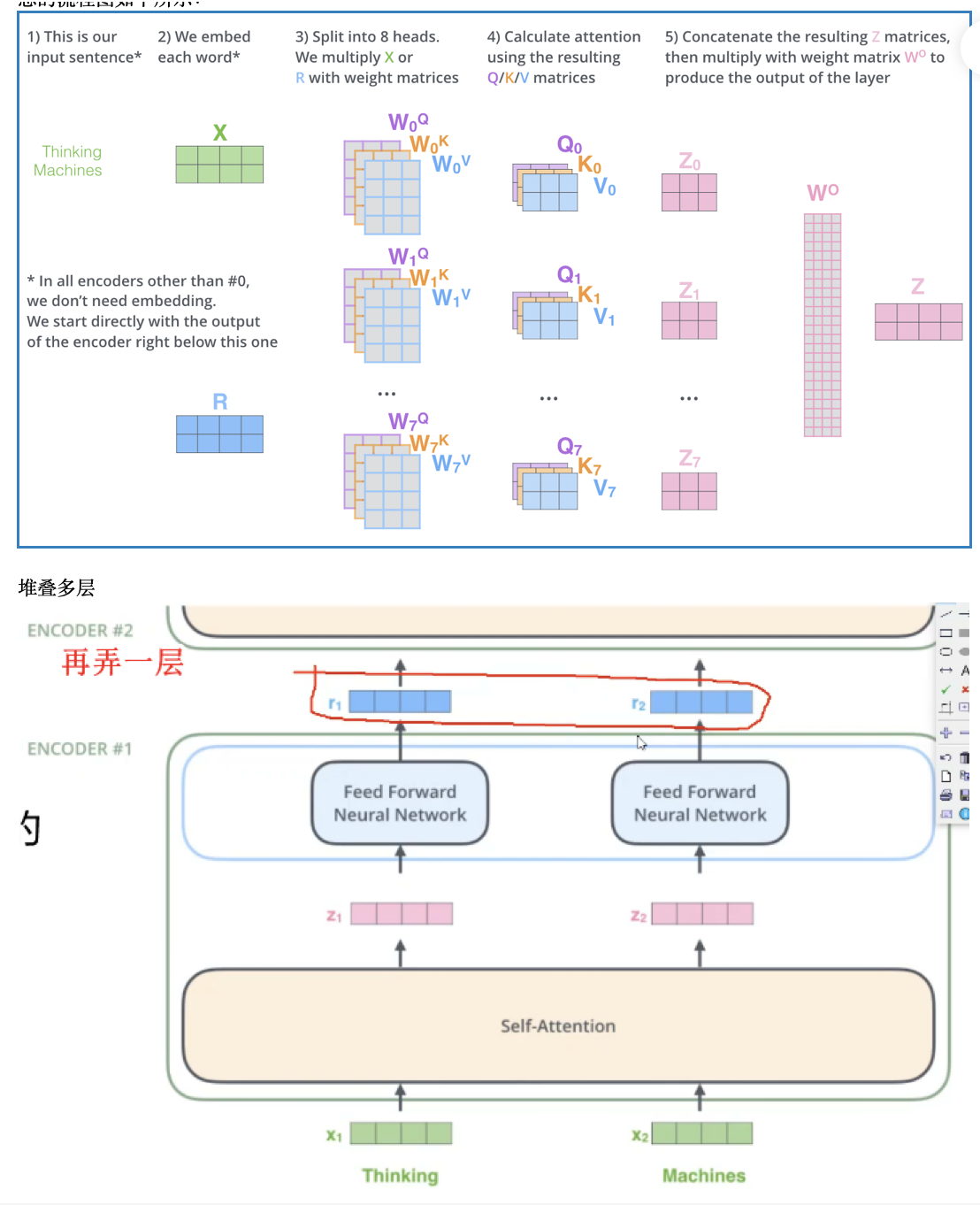
Transformer的编码部分是由6个编码器,同样解码有6个解码器组成
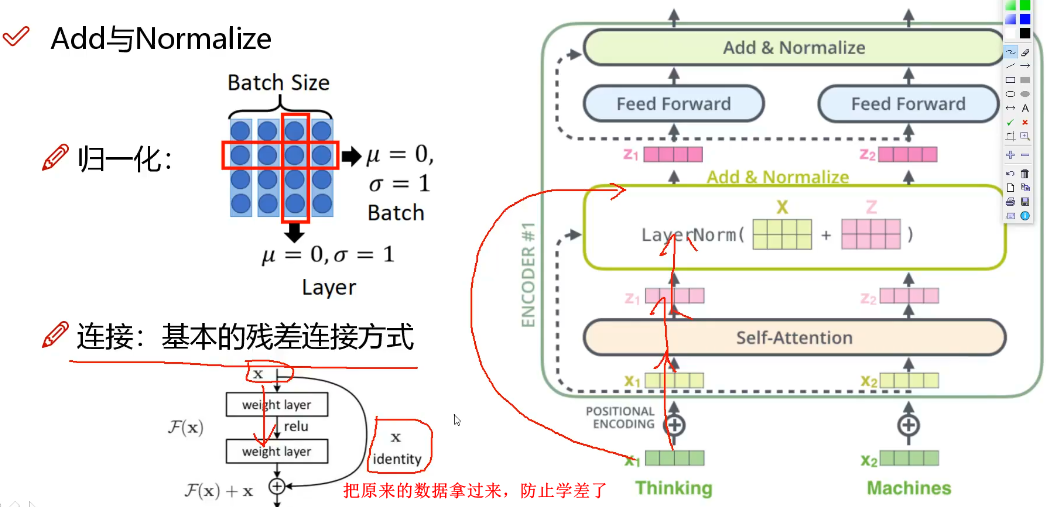
每个编码器的结构是先做一个self-attention,得到attention z,然后用一个全连接FNN对z的降维;输入的序列,先流入第一层self-attention,计算出当前词与其他单词的
Encoder
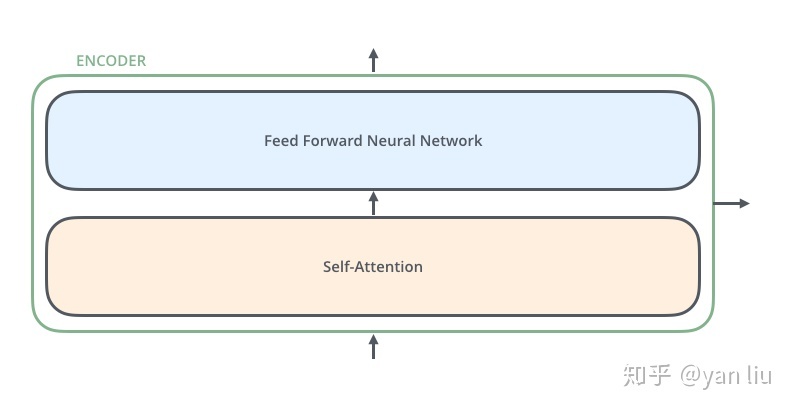
上述主要会用到两个网络部分:1)self-attention计算序列中的token与其他token的attetion值; 2) FNN 全连接层,两层第一层ReLU,第二层线性激活函数
Decoder
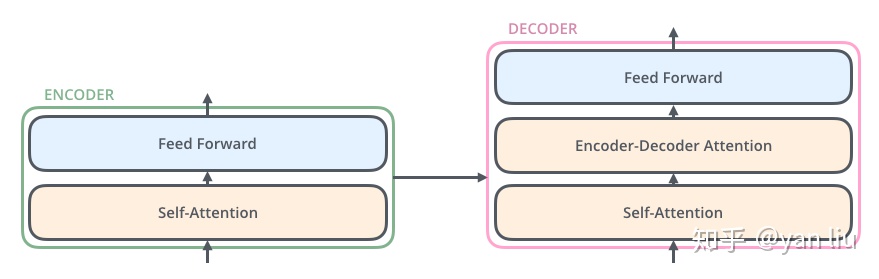
decoder是一个自回归的网络,根据前面的token,计算后面的token;
- 1)Self-Attention:当前翻译和已经翻译的前文之间的关系;
- 2)Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。
Self-attention
1)把每一个词编程词向量,文章用的是Xi是512维的,而乘出来后的q,k,v这些新向量是64维的。这样做的目的是可以持续计算多头
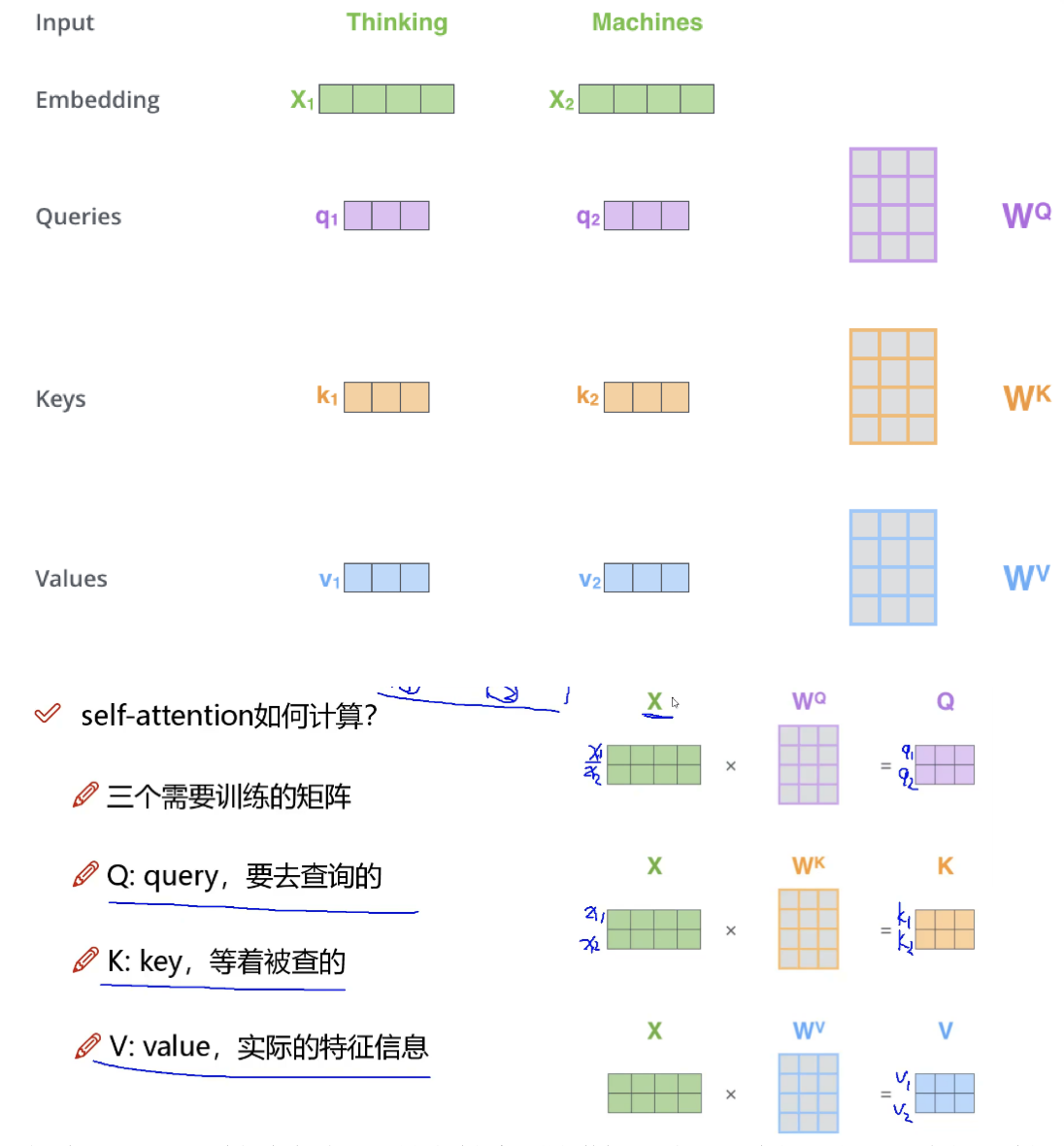
当得到Q、K、V三个矩阵时,便可以计算每个词与其他词的得分;这里用一个点积运算,可以求出某两个词的相关性;
2)计算socre
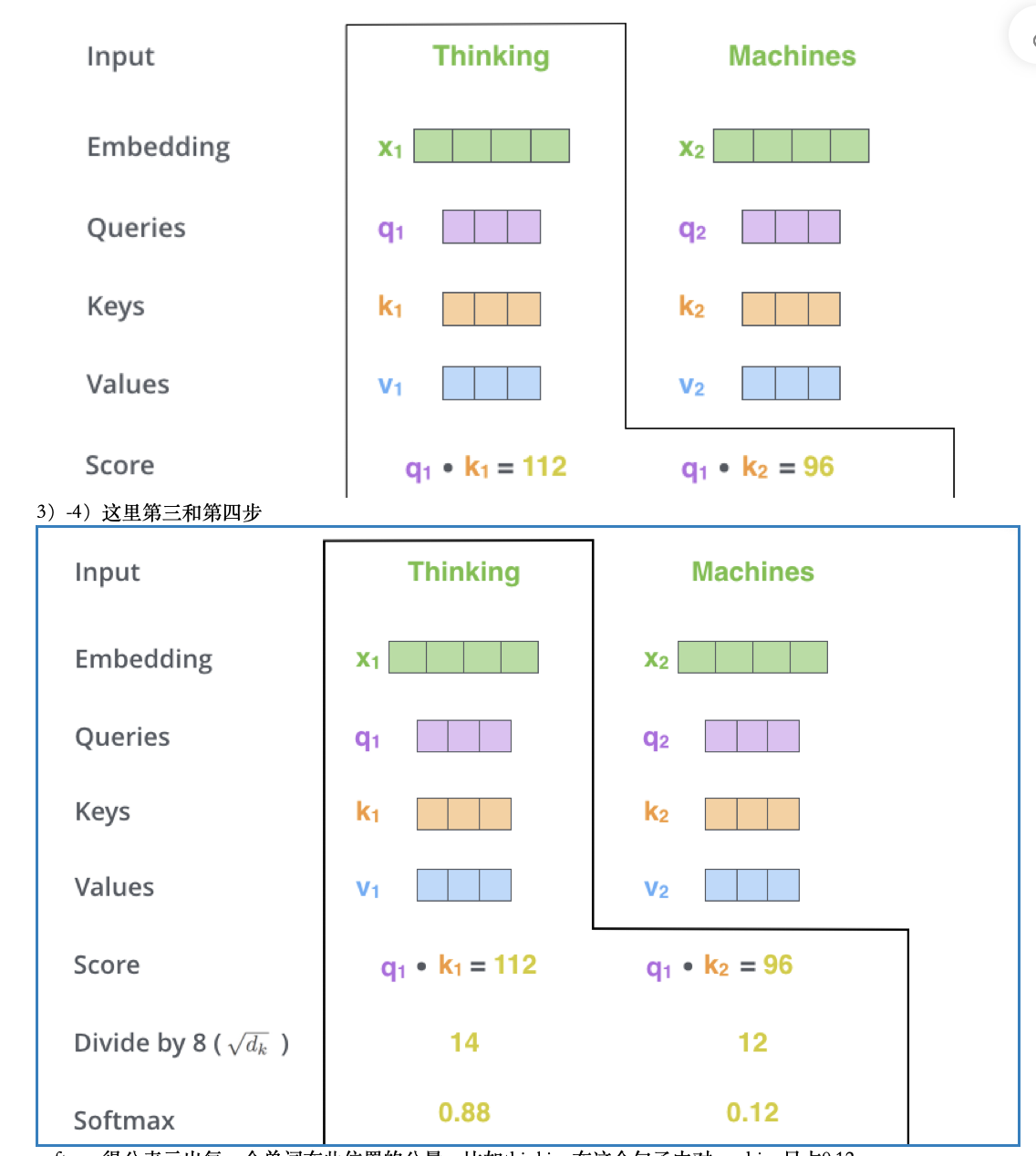
softmax得分表示出每一个单词在此位置的分量,比如thinking在这个句子中对machine只占0.12
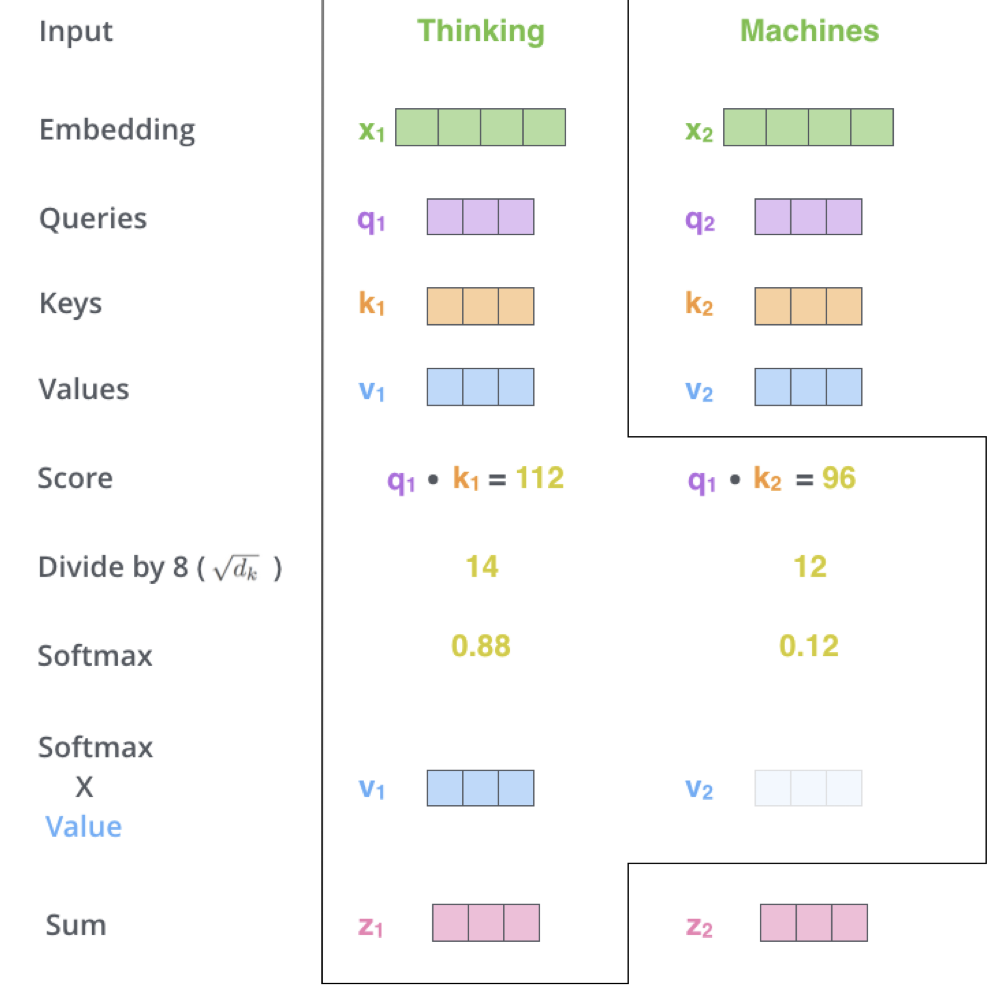
5) 将每个词的value*softmax得分,凭直观可以看出只关注那些我们注意的词,而drop-out那些无关的词(只需要乘以一个足够小的数)
6)把softmax*v加起来便可得到当前词对于整个序列而言的attetion
关于计算attention进一步解释
要把分值转换成一个概率,所以这里用到一个softmax,便可以得到一个词与其他词的分值,然后与其他词value做点积,便可得到self-attention的值
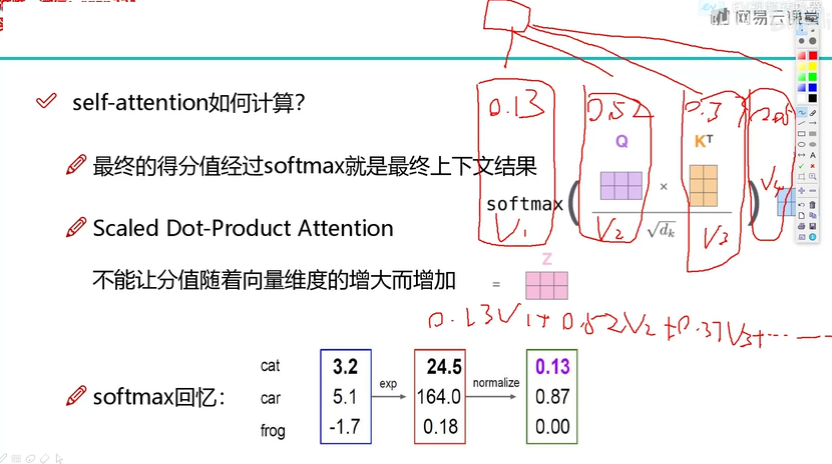
这个的最后用softmax输出与z做一个点积运算 求sum,单个词的对其他词的attention,然后在乘以V(实际特征信息)

多头机制multi-headed
- 1)让模型可以关注到不同的位置,要知道每一个attention都是体现当前词对整个序列的影响,当我的W不同的时候,得到的Q,K,V都不同,直接计算出来的attention都不一样;
- 2)可以得到attetion 层多种不同的子空间;
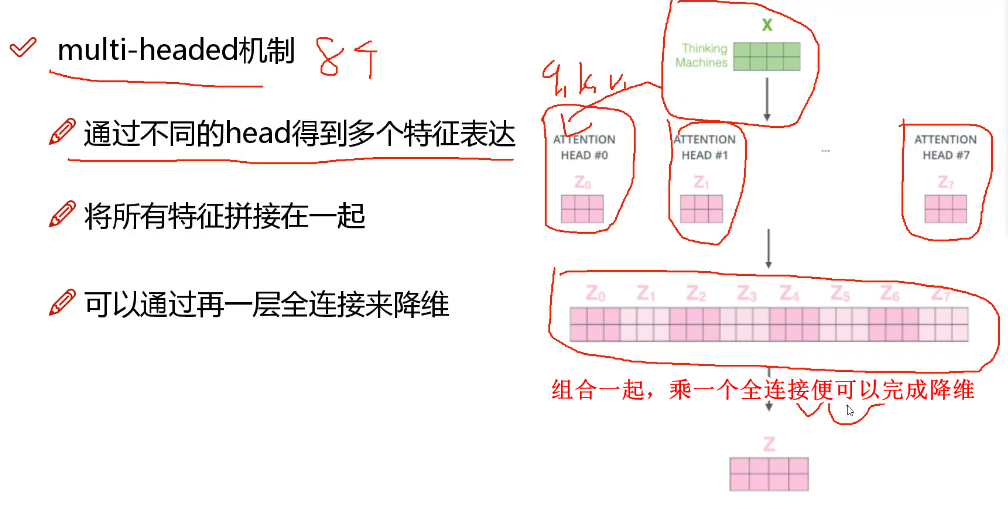
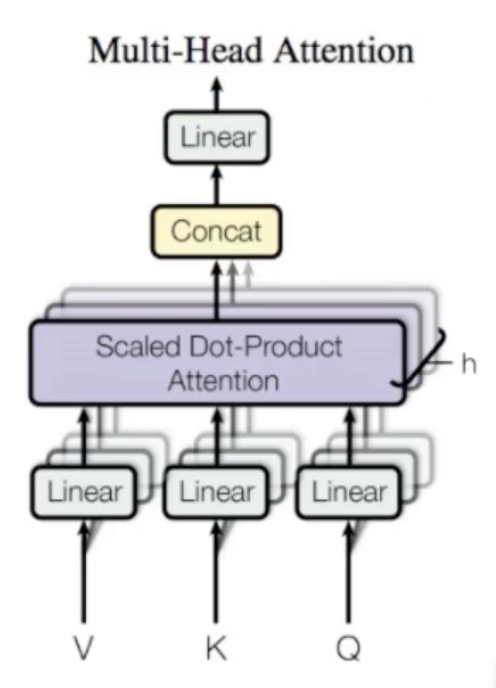
多头计算过程详细解释
首先会有多个W*矩阵去跟词嵌入矩阵做乘积,得到QKV,然后分别计算attention,拿到多个头的注意力,最后拼接成一个大的Z,在经过FF网络输出每个词经过模型后的embed
位置信息表达
词的位置会产生影响,所以add一个vector到输入的嵌入层,引入的这个vector要能够表达出整个序列词的顺序,还有不同词之间的distance信息;

BERT
结构
BERT其实就是transformer的编码器部分,其结构如下所示,首先是embedding层,分成三个部分,词嵌入、位置潜入、token类型嵌入;
embeddings.word_embeddings.weight torch.Size([173347, 768])
embeddings.position_embeddings.weight torch.Size([512, 768])
