文章目录
- 概率论基础
- 条件概率
- 全概公式
- 边缘概率
- 联合概率
- 联合概率与边缘概率的关系
- 贝叶斯公式(条件联合概率)
- 马尔科夫链的概念
- HMM简述
- HMM的三个元素
- 符号定义
- 1、状态转移概率矩阵A
- 2、观测概率矩阵B
- 3、初始状态概率向量π
- HMM的三个假设
- 1、齐次马尔可夫假设(一阶马尔可夫链)
- 2、观测独立性假设
- 3、参数不变性假设
- HMM的三个问题
- 1、评估问题 (Evaluation Problem)
- 暴力算法
- 前向算法 (Forward Algorithm)
- 后向算法 (Backward Algorithm)
- 2、学习问题 (Learning Problem)
- 监督学习算法(极大似然估计法)
- EM算法/Baum-Welch算法
- 3、解码问题 (Decoding Problem)
- 近似贪心算法
- 维特比算法(Viterbi Algorithm)
- Reference:
概率论基础
初学HMM之前,先回忆一下概率论、信息论中学到的一些离散型随机变量的基本公式和概念,势必有助于后续公式推导的理解。
条件概率
条件概率表示在条件Y=b成立的情况下,X=a的概率。
A,B相互独立时, P ( B ∣ A ) = P ( B ) , P ( A ∣ B ) = P ( A ) P(B|A)=P(B),P(A|B)=P(A) P(B∣A)=P(B),P(A∣B)=P(A)
全概公式
对于随机事件A与随机事件B,有事件B发生的概率等于在事件A发生的条件下,事件B发生的概率总和:
P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + ⋅ ⋅ ⋅ + P ( A n ) P ( B ∣ A n ) P(B)=P(A_1)P(B|A_1)+P(A_2)P(B|A_2)+···+P(A_n)P(B|A_n) P(B)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+⋅⋅⋅+P(An)P(B∣An)
= ∑ i = 1 n P ( A i ) P ( B ∣ A i ) =\sum_{i=1}^n P(A_i)P(B|A_i) =∑i=1nP(Ai)P(B∣Ai)
边缘概率
边缘概率是与联合概率对应的,P(X=A)或P(Y=B),这类仅与单个随机变量有关的概率称为边缘概率。
全概公式求的就是种边缘概率。
联合概率
联合概率指的是包含多个条件且所有条件同时成立的概率,记作P(X=A,Y=B)或P(A,B)、P(AB),
P ( A , B ) = P ( B ∣ A ) ⋅ P ( A ) P(A,B)=P(B|A)·P(A) P(A,B)=P(B∣A)⋅P(A)
A,B相互独立时, P ( A , B ) = P ( A ) ⋅ P ( B ) P(A,B)=P(A)·P(B) P(A,B)=P(A)⋅P(B)
联合概率与边缘概率的关系
P ( X = A ) = ∑ i P ( X = A , Y = B i ) P(X=A)=\sum_i P(X=A, Y= B_i) P(X=A)=∑iP(X=A,Y=Bi)
P ( X = B ) = ∑ i P ( X = A i , Y = B ) P(X=B)=\sum_i P(X= A_i, Y=B) P(X=B)=∑iP(X=Ai,Y=B)
贝叶斯公式(条件联合概率)
P ( B ∣ A ) = P ( A , B ) P ( A ) \bm{P(B|A) = \frac{P(A,B)}{P(A)}} P(B∣A)=P(A)P(A,B)
或 P ( A ∣ B ) = P ( A , B ) P ( B ) = P ( B ∣ A ) P ( A ) P ( B ) \bm{P(A|B) = \frac{P(A,B)}{P(B)}}=\frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(A,B)=P(B)P(B∣A)P(A)
若A是一个完备事件组(有i个子集),则可写为: P ( A i ∣ B ) = P ( B ∣ A i ) P ( A i ) P ( B ) \bm{P(A_i|B) =\frac{P(B|A_i)P(A_i)}{P(B)}} P(Ai∣B)=P(B)P(B∣Ai)P(Ai)
由于通常不会知道那么多给定的概率,则可继续对后验概率P(B)进行全集分解:
P ( A i ∣ B ) = P ( B ∣ A i ) P ( A i ) ∑ j P ( B ∣ A j ) P ( A j ) \bm{P(A_i|B) =\frac{P(B|A_i)P(A_i)}{\sum_j P(B|A_j)P(A_j)}} P(Ai∣B)=∑jP(B∣Aj)P(Aj)P(B∣Ai)P(Ai)
这样只需知道事件A的先验概率 P ( A ) P(A) P(A)(先验"指它不考虑任何B方面的因素),以及A发生后B的条件概率 P ( B ∣ A ) P(B|A) P(B∣A),就可推出事件B发生后A的条件概率 P ( A ∣ B ) P(A|B) P(A∣B),也由于得自B的取值而被称作A的后验概率。
例如:一座别墅在过去的 20 年里一共发生过 2 次被盗,别墅的主人有一条狗,狗平均每周晚上叫 3 次,在盗贼入侵时狗叫的概率被估计为 0.9,问题是:在狗叫的时候发生入侵的概率是多少?
