pandas的两个主要数据结构是:Series(一维数据)、DataFrame(二维数据)。
Series
Series是一种类似于NumPy中一维数组的对象,它由一组任意类型的数据以及一组与之相关的数据标签组成。
import pandas as pd
print(pd.Series([1, 10, 100, 1000]))
| 0 | 1 |
|---|---|
| 1 | 10 |
| 2 | 100 |
| 3 | 1000 |
dtype: int64
左边搜索数据标签,默认从零开始递增。右边是对应的数据,最后一行表明了数据类型。
也可以像下面这样使用index参数来自定义数据标签。
a = pd.Series([2, 4, 6, 8], index=['a', 'b', 'c', 'd'])
print(a)
| a | 2 |
|---|---|
| b | 4 |
| c | 6 |
| d | 8 |
dtype: int64
还可以直接使用字典同时创建带有自定义数据标签的数据,pandas会自动把字典的key当作数据标签,将value当作对应的数据。
print(pd.Series({"a":1,"b":11, "c":111, "d":1111}))
| a | 1 |
|---|---|
| b | 11 |
| c | 111 |
| d | 1111 |
dtype: int64
访问Series里的数据方式和python里访问字典和列表的方式类似。
s1 = pd.Series([2, 4, 6, 8])
print(s1[0]) # input: 2
s2 = pd.Series({"a":1, "b":2, "c": 3})
print(s2['b']) # input 2
pandas有着强大的数据对齐功能。
s3 = s1 + s1 # 将s1和s1的各个列相加是可以的。
如果相加的两个Series项不一样,就会出现NaN( Not a Number)。因为其中一个Series中没有对应数据标签的数据,无法进行计算。
对于这种情况,可以使用Series的add()方法,并设置好默认值既可。
s1 = pd.Series({"a":1, "c": 3, "d": 34})
s2 = pd.Series({"b": 4, "c": 34344})
print(s1.add(s2, fill_value = 0))
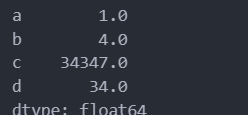
数学中的四则运算在pandas中都有一一对应的方法。
| + | add() | s1.add(s2, fill_value=0) |
|---|---|---|
| - | sub() | s1.sub(s2, fill_value=0) |
| * | mul() | s1.mul(s2, fill_value=0) |
| / | div() | s1.div(s2, fill_value=0) |
DataFrame
DataFrame是二维数据,可以当作一个表格,表格中的每一行或列都是一个Series。
- 按行分,每一行数据加上上面的数据标签就是一个Series
- 按列分,每一列数据加上左边的数据标签是一个Series。
DataFrame最常见的创建方法是由等长列表组成的字典。要求长度也相等。
df = pd.DataFrame({
"A":[1,2],
"B": [3, 4],
"C": [6, 34]
})
自定义索引标签
df = pd.Dataframe(data_object, index=["a", "b"])
列的增删查改
单列查
print(df["A"])
多列查
print(df([["A", "B"]]))
修改
df["A"] = [0,-1]
新增
df["NEW_COLUME"] = [1, 1]
删除列
df.drop("A", axis=1, inplace=True)
drop()方法是第一个参数表示要删除的列名或索引,axis表示针对行或列进行删除,axis=0表示删除对应的行,axis=1表示删除对应的列,axis默认为0。最后一个inplace=True表示直接修改原数据,否则只是返回删除后的表格,对原数据没有影响。
Pandas简介 - 知乎 (zhihu.com)