PyCaret简介
随着ChatGPT和AI画图的大火,机器学习作为实现人工智能的底层技术被大众越来越多的认知,基于机器学习的产品也越来越多。传统的机器学习实现方法需要较强的编程能力和数据科学基础,这使得想零基础尝试机器学习变得非常困难。
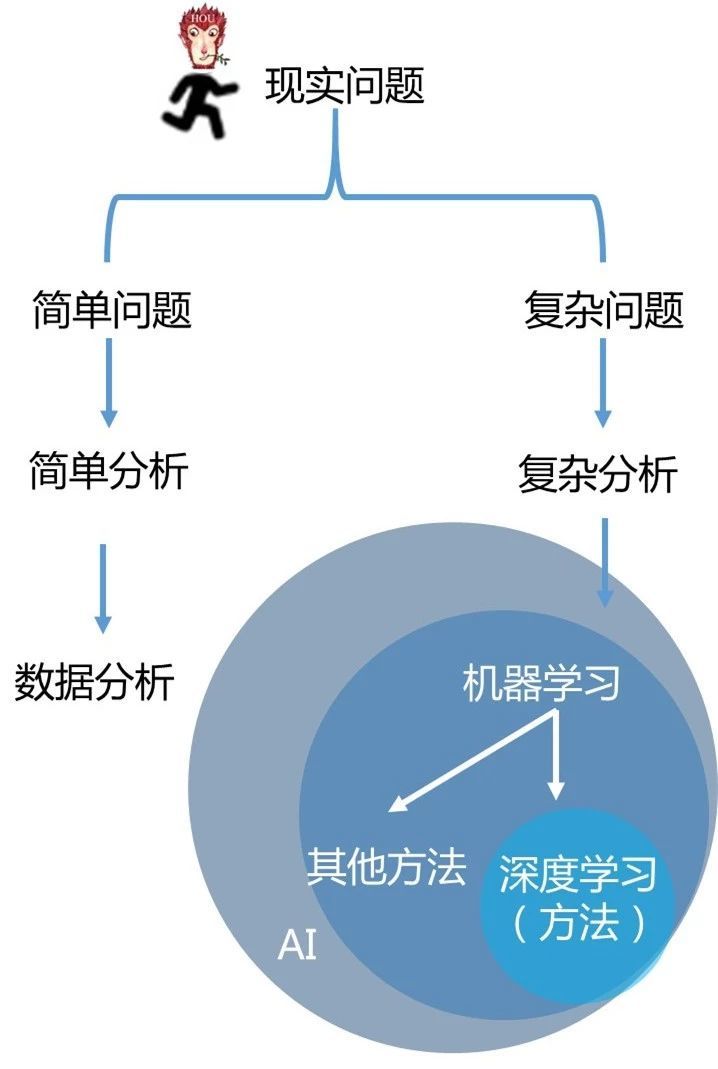
机器学习、深度学习和人工智能(AI)的关系
PyCaret 是 Python 中的开源低代码机器学习库,可自动执行机器学习工作流程。它是一种端到端的机器学习和模型管理工具,可以成倍地加快实验周期并提高您的工作效率。与其他开源机器学习库相比,PyCaret 是一个高度封装的低代码库,可以用几行代码代替数百行代码。这使得机器学习实验呈指数级快速和高效。
PyCaret的设计和简单性受到了公民数据科学家这一新兴角色的启发,这是Gartner首次使用的术语。公民数据科学家是超级用户,他们可以执行简单和适度复杂的分析任务,而这些任务以前需要更多的专业知识。经验丰富的数据科学家通常很难找到,而且雇佣成本也很高,但公民数据科学家可以成为缓解这一差距并解决商业环境中与数据相关的挑战的有效途径。

Pycaret的主要功能,多数可以以极少的代码自动化实现
Pycaret的特色
低代码量