我们假设 A 事件为狗在晚上叫,B 为盗贼入侵,则以天为单位统计,
P ( A ) = 3 / 7 , P ( B ) = 2 / ( 20 ∗ 365 ) = 2 / 7300 , P ( A ∣ B ) = 0.9 P(A) = 3/7,P(B) = 2/(20*365) = 2/7300,P(A|B) = 0.9 P(A)=3/7,P(B)=2/(20∗365)=2/7300,P(A∣B)=0.9,按照公式很容易得出结果: P ( B ∣ A ) = 0.9 ∗ ( 2 / 7300 ) / ( 3 / 7 ) = 0.00058 P(B|A) = 0.9*(2/7300) / (3/7) = 0.00058 P(B∣A)=0.9∗(2/7300)/(3/7)=0.00058
另一个例子,现分别有 A、B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,在容器 B 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个红球,问这个球来自容器 A 的概率是多少?
假设已经抽出红球为事件 B,选中容器 A 为事件 A,则有: P ( B ) = 8 / 20 , P ( A ) = 1 / 2 , P ( B ∣ A ) = 7 / 10 P(B) = 8/20,P(A) = 1/2,P(B|A) = 7/10 P(B)=8/20,P(A)=1/2,P(B∣A)=7/10,按照公式,则有: P ( A ∣ B ) = ( 7 / 10 ) ∗ ( 1 / 2 ) / ( 8 / 20 ) = 0.875 P(A|B) = (7/10)*(1/2) / (8/20) = 0.875 P(A∣B)=(7/10)∗(1/2)/(8/20)=0.875
对于变量有三个及以上的情况,贝叶斯公式亦成立,也被称作条件联合概率:

马尔科夫链的概念
在机器学习算法中,马尔可夫链(Markov chain)是个很重要的概念。马尔可夫链(Markov chain),又称离散时间马尔可夫链(discrete-time Markov chain),因俄国数学家安德烈·马尔可夫(俄语:Андрей Андреевич Марков)得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性”称作马尔可夫性质。马尔科夫链作为实际过程的统计模型具有许多应用。
在马尔可夫链的每一步,系统根据概率分布,可以从一个状态变到另一个状态,也可以保持当前状态。状态的改变叫做转移,与不同的状态改变相关的概率叫做转移概率。随机漫步就是马尔可夫链的例子。随机漫步中每一步的状态是在图形中的点,每一步可以移动到任何一个相邻的点,在这里移动到每一个点的概率都是相同的(无论之前漫步路径是如何的)。
HMM简述
HMM(Hidden Markov Model,隐马尔可夫模型)是一个输出符号序列的统计模型,也是应用于语音识别等研究领域的经典方法。由于只能观测到输出符号序列,而不能观测到其背后的状态转移序列(即模型输出符号序列时,是通过了哪些状态路径,不能知道),所以称之为“隐藏的”马尔可夫模型。
举一个简单的例子:

由于是隐藏的马尔可夫模型,所以状态序列不可知,即不知道HMM输出aab时,到底是经过了哪一条不同状态组成的路径。因为不知道该HMM输出aab时是通过了哪一条路径,所以是把每一种可能路径的概率相加得到的总的概率值作为aab的输出概率值作为计算输出概率的一种方法。
如上述HMM输出的aab,其总概率是0.036+0.018+0.01152=0.06552。相信通过这个例子,可以对 HMM有一个初步的认识。
HMM发展历史相关的综述就不再啰嗦了,说多了也记不住。
HMM所处理的符号序列结构示意图:

如图可知,我们只知道输出符号序列的观测值,而不知道幕后具体是由何种状态/概率产生的观测值结果,所以观测值背后的状态也叫作隐式变量。
我们已经有了观测值,所以在这种情况下,希望通过HMM来预测观测值是由何种状态产生的。
比如语音识别的场景下,我们假设序列
O
=
[
o
1
,
o
2
,
.
.
.
,
o
T
]
O=[o_1, o_2,...,o_T]
O=[o1,o2,...,oT]代表一段实际观测到的语音序列,已知矩阵
λ
\lambda
λ给定隐藏状态间的转移概率、观测值的生成概率和初始状态。通过所听到的语音序列去预测、反推出可能是说的哪些词这个过程,用条件概率的形式大致可描述为求
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ),即计算在模型
λ
\lambda
λ下观测序列O出现的概率
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ).
