强化学习泛化性 综述论文阅读
- 摘要
- 一、介绍
- 二、相关工作:强化学习子领域的survey
- 三、强化学习中的泛化的形式
- 3.1 监督学习中泛化性
- 3.2 强化学习泛化性背景
- 3.3 上下文马尔可夫决策过程
- 3.4 训练和测试上下文
- 3.6 应用实例
- 3.7 更可行泛化的其他假设
- 3.8 备注和讨论
- 4. 强化学习中的泛化基准
- 4.1 环境
- 4.1.1 泛化环境的分类
- 4.1.2 环境趋势
- 4.2 泛化评估协议
- 4.3 讨论
摘要
DRL泛化研究目的是将算法部署在新未知环境中仍然具有很好的效果,而不只是在训练环境有较好的效果。
泛化性的研究是在现实场景中实现DRL部署的重要环节。因为在现实世界中,环境将是多样的、动态的和不可预测的。
这篇文章的工作:1. 定义了强化学习泛化性的形式化定义。 2. 对现有的通用化基准及解决通用化问题的方法进行分类。3. 对该领域的现状进行批判性讨论和展望。
其他观点:1. 采用纯程序性内容生成方法进行基准设计不利于通用化的进展,建议快速在线适应和解决RL特定问题,作为未来通用化方法工作的一些领域。 2. 建议在未充分探索的问题设置中构建基准,例如离线RL泛化和奖励函数变化。
一、介绍
- 强化学习可应用于自动驾驶、算法控制、机器人等,但实现需要在真实环境中使用,而真实环境又是复杂变化的。因此,RL算法需要对环境的变化具有鲁棒性,并且在部署过程中能够转移和适应不可见的(但类似的)环境。
- 当前RL研究主要在Atari和MuJoCo等基准上进行,它们在完全相同的环境下评估政策,与现实场景不匹配(下图左栏)。这与监督学习完全不同,监督学习分为训练集与测试集属于不同分布。因此RL可能会严重过拟合,即使稍微调整环境算法也无法获得好的效果(如改变随机种子)。
- 研究侧重于生成其策略具有所需鲁棒性、传递和自适应特性的算法,挑战训练和测试将是相同的基本假设(下图中和右栏)。
- 本文研究范围:zero-shot策略转移问题。这要求将训练好的策略迁移到新的环境中不能进行额外的训练,因此域自适应和许多元RL方法的含义方法是不适用的。
- 文章结构:第2节简述相关工作;第3节介绍RL及泛化性背景;第4节描述RL中通用化的当前基准,同时讨论了环境(4.1)和评估协议(4.2);第5节对工作产生方法进行了分类和描述,以解决普遍化问题;第6节对当前领域进行批判性讨论和展望;第7节总结了调查中的主要收获。
- 文章贡献:
(1)提出了一种形式主义和术语描述RL泛化性问题。
(2) 提出了一个可用于测试泛化性的基准分类,讨论分为分类环境和评估协议。总结PCG方法的缺点:完全PCG环境限制了在该环境下进行的研究的精度,建议未来的环境应使用PCG和可控变化因素的组合。
(3)建议对现有方法进行分类,以解决各种泛化问题。进一步研究途径,包括快速在线适应、解决RL特定的泛化问题、新颖的架构、基于模型的RL和环境生成。