embeddings.token_type_embeddings.weight torch.Size([2, 768])
embeddings.LayerNorm.weight torch.Size([768])
embeddings.LayerNorm.bias torch.Size([768])
encoder.layer.0.attention.self.query.weight torch.Size([768, 768])
encoder.layer.0.attention.self.query.bias torch.Size([768])
encoder.layer.0.attention.self.key.weight torch.Size([768, 768])
encoder.layer.0.attention.self.key.bias torch.Size([768])
encoder.layer.0.attention.self.value.weight torch.Size([768, 768])
encoder.layer.0.attention.self.value.bias torch.Size([768])
encoder.layer.0.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.0.attention.output.dense.bias torch.Size([768])
encoder.layer.0.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.0.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.0.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.0.intermediate.dense.bias torch.Size([3072])
encoder.layer.0.output.dense.weight torch.Size([768, 3072])
encoder.layer.0.output.dense.bias torch.Size([768])
encoder.layer.0.output.LayerNorm.weight torch.Size([768])
encoder.layer.0.output.LayerNorm.bias torch.Size([768])
encoder.layer.1.attention.self.query.weight torch.Size([768, 768])
encoder.layer.1.attention.self.query.bias torch.Size([768])
encoder.layer.1.attention.self.key.weight torch.Size([768, 768])
encoder.layer.1.attention.self.key.bias torch.Size([768])
encoder.layer.1.attention.self.value.weight torch.Size([768, 768])
encoder.layer.1.attention.self.value.bias torch.Size([768])
encoder.layer.1.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.1.attention.output.dense.bias torch.Size([768])
encoder.layer.1.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.1.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.1.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.1.intermediate.dense.bias torch.Size([3072]) encoder.layer.1.output.dense.weight torch.Size([768, 3072]) encode