HMM的三个元素
符号定义
Q是所有可能状态的集合,V是所有观测值的集合:
Q = q 1 , q 2 , ⋅ ⋅ ⋅ , q N , V = v 1 , v 2 , ⋅ ⋅ ⋅ , v M Q={q_1,q_2,···,q_N}, V={v_1,v_2,···,v_M} Q=q1,q2,⋅⋅⋅,qN,V=v1,v2,⋅⋅⋅,vM
N是状态数、M是观测数(状态q是隐藏的、不可见的,观测值v是可见的)
I是长度为T的状态序列,O是对应的观测序列:
I = ( i 1 , i 2 , . . . , i T ) , O = ( o 1 , o 2 , . . . , o T ) I=(i_1,i_2,...,i_T),O=(o_1,o_2,...,o_T) I=(i1,i2,...,iT),O=(o1,o2,...,oT)
1、状态转移概率矩阵A
A = [ a i j ] N × N A=[a_{ij}]_{N\times N} A=[aij]N×N
其中 a i j = P ( i t + 1 = q j ∣ i t = q i ) i , j = 1 , . . . , N a_{ij}=P(i_{t+1}=q_j|i_t=q_i) \quad i,j=1,...,N aij=P(it+1=qj∣it=qi)i,j=1,...,N
矩阵 A 的元素 a i j 表示: t 时刻从 q i 状态转移到 t + 1 时刻 q j 状态的概率 矩阵A的元素a_{ij}表示:t时刻从q_i状态转移到t+1时刻q_j状态的概率 矩阵A的元素aij表示:t时刻从qi状态转移到t+1时刻qj状态的概率
2、观测概率矩阵B
B
=
[
b
j
(
k
)
]
N
×
M
B=[b_j(k)]_{N \times M}
B=[bj(k)]N×M
其中,
b
j
(
k
)
=
P
(
o
t
=
v
k
∣
i
t
=
q
j
)
k
=
1
,
2
,
.
.
.
,
M
;
j
=
1
,
2
,
.
.
.
,
N
b_j(k)=P(o_t=v_k|i_t=q_j) \quad k=1,2,...,M; j=1,2,...,N
bj(k)=P(ot=vk∣it=qj)k=1,2,...,M;j=1,2,...,N
矩阵 B 的元素 b j ( k ) 表示: t 时刻处于 q i 状态生成观测值 v k 的概率(也叫生成概率 / 发射概率) 矩阵B的元素b_j(k)表示:t时刻处于q_i 状态生成观测值 v_k的概率(也叫生成概率/发射概率) 矩阵B的元素bj(k)表示:t时刻处于qi状态生成观测值vk的概率(也叫生成概率/发射概率)
3、初始状态概率向量π
π i = P ( i 1 = q i ) i = 1 , 2 , . . . , N π_i = P(i_1=q_i) \quad i=1,2,...,N πi=P(i1=qi)i=1,2,...,N
隐马尔可夫模型由状态转移矩阵A、观测概率矩阵B和初始状态向量π决定。
π和A决定状态序列,B决定观测序列。因此,隐马尔可夫模型可用三元符号表示:
λ = ( A , B , π ) , π = ( π i ) \bm{\lambda = (A,B,π),π=(π_i)} λ=(A,B,π),π=(πi)
HMM模型类的定义-Python代码:
class HMM:
def __init__(self, Ann, Bnm, pi1n):
# 状态转移概率矩阵
self.A = np.array(Ann)
# 观测概率矩阵
self.B = np.array(Bnm)
# 初始概率分布
self.pi = np.array(pi1n)
# 状态的数量
self.N = self.A.shape[0]
# 观测结果的数量
self.M = self.B.shape[1]
调用示例:
if __name__ == "__main__":
print("python my HMM")
# 例子: 两枚硬币抛正反面,状态
# 状态集合Q: [q0, q1], q0: 0号硬币, q1: 1号硬币
# 状态转移概率矩阵A: [[q0 -> q0, q0 -> q1], [q1 -> q0, q1 -> q1]]
A = [[0.75, 0.25], [0.25, 0.75]]
# 观测集合V: [v0, v1], v0: 正面, v1: 反面
# 观测概率矩阵B: [[v0|q0, v1|q0], [v0|q1, v1|q1]]
B = [[0.51, 0.49], [0.48, 0.52]]
# 初始概率分布pai: 表示时刻t=1处于状态qi的概率。
pai = [0.5, 0.5]
