文章目录
- 前言
- 1. 引用和临时数据
- 🍑 什么样的临时数据会放到寄存器中
- 🍑 关于常量表达式
- 🍑 引用也不能指代临时数据
- 🍑 引用作为函数参数
- 2. 为const引用创建临时变量
- 3. const引用与转换类型
- 🍑 引用类型的函数形参请尽可能的使用 const
前言
在上一篇文章中,详细的为大家介绍了 引用和指针的区别,这篇文章继续跟着我一起探究引用的底层吧。
1. 引用和临时数据
我们知道,指针就是数据或代码在内存中的地址,指针变量指向的就是内存中的数据或代码。这里有一个关键词需要强调,就是 内存,指针只能指向内存,不能指向寄存器或者硬盘,因为寄存器和硬盘没法寻址。
其实 C++ 代码中的大部分内容都是放在内存中的,例如定义的变量、创建的对象、字符串常量、函数形参、函数体本身、new 或 malloc() 分配的内存等,这些内容都可以用 & 来获取地址,进而用指针指向它们。
除此之外,还有一些我们平时不太留意的临时数据,例如表达式的结果、函数的返回值等,它们可能会放在内存中,也可能会放在寄存器中。一旦它们被放到了寄存器中,就没法用 & 获取它们的地址了,也就没法用指针指向它们了。
下面的代码演示了表达式所产生的临时结果:
int main()
{
int n = 10, m = 20;
int* p1 = &(m + n); //m + n 的结果为 300
int* p2 = &(n + 100); //n + 100 的结果为 200
bool* p4 = &(m < n); //m < n 的结果为 false
return 0;
}
这些表达式的结果都会被放到寄存器中,尝试用 & 获取它们的地址都是错误的。

下面的代码演示了函数返回值所产生的临时结果:
int func()
{
int n = 100;
return n;
}
int main()
{
int* p = &(func());
return 0;
}
func() 的返回值 100 也会被放到寄存器中,也没法用 & 获取它的地址。
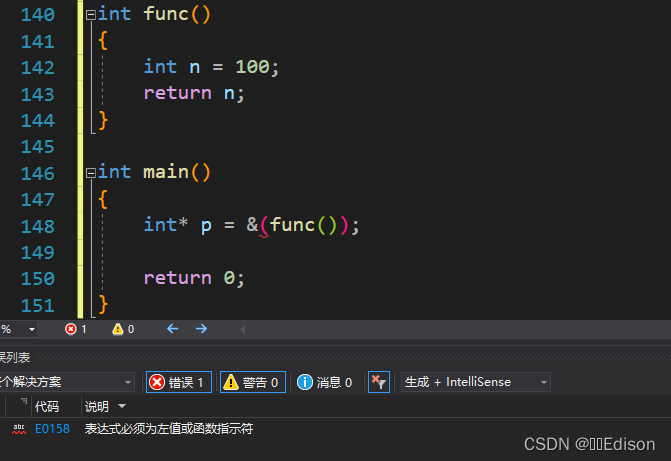
🍑 什么样的临时数据会放到寄存器中
寄存器离 CPU 近,并且速度比内存快,将临时数据放到寄存器是为了加快程序运行。但是寄存器的数量是非常有限的,容纳不下较大的数据,所以只能将较小的临时数据放在寄存器中。
int、double、bool、char 等基本类型的数据往往不超过 8 个字节,用一两个寄存器就能存储,所以这些类型的临时数据通常会放到寄存器中;而对象、结构体变量是自定义类型的数据,大小不可预测,所以这些类型的临时数据通常会放到内存中。
下面的代码证明了结构体类型的临时数据会被放到内存中:
struct S
{
int a;
int b;
};
//运算符重载
S operator+(const S& A, const S& B)
{
S C;
C.a = A.a + B.a;
C.b = A.b + B.b;
return C;
}
S func()
{
S a;
a.a = 100;
a.b = 200;
return a;
