一、 Kettle
上篇文章对 Kettle 流程、应用算子进行了介绍,本篇对查询、连接、统计、脚本算子进行讲解,下面是上篇文章的地址:
ETL工具 - Kettle 流程、应用算子介绍
二、查询算子
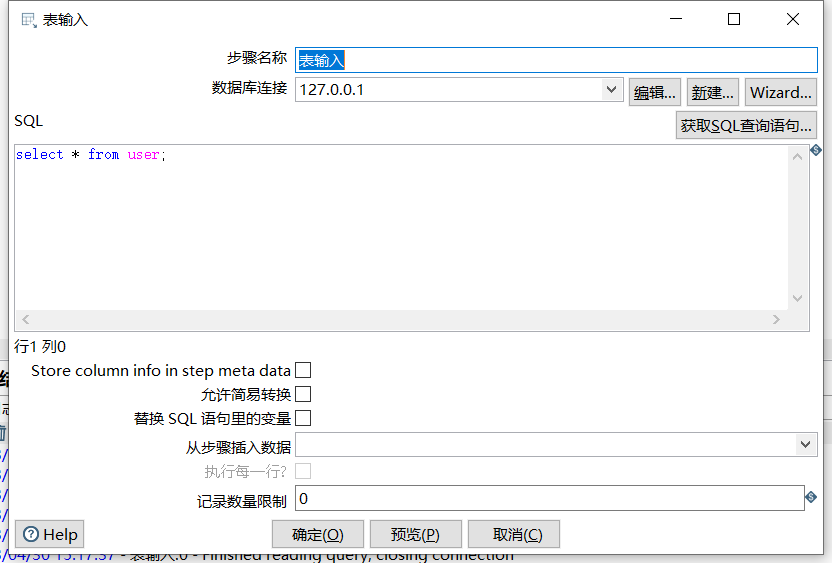
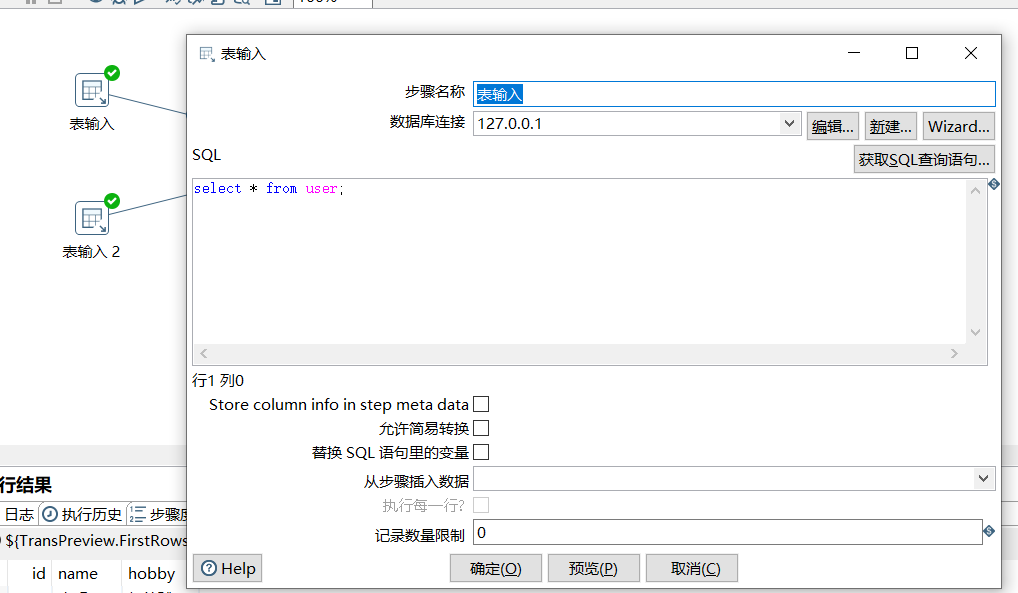
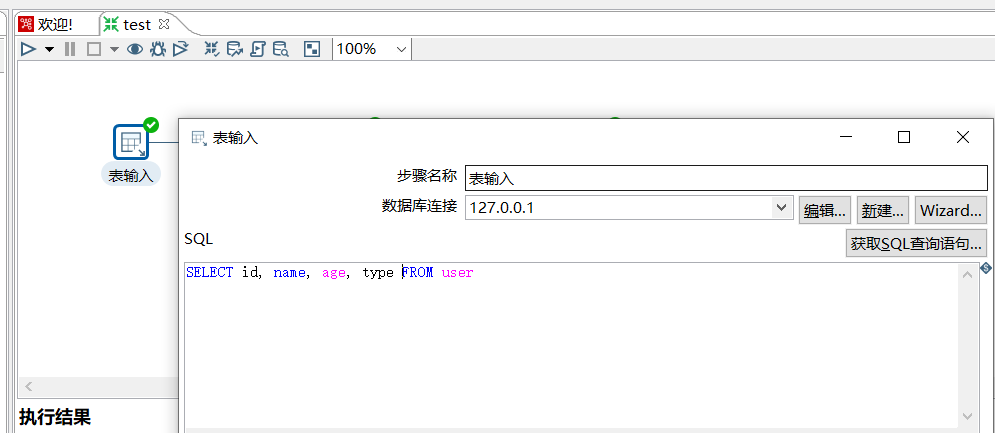
数据输入使用 MySQL 表输入,表结构如下:
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
`type` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (1, '小明', 90, '1');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (3, '小兰', 92, '1');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (4, '小爱', 