r.layer.1.output.dense.bias torch.Size([768]) encoder.layer.1.output.LayerNorm.weight torch.Size([768]) encoder.layer.1.output.LayerNorm.bias torch.Size([768]) encoder.layer.2.attention.self.query.weight torch.Size([768, 768]) encoder.layer.2.attention.self.query.bias torch.Size([768])
encoder.layer.2.attention.self.key.weight torch.Size([768, 768]) encoder.layer.2.attention.self.key.bias torch.Size([768]) encoder.layer.2.attention.self.value.weight torch.Size([768, 768]) encoder.layer.2.attention.self.value.bias torch.Size([768]) encoder.layer.2.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.2.attention.output.dense.bias torch.Size([768]) encoder.layer.2.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.2.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.2.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.2.intermediate.dense.bias torch.Size([3072]) encoder.layer.2.output.dense.weight torch.Size([768, 3072]) encoder.layer.2.output.dense.bias torch.Size([768]) encoder.layer.2.output.LayerNorm.weight torch.Size([768]) encoder.layer.2.output.LayerNorm.bias torch.Size([768]) encoder.layer.3.attention.self.query.weight torch.Size([768, 768]) encoder.layer.3.attention.self.query.bias torch.Size([768]) encoder.layer.3.attention.self.key.weight torch.Size([768, 768]) encoder.layer.3.attention.self.key.bias torch.Size([768]) encoder.layer.3.attention.self.value.weight torch.Size([768, 768]) encoder.layer.3.attention.self.value.bias torch.Size([768]) encoder.layer.3.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.3.attention.output.dense.bias torch.Size([768]) encoder.layer.3.