}
int main()
{
S s1 = { 10, 20 };
S s2 = { 40, 50 };
S p1 = (s1 + s2);
S p2 = (func());
S* pp1 = &p1;
S* pp2 = &p2;
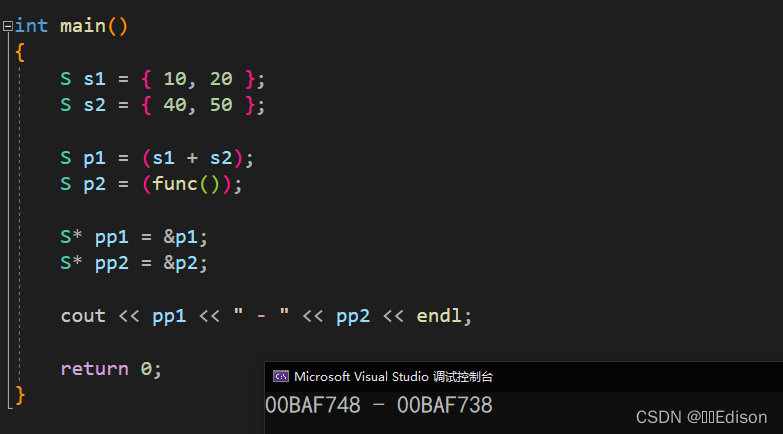
cout << pp1 << " - " << pp2 << endl;
return 0;
}
运行结果:
🍑 关于常量表达式
诸如 100、200+34、34.5*23、3+7/3 等不包含变量的表达式称为常量表达式(Constant expression)。
常量表达式由于不包含变量,没有不稳定因素,所以在编译阶段就能求值。编译器不会分配单独的内存来存储常量表达式的值,而是将常量表达式的值和代码合并到一起,放到虚拟地址空间中的代码区。从汇编的角度看,常量表达式的值就是一个立即数,会被“硬编码”到指令中,不能寻址。
总起来说,常量表达式的值虽然在内存中,但是没有办法寻址,所以也不能使用 & 来获取它的地址,更不能用指针指向它。
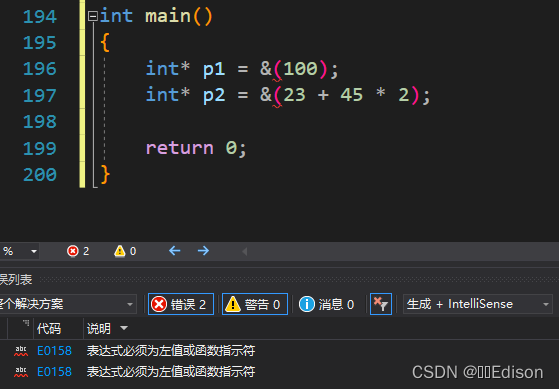
下面的代码就是错误的,它证明了不能用 & 来获取常量表达式的地址:
int main()
{
int* p1 = &(100);
int* p2 = &(23 + 45 * 2);
return 0;
}
错误说明:
🍑 引用也不能指代临时数据
引用和指针在本质上是一样的,引用仅仅是对指针进行了简单的封装。引用和指针都不能绑定到无法寻址的临时数据,并且 C++ 对引用的要求更加严格,在某些编译器下甚至连放在内存中的临时数据都不能指代。
下面的代码中,我们将引用绑定到了临时数据:
struct S {
int a;
int b;
};
int func_int() {
int n = 100;
return n;
}
S func_s() {
S a;
a.a = 100;
a.b = 200;
return a;
}
//运算符重载
S operator+(const S& A, const S& B) {
S C;
C.a = A.a + B.a;
C.b = A.b + B.b;
return C;
}
int main()
{
//下面的代码在GCC和Visual C++下都是错误的
int m = 100, n = 36;
int& r1 = m + n;
int& r2 = m + 28;
int& r3 = 12 * 3;
int& r4 = 50;
int& r5 = func_int();
//下面的代码在GCC下是错误的,在Visual C++下是正确的
S s1 = { 23, 45 };
S s2 = { 90, 75 };
S& r6 = func_s();
S& r7 = s1 + s2;
return 0;
}
因此可以说明:
- 在 GCC 下,引用不能指代任何临时数据,不管它保存到哪里;
- 在 Visual C++ 下,引用只能指代位于内存中(非代码区)的临时数据,不能指代寄存器中的临时数据。