93, '1');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (5, '张三', 94, '1');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (6, '李四', 95, '1');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (7, '王五', 96, '1');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (8, '赵六', 97, '1');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (9, 'xiao ai', 22, '2');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (10, 'wang wu ', 23, '2');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (11, '小王,小七', 22, '3');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `type`) VALUES (12, '小八,小九', 23, '3');
表输入控件:
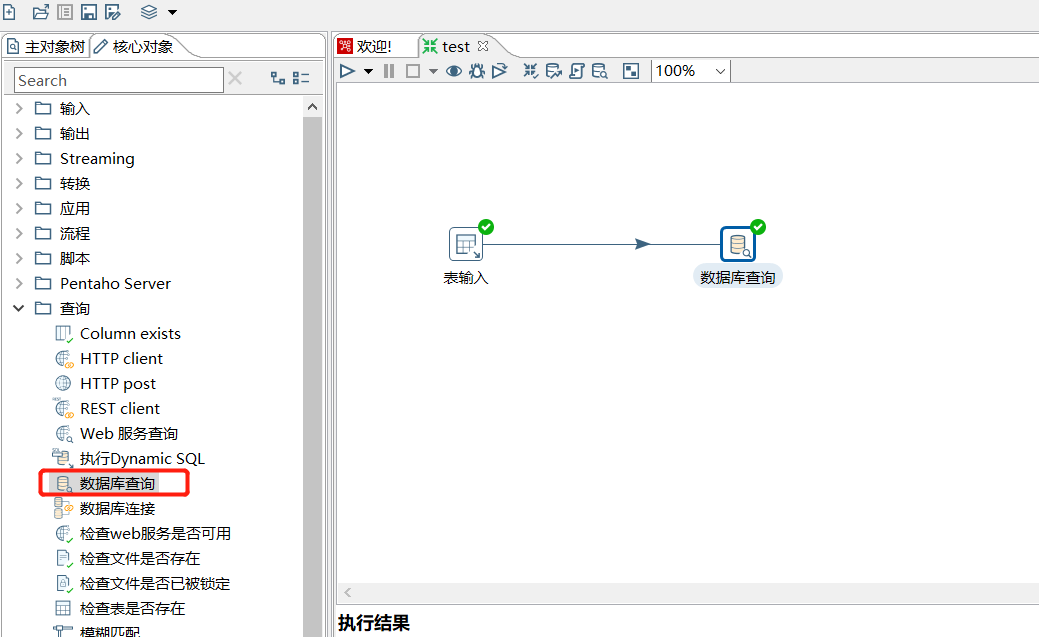
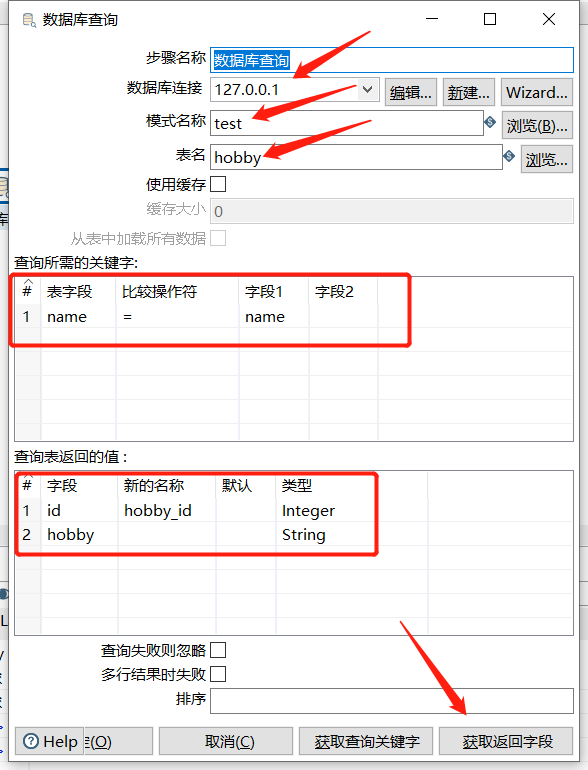
2.1 数据库查询
从数据库里面查询出数据,然后跟数据流中的数据进行左连接:
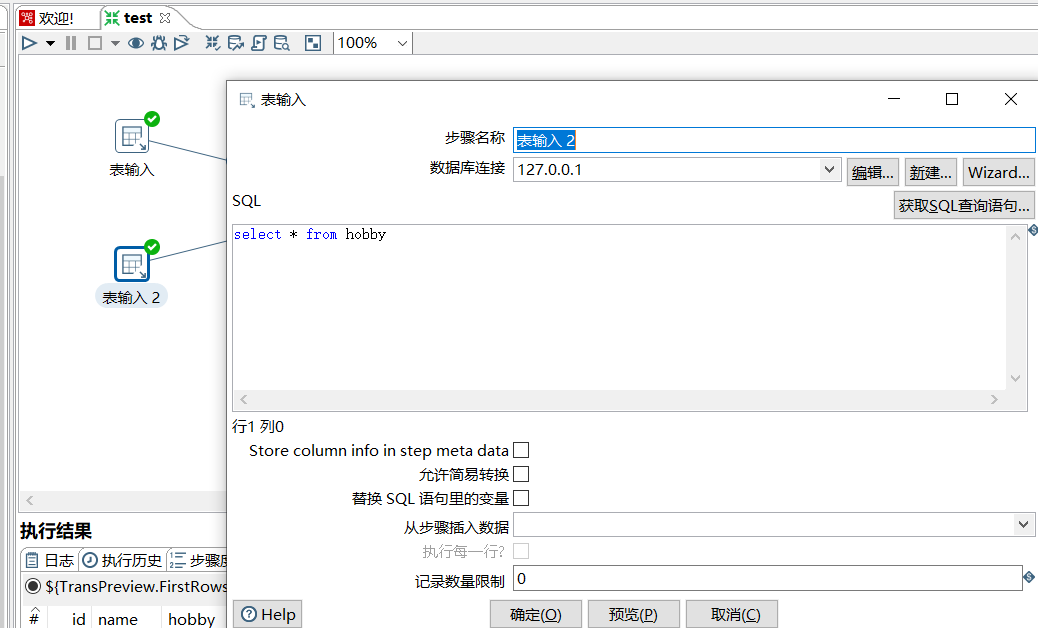
创建测试表:
CREATE TABLE `hobby` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`hobby` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `test`.`hobby`(`id`, `name`, `hobby`) VALUES (1, '小明', '打篮球');
INSERT INTO `test`.`hobby`(`id`, `name`, `hobby`) VALUES (2, '小兰', '踢足球');