# 初始化 hmm
hmm = HMM(A, B, pai)
HMM的三个假设
1、齐次马尔可夫假设(一阶马尔可夫链)
任意时刻的状态只依赖前一时刻的状态,与其他时刻及观测值无关。
P ( i t ∣ i t − 1 , o t − 1 , . . . , i 1 , o 1 ) = P ( i t ∣ i t − 1 ) P(i_t|i_{t-1},o_{t-1},...,i1,o1) = P(i_t|i_{t-1}) P(it∣it−1,ot−1,...,i1,o1)=P(it∣it−1)
此式即马尔科夫链模型的的数学表达式。在一阶马尔可夫过程(也称为一阶马尔可夫链)中,系统转移到下一时刻的任一给定状态的概率仅依赖于当前状态。
2、观测独立性假设
任意时刻的观测值只依赖当前时刻的状态,与其他状态及观测值无关。
P ( o t ∣ i t , o t , . . . , i t − 1 , o t − 1 , i 3 , o 3 , i 1 , o 1 ) = P ( o t ∣ i t ) P(o_t|i_t,o_{t},...,i_{t-1},o_{t-1},i_3,o_3,i_1,o_1)=P(o_t|i_t) P(ot∣it,ot,...,it−1,ot−1,i3,o3,i1,o1)=P(ot∣it)
(这个特征限制了HMM的特征选择,导致无法考虑到上下文特征,LSTM通过引入门控机制、遗忘门和输入门等方式,可以改善这个问题)
根据齐次马尔可夫假设和观测独立性假设,HMM求解的联合概率分布可以定义为:
P ( o 1 , i 1 , . . . , o n , i n ) = P ( i 1 ) P ( o 1 ∣ i 1 ) ∏ j = 2 n P ( i j ∣ i j − 1 ) P ( o j ∣ i j ) P(o_1,i_1,...,o_n,i_n) = P(i_1)P(o_1|i_1)\prod_{j=2}^{n}P(i_j|i_{j-1})P(o_j|i_j) P(o1,i1,...,on,in)=P(i1)P(o1∣i1)∏j=2nP(ij∣ij−1)P(oj∣ij)
等号右侧可以看出,联合概率被分解为 P ( o 1 , i 1 ) ∏ j = 2 n P ( i j ∣ i j − 1 ) P ( o j ∣ i j ) P(o_1,i_1)\prod_{j=2}^{n}P(i_j|i_{j-1})P(o_j|i_j) P(o1,i1)∏j=2nP(ij∣ij−1)P(oj∣ij)
当 n = 2 时, P ( o 1 , i 1 , o 2 , i 2 ) = P ( o 1 , i 1 ) ∏ j = 2 2 P ( i 2 ∣ i 1 ) P ( o 2 ∣ i 2 ) n=2时,P(o_1,i_1,o_2,i_2)=P(o_1,i_1)\prod_{j=2}^{2}P(i_2|i_{1})P(o_2|i_2) n=2时,P(o1,i1,o2,i2)=P(o1,i1)∏j=22P(i2∣i1)P(o2∣i2)
即 P ( o 1 , i 1 , o 2 , i 2 ) = P ( i 1 ) P ( o 1 ∣ i 1 ) P ( i 2 ∣ i 1 ) P ( o 2 ∣ i 2 ) , i 1 为初始时刻的状态 即P(o_1,i_1,o_2,i_2)=P(i_1)P(o_1|i_1)P(i_2|i_{1})P(o_2|i_2),i_1为初始时刻的状态 即P(o1,i1,o2,i2)=P(i1)P(o1∣i1)P(i2∣i1)P(o2∣i2),i1为初始时刻的状态
n n n取其他时,依此类推。
3、参数不变性假设
三要素不随时间的变化而变化,即三要素在整个训练过程中保持不变。
HMM的三个问题
1、评估问题 (Evaluation Problem)
给定模型 λ = ( A , B , π ) \lambda = (A,B,π) λ=(A,B,π)和观测序列 O = ( o 1 , o 2 , . . . , o T ) O=(o_1,o_2,...,o_T) O=(o1,o2,...,oT),计算在给定模型λ下观测序列O出现的概率: P ( O ∣ λ ) P(O|\lambda) P(O∣λ)
评估问题通常应用于语音识别、自然语言处理(NLP)、生物信息学等领域。
例如,在语音识别任务中,从计算机执行任务的角度去理解就是需要计算出某个说话人说出一句话的概率,而这句话的音频信号就可以转化为一个观测序列,通过HMM来计算其概率。
暴力算法
对所有可能的状态序列和观测序列的联合概率求和:
