1. 概述
1.1 线程池是什么
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。
创建线程本身开销大,反复创建并销毁,过多的占用内存。所以有大量线程创建考虑使用线程池。线程池不用反复创建线程达到线程的复用,更具配置合理利用cpu和内存减少了开销,性能会得到提高,还能统一管理任务
比如服务器收到大量请求,每个请求都分配线程去处理,对服务器性能考验就比较大,如果创建5个以上线程考虑使用线程池。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
而本文描述线程池是JDK中提供的ThreadPoolExecutor类。
当然,使用线程池可以带来一系列好处:
-
降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
-
提高响应速度:任务到达时,无需等待线程创建即可立即执行。
-
提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
-
提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
1.2 线程池解决的问题是什么
线程池解决的核心问题就是资源管理问题。在并发环境下,系统不能够确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。这种不确定性将带来以下若干问题:
-
频繁申请/销毁资源和调度资源,将带来额外的消耗,可能会非常巨大。
-
对资源无限申请缺少抑制手段,易引发系统资源耗尽的风险。
-
系统无法合理管理内部的资源分布,会降低系统的稳定性。
为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想。池化,顾名思义,是为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想。
Pooling is the grouping together of resources (assets, equipment, personnel, effort, etc.) for the purposes of maximizing advantage or minimizing risk to the users. The term is used in finance, computing and equipment management.——wikipedia
“池化”思想不仅仅能应用在计算机领域,在金融、设备、人员管理、工作管理等领域也有相关的应用。
在计算机领域中的表现为:统一管理IT资源,包括服务器、存储、和网络资源等等。通过共享资源,使用户在低投入中获益。除去线程池,还有其他比较典型的几种使用策略包括:
-
内存池(Memory Pooling):预先申请内存,提升申请内存速度,减少内存碎片。
-
连接池(Connection Pooling):预先申请数据库连接,提升申请连接的速度,降低系统的开销。
-
实例池(Object Pooling):循环使用对象,减少资源在初始化和释放时的昂贵损耗。
在了解完“是什么”和“为什么”之后,下面我们来一起深入一下线程池的内部实现原理。
2. 基本使用介绍及其相关参数和注重点
我们来先看下面两张类图
ThreadPoolExecutor
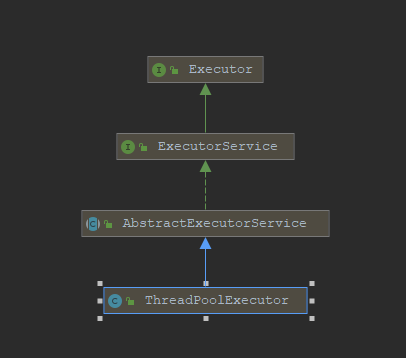
image-20210627142834199
ScheduledThreadPoolExecutor
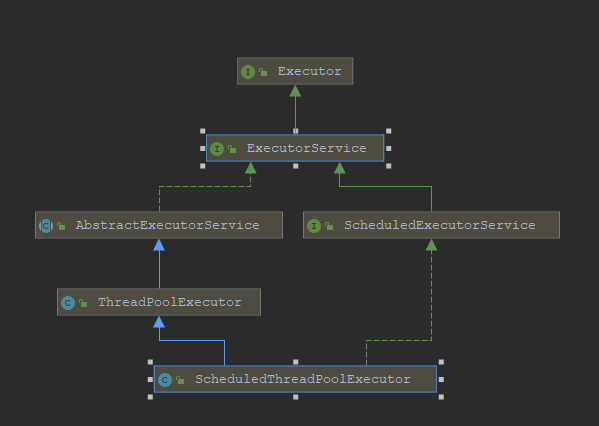
image-20210627142859123
ThreadPoolExecutor和ScheduledThreadPoolExecutor算是我们最常用的线程池类了,从上面我们可以看到这俩个最终都实现了Executor和ExecutorService这两个接口,实际上主要的接口定义都是在ExecutorService中
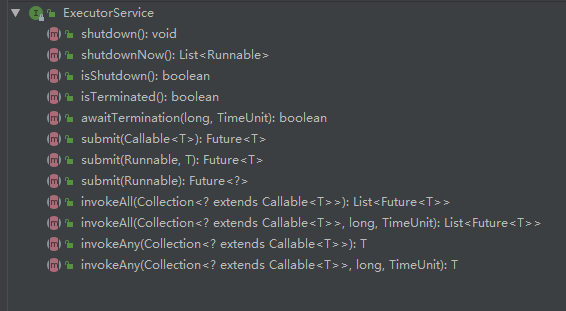
image-20210627143249342
image-20210627143331102
下面我们来着重讲解一下ThreadPoolExecutor的使用及其相关介绍
首先我们来看下它的构造方法:
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
参数说明:
-
corePoolSize:线程池核心线程数量
线程池在完成初始化之后,默认情况下,线程池中不会有任何线程,线程池会等有任务来的时候再去创建线程。核心线程创建出来后即使超出了线程保持的存活时间配置也不会销毁,核心线程只要创建就永驻了,就等着新任务进来进行处理。
-
maximumPoolSize:线程池最大线程数量
核心线程忙不过来且任务存储队列满了的情况下,还有新任务进来的话就会继续开辟线程,但是也不是任意的开辟线程数量,线程数(包含核心线程)达到
maximumPoolSize后就不会产生新线程了,就会执行拒绝策略。
-
keepAliverTime:当活跃线程数大于核心线程数时,空闲的多余线程最大存活时间