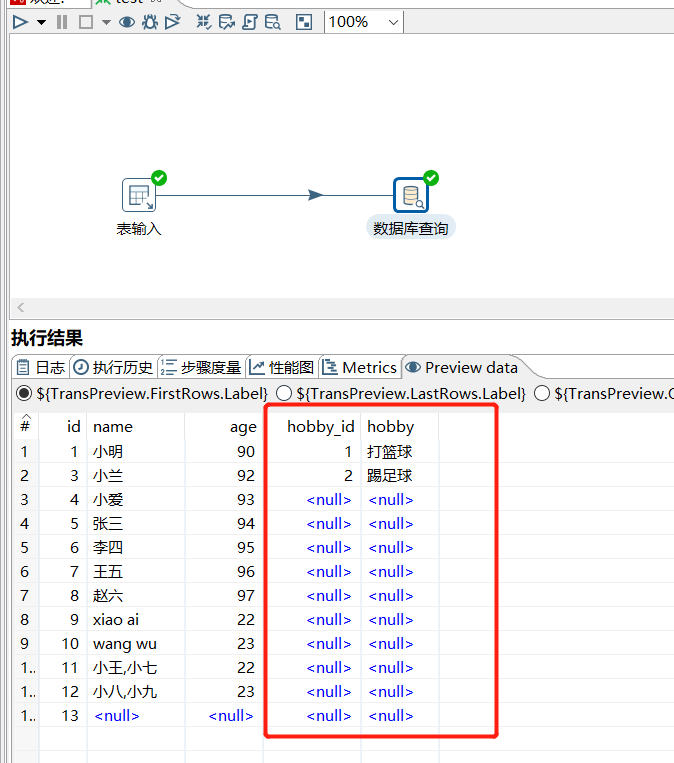
运行后效果:
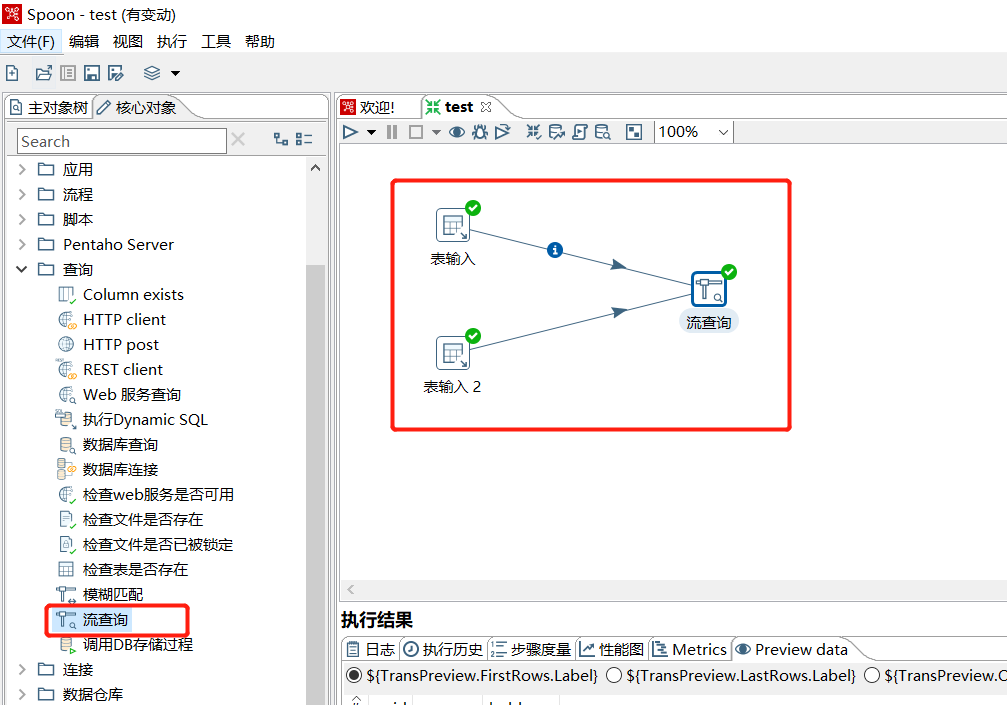
2.2 流查询
查询两条数据流中的数据,然后按照指定的字段做等值匹配。在查询前会把数据都加载到内存中,并且只能做等值查询,结果只能展示其中一条连接的数据:
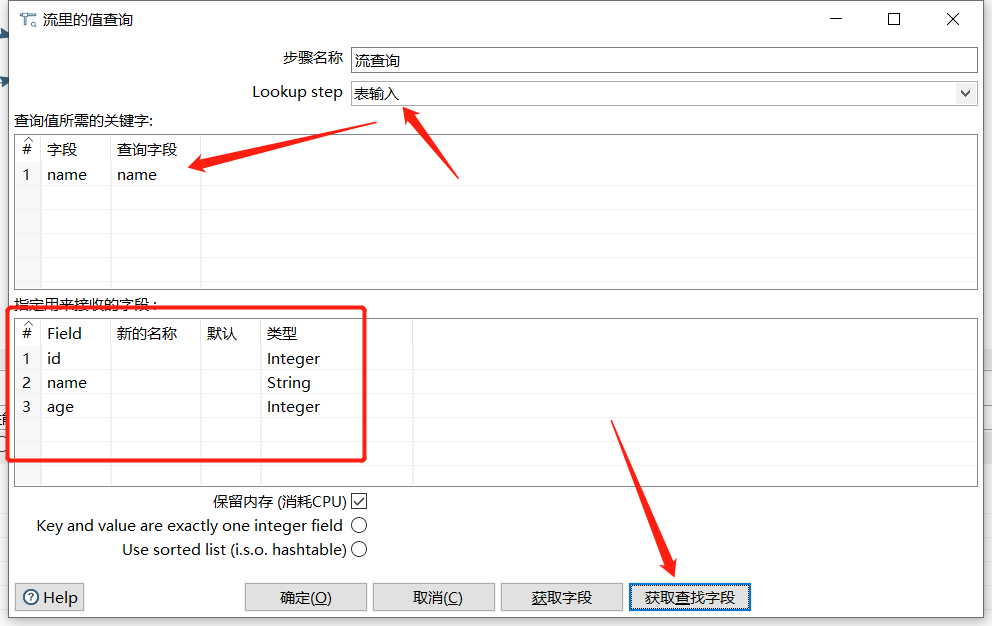
运行后效果:
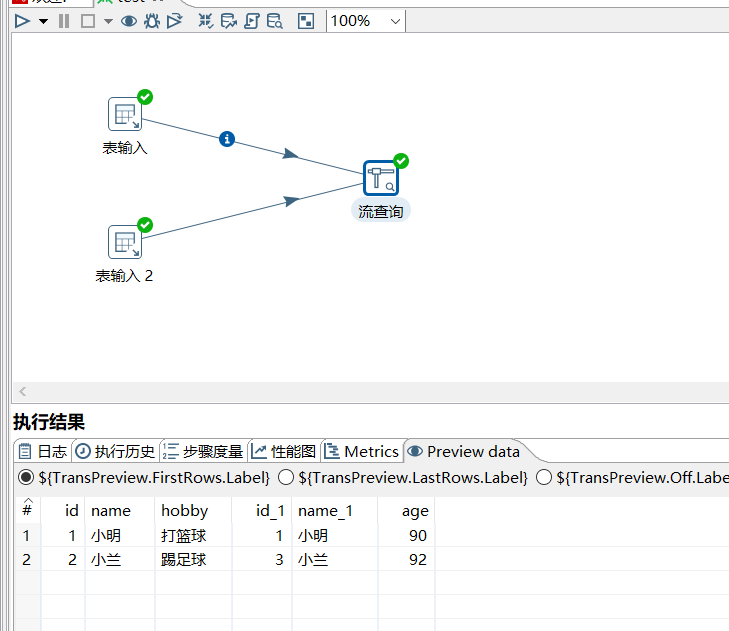
2.3 模糊匹配
需要有两个输入流,一个主数据流一个匹配流,会根据主数据流找出一个最佳的匹配流中的数据,匹配算法可以有多种选择。
比如修改 hobby 表数据为如下数据:
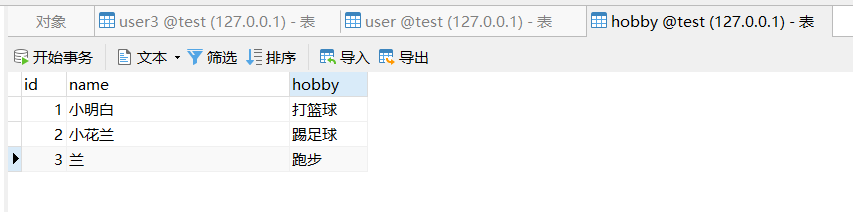
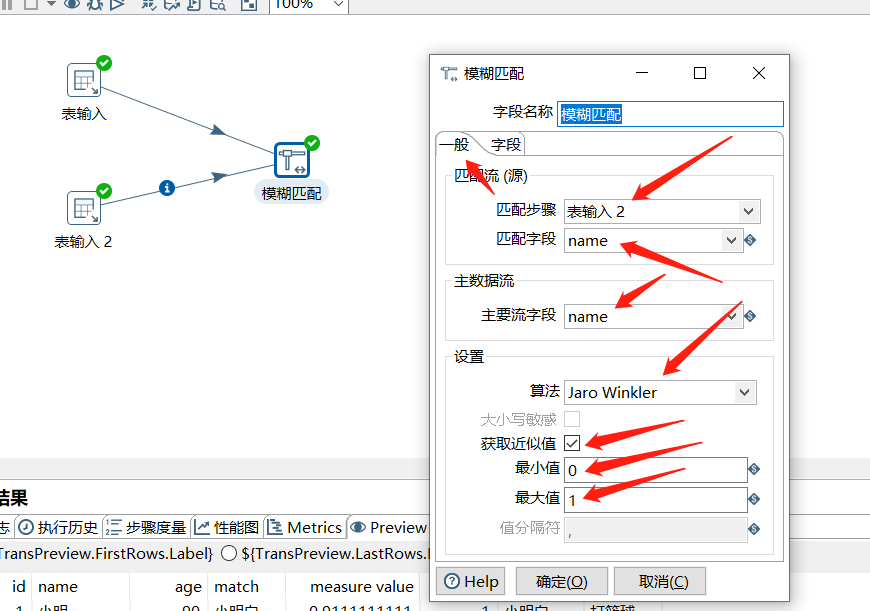
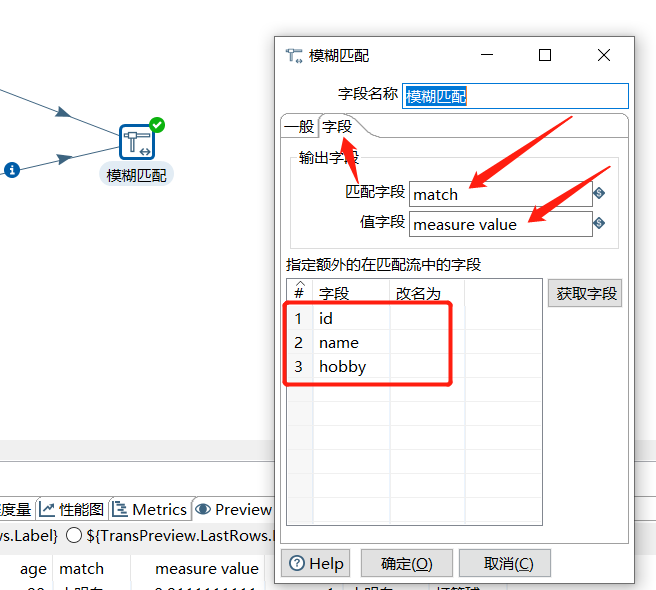