与其他开源机器学习库相比,PyCaret是一个替代的低代码库,可以用很少的单词替换数百行代码。这使得机器学习实验能以指数级的速度和效率进行。PyCaret本质上是一个Python包装器,围绕着几个机器学习库和框架,如scikit learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray等等。除模型选择外,调参,数据预处理等等也可以通过同样的方式进行处理。
在常规的机器学习方法中,如果想要比较多个机器学习算法的准确率和耗时等信息,需要挨个进行调用或编写,然后人工进行对比,而在PyCaret中仅需一行代码即可完成。
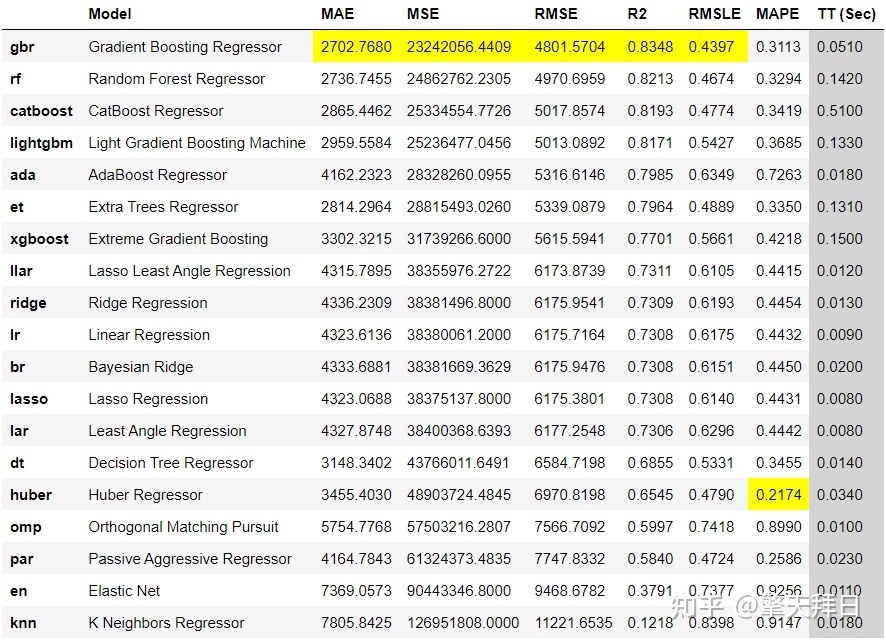
利用Pycaret一行代码测试大量机器学习算法和模型的准确率和耗时请看
跨环境使用
PyCaret 是 Python 中的部署就绪库,这意味着在 ML 实验中执行的所有步骤都可以使用可重现并保证生产的管道重现。管道可以保存为可跨环境传输的二进制文件格式。

Pycaret训练的模型可以保存为二进制管道
无缝衔接主流数据平台
PyCaret 及其机器学习功能与支持 Python 的环境无缝集成,例如 Microsoft Power BI、Tableau、Alteryx 和 KNIME 等。这为这些 BI 平台的用户提供了巨大的力量,他们现在可以将 PyCaret 集成到他们现有的工作流中,并轻松添加一层机器学习。