如果线程池当前的线程数多于
corePoolSize,那么如果多余的线程空闲时间超过keepAliveTime,那么这些多余的线程(超出核心线程数的那些线程)就会被回收。
-
unit:存活时间的单位
比如:
TimeUnit.MILLISECONDS、TimeUnit.SECONDS
-
workQueue:存放任务的队列,阻塞队列类型
核心线程数满了后还有任务继续提交到线程池的话,就先进入
workQueue。
workQueue通常情况下有如下选择:
LinkedBlockingQueue:无界队列,意味着无限制,其实是有限制,大小是int的最大值。也可以自定义大小。
ArrayBlockingQueue:有界队列,可以自定义大小,到了阈值就开启新线程(不会超过maximumPoolSize)。
SynchronousQueue:Executors.newCachedThreadPool();默认使用的队列。也不算是个队列,他不没有存储元素的能力。一般都采取
LinkedBlockingQueue,因为他也可以设置大小,可以取代ArrayBlockingQueue有界队列。
-
threadFactory:当线程池需要新的线程时,会用threadFactory来生成新的线程
默认采用的是
DefaultThreadFactory,主要负责创建线程。newThread()方法。创建出来的线程都在同一个线程组且优先级也是一样的。
-
handler:拒绝策略,任务量超出线程池的配置限制或执行shutdown还在继续提交任务的话,会执行handler的逻辑。
默认采用的是
AbortPolicy,遇到上面的情况,线程池将直接采取直接拒绝策略,也就是直接抛出异常。RejectedExecutionException
实际上JDK为了我们方便使用线程池,提供了一个
Executors工具来为我们快速方便的创建出线程池
Executors创建返回ThreadPoolExecutor对象的方法共有三种:
-
Executors#newCachedThreadPool => 创建可缓存的线程池
-
Executors#newSingleThreadExecutor => 创建单线程的线程池
-
Executors#newFixedThreadPool => 创建固定长度的线程池
Executors#newCachedThreadPool方法
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
CachedThreadPool是一个根据需要创建新线程的线程池
-
corePoolSize => 0,核心线程池的数量为0
-
maximumPoolSize => Integer.MAX_VALUE,可以认为最大线程数是无限的
-
keepAliveTime => 60L
-
unit => 秒
-
workQueue => SynchronousQueue
当一个任务提交时,corePoolSize为0不创建核心线程,SynchronousQueue是一个不存储元素的队列,可以理解为队里永远是满的,因此最终会创建非核心线程来执行任务。对于非核心线程空闲60s时将被回收。因为Integer.MAX_VALUE非常大,可以认为是可以无限创建线程的,在资源有限的情况下容易引起OOM异常
Executors#newSingleThreadExecutor方法
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
SingleThreadExecutor是单线程线程池,只有一个核心线程
-
corePoolSize => 1,核心线程池的数量为1
-
maximumPoolSize => 1,只可以创建一个非核心线程
-
keepAliveTime => 0L
-
unit => 毫秒
-
workQueue => LinkedBlockingQueue
当一个任务提交时,首先会创建一个核心线程来执行任务,如果超过核心线程的数量,将会放入队列中,因为LinkedBlockingQueue是长度为Integer.MAX_VALUE的队列,可以认为是无界队列,因此往队列中可以插入无限多的任务,在资源有限的时候容易引起OOM异常,同时因为无界队列,maximumPoolSize和keepAliveTime参数将无效,压根就不会创建非核心线程
Executors#newFixedThreadPool方法
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
FixedThreadPool是固定核心线程的线程池,固定核心线程数由用户传入
-
corePoolSize => 1,核心线程池的数量为1
-
maximumPoolSize => 1,只可以创建一个非核心线程
-
keepAliveTime => 0L
-
unit => 毫秒
-
workQueue => LinkedBlockingQueue
-
它和SingleThreadExecutor类似,唯一的区别就是核心线程数不同,并且由于使用的是LinkedBlockingQueue,在资源有限的时候容易引起OOM异常
因此由上面的结论,可以看出使用
Executors创建出的线程池是有可能引起内存溢出的,所以我们并不推荐甚至不允许使用Executors来创建线程池