下面的 匹配字段、值字段 表示匹配时命中的内容和匹配的置信度的列名,可以固定写成 match、measure value
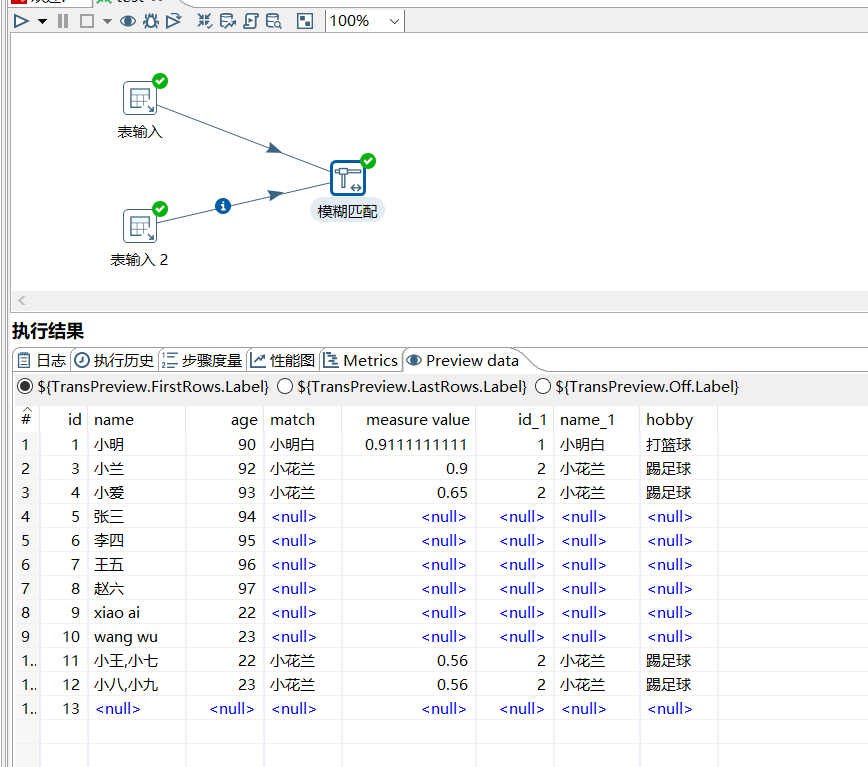
运行后查看结果:
三、连接算子
连接算子一般将多个数据集通过关键字进行连接,类似 SQL 中的连接操作:
3.1 合并记录
将两个不同来源的数据合并,数据分别为旧数据和新数据,将旧数据和新数据按照指定的关键字匹配、比较、合并。注意旧数据和新数据需要按照关键字段排序,并且旧数据和新数据要有相同的字段名称。
合并后的数据将包括旧数据和新数据的所有数据,对于变化的数据,使用新数据代替旧数据,同时在结果里用一个标示字段,来指定新旧数据的比较结果。
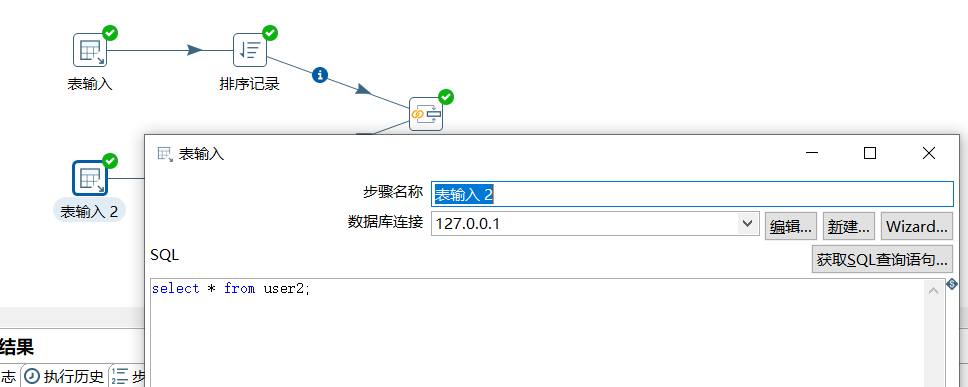
下面创建 user2 表作为 新数据:
CREATE TABLE `user2` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
`type` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `test`.`user2`(`id`, `name`, `age`, `type`) VALUES (1, '小明', 90, 1);