(4) 给出展望,建立基准将使离线RL通用化和奖励功能变化取得进展。指出了几个值得探索的不同设置和评估指标:调查上下文效率和进行连续RL设置都是未来工作的必要领域。
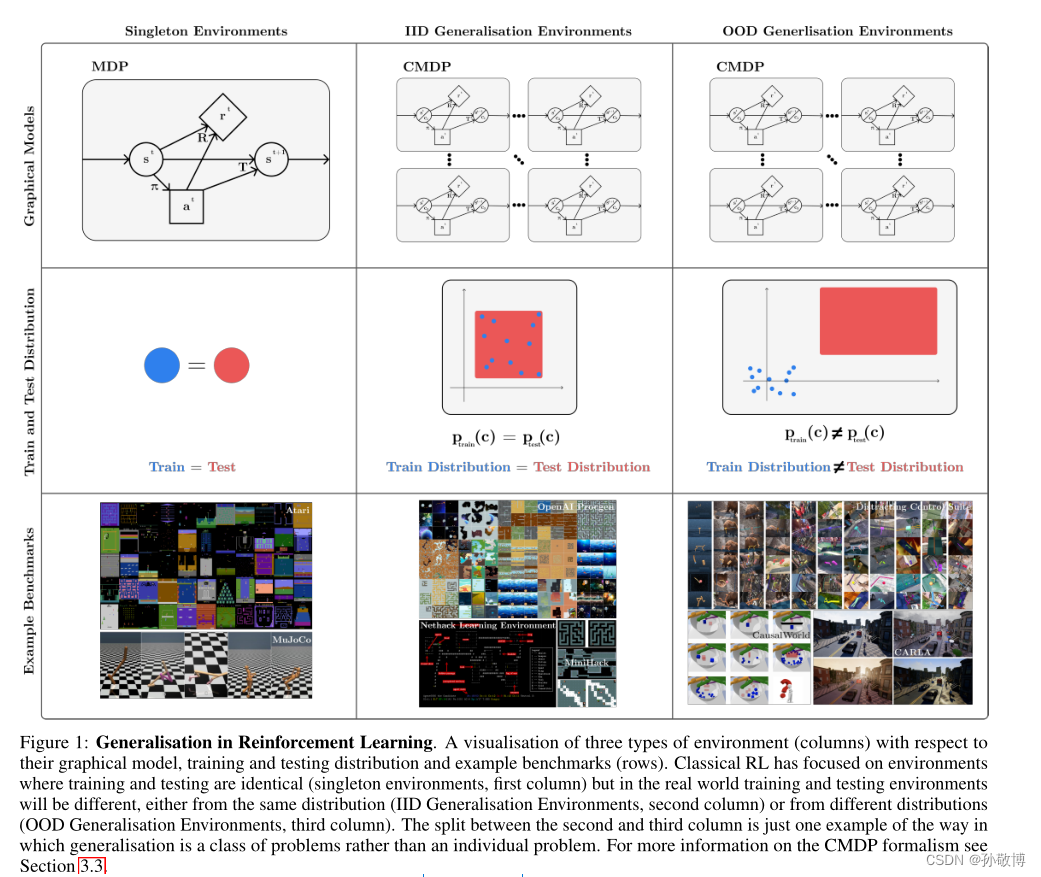
(图中可见,经典RL侧重于训练和测试相同的环境(单例环境,第一列),但在现实世界中,训练和测试环境将不同,要么来自相同的分布(IID泛化环境,第二列),要么来自不同的分布(OOD泛化环境,第三列))
二、相关工作:强化学习子领域的survey
- 以往的survey工作包括:
(1)持续强化学习(CRL):这与RL中的泛化密切相关,但未考虑zero-shot的特性。
(2)鲁棒RL(RRL):聚焦于解决环境模型中最坏情况的效果,是泛化性的一个子领域。
(3)sim-to-real:模拟到真实是泛化问题的具体实例,sim-to-real的一些方法依赖于来现实数据。
(4)RL迁移学习(TRL):TRL与泛化相关,都假设策略在不同环境中训练,但TRL侧重于额外训练,这里侧重于zero-shot。
(5)多任务深度RL
(6)RL中的探索
(7)RL中课程学习
三、强化学习中的泛化的形式
3.1 监督学习中泛化性
监督学习中,通常假设训练和测试数据集来自相同分布,其泛化性与测试效果相同。具有训练和测试数据Dtrain、Dtest和损失函数L的模型φ的监督学习中的广义差距定义为
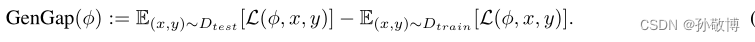
对于泛化性的五种概括:
(1) 系统性:通过系统地重组已知的部分和规则来概括
(2) 生产力:将预测扩展到超出训练数据长度的能力
(3) 替代性:通过用同义词替换组件的能力来概括,
(4).局部性:如果模型合成操作是局部的,而不是全局的
(5) 过度概括:如果模型关注异常或对异常具有鲁棒性
3.2 强化学习泛化性背景
- RL中的标准形式是马尔可夫决策过程(MDP),MDP由元组M=(S,a,R,T,p)组成。
- POMDP是部分可观测马尔可夫决策过程,POMDP由一个元组M=(S,A,O,R,T,φ,p)组成,其中o是观测函数,φ是状态到观测的转移函数。
3.3 上下文马尔可夫决策过程
- 讨论泛化性需要一种方法谈论一系列任务、环境或级别。如OpenAI的Procgen,标准协议是在200个级别的固定集合上训练策略,然后评估级别的完整分布的性能。
- 为正式化任务集合的概念,这里从上下文马尔可夫决策过程(CMDP)开始。这里状态变为 s = ( c , s ′ ) ∈ S C s=(c,s^{'}) \in S_{C} s=(c,s′)∈SC,其中 c c c是上下文信息, s ′ s^{'} s′是基础状态。其中上下文 c c c代表种子、ID或参数向量这些决定任务的信息。因此在一个episode里 c c c不会发生变化,在不同的episode中 c c c才不同。CMDP是任务或环境的全部集合,在Procgen中,每个游戏都是一个单独的CMDP。