线程池的流程运转原理
提交一个任务到线程池中,线程池的处理流程如下:
1、判断线程池里的核心线程是否都在执行任务,如果不是(核心线程空闲或者还有核心线程没有被创建)则创建一个新的工作线程来执行任务。如果核心线程都在执行任务,则进入下个流程。
2、线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。
3、判断线程池里的线程是否都处于工作状态[线程数量是否达到最大值],如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
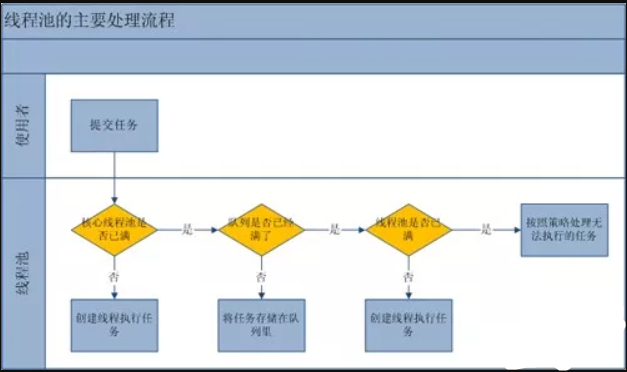
image-20210627171512964
其他的参数都比较容易理解,所以我们来着重看下拒绝策略handler这个参数,其类型为RejectedExecutionHandler,当线程池达到最大值并且线程数也达到最大值时才会工作,当队列和线程池都满了,说明线程池处于饱和状态,那么必须对新提交的任务采用一种特殊的策略来进行处理。这个策略默认配置是AbortPolicy,表示无法处理新的任务而抛出异常。JAVA提供了4种策略:
-
AbortPolicy:直接抛出异常 -
CallerRunsPolicy:只用调用所在的线程运行任务 -
DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。 -
DiscardPolicy:不处理,丢弃掉。

image-20210627174730111
当然我们上面也说了
handler是一个RejectedExecutionHandler的类型,所以我们也可以实现这个接口来创建一个我们自己的拒绝策略
自定义拒绝策略
拒绝策略是一个接口,其设计如下:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
用户可以通过实现这个接口去定制拒绝策略,在手动配置线程池时的构造函数传入或者通过方法setRejectedExecutionHandler 在线程池运行期间改变拒绝任务的策略。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//省略其他代码
this.handler = handler;
}
public void setRejectedExecutionHandler(RejectedExecutionHandler handler) {
if (handler == null)
throw new NullPointerException();
this.handler = handler;
}
public class AbortPolicyWithReport extends ThreadPoolExecutor.AbortPolicy {
protected static final Logger logger = LoggerFactory.getLogger(AbortPolicyWithReport.class);
private final String threadName;
private final URL url;
private static volatile long lastPrintTime = 0;
private static Semaphore guard = new Semaphore(1);
public AbortPolicyWithReport(String threadName, URL url) {
this.threadName = threadName;
this.url = url;
}
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
String msg = String.format("Thread pool is EXHAUSTED!" +
" Thread Name: %s, Pool Size: %d (active: %d, core: %d, max: %d, largest: %d), Task: %d (completed: %d)," +
" Executor status:(isShutdown:%s, isTerminated:%s, isTerminating:%s), in %s://%s:%d!",
threadName, e.getPoolSize(), e.getActiveCount(), e.getCorePoolSize(), e.getMaximumPoolSize(), e.getLargestPoolSize(),
e.getTaskCount(), e.getCompletedTaskCount(), e.isShutdown(), e.isTerminated(), e.isTerminating(),
url.getProtocol(), url.getIp(), url.getPort());
logger.warn(msg);
dumpJStack();
throw new RejectedExecutionException(msg);
}
private void dumpJStack() {
//......