INSERT INTO `test`.`user2`(`id`, `name`, `age`, `type`) VALUES (3, '小兰', 92, 1);
INSERT INTO `test`.`user2`(`id`, `name`, `age`, `type`) VALUES (4, '小爱2', 93, 1);
INSERT INTO `test`.`user2`(`id`, `name`, `age`, `type`) VALUES (5, '张三2', 94, 1);
INSERT INTO `test`.`user2`(`id`, `name`, `age`, `type`) VALUES (6, '李四', 95, 1);
INSERT INTO `test`.`user2`(`id`, `name`, `age`, `type`) VALUES (7, '王五', 96, 1);
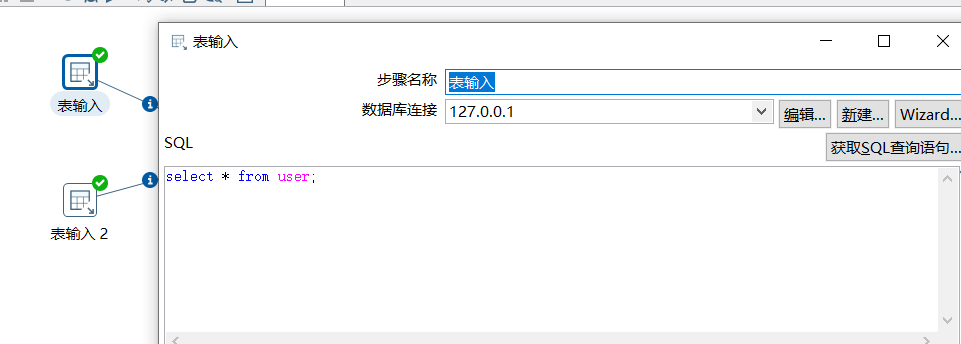
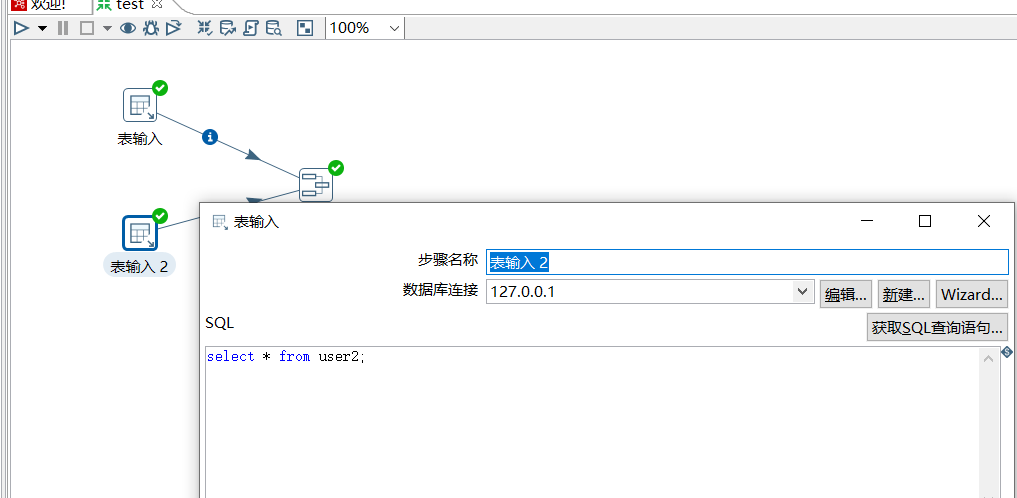