- 这里通常假设智能体无法观察到上下文信息c,因此将CMDP看作可以观察到状态s的POMDP。其中观测转移函数为: ϕ ( s ′ , c ) = s ′ \phi (s^{'},c) = s^{'} ϕ(s′,c)=s′。
- 奖励函数、转移函数、初始状态分布和发射函数都将上下文作为输入,因此上下文决定了MDP。每个上下文MDP代表了一种任务的等级或类型。
- 一些MDP具有随机过渡或奖励功能,因此进行试验时需进行随机种子的设置,理论上讲这些种子可以被看作是上下文。但这里作者不认为它是上下文,这更紧密地映射到具有随机动力学的真实场景,在那里无法控制随机性。
3.4 训练和测试上下文
- 由于泛化性源自训练集和测试集的差异,因此需要指定一组训练和测试的上下文MDP(因为上下文决定MDP)。
- 划分训练集和测试集时,对于任意的CMDP: M = { S , A , R , T , C , p } M = \{S, A, R, T, C, p \} M={S,A,R,T,C,p}, 可以生成一个子集 C ′ ∈ C C^{'} \in C C′∈C, 通过上下文子集划分训练和测试集。(如设置procgen的种子)。
- 训练:
对于任何CMDP,其期望回报可设置为:
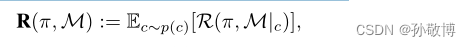
其中,R是策略奖励, p ( c ) p(c) p(c)是上下文分布。
在上下文训练集中训练,上下文测试集中测试,目标就是在测试集中的表现:
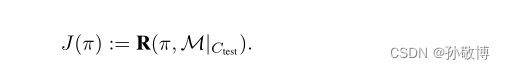
如procgen中,使用200关作为训练集,使用全分布作为测试集,实现zero-shot的迁移。 - 与监督学习一样,可以将训练和测试效果之间的差距作为通用性的衡量标准:
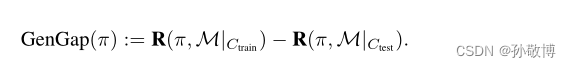
- 这种形式主义定义了一般化问题,每个问题都由CMDP、训练和测试上下文集的选择决定。
3.6 应用实例
- openai的procgen:游戏由不同层次组成,具有不同的布局或敌人数量,以及不同的视觉风格,不会影响动态或奖励功能。在这种环境中,上下文是一个随机种子,作为级别生成的输入。
- Sim-to-real:上下文集分为与模拟相对应的上下文和与现实相对应的上下文。环境决定了动力学、观察功能和状态空间。CMDP通常可以理解为两个CMDP的有效结合,一个用于现实,一个模拟,具有共享的行动空间和观察空间类型。领域随机化的动机是,在模拟中产生广泛的可能上下文将使上下文的测试分布更接近扩展的训练分布。
- 医疗保健:未来RL部署的一个有前途的领域,因为存在许多顺序决策问题。如,诊断和治疗单个患者的任务可以理解为CMDP,其中患者有效地指定了上下文:患者对测试和治疗的反应不同(动态变化),并可能提供不同的测量(状态变化)。上下文总是可以调节相关MDP函数以控制变化。假设某些部分的上下文(或关于上下文的某些信息)是可观察的,因为可以访问患者的病史和个人信息。