🍑 引用作为函数参数
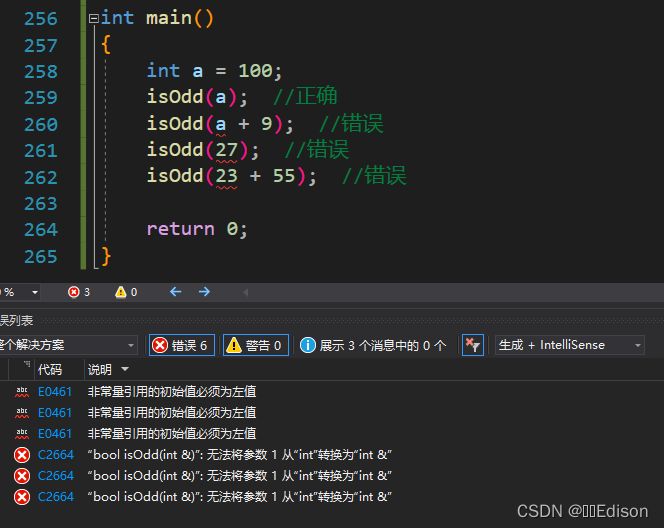
当引用作为函数参数时,有时候很容易给它传递临时数据。下面的 isOdd() 函数用来判断一个数是否是奇数:
bool isOdd(int& n)
{
if (n % 2 == 0)
return false;
else
return true;
}
int main()
{
int a = 100;
isOdd(a); //正确
isOdd(a + 9); //错误
isOdd(27); //错误
isOdd(23 + 55); //错误
return 0;
}
isOdd() 函数用来判断一个数是否为奇数,它的参数是引用类型,只能传递变量,不能传递常量或者表达式。但用来判断奇数的函数不能接受一个数字又让人感觉很奇怪,所以类似这样的函数应该坚持使用值传递,而不是引用传递。
下面是更改后的代码:
bool isOdd(int n) { //改为值传递
if (n % 2 == 0)
return false;
else
return true;
}
int main()
{
int a = 100;
isOdd(a); //正确
isOdd(a + 9); //正确
isOdd(27); //正确
isOdd(23 + 55); //正确
return 0;
}
2. 为const引用创建临时变量
上面说到,引用不能绑定到临时数据,这在大多数情况下是正确的,但是当使用 const 关键字对引用加以限定后,引用就可以绑定到临时数据了。
下面的代码演示了引用和 const 这一对神奇的组合:
struct S
{
int a;
int b;
};
int func_int() {
int n = 100;
return n;
}
S func_s() {
S a;
a.a = 100;
a.b = 200;
return a;
}
S operator+(const S& A, const S& B) {
S C;
C.a = A.a + B.a;
C.b = A.b + B.b;
return C;
}
int main()
{
int m = 100, n = 36;
const int& r1 = m + n;
const int& r2 = m + 28;
const int& r3 = 12 * 3;
const int& r4 = 50;
const int& r5 = func_int();
S s1 = { 23, 45 };
S s2 = { 90, 75 };
const S& r6 = func_s();
const S& r7 = s1 + s2;
return 0;
}
这段代码在 GCC 和 Visual C++ 下都能够编译通过,这是因为将常引用绑定到临时数据时,编译器采取了一种妥协机制:编译器会为临时数据创建一个新的、无名的临时变量,并将临时数据放入该临时变量中,然后再将引用绑定到该临时变量。注意,临时变量也是变量,所有的变量都会被分配内存。
为什么编译器为常引用创建临时变量是合理的,而为普通引用创建临时变量就不合理呢?