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.3.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.3.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.3.intermediate.dense.bias torch.Size([3072]) encoder.layer.3.output.dense.weight torch.Size([768, 3072]) encoder.layer.3.output.dense.bias torch.Size([768]) encoder.layer.3.output.LayerNorm.weight torch.Size([768]) encoder.layer.3.output.LayerNorm.bias torch.Size([768]) encoder.layer.4.attention.self.query.weight torch.Size([768, 768]) encoder.layer.4.attention.self.query.bias torch.Size([768]) encoder.layer.4.attention.self.key.weight torch.Size([768, 768]) encoder.layer.4.attention.self.key.bias torch.Size([768]) encoder.layer.4.attention.self.value.weight torch.Size([768, 768]) encoder.layer.4.attention.self.value.bias torch.Size([768]) encoder.layer.4.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.4.attention.output.dense.bias torch.Size([768]) encoder.layer.4.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.4.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.4.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.4.intermediate.dense.bias torch.Size([3072]) encoder.layer.4.output.dense.weight torch.Size([768, 3072]) encoder.layer.4.output.dense.bias torch.Size([768]) encoder.layer.4.output.LayerNorm.weight torch.Size([768]) encoder.layer.4.output.LayerNorm.bias torch.Size([768]) encoder.layer.5.attention.self.query.weight torch.Size([768, 768]) encoder.layer.5.attention.self.query.bias torch.Size([768]) encoder.layer.5.attention.self.key.weight torch.Size([768, 768]) encoder.layer.5.attention.self.key.bias torch.Size([768]) encoder.layer.5.attention.self.value.weight torch.Size([768, 768]) encoder.layer.5.attention.self.value.bias torch.Size([768]) encoder.layer.5.