}
}
拒绝策略的执行
从调用execute()方法,经过一系列判断,当该任务被判断需要被被拒绝后,会接着执行reject(command) ,最终就会执行具体实现RejectedExecutionHandler接口的rejectedExecution(r,executor) 方法了。
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
3. 线程池结合SpringBoot实战(结合项目)
SpringBoot使用线程池我们常见的有两种方式:
使用默认的线程池
@Async使用自定义的线程池
方式一:通过@Async注解调用
第一步:在Application启动类上面加上@EnableAsync
@SpringBootApplication
@EnableAsync
public class ThreadpoolApplication {
public static void main(String[] args) {
SpringApplication.run(ThreadpoolApplication.class, args);
}
}
第二步:在需要异步执行的方法上加上@Async注解
@Service
public class AsyncTest {
protected final Logger logger = LoggerFactory.getLogger(this.getClass());
@Async
public void hello(String name){
//这里使用logger 方便查看执行的线程是什么
logger.info("异步线程启动 started."+name);
}
}
第三步:测试类进行测试验证
@Autowired
AsyncTest asyncTest;
@Test
void contextLoads() throws InterruptedException {
asyncTest.hello("afsasfasf");
//一定要休眠 不然主线程关闭了,子线程还没有启动
Thread.sleep(1000);
}
查看打印的日志:
INFO 2276 --- [ main] c.h.s.t.t.ThreadpoolApplicationTests : Started ThreadpoolApplicationTests in 3.003 seconds (JVM running for 5.342)
INFO 2276 --- [ task-1] c.h.s.threadpool.threadpool.AsyncTest : 异步线程启动 started.afsasfasf
可以清楚的看到新开了一个task-1的线程执行任务。验证成功!!!
***注意:***@Async注解失效常景
方式二:使用自定义的线程池
在默认配置信息里面是没有线程池的拒绝策略设置的方法的,如果需要更换拒绝策略就需要自定义线程池,并且如果项目当中需要多个自定义的线程池,又要如何进行管理呢?
自定义Configuration
第一步:创建一个ThreadPoolConfig 先只配置一个线程池,并设置拒绝策略为CallerRunsPolicy
@Configuration
public class ThreadPoolConfig {
@Bean("taskExecutor")
public Executor taskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
//设置线程池参数信息
taskExecutor.setCorePoolSize(10);
taskExecutor.setMaxPoolSize(50);
taskExecutor.setQueueCapacity(200);
taskExecutor.setKeepAliveSeconds(60);
taskExecutor.setThreadNamePrefix("myExecutor--");
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
//修改拒绝策略为使用当前线程执行
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//初始化线程池
taskExecutor.initialize();
return taskExecutor;
}
}
然后执行之前写的测试代码发现,使用的线程池已经变成自定义的线程池了。
INFO 12740 --- [ myExecutor--2] c.h.s.t.t.ThreadpoolApplicationTests : threadPoolTaskExecutor 创建线程
INFO 12740 --- [ myExecutor--1] c.h.s.threadpool.threadpool.AsyncTest : 异步线程启动 started.async注解创建
第二步:如果配置有多个线程池,该如何指定线程池呢?
@Configuration
public class ThreadPoolConfig {
@Bean("taskExecutor")
public Executor taskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
//设置线程池参数信息
taskExecutor.setCorePoolSize(10);
taskExecutor.setMaxPoolSize(50);
taskExecutor.setQueueCapacity(200);
taskExecutor.setKeepAliveSeconds(60);
taskExecutor.setThreadNamePrefix("myExecutor--");
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
//修改拒绝策略为使用当前线程执行
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//初始化线程池
taskExecutor.initialize();
return taskExecutor;
}
@Bean("poolExecutor")
public Executor poolExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
//设置线程池参数信息
taskExecutor.setCorePoolSize(10);
taskExecutor.setMaxPoolSize(50);
taskExecutor.setQueueCapacity(200);
taskExecutor.setKeepAliveSeconds(60);
taskExecutor.setThreadNamePrefix("myExecutor2--");
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
//修改拒绝策略为使用当前线程执行
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//初始化线程池
taskExecutor.initialize();
return taskExecutor;
}
@Bean("taskPoolExecutor")
public Executor taskPoolExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
//设置线程池参数信息
taskExecutor.setCorePoolSize(10);
taskExecutor.setMaxPoolSize(50);
taskExecutor.setQueueCapacity(200);
taskExecutor.setKeepAliveSeconds(60);
taskExecutor.setThreadNamePrefix("myExecutor3--");
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
//修改拒绝策略为使用当前线程执行
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//初始化线程池
taskExecutor.initialize();
return taskExecutor;
}
}
执行测试类,直接报错说找到多个类,不知道加载哪个类:
No qualifying bean of type 'org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor' available: expected single matching bean but found 3: taskExecutor,taskPoolExecutor
由于测试类当中是这样自动注入的:
@Autowired
ThreadPoolTaskExecutor threadPoolTaskExecutor;
考虑到@Autowired 以及@Resource两个注入时的存在多个类如何匹配问题,然后发现只要我们在注入时指定具体的bean就会调用对应的线程池!!!