(1)我们知道,将引用绑定到一份数据后,就可以通过引用对这份数据进行操作了,包括读取和写入(修改);尤其是写入操作,会改变数据的值。而临时数据往往无法寻址,是不能写入的,即使为临时数据创建了一个临时变量,那么修改的也仅仅是临时变量里面的数据,不会影响原来的数据,这样就使得引用所绑定到的数据和原来的数据不能同步更新,最终产生了两份不同的数据,失去了引用的意义。
以 swap() 函数为例:
void swap(int& r1, int& r2)
{
int temp = r1;
r1 = r2;
r2 = temp;
}
如果编译器会为 r1、r2 创建临时变量,那么函数调用 swap(10, 20) 就是正确的,但是 10 不会变成 20,20 也不会变成 10,所以这种调用是毫无意义的。
总起来说,不管是从 “引用的语义” 这个角度看,还是从 “实际应用的效果” 这个角度看,为普通引用创建临时变量都没有任何意义,所以编译器不会这么做。
(2)const 引用和普通引用不一样,我们只能通过 const 引用读取数据的值,而不能修改它的值,所以不用考虑同步更新的问题,也不会产生两份不同的数据,为 const 引用创建临时变量反而会使得引用更加灵活和通用。
以上面的 isOdd() 函数为例:
bool isOdd(const int& n) //改为常引用
{
if (n / 2 == 0)
return false;
else
return true;
}
由于在函数体中不会修改 n 的值,所以可以用 const 限制 n,这样一来,下面的函数调用就都是正确的了:
int main()
{
int a = 100;
isOdd(a); //正确
isOdd(a + 9); //正确
isOdd(27); //正确
isOdd(23 + 55); //正确
return 0;
}
对于第 2 行代码,编译器不会创建临时变量,会直接绑定到变量 a;对于第 3~5 行代码,编译器会创建临时变量来存储临时数据。
也就是说,编译器只有在必要时才会创建临时变量。
3. const引用与转换类型
不同类型的数据占用的内存数量不一样,处理方式也不一样,指针的类型要与它指向的数据的类型严格对应。
下面的例子演示了错误的指针使用方式:
int main()
{
int n = 100;
int* p1 = &n; //正确
float* p2 = &n; //错误
char c = '@';
char* p3 = &c; //正确
int* p4 = &c; //错误
return 0;
}
虽然 int 可以自动转换为 float,char 也可以自动转换为 int,但是 float * 类型的指针不能指向 int 类型的数据,int * 类型的指针也不能指向 char 类型的数据。
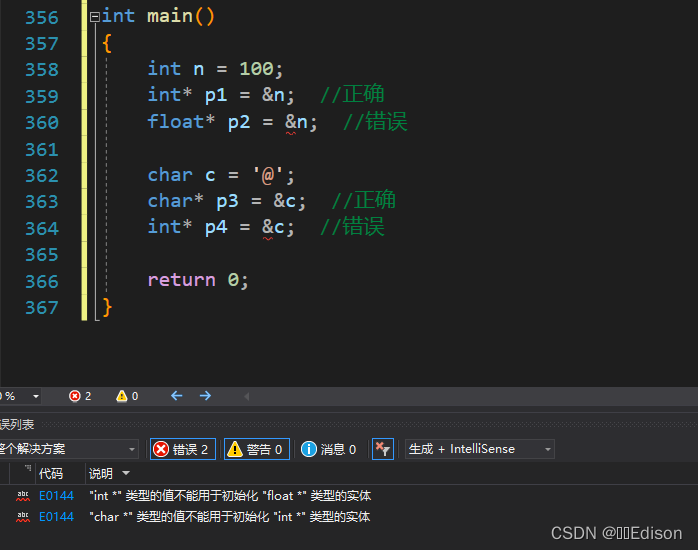
为什么「编译器禁止指针指向不同类型的数据」是合理的呢?