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.5.attention.output.dense.bias torch.Size([768]) encoder.layer.5.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.5.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.5.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.5.intermediate.dense.bias torch.Size([3072]) encoder.layer.5.output.dense.weight torch.Size([768, 3072]) encoder.layer.5.output.dense.bias torch.Size([768]) encoder.layer.5.output.LayerNorm.weight torch.Size([768]) encoder.layer.5.output.LayerNorm.bias torch.Size([768]) encoder.layer.6.attention.self.query.weight torch.Size([768, 768]) encoder.layer.6.attention.self.query.bias torch.Size([768]) encoder.layer.6.attention.self.key.weight torch.Size([768, 768]) encoder.layer.6.attention.self.key.bias torch.Size([768]) encoder.layer.6.attention.self.value.weight torch.Size([768, 768]) encoder.layer.6.attention.self.value.bias torch.Size([768]) encoder.layer.6.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.6.attention.output.dense.bias torch.Size([768]) encoder.layer.6.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.6.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.6.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.6.intermediate.dense.bias torch.Size([3072]) encoder.layer.6.output.dense.weight torch.Size([768, 3072]) encoder.layer.6.output.dense.bias torch.Size([768]) encoder.layer.6.output.LayerNorm.weight torch.Size([768]) encoder.layer.6.output.LayerNorm.bias torch.Size([768]) encoder.layer.7.attention.self.query.weight torch.Size([768, 768]) encoder.layer.7.attention.self.query.bias torch.Size([768]) encoder.layer.7.attention.self.key.weight torch.Size([768, 768]) encoder.layer.7.attention.self.key.bias torch.Size([768]) encoder.layer.7.attention.self.value.weight torch.Size([768, 768]) encoder.layer.7.attention.self.value.bias torch.Size([768]) encoder.layer.7.