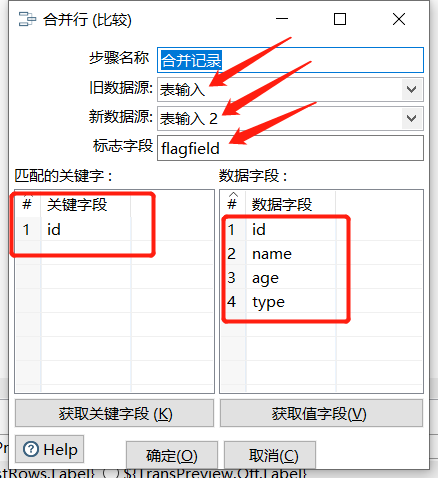
运行后查看结果:
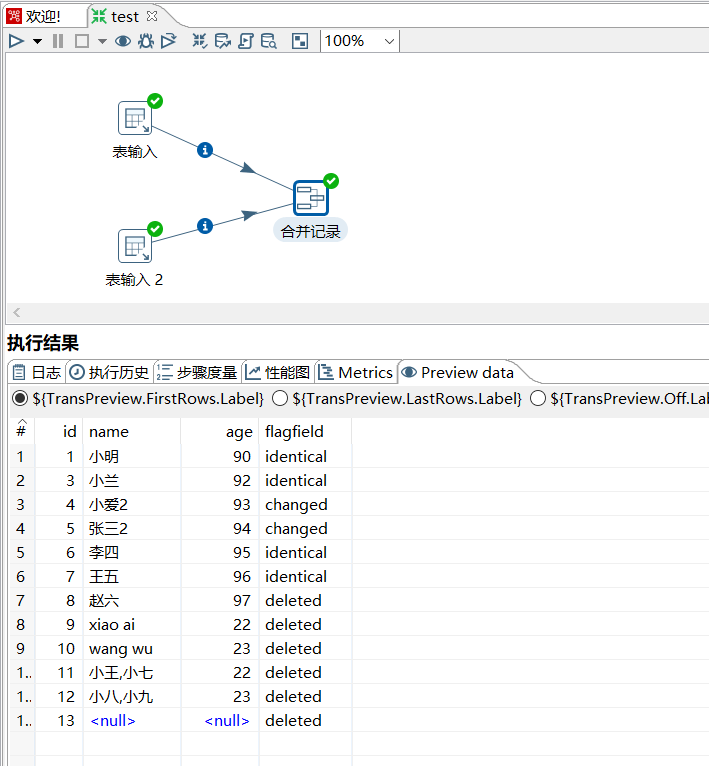
其中标志字段的含义:
identical: 旧数据和新数据一样changed: 数据发生了变化;new: 新数据中有而旧数据中没有的记录deleted:旧数据中有而新数据中没有的记录
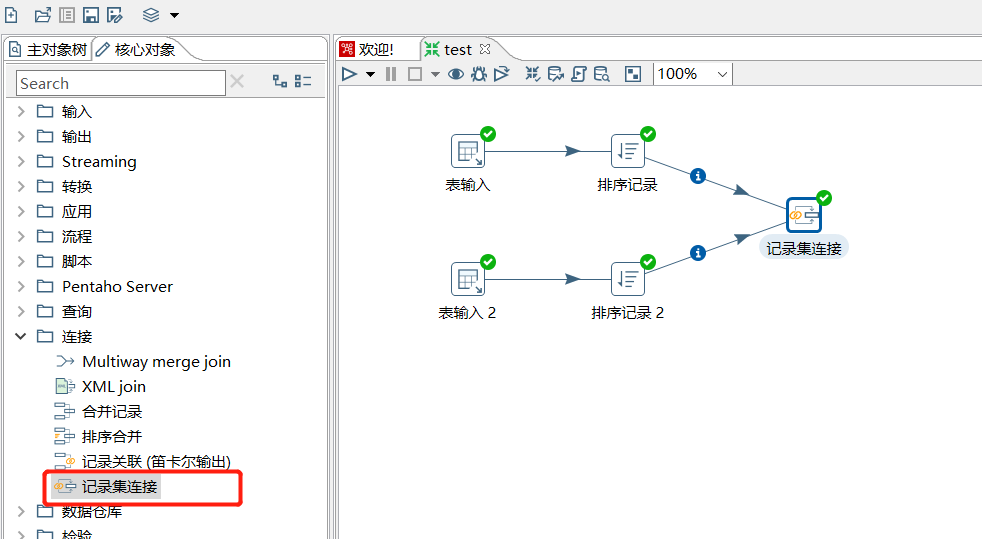
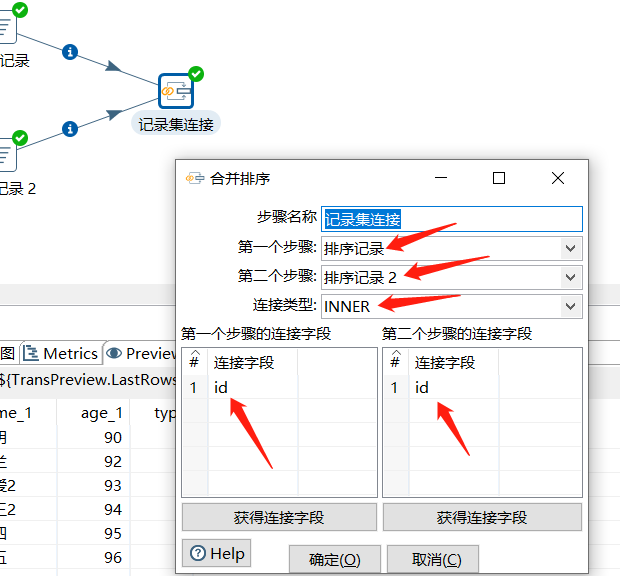
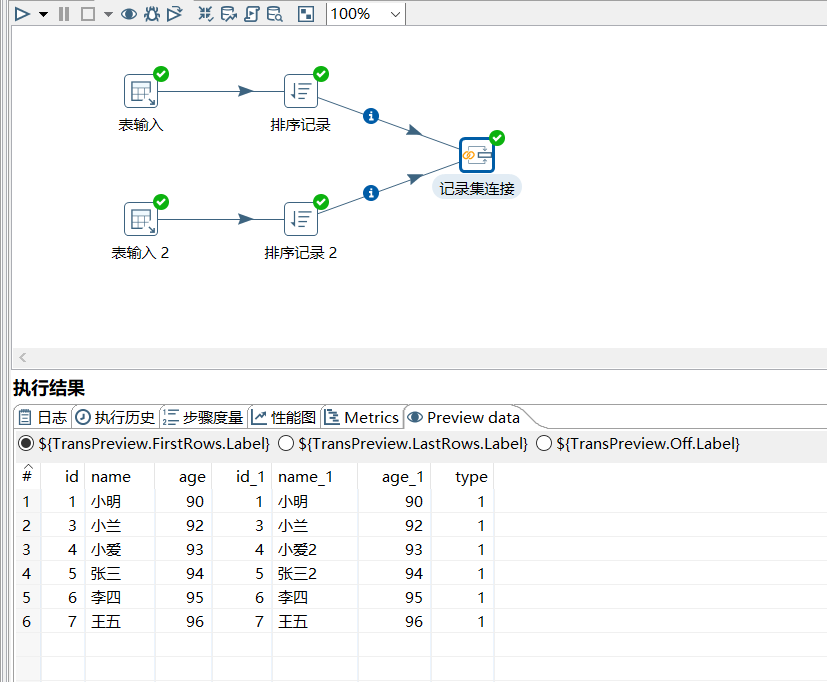
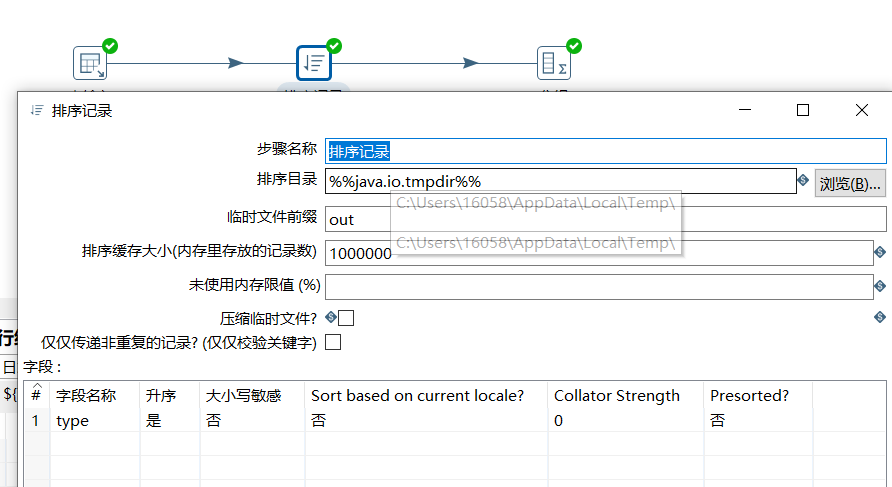
3.2 记录集连接
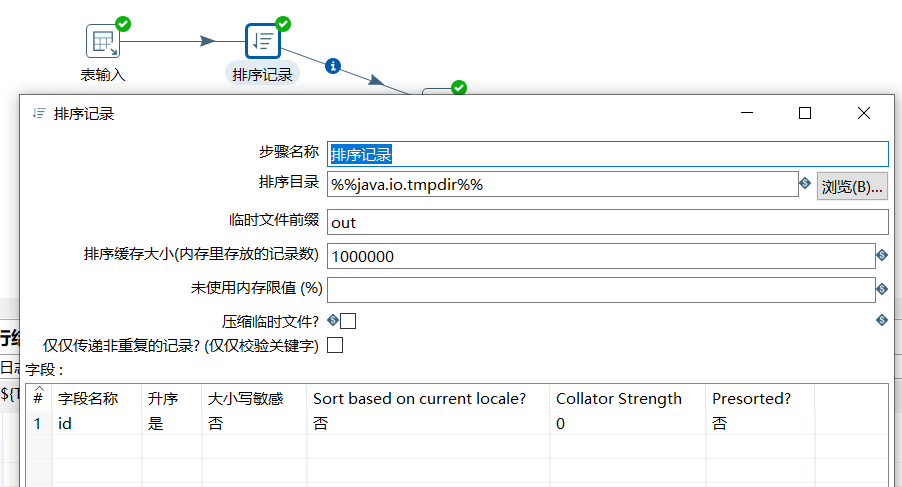
可以对两个步骤中的数据流进行左连接,右连接,内连接,外连接,进行记录集连接之前,需要对记录集的数据进行排序,排序字段需要是关联字段,否则数据会错乱出现null 值。
对 user 表和 user2 表进行内连接操作如下:

