文章目录
- 前言
- 一、数据预处理
- 二、SVM的调参策略
- 三、SVM调参演示
- 总结
前言
支持向量机(SVM)建模。
一、数据预处理
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('X disease code fs.csv')
X = dataset.iloc[:, 1:14].values
Y = dataset.iloc[:, 0].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.30, random_state = 666)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
二、SVM的调参策略
先复习一下参数(传送门),需要调整的参数有:
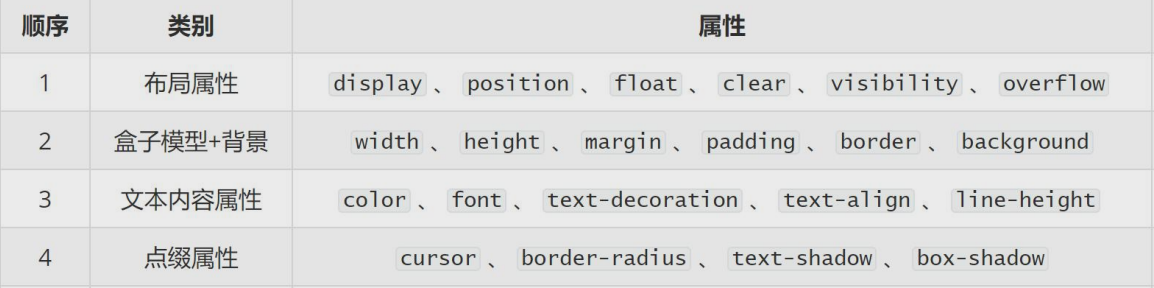
① kernel:{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’},默认为’rbf’。使用的核函数,必须是“linear”,“poly”,“rbf”,“sigmoid”,“precomputed”或者“callable”中的一个。
② c:浮点数,默认为1.0。正则化参数。正则化的强度与C成反比。必须严格为正。一般可以选择为:10^t , t=[- 4,4]就是0.0001 到10000。
③ gamma:核系数为‘rbf’,‘poly’和‘sigmoid’才可以设置。可选择下面几个数的倒数:0.1、0.2、0.4、0.6、0.8、1.6、3.2、6.4、12.8。
④ degree:整数,默认3。多项式核函数的次数(’ poly ')。将会被其他内核忽略。。
三、SVM调参演示
(A)先默认参数走一波:
from sklearn.svm import SVC
classifier = SVC(random_state = 0, probability=True)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
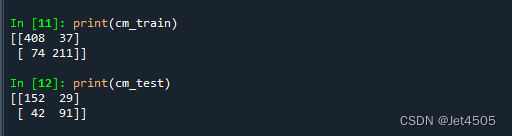
print(cm_train)
print(cm_test)
俗话说廋死的骆驼比马大,SVM厉害哦:

调整一下参数,看看能否逆袭那几个集成模型,我们按照内核来分别调整:
(B)kernel=‘rbf’,只需要调gamma:
from sklearn.svm import SVC
param_grid=[{
'gamma':[10, 5, 2.5, 1.5, 1.25, 0.625, 0.3125, 0.15, 0.05, 0.025, 0.0125],
},
]
boost = SVC(kernel='rbf', random_state = 0, probability=True)
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, n_jobs = -1, verbose = 1, cv=10)
grid_search.fit(X_train, y_train)
classifier = grid_search.best_estimator_
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
print(cm_train)
print(cm_test)
看结果,还不错:
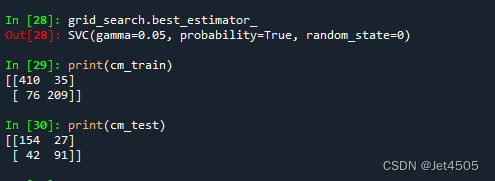

(C)kernel=‘linear’,没参数:
from sklearn.svm import SVC
classifier = SVC(kernel='linear', random_state = 0, probability=True)
看结果,也还不错:
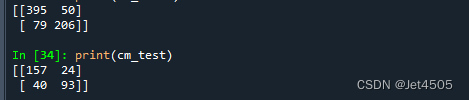
(D)kernel=‘sigmoid’,调整参数C(大写的C)和gamma:
from sklearn.svm import SVC
param_grid=[{
'gamma':[1,2,3,4,5,6,7,8,9,10],
'C':[0.0001,0.001,0.01,0.1,1,10,100,1000,10000],
},
]
boost = SVC(kernel='sigmoid', random_state = 0, probability=True)
结果,稍微差一点:
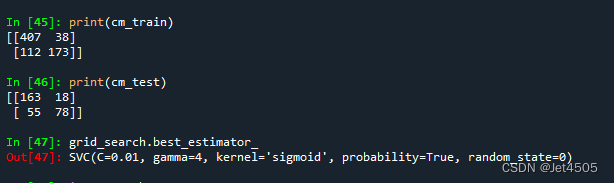

最优模型:
SVC(C=0.01, gamma=4, kernel=‘sigmoid’, probability=True, random_state=0)
(E)kernel=‘poly’,调整参数C(大写的C)、gamma和d:
多说一句,如何看每一个核有哪些参数:
from sklearn.svm import SVC
classifier = SVC(kernel='poly', random_state = 0, probability=True)
classifier.get_params().keys()
然后就输出kernel='poly’对应的所有参数:
dict_keys(['C', 'break_ties', 'cache_size', 'class_weight', 'coef0', 'decision_function_shape', 'degree', 'gamma', 'kernel', 'max_iter', 'probability', 'random_state', 'shrinking', 'tol', 'verbose'])
(a)先调整参数C(大写的C)、gamma:
from sklearn.svm import SVC
param_grid=[{
'gamma':[1,2,3,4,5,6,7,8,9,10],
'C':[0.0001,0.001,0.01,0.1,1,10,100,1000,10000],
},
]
boost = SVC(kernel='poly', random_state = 0, probability=True)
看结果:
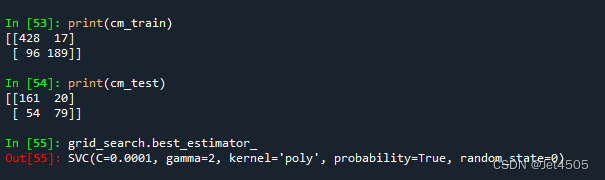
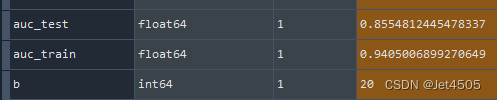
(b)再调整degree:
from sklearn.svm import SVC
param_grid=[{
"degree":[1,2,3,4,5,6,7,8,9,10],
},
]
boost = SVC(C=0.0001, gamma=2, kernel='poly', probability=True, random_state=0)
最终,degree还是3。
总结
综合来看,可能还是rbf核还有liner核的性能好一些。SVM还是厉害哦,至少在这个数据集,调参容易快捷,性能也到位。