Spring 中的一些顺序问题
Spring 中的顺序问题并不是不重要,比如多个 BeanFactoryPostProcessor如何知道先执行哪一个;为什么自定义的 Bean 可以覆盖默认的自动装配的 Bean;AOP 拦截器链中拦截器的顺序是如何确定的等等问题。
相信看完这篇文档你应该能够对 Spring 的顺序问题有一些理解!
结论:总体上是无序的,但局部是有顺序的
1、有特殊接口或注解,就用它的顺序
特殊接口或注解就是:PriorityOrdered 接口、Ordered 接口、@Priority 注解、@Order 注解
2、没有,就用 beanDefinitionNames 顺序
那么什么决定了 beanDefinitionNames 的顺序呢???在下文中有说明
下面会列举一些 Spring 中的一些常见的顺序代码来分析
举例 1:Spring 注册非懒加载的的 Bean
// DefaultListableBeanFactory.class
public void preInstantiateSingletons() throws BeansException {
// <1> 收集beanDefinitionNames集合
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
for (String beanName : beanNames) {
// <2> 依次注册 Bean
getBean(beanName);
}
}
<1>处,收集 BeanDefinition 集合<2>处,实例化的顺序总体上是跟注册的顺序一致,但是实例化过程中处理属性依赖、构造器参数依赖等等依赖时,会先对依赖的 Bean 进行实例化!
举例 2:Spring 处理 BeanFactoryPostProcessor 接口
// PostProcessorRegistrationDelegate.class
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// <1> 收集BeanDefinitionRegistryPostProcessor集合
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
// <2> 优先处理 PriorityOrdered 接口
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
processedBeans.add(ppName);
}
}
// <3> 再处理 Ordered 接口的
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
}
}
// <4> 最后处理不是这 2 个接口的
}
<1>处,收集 BeanDefinitionRegistryPostProcessor 集合,但是是根据注册的顺序(即 beanDefinitionNames )收集的<2>处,优先处理 PriorityOrdered 接口<3>处,再处理 Ordered 接口的<4>处,最后处理不是这 2 个接口的
举例 3:AnnotationAwareOrderComparator 注解排序比较
作用:该比较器的作用是对标注了注解的内容进行排序,@Priority 优先 @Order,同注解要看 value 大小
在 Spring 中几乎所有需要用到比较的地方都会使用该注解比较器,如:
- 在实例化 ApplicationContextInitializer 接口时,代码及注释如下:
// 代码位置:AbstractContextLoader.class
private void invokeApplicationContextInitializers(ConfigurableApplicationContext context,
MergedContextConfiguration mergedConfig) {
... ...略
// <1> 对 initializerInstances 排序
AnnotationAwareOrderComparator.sort(initializerInstances);
for (ApplicationContextInitializer<ConfigurableApplicationContext> initializer : initializerInstances) {
// <2> 比较后挨个实例化
initializer.initialize(context);
}
}
- loadFactories 方法从配置中加载和实例化指定类型的类,代码及注释如下:
// 代码位置:SpringFactoriesLoader.class
// 功能:加载配置中的 factoryClass 类型的定义
public static <T> List<T> loadFactories(Class<T> factoryClass, @Nullable ClassLoader classLoader) {
// <1> 加载factoryClass 类型的列表
List<String> factoryNames = loadFactoryNames(factoryClass, classLoaderToUse);
List<T> result = new ArrayList<>(factoryNames.size());
for (String factoryName : factoryNames) {
// <2> 逐个实例化
result.add(instantiateFactory(factoryName, factoryClass, classLoaderToUse));
}
// <3> 排序
AnnotationAwareOrderComparator.sort(result);
return result;
}
- AOP 进行排序时,代码及注释如下:
// 代码位置:AbstractAdvisorAutoProxyCreator.class
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
// <1> 查找候选的 Advisor
List<Advisor> candidateAdvisors = findCandidateAdvisors();
// <2> 适配当前 beanClass 的 Advisor
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
// <3> 对 Advisor 排序
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
什么决定了 beanDefinitionNames 的顺序
需要了解的背景知识
1、Spring 的启动流程、Spring Boot 的启动流程
2、Spring Boot 自动装配原理
3、BeanFactoryPostProcessor 后置处理器是如何工作的,特别的重点掌握
ConfigurationClassPostProcessor
注册过程简单分析过程
- 因为 beanDefinitionNames 属性只能通过如下代码添加(有且仅有这一处 add 方法)
// 代码位置:DefaultListableBeanFactory.class