- 自动驾驶:在不同的地点(状态空间变化)、由于一天中的时间(观察功能变化)而在不同的天气和照明条件下以及在不同的路面上驾驶(动态变化)都是这些系统需要解决的问题。
3.7 更可行泛化的其他假设
仅使用CMDP结构假设难以给出泛化效果的理论保证。必须做出进一步的假设。这些是关于类型变化、训练和测试上下文集的分布或上下文集中的附加基础结构的假设。
- 训练和测试上下文集分布的假设
假设:
(1)尽管训练和测试上下文集不相同,但这两个集合的元素来自相同的基础分布,类似于监督学习中的iid数据假设。如 OpenAI Procgen的设置,其中训练上下文集是从种子的全分布中随机均匀采样的200个种子的集合,并且全分布被用作测试上下文集。
(2)许多RL泛化工作不假设训练和测试环境来自相同的分布。被称为领域泛化,这里将训练和测试环境称为不同的领域,这些领域可能相似,但不是来自相同的底层生成分布。典型的如sim-to-real。 - 结构的进一步形式化假设
假设:
(1)块MDP:假设在从潜在状态空间到给定观察空间的映射中存在块结构,或者存在由具有与给定MDP相同行为的较小状态空间描述的另一MDP。Du等人[39]使用这一假设来改善勘探边界,这取决于潜在状态空间的大小,而不是给定的观测空间。Zhang等人[40]开发了一种表示学习方法,该方法将相关特征与不相关特征区分开来,改善了对只有不相关特征变化的环境的泛化。
(2)因子MDP:可用于描述面向对象的环境或多智能体设置,其中状态空间可分解为独立的因素。
3.8 备注和讨论
- 泛化的度量
有两种明显的方法可以评估模型的泛化性能。一种是只看评估任务的绝对表现,另一种是看泛化差距。在监督学习中,不同算法的泛化能力通常通过评估任务的最终性能来评估。在RL中,我们更关心算法的泛化潜力,方法是将泛化与训练性能解耦,并使用泛化间隙进行评估。
但在如此广泛的类别中,目标甚至可能相互冲突。各种RL算法的泛化性能可能取决于其部署的环境类型,因此需要对部署时存在的挑战类型进行仔细分类,以正确评估泛化能力。 - 解决泛化问题的角度
为了提高测试性能,可以(1)提高训练时间性能,同时保持泛化间隙恒定,(2)减少泛化间隙,同时保持训练时间奖励恒定,或者(3)混合使用两种方法。在RL中,与泛化无关的工作采用第一种方法,RL中的泛化工作目标是(2)。 - Zero-shot策略转移动机
在这项工作中,专注于zero-shot的策略转移:策略从训练CMDP转移到测试CMDP,并且不允许在测试上下文中进行任何进一步的训练。
4. 强化学习中的泛化基准
本节给出了RL泛化的基准分类。基准任务是环境选择(CMDP,第4.1节)和适当的评估协议(训练和测试环境集,第4.2节)的组合。对基准进行分类后,作者指出纯PCG方法生成环境的局限性(第4.3节,通用化程序内容生成的缺点),并讨论了泛化问题中困难的范围。
4.1 环境
4.1.1 泛化环境的分类
-
表1中列出了RL中测试泛化的可用环境,并总结了每个环境的关键属性。这些环境都提供了一个非单例上下文集,可用于创建各种评估协议。选择一个特定的评估协议,然后产生一个基准。
