原文链接和代码链接A Self-Attentive model for Knowledge Tracing | Papers With Code
motivation:传统方法面临着处理稀疏数据时不能很好地泛化的问题。
本文提出了一种基于自注意力机制的知识追踪模型 Self Attentive Knowledge Tracing (SAKT)。其本质是用 Transformer 的 encoder 部分来做序列任务。具体从学生过去的活动中识别出与给定的KC相关的KC,并根据所选KC相对较少的KC预测他/她的掌握情况。由于预测是基于相对较少的过去活动,它比基于RNN的方法更好地处理数据稀疏性问题。
模型结构

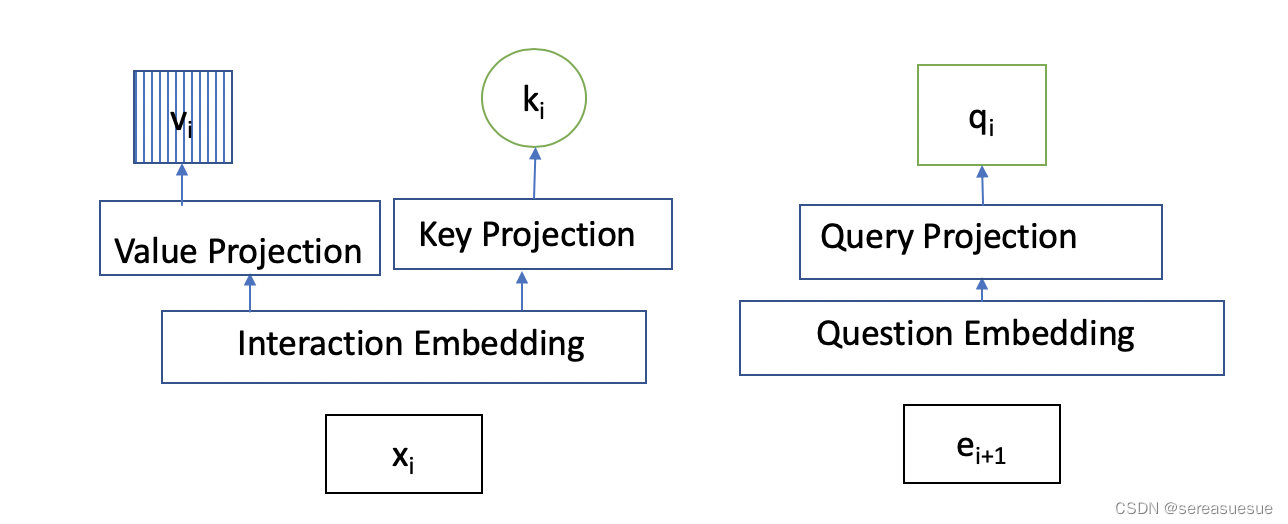

输入编码
交互信息 通过公式
转变成一个数字,总量为 2E。
我们 用Interaction embedding matrix 训练一个交互嵌入矩阵,
被用来为序列中的每个元素
Exercise 编码 利用 exercise embedding matrix训练练习嵌入矩阵,,每行代表一个题目ei
Position Encoding
自动学习,n 是序列长度。
最终编码层的输出如下

注意力机制
Self-attention layer采用scaled dotproduct attention mechanism。
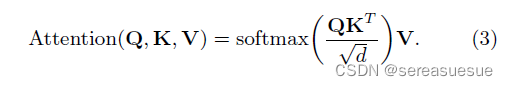
Self-attention的query、key和value分别为:

Causality:因果关系也是mask 避免未来交互对现在的
Feed Forward layer
用一个简单的前向传播网络将self-attention的输出进行前向传播。
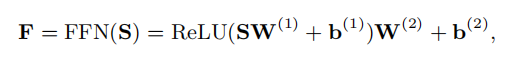
Prediction layer
self-attention的输出经过前向传播后得到矩阵F,预测层是一个全连接层,最后经过sigmod激活函数,输出每个question的概率
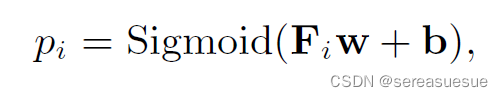
模型的目标是预测用户答题的对错情况,利用cross entropy loss计算(y_true, y_pred)

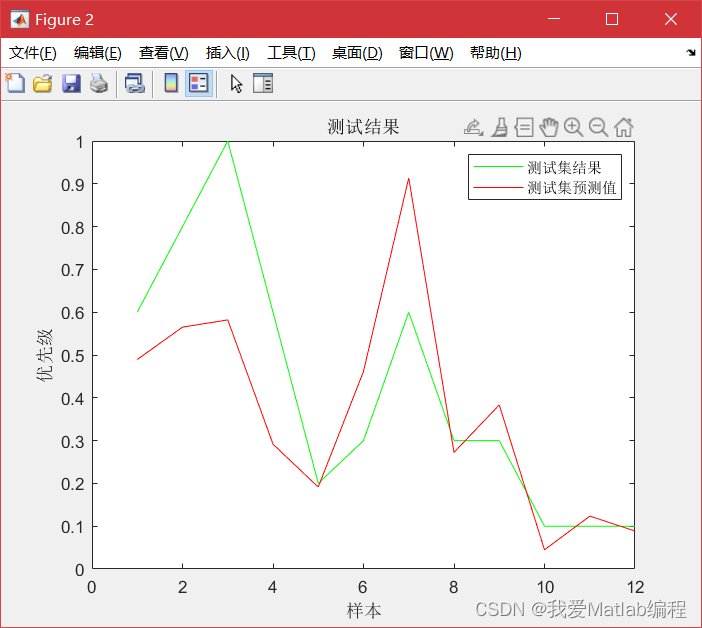
实验
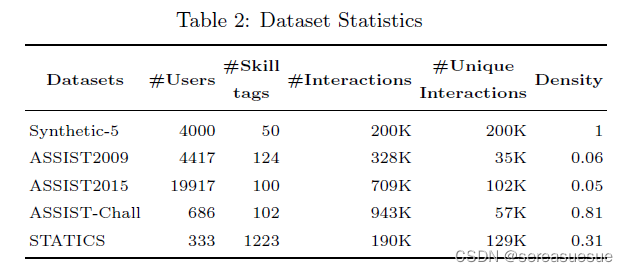
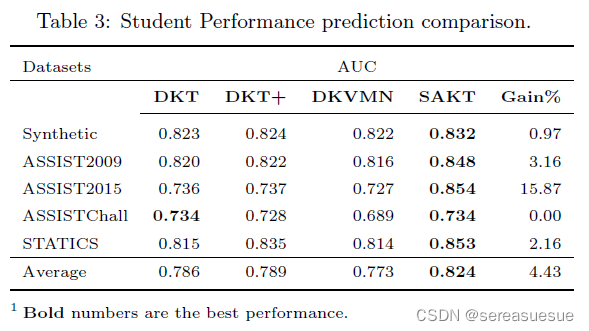





![[附源码]计算机毕业设计springboot高校后勤保障系统](https://img-blog.csdnimg.cn/8d98563acf254a23b984c55c23d8b7e2.png)
![[附源码]计算机毕业设计springboot个性化名片网站](https://img-blog.csdnimg.cn/17a78f98309940788adcd1b8668104dc.png)