P ( I ∣ λ ) = π i 1 a i 1 i 2 a i 2 i 2 ⋅ ⋅ ⋅ a i T − 1 i T P(I|\lambda)=π_{i_1}a_{i_1i_2}a_{i_2i_2}···a_{i_{T-1}i_T} P(I∣λ)=πi1ai1i2ai2i2⋅⋅⋅aiT−1iT
其中 π i 1 π_{i_1} πi1为初始状态的概率,符号 a i t − 1 i t a_{i_{t-1}i_t} ait−1it代表从 t − 1 t-1 t−1时刻状态到 t t t时刻状态的状态转移概率,具体如何化简出的,主要就靠条件概率公式和条件联合概率公式(含多个随机事件的贝叶斯公式)推导得出,感兴趣的同学可以观看学习机器学习-白板推导系列(十四)-隐马尔可夫模型HMM(Hidden Markov Model);
对于固定的状态序列,观测序列O的概率为:
P ( O ∣ I , λ ) = b i 1 ( o 1 ) b i 2 ( o 2 ) ⋅ ⋅ ⋅ b i T ( o T ) P(O|I,\lambda)=b_{i_1}(o_1)b_{i_2}(o_2)···b_{i_T}(o_T) P(O∣I,λ)=bi1(o1)bi2(o2)⋅⋅⋅biT(oT)
其中符号 b b b为各时刻状态 i t i_t it对应下生成观测值 o t o_t ot的生成概率;
则在给定模型 λ \lambda λ下观测序列 O O O出现的概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)为:
P ( O ∣ λ ) = ∑ I P ( O ∣ I , λ ) P ( I ∣ λ ) P(O|\lambda)=\sum_I P(O|I,\lambda) P(I|\lambda) P(O∣λ)=∑IP(O∣I,λ)P(I∣λ)
= ∑ i 1 , i 2 , ⋅ ⋅ ⋅ , i T π i 1 b i 1 ( o 1 ) a i 1 i 2 b i 2 ( o 2 ) ⋅ ⋅ ⋅ a i T − 1 i T b i T ( o T ) =\sum_{i_1,i_2,···,i_T}π_{i_1}b_{i_1}(o_1)a_{i_1i_2}b_{i2}(o_2)···a_{i_{T-1}i_T}b_{i_T}(o_T) =∑i1,i2,⋅⋅⋅,iTπi1bi1(o1)ai1i2bi2(o2)⋅⋅⋅aiT−1iTbiT(oT)
由于状态数为N,状态序列
I
I
I的长度为
T
T
T,状态序列共有
N
T
N^T
NT种可能,求和符号包含
i
1
i_1
i1~
i
T
i_T
iT共
T
T
T个因子,故暴力算法的时间复杂度为
O
(
T
N
T
)
O(TN^T)
O(TNT),计算量太大,所以该方法仅理论上可行。
通过前向算法和后向算法可以降低暴力算法求解的时间复杂度。
前向算法 (Forward Algorithm)
定义前向变量:
α
t
(
i
)
=
P
(
o
1
,
o
2
,
⋅
⋅
⋅
,
o
t
,
i
t
=
q
i
∣
λ
)
\alpha_t(i) = P(o_1,o_2,···,o_t,i_t=q_i|\lambda)
αt(i)=P(o1,o2,⋅⋅⋅,ot,it=qi∣λ),注意这里用到的符号是阿尔法
α
\alpha
α,和之前状态转移概率的符号
a
a
a要区别开,两者含义并不一致。

α
t
(
i
)
\alpha_t(i)
αt(i)表示在
t
t
t时刻,观测序列为
o
1
,
o
2
,
⋅
⋅
⋅
,
o
t
o_1,o_2,···,o_t
o1,o2,⋅⋅⋅,ot,状态为
q
i
=
i
t
q_i=i_t
qi=it的概率,则在给定模型
λ
\lambda
λ下观测序列
O
O
O的概率
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ)为:
P ( O ∣ λ ) = ∑ i = 1 N α T ( i ) P(O|\lambda)=\sum_{i=1}^N\alpha_T(i) P(O∣λ)=∑i=1NαT(i)
计算过程:
1、初始概率
α 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2 , . . . , N \alpha_1(i)=π_ib_i(o_1),i=1,2,...,N α1(i)=πibi(o1),i=1,2,...,N
2、递归计算