-
Style:给定一个高级别描述
-
Contexts:描述了上下文集。有两种设计上下文集的方法,其区别在于是否可以看到上下文内容。
(1)第一种,叫做过程性内容生成(PCG),使用随机种子来在上下文MDP生成期间确定选择。是一个黑箱过程,只选择一个种子。
(2)第二种,叫做可控环境,对上下文MDP之间的变化因素提供了更直接的控制。上下文集通常是多因素空间,既包括连续空间又包括离散空间。
后面使用“PCG”表示使用种子作为输入的黑盒PCG,使用“可控”来指直接更改上下文MDP相关参数的环境,即白盒PCG。 -
Variation:描述了上下文MDP集合中的变化。可以是状态空间变化(、动态变化(过渡函数)、视觉变化(观察函数)或奖励函数变化。
-
分类列表:
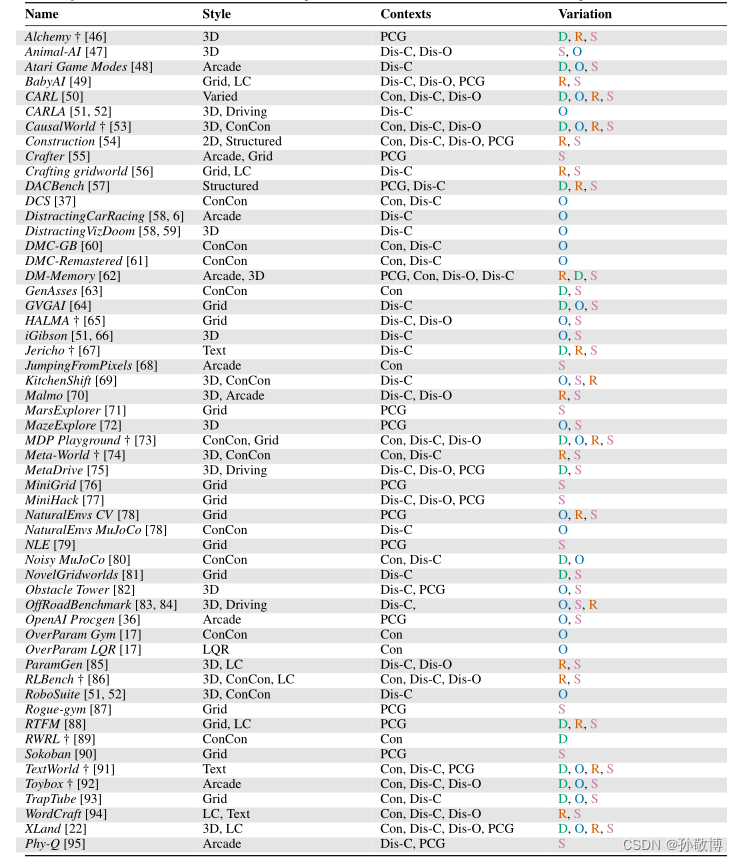
在上下文列中,PCG表示过程内容生成,Con表示连续,Dis-C表示离散基数,Dis-O表示离散序数。在变异栏中,S、D、O和R分别是状态、动态、观察或奖励函数变异。
4.1.2 环境趋势
- 环境中网格世界(14.25%)和连续控制(13.24%)受到关注,但街机风格和3D环境的基准已经确立。PCG在通用环境中大量使用,在21个(38%)环境中使用。许多环境将PCG组件与可控变化相结合。大多数环境在其上下文集合中有几种不同的变化因素。
- 在变化方面,状态变化最常见(42,76%),其次是观察(29,53%),然后是奖励(20,36%)和动态(19,35%)。
- 在基准集合中可以分类:PCG状态变化的网格环境(MiniGrid、BabyAI、Crafter、Rogue-gym、MarsExplorer、NLE、MiniHack),非PCG观察变化的连续控制环境(RoboSuite、DMC Remasted、DMC-GB、DCS、KitchenShift、NaturalEnvs、MuJoCo),以及可适用于zero-shot泛化的多任务连续控制基准(CausalWorld、RLBench、Meta-world)。
4.2 泛化评估协议
评估协议规定了训练和测试上下文集、训练时对训练集采样的限制以及训练环境中允许的样本数量。
-
PCG评估协议
PCG环境提供了三类评估协议,分别为
A:单个上下文训练,整个上下文集测试
B:一小组上下文训练,整个上下文集测试
C:完整上下文集训练,其中的一组上下文测试
对于A, 由于难度太大,目前没有实例。
对于B,可能会出现在训练集上过拟合而导致在测试集上效果不好的情况。该协议的示例包括OpenAI Procgen、RogueGym的两种模式,JumpingFromPixels和MarsExplorer的一些使用。
对于C,并没有明显地针对泛化问题,它的测试集来自训练集的一部分,但相对于原始RL的协议具有一定的泛化性。这里作者任务C应该是标准RL的评估协议,原来的评估协议只是一个特例。
A,B,C分别对应于下图的三列。

-
可控环境评估协议