以 int 类型的数据和 float * 类型的指针为例,我们让 float * 类型的指针强制指向 int 类型的数据,看看会发生什么。
代码示例如下:
int main()
{
int n = 100;
float* p = (float*)&n;
*p = 19.625;
printf("%d\n", n);
return 0;
}
将 float 类型的数据赋值给 int 类型的变量时,会直接截去小数部分,只保留整数部分,本例中将 19.626 赋值给 n,n 的值应该为 19 才对,这是我们通常的认知。但是本例的输出结果是一个毫无意义的数字,它与 19 没有任何关系,这颠覆了我们的认知。
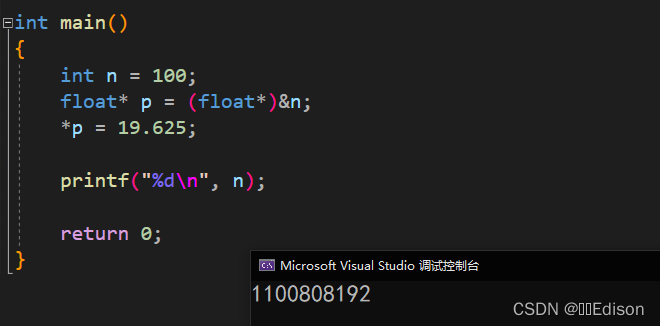
虽然 int 和 float 类型都占用 4 个字节的内存,但是程序对它们的处理方式却大相径庭:
- 对于 int,程序把最高 1 位作为符号位,把剩下的 31 位作为数值位;
- 对于 float,程序把最高 1 位作为符号位,把最低的 23 位作为尾数位,把中间的 8 位作为指数位。
n 存储的二进制位是不变的,只是当以不同的形式展现出来的时候,我们看到的结果是不一样的。
让指针指向「相关的(相近的)但不是严格对应的」类型的数据,表面上看起来是合理的,但是细思极恐,这样会给程序留下很多意想不到的、难以发现的 Bug,所以编译器禁止这样做是非常合理的。当然,如果你想通过强制类型转换达到这个目的(如上例所示),那编译器也会放任不管,给你自由发挥的余地。
引用(Reference)和指针(Pointer)在本质上是一样的,引用仅仅是对指针进行了简单的封装,「类型严格一致」这条规则同样也适用于引用。
下面的例子演示了错误的引用使用方式:
int main()
{
int n = 100;
int& r1 = n; //正确
float& r2 = n; //错误
char c = '@';
char& r3 = c; //正确
int& r4 = c; //错误
return 0;
}
错误说明:
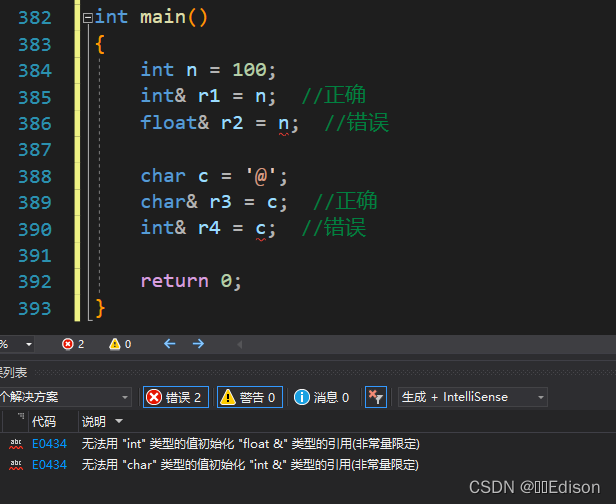
类型严格一致 是为了防止发生让人匪夷所思的操作,但是这条规则仅仅适用于普通引用,当对引用添加 const 限定后,情况就又发生了变化,编译器允许引用绑定到类型不一致的数据。
请看下面的代码:
int main()
{
int n = 100;
int& r1 = n; //正确
const float& r2 = n; //正确
char c = '@';
char& r3 = c; //正确
const int& r4 = c; //正确
return 0;
}
当引用的类型和数据的类型不一致时,如果它们的类型是相近的,并且遵守 数据类型的自动转换 规则,那么编译器就会创建一个临时变量,并将数据赋值给这个临时变量(这时候会发生自动类型转换),然后再将引用绑定到这个临时的变量,这与「将 const 引用绑定到临时数据时」采用的方案是一样的。