运行后查看结果:
四、统计算子
统计算子可以提供数据的采样和统计功能。
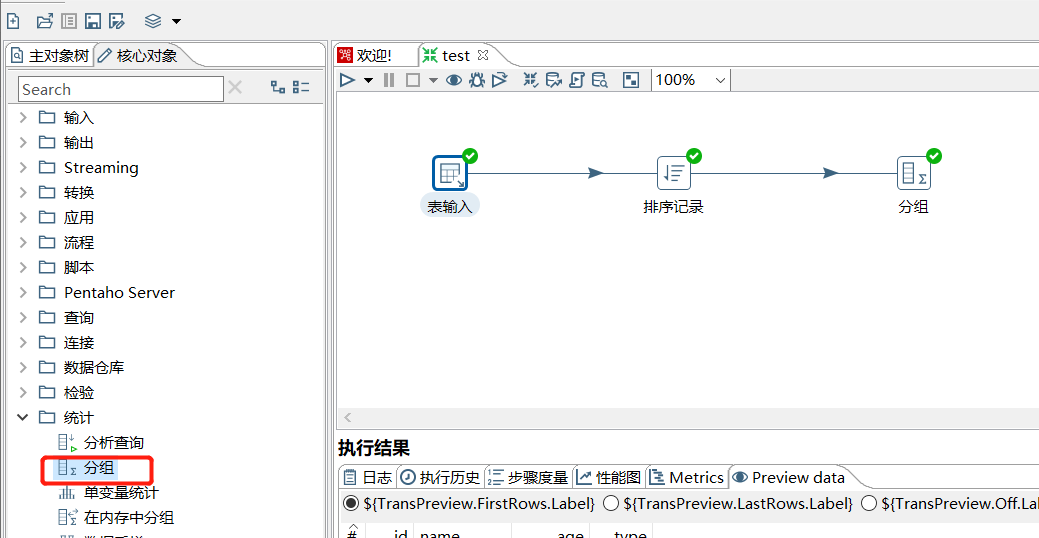
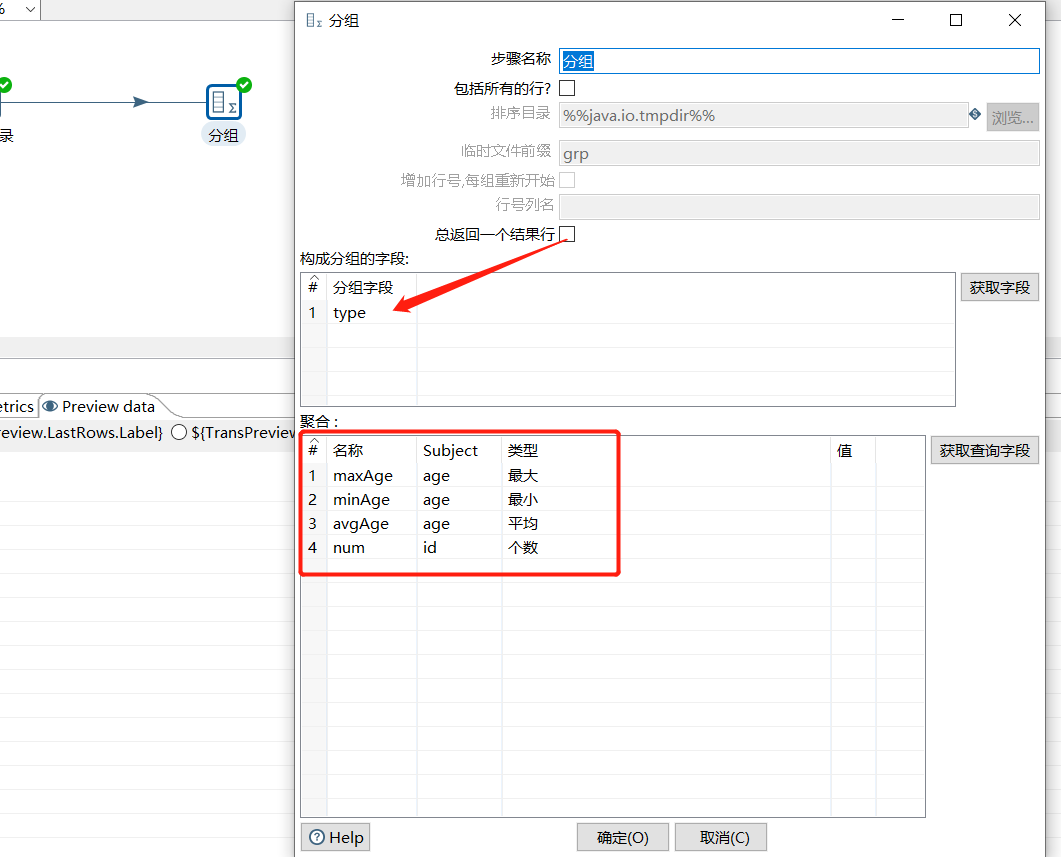
4.1 分组
类似于GROUP BY,可以按照指定的一个或者几个字段进行分组,然后其余字段可以按照聚合函数进行合并计算。注意,在进行分组之前,最好先进行排序。
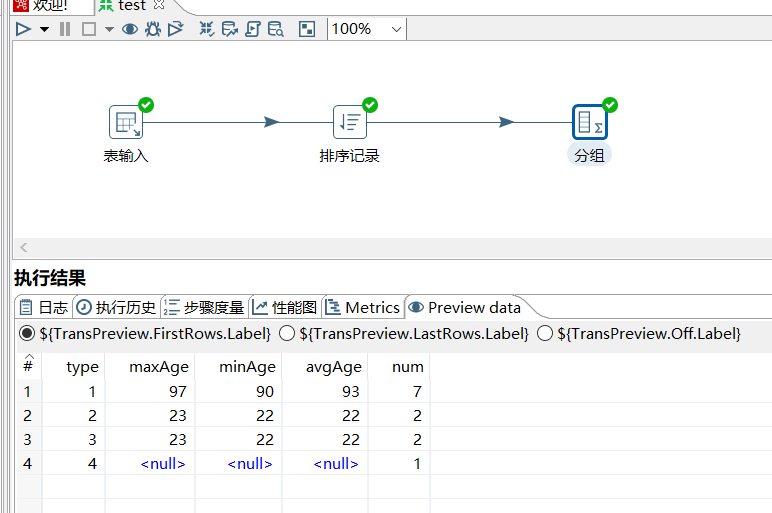
下面对 user 表根据 type 分组后取 age 的最大、最小、平均、数量 :
运行后查看结果:
五、脚本算子
脚本算子可以通过程序代码完成一些复杂的操作。
5.1 执行SQL脚本
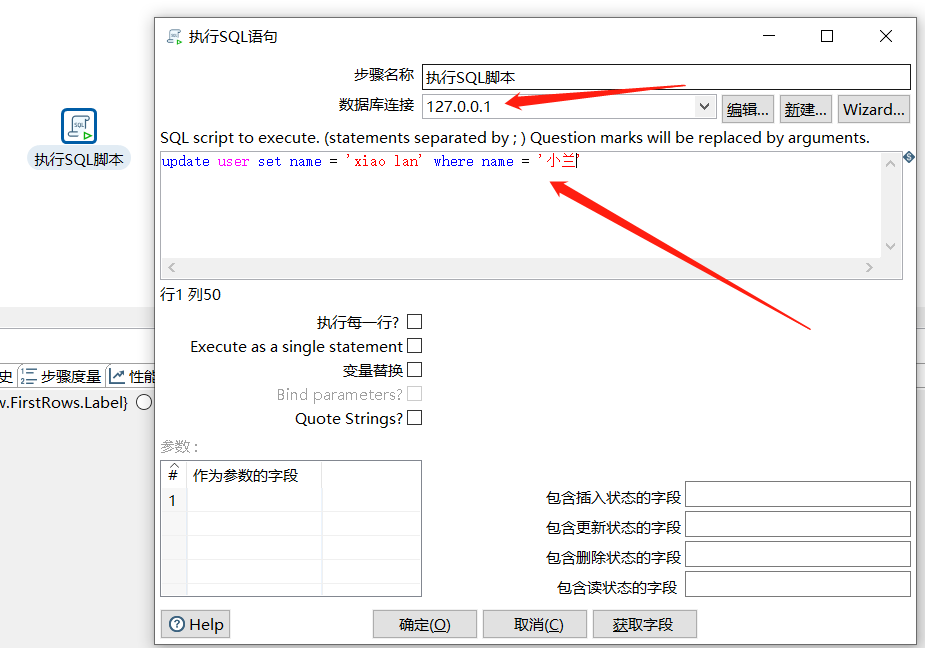
运行后查看结果:
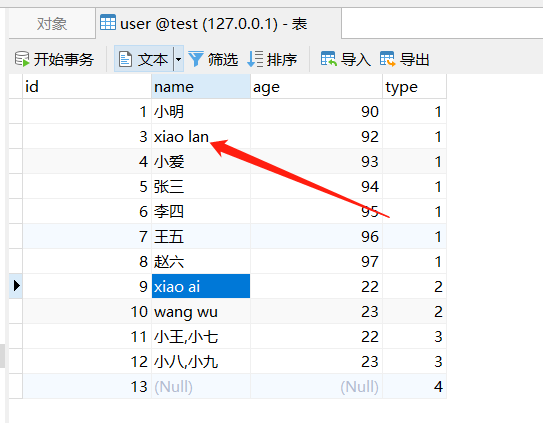
5.2 正则表达式
使用正则表达式实现复杂的匹配。
例如匹配 name 中带有 明 或 三 的:
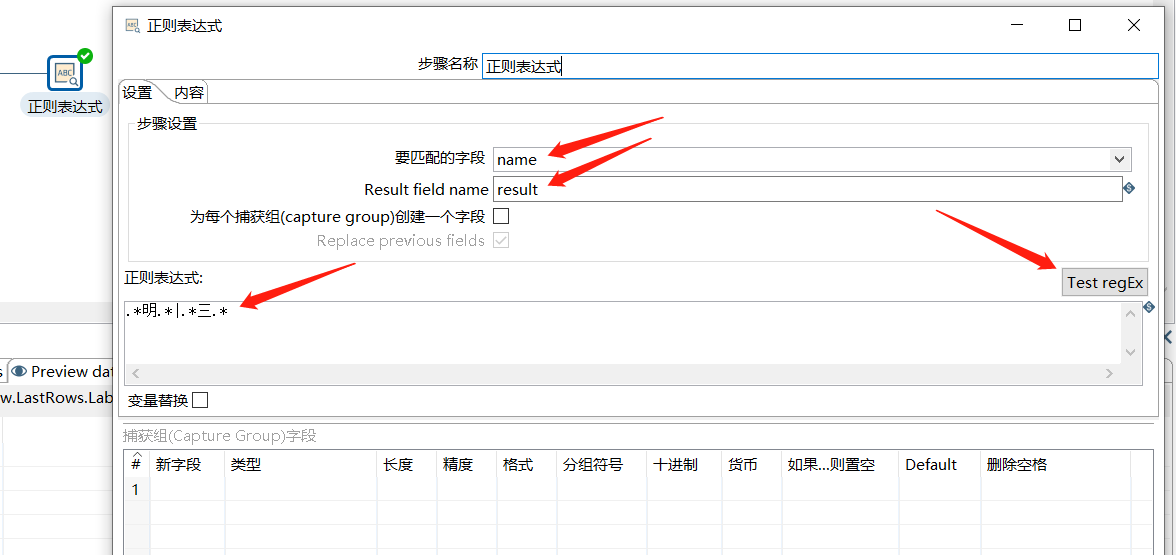
运行后查看结果: