大家好,我是微学AI,今天教你们本地CPU环境部署清华大ChatGLM-6B模型,利用量化模型,每个人都能跑动大模型。ChatGLM-6B是一款出色的中英双语对话模型,拥有超过62亿个参数,可高效地处理日常对话场景。与GLM-130B模型相比,ChatGLM-6B在对话场景处理能力方面表现更加卓越。此外,在使用体验方面,ChatGLM-6B采用了模型量化技术和本地部署技术,为用户提供更加便利和灵活的使用方式。值得一提的是,该模型还能够在单张消费级显卡上顺畅运行,速度较快,是一款非常实用的对话模型。
ChatGLM-6B是清华开发的中文对话大模型的小参数量版本,目前已经开源了,可以单卡部署在个人电脑上,利用 INT4 量化还可以最低部署到 6G 显存的电脑上,在 CPU 也可以运行起来的。
项目地址:mirrors / THUDM / chatglm-6b · GitCode
第1步:下载:
git clone https://gitcode.net/mirrors/THUDM/chatglm-6b.git第2步:进入ChatGLM-6B-main目录下,安装相关依赖
pip install -r requirements.txt其中 torch安装CPU版本即可。
第3步:打开ChatGLM-6B-main目录的web_demo.py文件,源代码:
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
这个是在GPU版本下的代码,现在改为CPU版本下的代码:
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).float()
model = model.eval()
模型下载改成THUDM/chatglm-6b-int4,也就是int4量化版本。模型量化到int4是一种将神经网络模型中的参数从浮点数格式调整为4位精度的整数格式的技术,可以显著提高硬件设备的效率和速度,并且适用于需要在低功耗设备上运行的场景。
INT4量化的预训练文件下载地址:https://huggingface.co/THUDM/chatglm-6b-int4/tree/main
第4步:kernel的编译
CPU版本的安装还需要安装好C/C++的编译环境。这里大家可以安装TDM-GCC。
下载地址:https://jmeubank.github.io/tdm-gcc/,大家选择选取TDM-GCC 10.3.0 release下载安装。特别注意:安装的时候在选项gcc选项下方,勾选openmp,这个很重要,踩过坑,直接安装的话后续会报错。
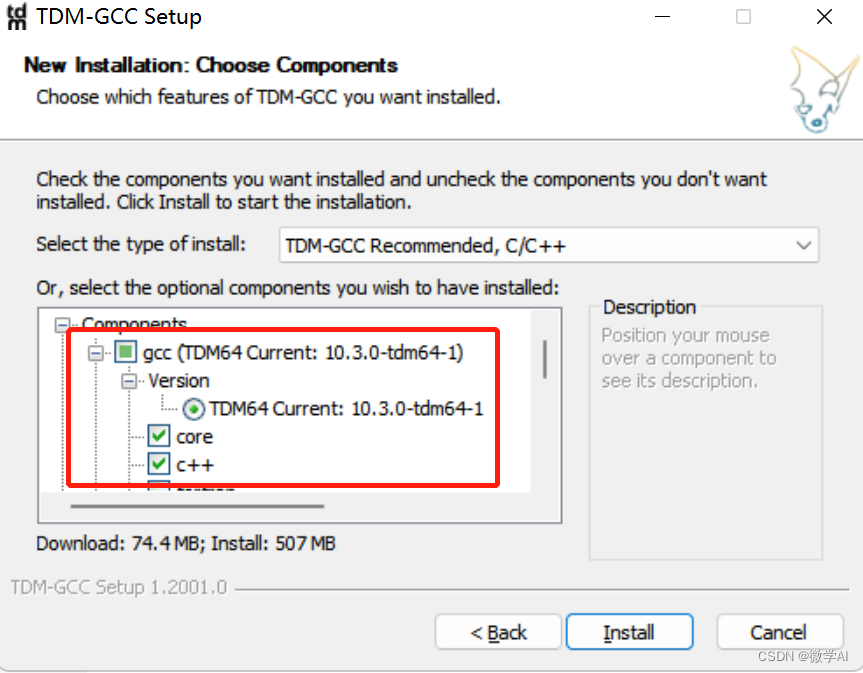
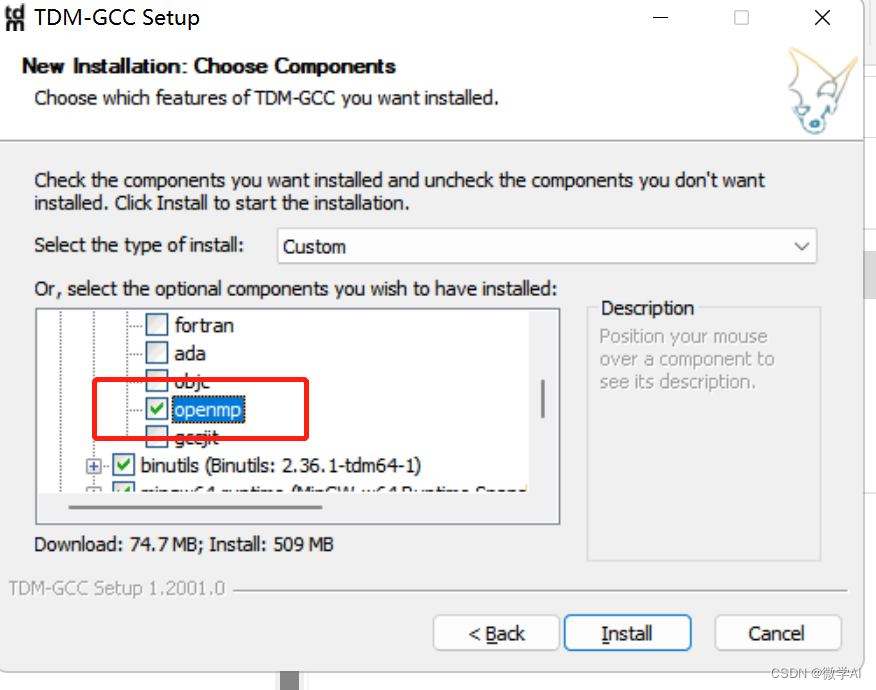
安装完在cmd中运行”gcc -v”测试是否成功即可。
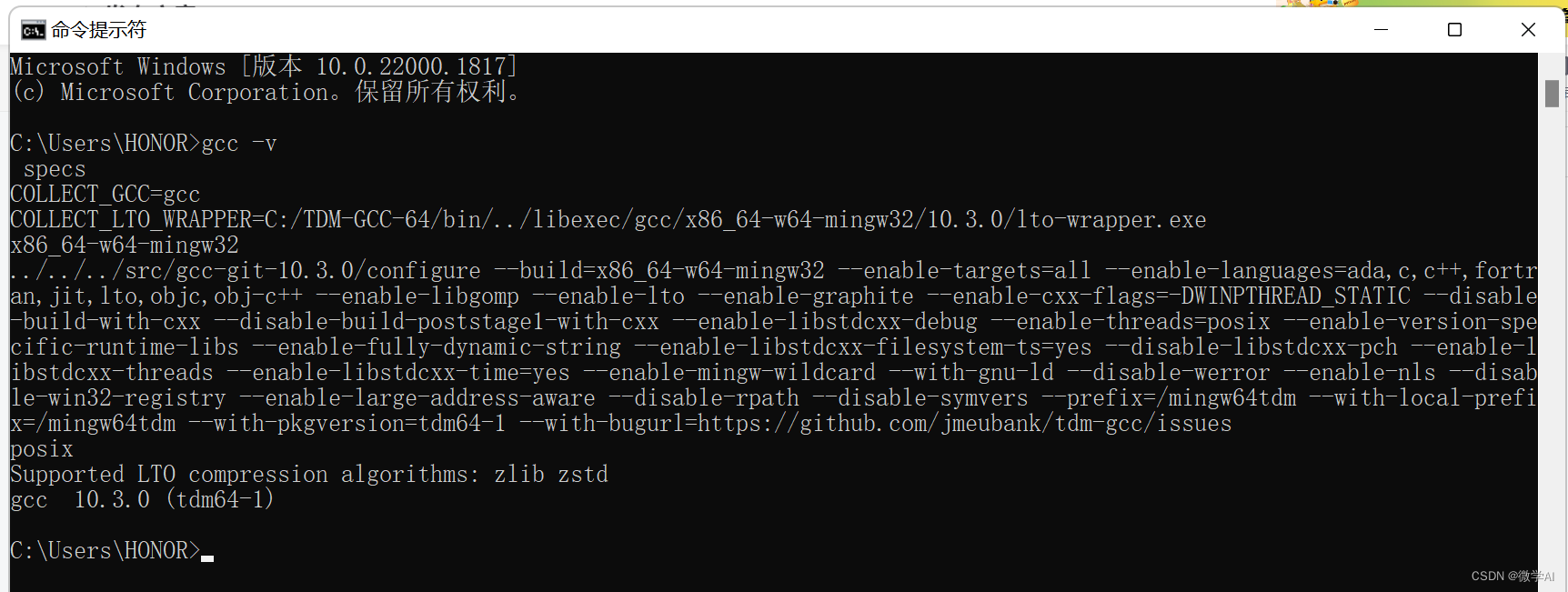
安装gcc的目的是为了编译c++文件,quantization_kernels.c和quantization_kernels_parallel.c
quantization_kernels.c文件:
void compress_int4_weight(void *weight, void *out, int n, int m)
{
for(int i=0;i<n*m;i++)
{
(*(unsigned char*)(out)) = ((*(unsigned char*)(weight)) << 4);
weight += sizeof(char);
(*(unsigned char*)(out)) |= ((*(unsigned char*)(weight)) & 15);
weight += sizeof(char);
out += sizeof(char);
}
}
void extract_int8_weight_to_float(void *weight, void *scale_list, void *out, int n, int m)
{
for(int i=0;i<n;i++)
for(int j=0;j<m;j++)
(*(float*)(out + sizeof(float) * (i * m + j))) = (*(float*)(scale_list + sizeof(float) * i)) * (*(char*)(weight + sizeof(char) * (i * m + j)));
}
void extract_int4_weight_to_float(void *weight, void *scale_list, void *out, int n, int m)