α t + 1 ( i ) = b i ( o t + 1 ) ∑ j = 1 N α t ( j ) α j i , i = 1 , 2 , . . . , N \alpha_{t+1}(i)=b_i(o_{t+1})\sum_{j=1}^N\alpha_t(j)\alpha_{ji},i=1,2,...,N αt+1(i)=bi(ot+1)∑j=1Nαt(j)αji,i=1,2,...,N
3、对T时刻的所有前向概率求和(到T时刻递归终止)
P ( O ∣ λ ) = ∑ i = 1 N α T ( i ) P(O|\lambda)=\sum_{i=1}^N\alpha_T(i) P(O∣λ)=∑i=1NαT(i)
HMM评估问题-前向算法-Python代码示例:
# 函数名称:Forward *功能:前向算法估计参数 *参数:phmm:指向HMM的指针
# T:观察值序列的长度 O:观察值序列
# alpha:运算中用到的临时数组 pprob:返回值,所要求的概率
def Forward(self, T, O, alpha, pprob):
# 1. 初始化
for i in range(self.N):
alpha[0, i] = self.pi[i] * self.B[i, O[0]]
# 2. 递归
for t in range(T - 1):
for j in range(self.N):
sum = 0.0
for i in range(self.N):
sum += alpha[t, i] * self.A[i, j]
alpha[t + 1, j] = sum * self.B[j, O[t + 1]]
# 3. 终止
sum = 0.0
for i in range(self.N):
sum += alpha[T - 1, i]
pprob[0] *= sum
后向算法 (Backward Algorithm)
对比前向变量,后向变量 β \beta β取的是t+1时刻到最终时刻T的观测值,即所选观测序列为 o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T o_{t+1},o_{t+2},···,o_T ot+1,ot+2,⋅⋅⋅,oT,状态为 q i = i t q_i=i_t qi=it的概率。

在HMM模型中,可以利用前向变量和后向变量计算单个状态的概率和两个状态的联合概率。
HMM评估问题-后向算法-Python代码示例:
# 函数名称:Backward * 功能:后向算法估计参数 * 参数:phmm:指向HMM的指针
# T:观察值序列的长度 O:观察值序列
# beta:运算中用到的临时数组 pprob:返回值,所要求的概率
def Backword(self, T, O, beta, pprob):
# 1. Intialization
for i in range(self.N):
beta[T - 1, i] = 1.0
# 2. Induction
for t in range(T - 2, -1, -1):
for i in range(self.N):
sum = 0.0
for j in range(self.N):
sum += self.A[i, j] * self.B[j, O[t + 1]] * beta[t + 1, j]
beta[t, i] = sum
# 3. Termination
pprob[0] = 0.0
for i in range(self.N):
pprob[0] += self.pi[i] * self.B[i, O[0]] * beta[0, i]
2、学习问题 (Learning Problem)
给定模型 λ = ( A , B , π ) \lambda = (A,B,π) λ=(A,B,π)和观测序列 O = ( o 1 , o 2 , . . . , o T ) O=(o_1,o_2,...,o_T) O=(o1,o2,...,oT),使得模型 λ \lambda λ下观测序列的条件概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)最大。
在机器翻译任务中,需要将源语言的句子翻译成目标语言的句子,而HMM可以用来选择最优的单词对齐方式,从而生成对应的译文。
监督学习算法(极大似然估计法)
通常,如果给定数据和已经模型,在已知状态序列的情况下,可以直接采用极大似然估计来估计隐马尔可夫模型的参数,但在没有对应状态序列的情况下,采用人工标注训练数据代价太高,无法用极大似然求解(对数式子里面有求和,难以求出解析解),此时就可以使用EM算法(无监督学习)。
EM算法/Baum-Welch算法