private volatile List<String> beanDefinitionNames = new ArrayList<>(256);
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
// 注册
this.beanDefinitionNames.add(beanName);
}
所以该属性的顺序主要与 this.registry.registerBeanDefinition 方法的调用相关
- ConfigurationClassPostProcessor 简单分析
调用容器registry来注册 BeanDefinition 的代码省略如下:
// 代码位置:ConfigurationClassPostProcessor.class
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
do {
// <1> 解析 candidates
parser.parse(candidates);
// <2> 获取【有序的】配置类集合
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
// <3> 处理配置类
this.reader.loadBeanDefinitions(configClasses);
}
while (!candidates.isEmpty());
}
<1>处,最开始一般 candidates 只有一个类就是@SpringApplication注解标注的类;然后在parse方法内部经历了各种各种递归调用处理完所有的配置类<2>处,获取parse阶段解析好的所有配置类<3>处,处理【有序的配置类】的注册,注册到beanDefinitionNames属性中
基于以上的简单分析给出如下结论
注册顺序的结论
以以下代码举例来说明 beanDefinitionNames 的注册顺序
@SpringBootApplication
@EnableCaching
@EnableTransactionManagement
@MapperScan(basePackages = "cn.iocoder.springboot.lab21.cache.mapper")
public class Application {
public static void main(String[] args) {
// 先处理 run 方法中传入的"配置类",即 Application 类
SpringApplication.run(Application.class);
}
}
- Application 优先级最高
因为一般只有唯一一个 candidates 类,即启动类 Application,它是配置类 Configuration 注册的入口
-
其次是 Application 类所在的包
-
处理各种
ImportSelector导入的类先处理 @EnableCaching 注解、再处理 @EnableTransactionManagement 注解、再处理 @MapperScan 注解
-
最后是自动装配的类
备注:
1、排序在前面的 Configuration 类会先被注册
2、Configuration 的顺序是可能控制的,如可通过 @AutoConfigureBefore、@AutoConfigureAfter、@AutoConfigureOrder等方式
解释一些顺序相关的问题
因为有了上面的结论,我们就可以尝试解决一些顺序相关的问题
问题 1:我们自定义的 Bean 存在时,不会加载默认的 Bean,只有我们自定义 Bean 不存在时才会加载默认的 Bean
答案:按照上面的注册顺序,先扫描我们自定义的包,所以我们自定义的 Bean 先被注册;而在自动装配时可能使用了@ConditionalOnBean等条件注解,从而导致条件不满足,就不再注册默认的 Bean
问题 2:注册的顺序影响大吗
答案:
1、有很大影响,除了标注或实现特殊注解或接口的类没有影响外,其他类都会受到一定的影响
2、很难全面把握 Spring Boot 自动装配的顺序,这也是导致 Spring Boot 比较晦涩难懂的一方面
留下一个疑问供各位看官答疑
问题 :如下@EnableCaching注解、@EnableTransactionManagement的先后顺序对 2 种拦截器的顺序有影响???
方式 1:
@SpringBootApplication
@EnableTransactionManagement
@EnableCaching
@MapperScan(basePackages = "cn.iocoder.springboot.lab21.cache.mapper")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
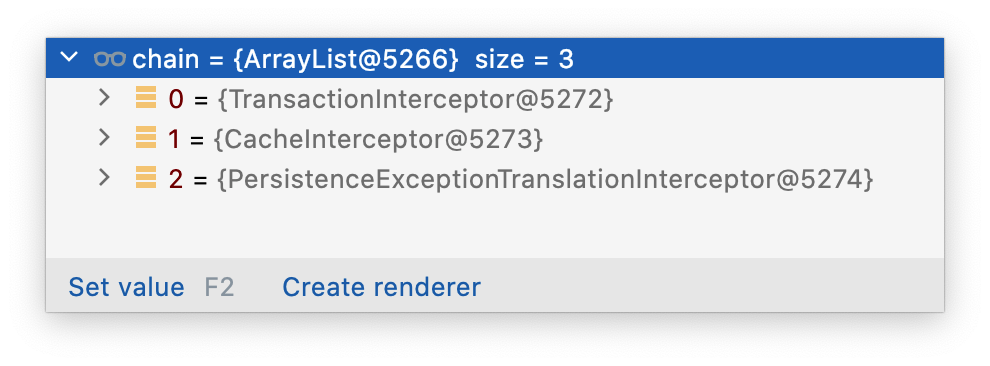
方式 2:
@SpringBootApplication
@EnableCaching
@EnableTransactionManagement
@MapperScan(basePackages = "cn.iocoder.springboot.lab21.cache.mapper")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
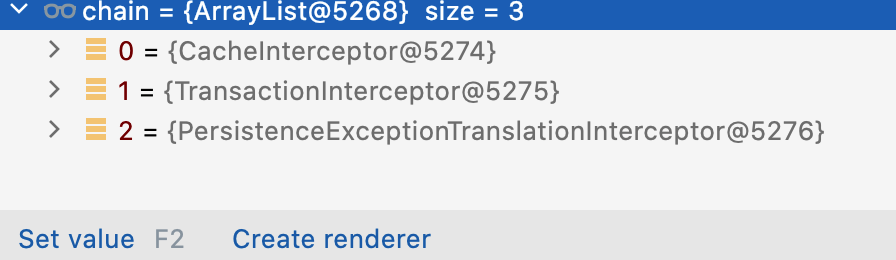
答案:从截图的结果上来看是有影响的,为啥呢
说明:
1、因为@EnableCaching和@@EnableTransactionManagement都是通过 ImportSelector 机制,上面的注解会先被处理;所以方式 1 的事务会被先注册,缓存会被后注册
2、其次虽然在 AOP 会被 Advisor 进行排序
// 代码位置:AbstractAdvisorAutoProxyCreator.class protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) { // <1> 查找候选的 Advisor List<Advisor> candidateAdvisors = findCandidateAdvisors(); // <2> 适配当前 beanClass 的 Advisor List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName); extendAdvisors(eligibleAdvisors); if (!eligibleAdvisors.isEmpty()) { // <3> 对 Advisor 排序 eligibleAdvisors = sortAdvisors(eligibleAdvisors); } return eligibleAdvisors; }但是事务的BeanFactoryTransactionAttributeSourceAdvisor 和缓存的BeanFactoryCacheOperationSourceAdvisor均没有顺序接口或注解,所以排序失效,注册的顺序就是 Advisor 的顺序








-软件测试背景、软件开发过程、软件测试基础](https://img-blog.csdnimg.cn/79677cf37f0e41febc033115d7aa0ebf.png#pic_center)