注意,临时变量的类型和引用的类型是一样的,在将数据赋值给临时变量时会发生自动类型转换。
请看下面的代码:
int main()
{
float f = 12.45;
const int& r = f;
printf("%d", r);
return 0;
}
该代码的输出结果为 12,说明临时变量和引用的类型都是 int(严格来说引用的类型是 int &),并没有变为 float。
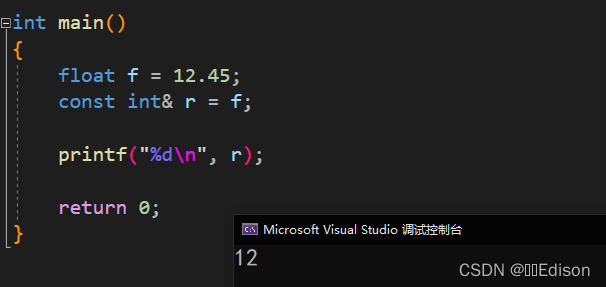
当引用的类型和数据的类型不遵守 数据类型的自动转换 规则,那么编译器将报错,绑定失败。
代码示例如下:
int main()
{
char* str = "http://www.edison.com";
const int& r = str;
return 0;
}
char * 和 int 两种类型没有关系,不能自动转换,这种引用就是错误的。
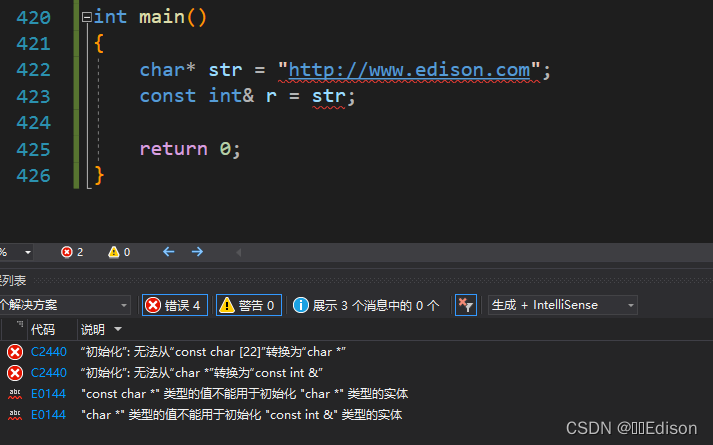
总结起来说,给引用添加 const 限定后,不但可以将引用绑定到临时数据,还可以将引用绑定到类型相近的数据,这使得引用更加灵活和通用,它们背后的机制都是临时变量。
🍑 引用类型的函数形参请尽可能的使用 const
当引用作为函数参数时,如果在函数体内部不会修改引用所绑定的数据,那么请尽量为该引用添加 const 限制。
下面的例子演示了 const 引用的灵活性:
double volume(const double& len, const double& width, const double& hei)
{
return len * width * 2 + len * hei * 2 + width * hei * 2;
}
int main()
{
int a = 12, b = 3, c = 20;
double v1 = volume(a, b, c);
double v2 = volume(10, 20, 30);
double v3 = volume(89.4, 32.7, 19);
double v4 = volume(a + 12.5, b + 23.4, 16.78);
double v5 = volume(a + b, a + c, b + c);
printf("%lf, %lf, %lf, %lf, %lf\n", v1, v2, v3, v4, v5);
return 0;
}
volume() 函数用来求一个长方体的体积,它可以接收不同类型的实参,也可以接收常量或者表达式。
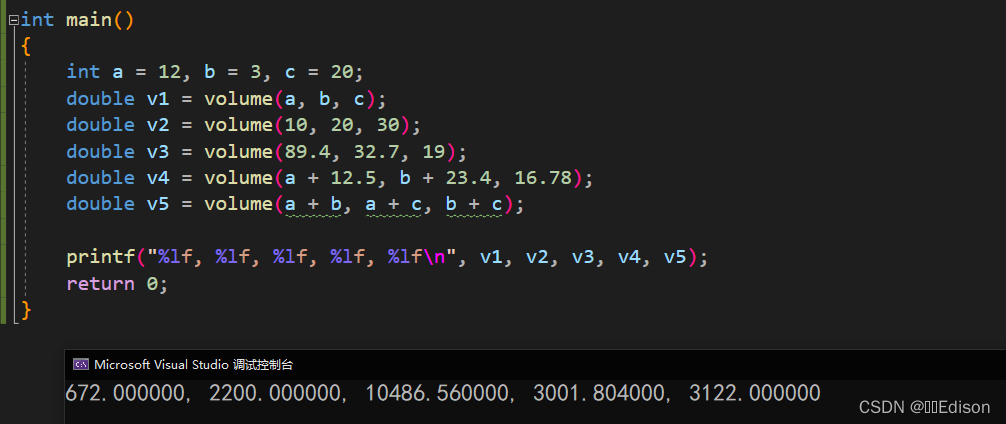
概括起来说,将引用类型的形参添加 const 限制的理由有三个:
- 使用 const 可以避免无意中修改数据的编程错误;
- 使用 const 能让函数接收 const 和非 const 类型的实参,否则将只能接收非 const 类型的实参;
- 使用 const 引用能够让函数正确生成并使用临时变量。