EM算法(Expectation-Maximization Algorithm)是一种迭代求解最大似然估计或最大后验概率模型参数的方法。它通常用于处理含有隐变量(即缺失数据)的统计模型,例如高斯混合模型(GMM)、隐马尔可夫模型等。
该算法的大致原理是:首先设定模型参数的初始值,然后重复执行两步操作:E步(Expectation Step)和M步(Maximization Step)
在E步中,根据当前参数估计值来计算每个数据点属于每个隐变量取值的概率;
在M步中,根据这些概率重新估计模型参数值。这样不断迭代直至收敛,得到最优的模型参数估计值。
具体而言,在E步中,需要计算每个隐变量的期望值(也就是对应的后验概率),这一步通常使用贝叶斯公式进行计算;在M步中,需要最大化边缘似然函数关于参数的期望值,得到新的参数估计值。这一步通常通过求解参数估计方程、梯度下降等方法实现。
总之,EM算法通过迭代求解隐变量及参数的估计值,从而实现基于无标记数据的参数估计。
Baum-Welch算法就是EM算法在HMM中的具体体现。
EM算法的推导过程要复杂很多,这里就不抄了,具体可以参考机器学习-白板推导系列(十四)-隐马尔可夫模型HMM(Hidden Markov Model)-P5
HMM-Baum-Welch算法-Python代码示例:
# Baum-Welch算法
# 初始模型:HMM={A,B,pi,N,M}
# 输入 L个观测序列O
def BaumWelch(self, L, T, O, alpha, beta, gamma):
print("BaumWelch")
DELTA = 0.01
round = 0
flag = 1
probf = [0.0]
delta = 0.0
deltaprev = 0.0
probprev = 0.0
ratio = 0.0
deltaprev = 10e-70
xi = np.zeros((T, self.N, self.N))
pi = np.zeros((T), np.float64)
denominatorA = np.zeros((self.N), np.float64)
denominatorB = np.zeros((self.N), np.float64)
numeratorA = np.zeros((self.N, self.N), np.float64)
numeratorB = np.zeros((self.N, self.M), np.float64)
scale = np.zeros((T), np.float64)
while True:
probf[0] = 0
# E - step
for l in range(L):
self.ForwardWithScale(T, O[l], alpha, scale, probf)
self.BackwardWithScale(T, O[l], beta, scale)
self.ComputeGamma(T, alpha, beta, gamma)
self.ComputeXi(T, O[l], alpha, beta, gamma, xi)
for i in range(self.N):
pi[i] += gamma[0, i]
for t in range(T - 1):
denominatorA[i] += gamma[t, i]
denominatorB[i] += gamma[t, i]
denominatorB[i] += gamma[T - 1, i]
for j in range(self.N):
for t in range(T - 1):
numeratorA[i, j] += xi[t, i, j]
for k in range(self.M):
for t in range(T):
if O[l][t] == k:
numeratorB[i, k] += gamma[t, i]
# M - step
# 重估状态转移矩阵 和 观察概率矩阵
for i in range(self.N):
self.pi[i] = 0.001 / self.N + 0.999 * pi[i] / L
for j in range(self.N):
self.A[i, j] = (
0.001 / self.N + 0.999 * numeratorA[i, j] / denominatorA[i]
)
numeratorA[i, j] = 0.0
for k in range(self.M):
self.B[i, k] = (
0.001 / self.M + 0.999 * numeratorB[i, k] / denominatorB[i]
)
