YOLO V3
论文链接:YOLOv3: An Incremental Improvement
主要改进
- Anchor: 9个大小的anchor,每个尺度分配3个anchor。
- Backbone改为Darknet-53, 引入了残差模块。
- 引入了FPN,可以进行多个尺度的训练,同时对于小目标的检测有了一定的提升 (因为有3个不同大小的feature map 用来做检测)。
- Loss function的改进。
Network structure improvement
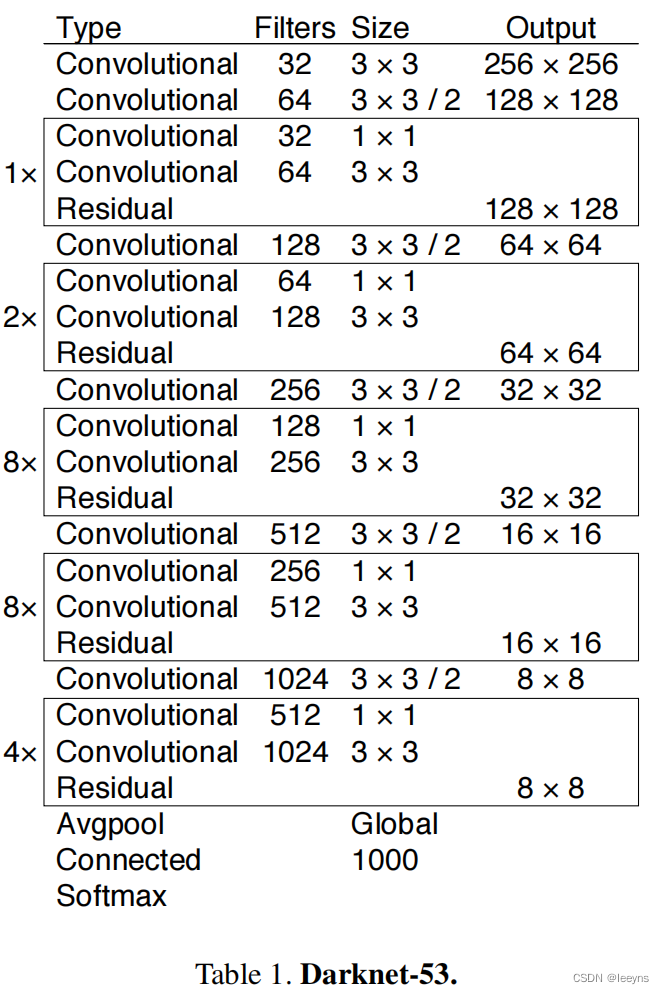
Backbone: Darknet-53
分别要下采样 32, 16, 8。因此输入的图片尺度一定要是32的倍数。改进点在于引进了残差模块。
FPN-多尺度学习
论文链接: Feature Pyramid Networks for Object Detection
Backbone是一个全卷积的网路结构,不含有全连接层,所以可以适用于各种不同尺度的输入大小。
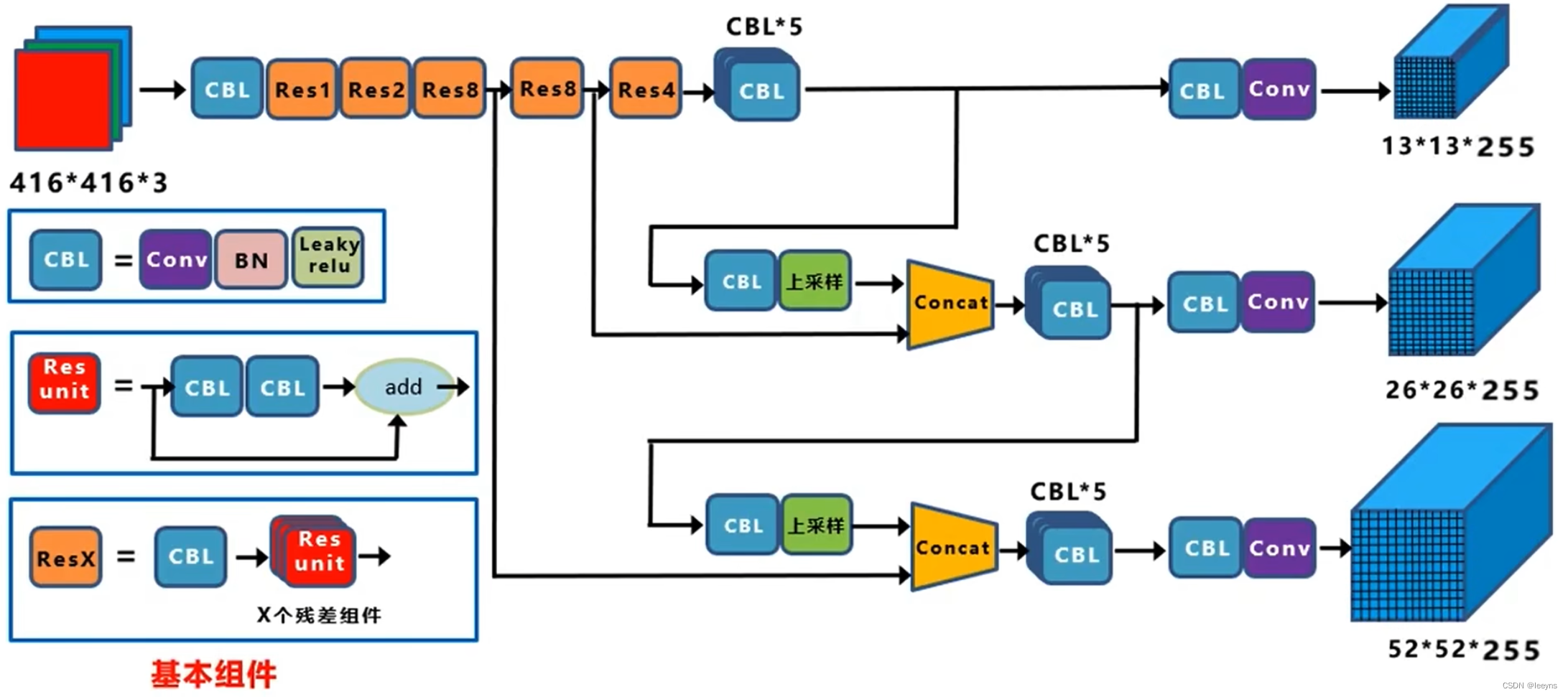
多尺度的含义:
- 3个尺度的feature map 来预测大目标和小目标。
- 通过上采样的方法将深层的特征与浅层的特征相融合。
- 比如,52×52的特征是由darknet浅层的细粒度像素级别的特征和深层的语义全局的特征的融合。
Loss Function
预测框分为三种:
- 正样本: 与GT的IOU最大
- 负样本: 与GT的IOU < 0.5
- 忽略样本:与GT的IOU > 0.5 但不是最大的。
忽略样本不参与loss的计算。
正负样本
- YOLO v3 只选取与groud truth的IOU最大的预测框进行拟合。而前面两个版本只是按照置信度标签及IOU值进行拟合。
- 区别于前面版本的YOLO,置信度标签 (objectness score)是预测框和ground truth的IOU值, YOLO v3 对于正样本的置信度标签直接设为1。这样的好处在于,如果是用IOU值作为置信度标签,对于一些IOU值较低的样本不能很好的学习,同时对于小目标IOU对于像素的偏移很敏感。
Loss Function
- 正样本对于分类和定位学习产生贡献,而负样本只对置信度学习产生贡献。
- 多标签范式:不再使用softmax来进行分类(即假设所有的类别都是互斥的,同一个框只可能属于一个类)。而使用对于每个类别都进行二分类任务,这样的好处在于对于同一个框可能可以存在不同的标签 (e.g. 学生、人).
在YOLOv3中,Loss分为三个部分:
- 一个是xywh部分带来的误差,也就是bbox带来的loss
- 一个是置信度带来的误差,也就是obj带来的loss
- 最后一个是类别带来的误差, 也就是class带来的loss
在代码中分别对应lbox, lobj, Icls,yolov3中使用的loss公式如下:
l b o x = λ coord ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j ( 2 − w i × h i ) [ ( x i − x i ^ ) 2 + ( y i − y i ^ ) 2 + ( w i − w ^ i ) 2 + ( h i − h i ^ ) 2 ] l c l s = λ class ∑ i = 0 S 2 ∑ j = 0 B 1 i , j obj ∑ c ∈ classes p i ( c ) log ( p ^ i ( c ) ) l o b j = λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i , j n o o b j ( c i − c ^ i ) 2 + λ o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j ( c i − c ^ i ) 2 l o s s = l b o x + l o b j + l c l s \begin{aligned} l b o x &=\lambda_{\text {coord }} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} 1_{i, j}^{o b j}\left(2-w_{i} \times h_{i}\right)\left[\left(x_{i}-\hat{x_{i}}\right)^{2}+\left(y_{i}-\hat{y_{i}}\right)^{2}+\left(w_{i}-\hat{w}_{i}\right)^{2}+\left(h_{i}-\hat{h_{i}}\right)^{2}\right] \\ l c l s &=\lambda_{\text {class }} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} 1_{i, j}^{\text {obj }} \sum_{c \in \text { classes }} p_{i}(c) \log \left(\hat{p}_{i}(c)\right) \\ l o b j &=\lambda_{\text {noobj }} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} 1_{i, j}^{n o o b j}\left(c_{i}-\hat{c}_{i}\right)^{2}+\lambda_{o b j} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} 1_{i, j}^{o b j}\left(c_{i}-\hat{c}_{i}\right)^{2} \\ l o s s &=l b o x+l o b j+l c l s \end{aligned} lboxlclslobjloss=λcoord i=0∑S2j=0∑B1i,jobj(2−wi×hi)[(xi−xi^)2+(yi−yi^)2+(wi−w^i)2+(hi−hi^)2]=λclass i=0∑S2j=0∑B1i,jobj c∈ classes ∑pi(c)log(p^i(c))=λnoobj i=0∑S2j=0∑B1i,jnoobj(ci−c^i)2+λobji=0∑S2j=0∑B1i,jobj(ci−c^i)2=lbox+lobj+lcls
其中:
S S S: 代表grid size
B B B: box
1 i , j o b j 1_{i, j}^{o b j} 1i,jobj : 如果在i,j 处的box有目标,其值为 1 ,否则为 0
1 i , j noobj 1_{i, j}^{\text {noobj }} 1i,jnoobj : 如果在i,j 处的box没有目标,其值为 1 ,否则为 0
Focal Loss
为什么YOLO v3使用focal loss效果不好?
Focal loss解决单阶段目标检测,正负样本不均衡,有用的负样本较少的问题。相当于挖掘负样本信息。而YOLO v3对于负样本的IOU阈值设置为0.5过高,因此负样本中其实存在一些疑似正样本的样本,对于这些样本,focal loss基于过高的noise权重会导致效果不好。