主要为下图,考虑训练上下文,在其基础上进行内推分布测试、单个因子的外推测试和多个因子的外推测试。

4.3 讨论
- 非视觉泛化:非视觉类型的泛化应使用视觉简单的领域,如MiniHack[77]和NLE[79]。这些环境包含足够的复杂性,可以测试许多类型和非视觉概括的优势。有许多现实世界中的问题设置不需要视觉处理,例如系统控制和推荐系统。
- DeepMind控制套件变体:泛化基准的一个子类别是DeepMind Control Suite[99]变体的选择:DMC-Remastered, DMC-Generalisation Benchmark, Distracting Control Suite, Natural Environments [61, 60, 37, 78]。这些环境都关注视觉概括和样本效率,需要从像素学习连续的控制策略。其中Distracting
Control Suite是功能最全面的变体,因为它具有最广泛的变体,其中最难的组合是当前方法无法解决的。 - 无意的泛化基准:一些环境最初并不是泛化基准,但可以通过不同的评估协议来适应这种情况。包括CausalWorld, RWRL, RLBench, Alchemy, Meta-world等。建议在使用这些基准测试时明确使用哪种协议,并与之前方法的评估进行比较。使用标准方案有助于再现性。
- 泛化过程内容生成的缺点:PCG往往使用随机种子集,没有用于控制上下文MDP之间的变化的附加结构。
(1)PCG很有用,但纯PCG存在一些问题:这些环境支持的评估协议范围限于不同大小的训练上下文集,不对其特定因素进行解耦难以进行一般化。通常需要付出更多的努力才能将这些因素设置为特定的值,而不是仅显示生成级别的值。因此纯PCG无法对特定类型的通用化进行更具针对性的评估。
这意味着,虽然PCG是创建一组大型上下文MDP的有用工具,但纯基于PCG的环境有一个缺点:这些环境支持的评估协议范围限于不同大小的训练上下文集。如果不大力标记生成的水平或解开PCG以暴露捕获这些因素的潜在参数化,就不可能测量沿着特定变化因素的一般化。通常需要付出更多的努力才能将这些因素设置为特定的值,而不是仅显示生成级别的值。因此,PCG基准正在测试“通用”形式的通用化和RL优化,但无法对特定类型的通用化进行更具针对性的评估。这意味着在特定问题上取得研究进展是困难的,因为孤立地关注特定瓶颈是困难的。
一个有趣的折衷方案是,在几个环境中达成,即在程序上产生一些低水平的环境,但仍有许多变化因素在研究人员的控制下。例如,障碍塔[82]有程序生成的平面布局,但视觉特征(以及某种程度上的布局复杂性)可以控制。另一个例子是MiniHack[77],其中可以用丰富的描述语言从头开始指定整个MDP,如果需要,PCG可以填充任何组件。这两者都能实现更具针对性的实验类型。我们认为,这种PCG和可控环境的结合是设计未来环境的最佳方法;为了在环境(尤其是状态空间)中产生足够的多样性,需要使用PCG,如果控制足够精细,能够进行精确的科学实验,那么环境仍然有助于解开一般化的进展。