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.7.attention.output.dense.bias torch.Size([768]) encoder.layer.7.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.7.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.7.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.7.intermediate.dense.bias torch.Size([3072]) encoder.layer.7.output.dense.weight torch.Size([768, 3072]) encoder.layer.7.output.dense.bias torch.Size([768]) encoder.layer.7.output.LayerNorm.weight torch.Size([768]) encoder.layer.7.output.LayerNorm.bias torch.Size([768]) encoder.layer.8.attention.self.query.weight torch.Size([768, 768]) encoder.layer.8.attention.self.query.bias torch.Size([768]) encoder.layer.8.attention.self.key.weight torch.Size([768, 768]) encoder.layer.8.attention.self.key.bias torch.Size([768]) encoder.layer.8.attention.self.value.weight torch.Size([768, 768]) encoder.layer.8.attention.self.value.bias torch.Size([768]) encoder.layer.8.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.8.attention.output.dense.bias torch.Size([768]) encoder.layer.8.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.8.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.8.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.8.intermediate.dense.bias torch.Size([3072]) encoder.layer.8.output.dense.weight torch.Size([768, 3072]) encoder.layer.8.output.dense.bias torch.Size([768]) encoder.layer.8.output.LayerNorm.weight torch.Size([768]) encoder.layer.8.output.LayerNorm.bias torch.Size([768]) encoder.layer.9.attention.self.query.weight torch.Size([768, 768]) encoder.layer.9.attention.self.query.bias torch.Size([768]) encoder.layer.9.attention.self.key.weight torch.Size([768, 768]) encoder.layer.9.attention.self.key.bias torch.Size([768]) encoder.layer.9.attention.self.value.weight torch.Size([768, 768]) encoder.layer.9.attention.self.value.bias torch.Size([768]) encoder.layer.9.