PyCaret适用人群
- 希望提高生产力的经验丰富的数据科学家。
- 喜欢低代码机器学习解决方案的公民数据科学家。
- 想要构建快速原型的数据科学专业人士。
- 数据科学和机器学习的学生和爱好者。
安装 PyCaret
准备工作
PyCaret在以下64位系统上得到测试和支持,因此,安装前需要先准备好环境支持。
1.系统环境:Windows7+/unbantu 16.04+
2.编程环境:Python3.6-3.8/Python 3.9 for Ubuntu only
最简安装
最简单安装方式是使用Python的pip包管理器安装PyCaret,只需要一行代码:
pip install pycaret虚拟环境安装
安装PyCaret是在PyCaret中构建第一个机器学习模型的第一步。由于PyCaret会自动安装所有硬依赖项,为了避免与其他软件包发生潜在冲突,强烈建议使用虚拟环境,例如conda环境。使用隔离环境,可以独立于以前安装的任何Python包安装特定版本的pycaret及其依赖项。
# 创建conda环境
conda create --name yourenvname python=3.8
# 激活上一行创建的环境
conda activate yourenvname
# 安装Pycaret
pip install pycaret
# 创建一个笔记本内核并调用虚拟环境
python -m ipykernel install --user --name yourenvname --display-name "display-name"PyCaret适用的问题
分类问题
分类问题指的是可以将具有不同特征的元素分类成组的一类的问题。其目标是预测离散的、无序的分类标签。一些常见的用例包括预测客户违约(是或不是),预测客户流失(客户将离开或留下),发现的疾病(预后积极或消极),花的类型等。
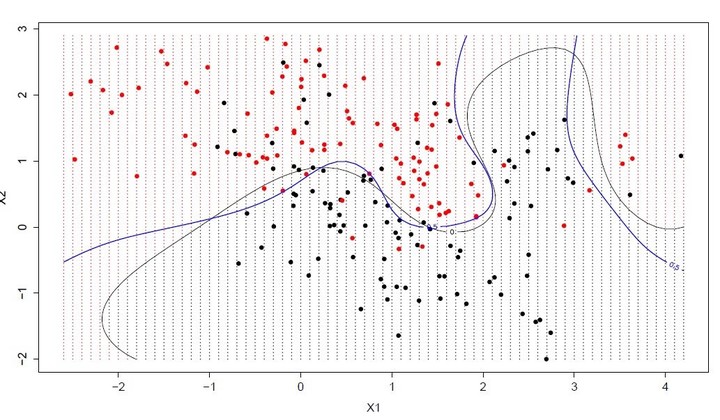
图中分界线尝试将红点和黑点分开,找到这种分界线是就是一种分类问题
回归问题
回归问题是指将用于估计因变量(通常称为 "结果变量",或 "目标")和一个或多个自变量(通常称为 "特征","预测因素",或 "协变量")之间的关系。回归的目的是预测连续值,如预测销售金额、预测数量、预测温度等。
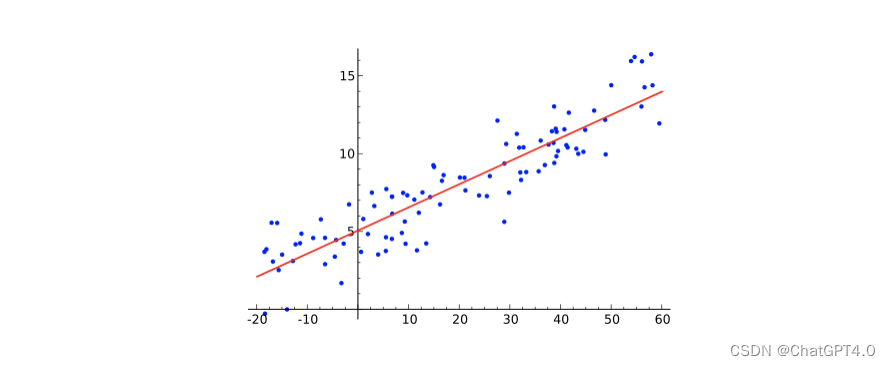
图中红线对点进行了回归,如何找到最适合的红线是一个回归问题
聚类问题
聚类问题是将一组对象分组,使同一组(也称为聚类)的对象比其他组的对象更相似。这包括找到共同表达的酶或者适合同一个环境的植物等。
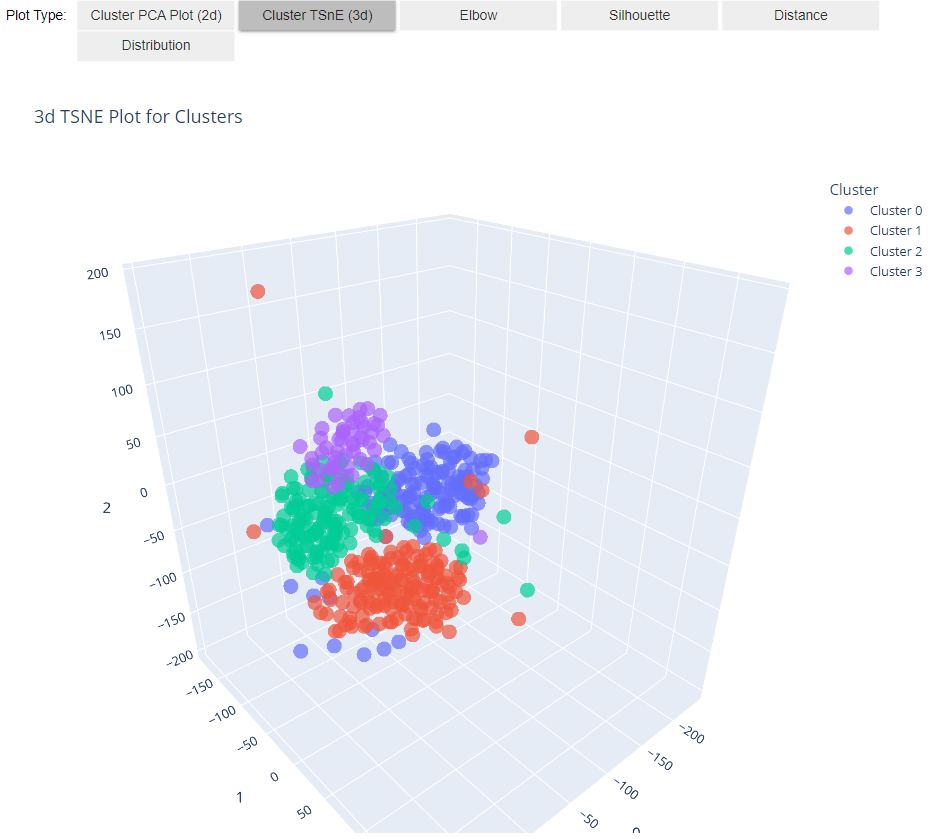