即修改测试类如下:
@Autowired
AsyncTest asyncTest;
@Autowired
ThreadPoolTaskExecutor poolExecutor; //会去匹配 @Bean("poolExecutor") 这个线程池
@Test
void contextLoads() throws InterruptedException {
asyncTest.hello("async注解创建");
//一定要休眠 不然主线程关闭了,子线程还没有启动
poolExecutor.submit(new Thread(()->{
logger.info("threadPoolTaskExecutor 创建线程");
}));
Thread.sleep(1000);
}
最后得到如下信息:
INFO 13636 --- [ myExecutor2--1] c.h.s.t.t.ThreadpoolApplicationTests : threadPoolTaskExecutor 创建线程 INFO 13636 --- [ myExecutor--1] c.h.s.threadpool.threadpool.AsyncTest : 异步线程启动 started.async注解创建
注意:如果是使用的@Async注解,只需要在注解里面指定bean的名称就可以切换到对应的线程池去了。如下所示:
@Async("taskPoolExecutor")
public void hello(String name){
logger.info("异步线程启动 started."+name);
}
注意:如果有多个线程池,但是在@Async注解里面没有指定的话,会默认加载第一个配置的线程池
submit和executor区别
execute和submit都属于线程池的方法,execute只能提交Runnable类型的任务,而submit既能提交Runnable类型任务也能提交Callable类型任务。
execute会直接抛出任务执行时的异常,submit会吃掉异常,可通过Future的get方法[会阻塞]将任务执行时的异常重新抛出。
execute所属顶层接口是Executor,submit所属顶层接口是ExecutorService,实现类ThreadPoolExecutor重写了execute方法,抽象类AbstractExecutorService重写了submit方法。
submit和execute由于参数不同有四种实现形式,如下所示,本文主要研究这四种形式在各自使用场景下的区别和联系
这种提交的方式会返回一个Future对象,这个Future对象代表这线程的执行结果
当主线程调用Future的get方法的时候会获取到从线程中返回的结果数据。
如果在线程的执行过程中发生了异常,get会获取到异常的信息。
<T> Future<T> submit(Callable<T> task);
当线程正常结束的时候调用Future的get方法会返回result对象,当线程抛出异常的时候会获取到对应的异常的信息。
<T> Future<T> submit(Runnable task, T result);
提交一个Runable接口的对象,这样当调用get方法的时候,如果线程执行成功会直接返回null,如果线程执行异常会返回异常的信息
Future<?> submit(Runnable task);
void execute(Runnable command);
execute提交的方式只能提交一个Runnable的对象,且该方法的返回值是void,也即是提交后如果线程运行后,和主线程就脱离了关系了,当然可以设置一些变量来获取到线程的运行结果。并且当线程的执行过程中抛出了异常通常来说主线程也无法获取到异常的信息的,只有通过ThreadFactory主动设置线程的异常处理类才能感知到提交的线程中的异常信息。
4. 线程池原理
4.1 主要介绍线程池中线程复用原理
对于线程池的复用原理,可以简单的用一句话概括:创建指定数量的线程并开启,判断当前是否有任务执行,如果有则执行任务。再通俗易懂一些:创建指定数量的线程并运行,重写run方法,循环从任务队列中取Runnable对象,执行Runnable对象的run方法。
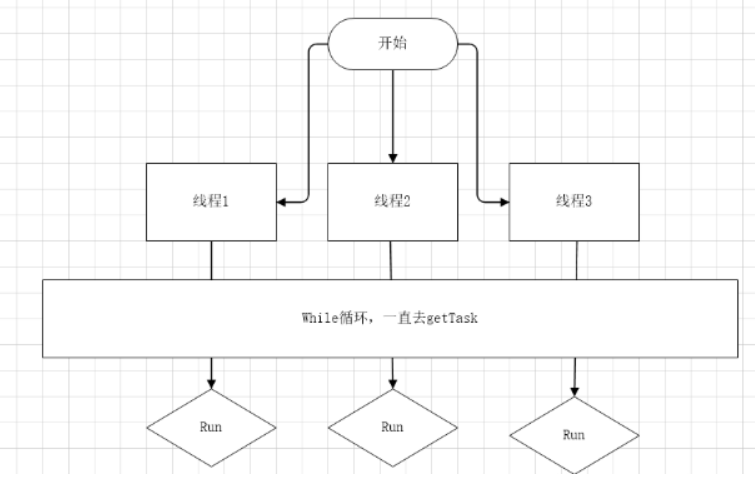
image-20210702000757740
接下来开始手写线程池吧,注意是简易线程池,跟JDK自带的线程池无法相提并论,在这里我省略了判断当前线程数有没有大于核心线程数的步骤,简化成直接从队列中取任务,对于理解原理来说已然足矣,代码如下:
public class MyExecutorService {
/**
* 一直保持运行的线程