numeratorB[i, k] = 0.0
pi[i] = denominatorA[i] = denominatorB[i] = 0.0
if flag == 1:
flag = 0
probprev = probf[0]
ratio = 1
continue
delta = probf[0] - probprev
ratio = delta / deltaprev
probprev = probf[0]
deltaprev = delta
round += 1
if ratio <= DELTA:
print("num iteration ", round)
break
3、解码问题 (Decoding Problem)
给定模型 λ = ( A , B , π ) \lambda = (A,B,π) λ=(A,B,π)和观测序列 O = ( o 1 , o 2 , . . . , o T ) O=(o_1,o_2,...,o_T) O=(o1,o2,...,oT),求最有可能的状态序列。
在人脸识别任务中,需要从大量的人脸图像中学习出一种HMM模型,以便在未知图像中识别出其所属的人物身份。
近似贪心算法
在HMM解码问题中,使用的近似贪心算法是一种基于“贪心”思想的启发式算法。它从观测序列的第一个位置开始,通过每次选择在当前位置上具有最大概率的状态来递推地计算整个状态序列。简单来说,该算法假定每个时刻只考虑当前最优解,而不考虑全局最优解。
与维特比算法相比,近似贪心算法的主要区别在于其计算效率更高,但精度较低。尽管两种算法都是基于动态规划的思想,但近似贪心算法没有计算和存储全局最优解的表格,同时也没有使用回溯的方式进行全局搜索。因此,对于一些较长的观测序列和复杂的状态转移矩阵,近似贪心算法可能会导致误差累积和漏解等问题。
维特比算法则是一种准确且经典的解决HMM解码问题的算法,其主要思想是通过动态规划计算全局最优路径,并使用回溯的方式得到最优解。当状态转移矩阵和观测矩阵满足Markov性质时,维特比算法能够保证全局最优解的正确性。尽管维特比算法的时间复杂度较高,但在实际应用中其表现良好,被广泛使用于语音识别、自然语言处理和生物信息学等领域。
维特比算法(Viterbi Algorithm)
维特比算法学通信的小伙伴肯定非常熟悉,在《通信原理》、《数字通信原理》课程中维特比译码也是十分重要的知识点。其本质就是根据状态之间的转移概率每次取最优的状态转移路径,而抛弃其他路径,最终留下一条完整的从起点至终点的最优路径。
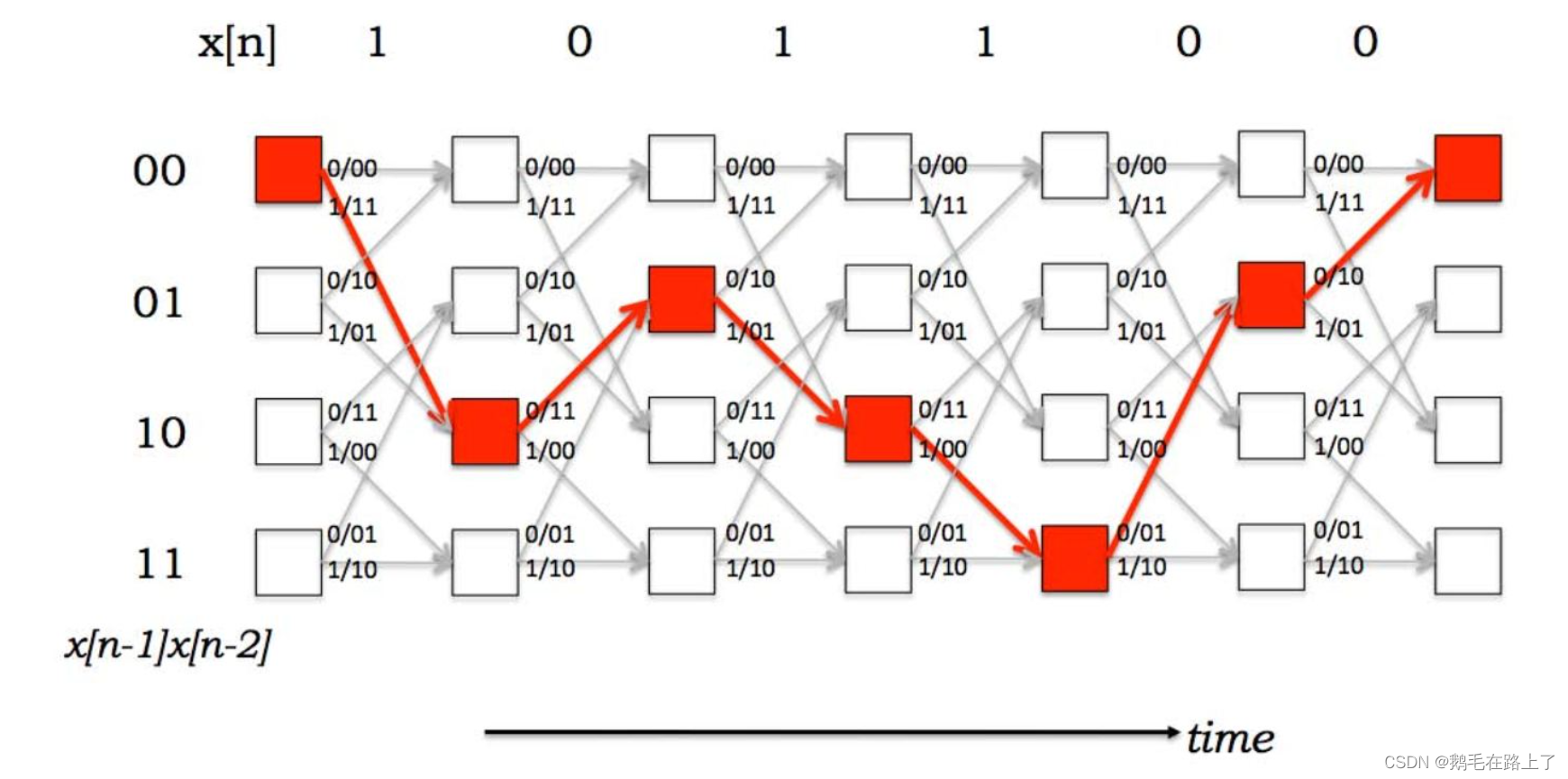
HMM-Viterbi算法-Python代码示例:
# Viterbi算法
# 输入:A,B,pi,O 输出P(O|lambda)最大时Poptimal的路径I
def viterbi(self, O):
T = len(O)
# 初始化
delta = np.zeros((T, self.N), np.float6464)
phi = np.zeros((T, self.N), np.float6464)
I = np.zeros(T)
for i in range(self.N):
delta[0, i] = self.pi[i] * self.B[i, O[0]]
phi[0, i] = 0
# 递推
for t in range(1, T):
for i in range(self.N):
delta[t, i] = (
self.B[i, O[t]]
* np.array(
[delta[t - 1, j] * self.A[j, i] for j in range(self.N)]
).max()
)
phi[t, i] = np.array(
[delta[t - 1, j] * self.A[j, i] for j in range(self.N)]
).argmax()
# 终结
prob = delta[T - 1, :].max()
I[T - 1] = delta[T - 1, :].argmax()
# 状态序列求取
for t in range(T - 2, -1, -1):
I[t] = phi[t + 1, I[t + 1]]
return I, prob
Reference:
1、《语音信号处理》—— 赵力
2、一般一般世界第三:一文带你了解隐马尔可夫模型(含详细推导)
3、Return到主函数:下面条件联合分布如何推导出来的?
4、数学中国:马尔可夫链 ▏小白都能看懂的马尔可夫链详解
5、liuwu265:隐马尔可夫模型(HMM)原理
6、python 实现HMM