PyCaret解决聚类问题的可视化呈现,不同颜色代表不同聚类
异常检测问题
异常检测是一种用于识别罕见的项目、事件或观察结果的问题,这些项目、事件或观察结果与大多数数据有很大的不同,会引起人们的怀疑。通常情况下,异常项目将转化为某种问题,如银行欺诈、结构缺陷、医疗问题或某些少见的错误。
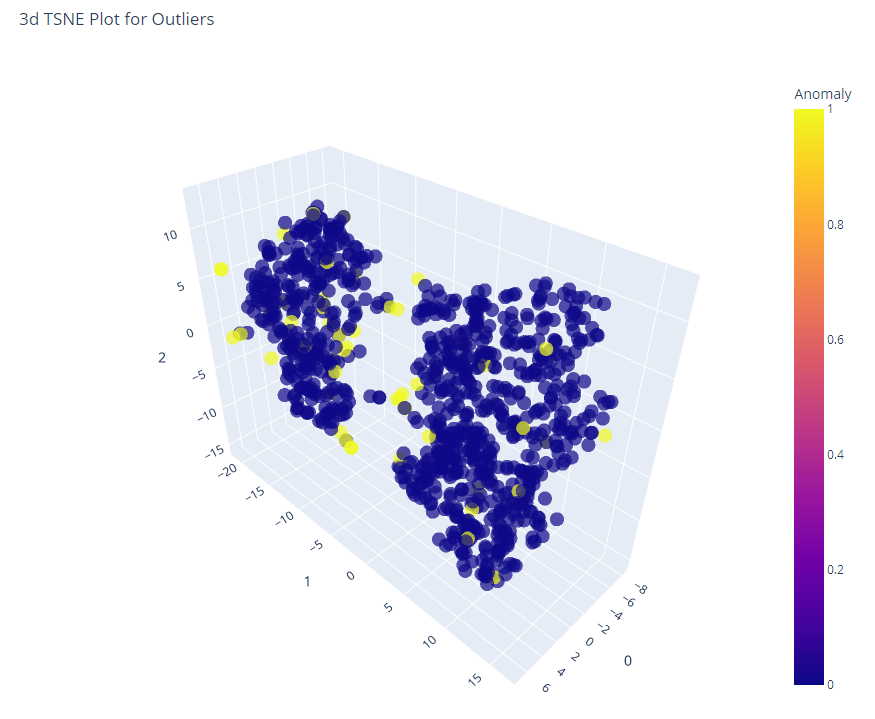
PyCaret解决异常检测问题的可视化呈现,黄色为异常数据
主题模型问题
自然语言处理中有一类用来分析文本数据,产生可以用于训练文本数据的主题模型。主题模型是一种统计模型,用于发现文档集合中的抽象主题。

词云就是这种主题模型的一种表现方式
关联规则挖掘问题
这类问题可以理解为发现数据集中变量之间的关系。它旨在使用一些不同的度量来识别在数据库中发现的强规则。
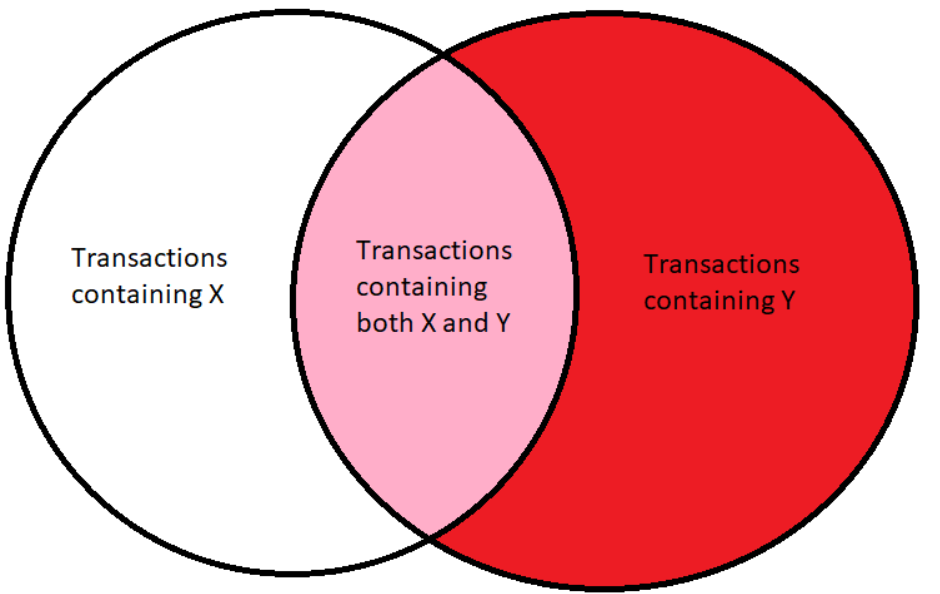
图中所示为数据之间的包含关系
时间序列预测
时间序列预测是基于按时间顺序索引(或列出或绘制)的一系列数据点,预测在后续时间的数据点,包括海洋潮汐的高度、太阳黑子的数量和道琼斯工业平均指数的每日收盘值的预测。

图中黑色为已有数据,蓝色为预测数据
一行代码实现多模型比较