*/
private List<WorkThread> workThreads;
/*
* 任务队列容器
*/
private BlockingDeque<Runnable> taskRunables;
/*
* 线程池当前是否停止
*/
private volatile boolean isWorking = true;
public MyExecutorService(int workThreads, int taskRunables) {
this.workThreads = new ArrayList<>();
this.taskRunables = new LinkedBlockingDeque<>(taskRunables);
//直接运行核心线程
for (int i = 0; i < workThreads; i++) {
WorkThread workThread = new WorkThread();
workThread.start();
this.workThreads.add(workThread);
}
}
/**
* WorkThread累,线程池的任务类,类比JDK的worker
*/
class WorkThread extends Thread {
@Override
public void run() {
while (isWorking || taskRunables.size() != 0) {
//获取任务
Runnable task = taskRunables.poll();
if (task != null) {
task.run();
}
}
}
}
//执行execute,jdk中会存在各种判断,这里省略了
public void execute(Runnable runnable) {
//把任务加入队列
taskRunables.offer(runnable);
}
//停止线程池
public void shutdown() {
this.isWorking = false;
}
}
测试
//测试自定义的线程池
public static void main(String[] args) {
MyExecutorService myExecutorService = new MyExecutorService(3, 6);
//运行8次
for (int i = 0; i < 8; i++) {
myExecutorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "task begin");
});
}
myExecutorService.shutdown();
}
总结
通过以上分析并手写线程池,我们应该已经基本理解了线程池的复用机制原理,实际上JDK的实现机制远比我们手写的要复杂的多,主要有以下两点,可以让我们进一步加深理解:
-
当有新任务来的时候,首先判断当前的线程数有没有超过核心线程数,如果没超过则直接新建一个线程来执行新的任务,如果超过了则判断缓存队列有没有满,没满则将新任务放进缓存队列中,如果队列已满并且线程池中的线程数已经达到了指定的最大线程数,那就根据相应的策略拒绝任务,默认为抛异常。
-
当缓存队列中的任务都执行完毕后,线程池中的线程数如果大于核心线程数并且已经超过了指定的存活时间(存活时间通过队列的poll方法传入,如果指定时间内没有获取到任务,则break退出,线程运行结束),就销毁多出来的线程,直到线程池中的线程数等于核心线程数。此时剩余的线程会一直处于阻塞状态,等待新的任务到来。
有兴趣可以看这块的源码,大致的思想就是:
首先,线程池会有一个管理任务的队列,这个任务队列里存放的就是各种任务,线程池会一直不停循环的去查看消息队里有没有接到任务,如果没有,则继续循环,如果有了则开始创建线程,如果给这个线程池设定的容量是10个线程,那么当有任务的时候就会调用创建线程的函数方法去根据当前任务总数量依次创建线程(这里创建线程的函数方法都是你提前些好了的),线程中会写好循环获取任务队列里任务的逻辑、判断是否销毁该线程的逻辑、进入等待的逻辑,这样线程一旦创建出来就会循环的去查询任务队列里的任务,拿到任务后就执行,执行任务完毕后判断是否销毁该线程,如果不销毁就进入等待(sleep),等待时间过后继续查询消息是否有任务,如此循环,直到逻辑判断需要销毁该线程为止(一般都是根据设定时间去判断是否销毁,例如在线程创建的时候设置一个计时器去控制,如果180秒都没有接到新的任务,则销毁该线程) 。






![[计算机图形学]材质与外观(前瞻预习/复习回顾)](https://img-blog.csdnimg.cn/ba749dca309e42a6a4960b009787bbeb.png)