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.9.attention.output.dense.bias torch.Size([768]) encoder.layer.9.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.9.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.9.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.9.intermediate.dense.bias torch.Size([3072]) encoder.layer.9.output.dense.weight torch.Size([768, 3072]) encoder.layer.9.output.dense.bias torch.Size([768]) encoder.layer.9.output.LayerNorm.weight torch.Size([768]) encoder.layer.9.output.LayerNorm.bias torch.Size([768]) encoder.layer.10.attention.self.query.weight torch.Size([768, 768]) encoder.layer.10.attention.self.query.bias torch.Size([768]) encoder.layer.10.attention.self.key.weight torch.Size([768, 768]) encoder.layer.10.attention.self.key.bias torch.Size([768]) encoder.layer.10.attention.self.value.weight torch.Size([768, 768]) encoder.layer.10.attention.self.value.bias torch.Size([768]) encoder.layer.10.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.10.attention.output.dense.bias torch.Size([768]) encoder.layer.10.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.10.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.10.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.10.intermediate.dense.bias torch.Size([3072]) encoder.layer.10.output.dense.weight torch.Size([768, 3072]) encoder.layer.10.output.dense.bias torch.Size([768]) encoder.layer.10.output.LayerNorm.weight torch.Size([768]) encoder.layer.10.output.LayerNorm.bias