比较不同模型在同一任务中的表现一直是机器学习中需要得到关注的问题,这一问题在PyCaret中可以通过一行代码得到解决,这可以大大加快实验机器学习模型的速度。
best = compare_models()
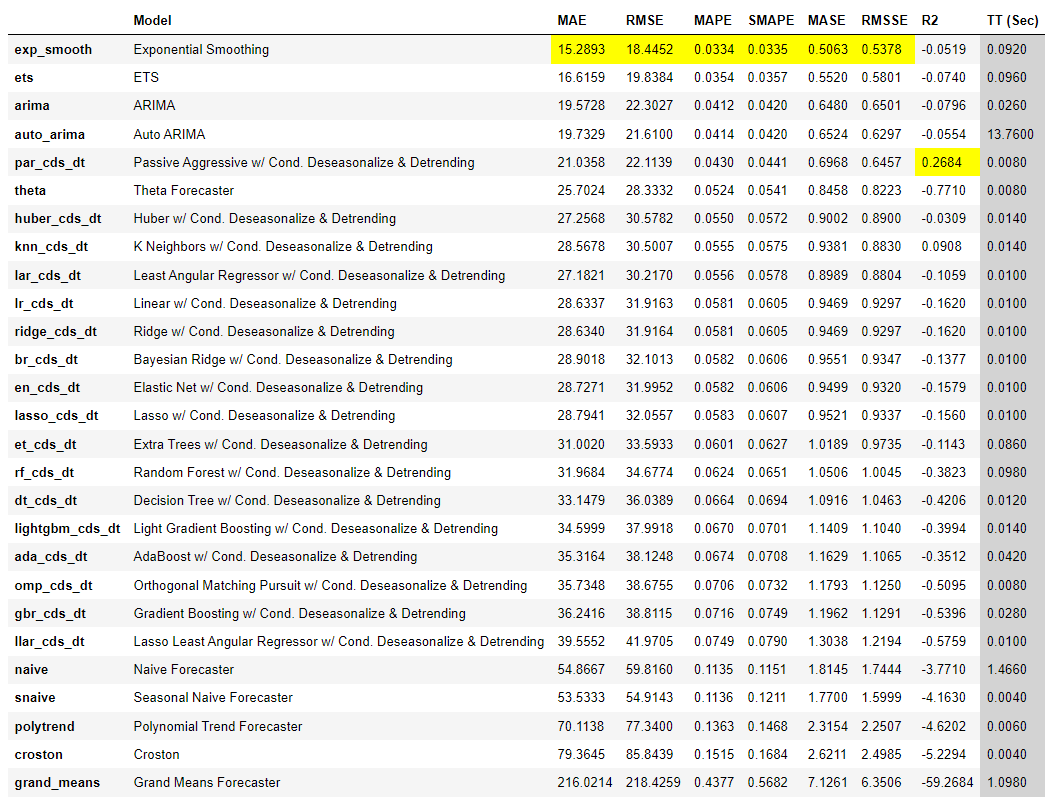
用多种指标描述不同模型在同一时间序列预测问题的表现
多种可视化方式分析模型和数据
在训练完成模型后,PyCaret集成了多种用于评价模型、数据和特征重要性的可视化方式,秩序一行代码即可实现。
evaluate_model(best)
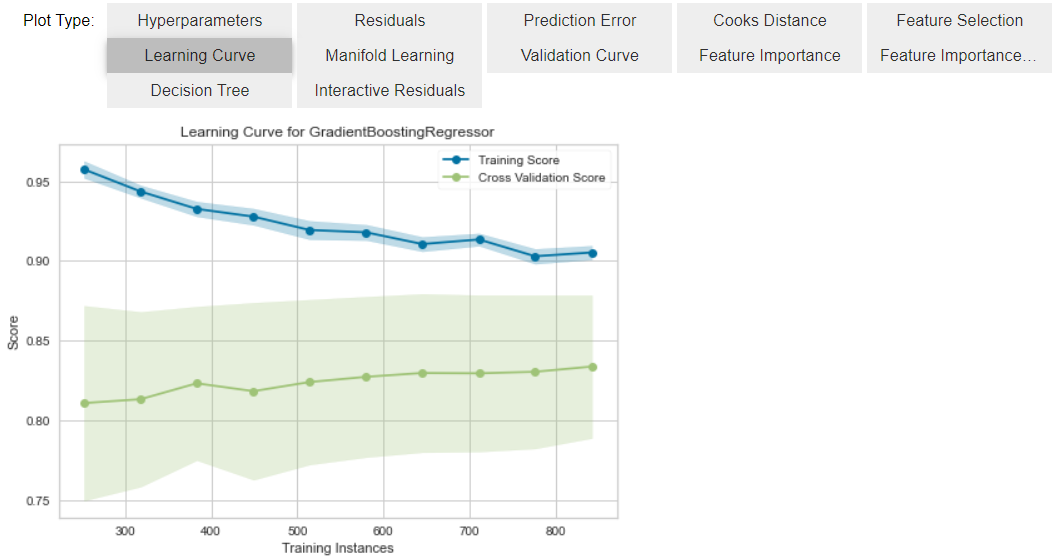
对回归模型、所用数据和特征重要性的可视化呈现
一行代码进行参数调优
对参数进行调优在机器学习模型训练中占有较大工作量,Pycaret可以选择不同迭代次数、参数搜索方式等进行参数优化,而且仅需一行代码即可实现。
tuned_dt = tune_model(dt, n_iter = 50)

参数调优结果
一行代码进行模型融合
blender = blend_models([lr, dt, knn])

模型融合结果
结语
PyCaret是我用过效率最高的机器学习工具,它在高度封装和高度自动化的情况下较好的保留了可配置性。我认为,PyCaret端到端的属性适合刚刚入门机器学习领域或者想要应用已有的机器学习模型和算法处理实际问题的人们。