torch.Size([768]) encoder.layer.11.attention.self.query.weight torch.Size([768, 768]) encoder.layer.11.attention.self.query.bias torch.Size([768]) encoder.layer.11.attention.self.key.weight torch.Size([768, 768]) encoder.layer.11.attention.self.key.bias torch.Size([768]) encoder.layer.11.attention.self.value.weight torch.Size([768, 768]) encoder.layer.11.attention.self.value.bias torch.Size([768]) encoder.layer.11.attention.output.dense.weight torch.Size([768, 768]) encoder.layer.11.attention.output.dense.bias torch.Size([768]) encoder.layer.11.attention.output.LayerNorm.weight torch.Size([768]) encoder.layer.11.attention.output.LayerNorm.bias torch.Size([768]) encoder.layer.11.intermediate.dense.weight torch.Size([3072, 768]) encoder.layer.11.intermediate.dense.bias torch.Size([3072]) encoder.layer.11.output.dense.weight torch.Size([768, 3072]) encoder.layer.11.output.dense.bias torch.Size([768]) encoder.layer.11.output.LayerNorm.weight torch.Size([768]) encoder.layer.11.output.LayerNorm.bias torch.Size([768]) pooler.dense.weight torch.Size([768, 768]) pooler.dense.bias torch.Size([768])
说明
按照官网给出的 BERT 技术,一方面因为是 unsupervised ,另一方面是因为用于预训练 NLP 的深度双向系统。预训练表示既可以是 context-free 也可是 contexual
- context-free: word2vec 和 glove
- 上下文相关的模型:BERT、ELMO;例如 I made a bank deposit中 对bank的理解 bert会看bank的前后。
而其他模型要么只看左边,要么只看右边 pre-training & fine-tunings 难的是对词的编码,就是transfomer的encoder部分;
如何训练bert
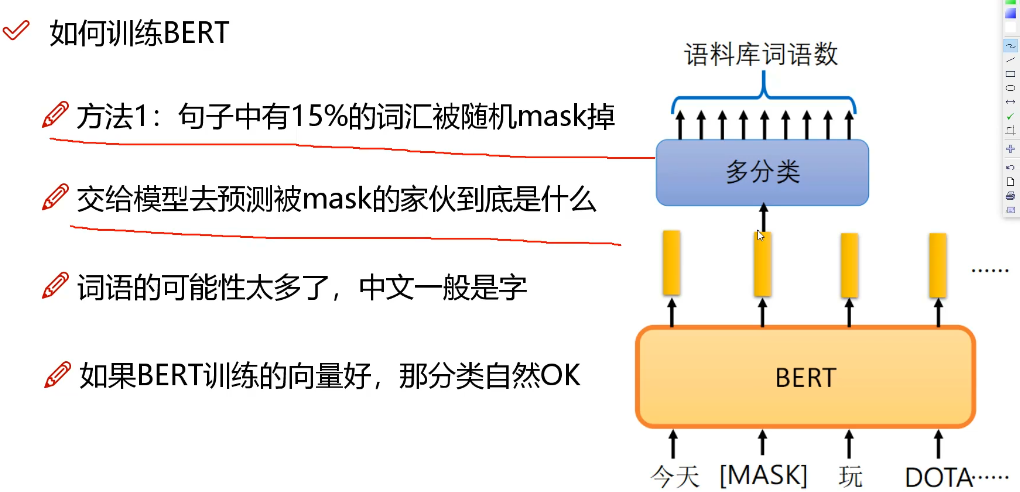
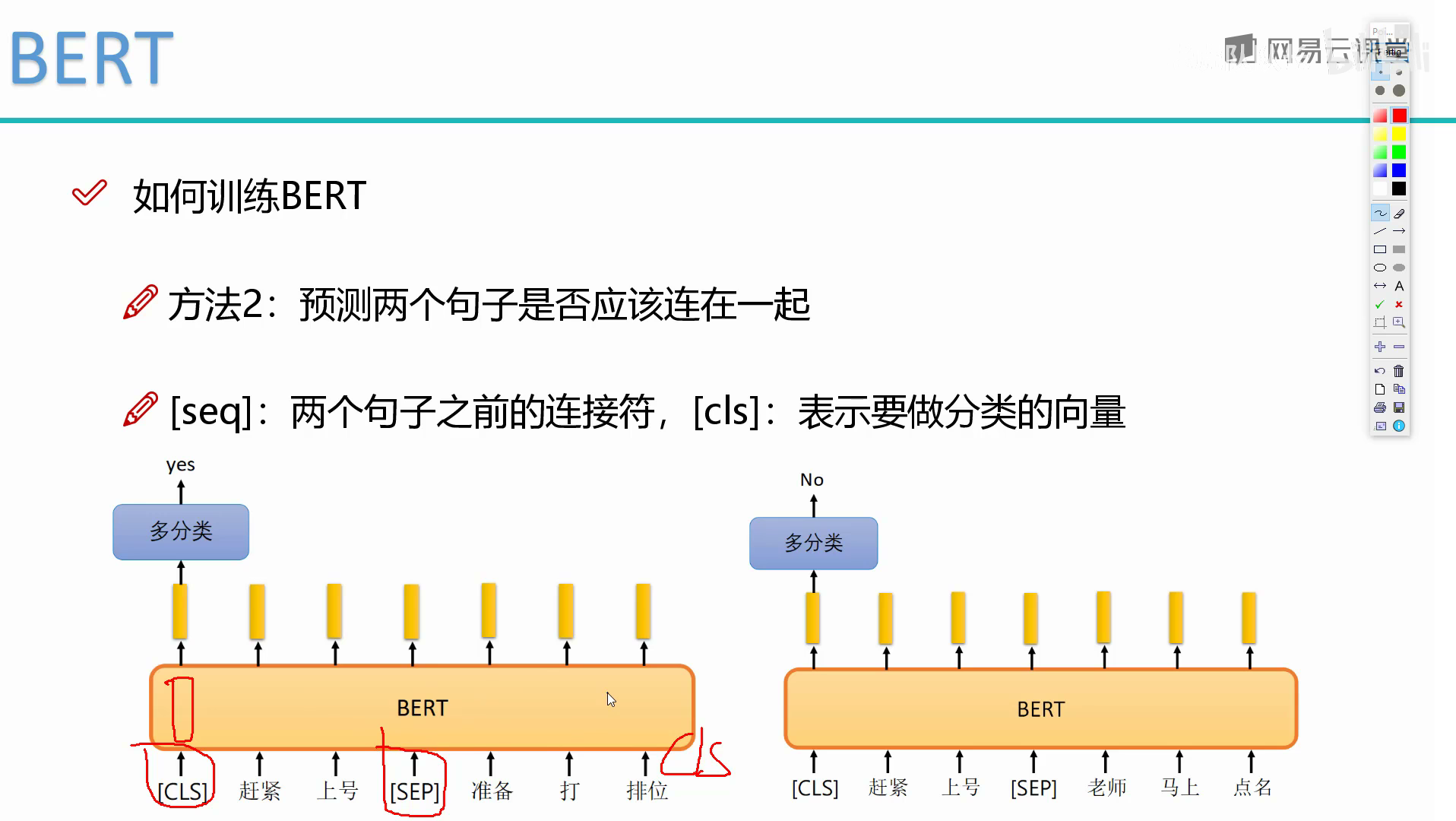
BERT 是一种端到端的模型
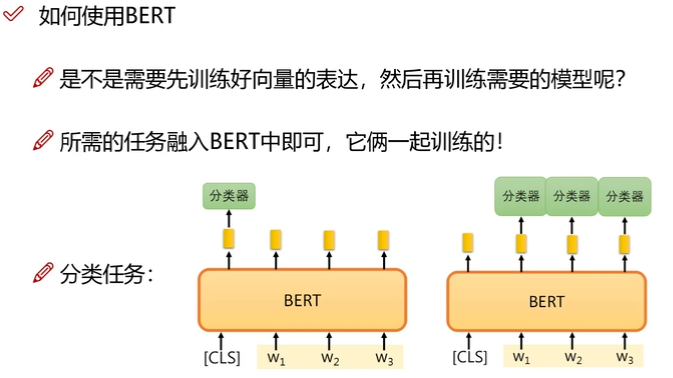
可以讲 BERT 模型已经训练好的参数加载进来,然后直接在下游任务进行微调是目前主流做法。
参考资料
- https://zhuanlan.zhihu.com/p/48508221
- http://jalammar.github.io/illustrated-transformer/






![C++——类和对象[中]](https://img-blog.csdnimg.cn/img_convert/91ac2b1aaf8c363bca7c649cb98b6d65.png)