{
for(int i=0;i<n;i++)
{
for(int j=0;j<m;j++)
{
(*(float*)(out)) = (*(float*)(scale_list)) * ((*(char*)(weight)) >> 4);
out += sizeof(float);
(*(float*)(out)) = (*(float*)(scale_list)) * (((char)((*(unsigned char*)(weight)) << 4))>> 4);
out += sizeof(float);
weight += sizeof(char);
}
scale_list += sizeof(float);
}
}以上C++程序对于每个8位的输入权重值,都会被压缩成一个4位的输出权重值,并存储到指定的输出数组中。这种权重量化方式可以有效减小模型的内存占用,提高模型的推理速度。
第5步:运行web_demo.py文件
注意:如果大家在运行中遇到了错误提示,说明两个文件编译出问题。我们可以手动去编译这两个文件:即在上面下载的D:..\chatglm-6b-int4本地目录下进入cmd,运行两个编译命令:
gcc -fPIC -pthread -fopenmp -std=c99 quantization_kernels.c -shared -o quantization_kernels.so
gcc -fPIC -pthread -fopenmp -std=c99 quantization_kernels_parallel.c -shared -o quantization_kernels_parallel.so没有报错说明运行成功,目录下看到下面两个新的文件:quantization_kernels_parallel.so和quantization_kernels.so。说明编译成功,后面我们手动载入,这里要多加一行代码
model = model.quantize(bits=4, kernel_file="D:..\\chatglm-6b-int4\\quantization_kernels.so")如果原来代码没有错可以去掉这行。
第6步:web_demo.py文件运行成功

出现地址就大功告成了。
第7步:测试问题
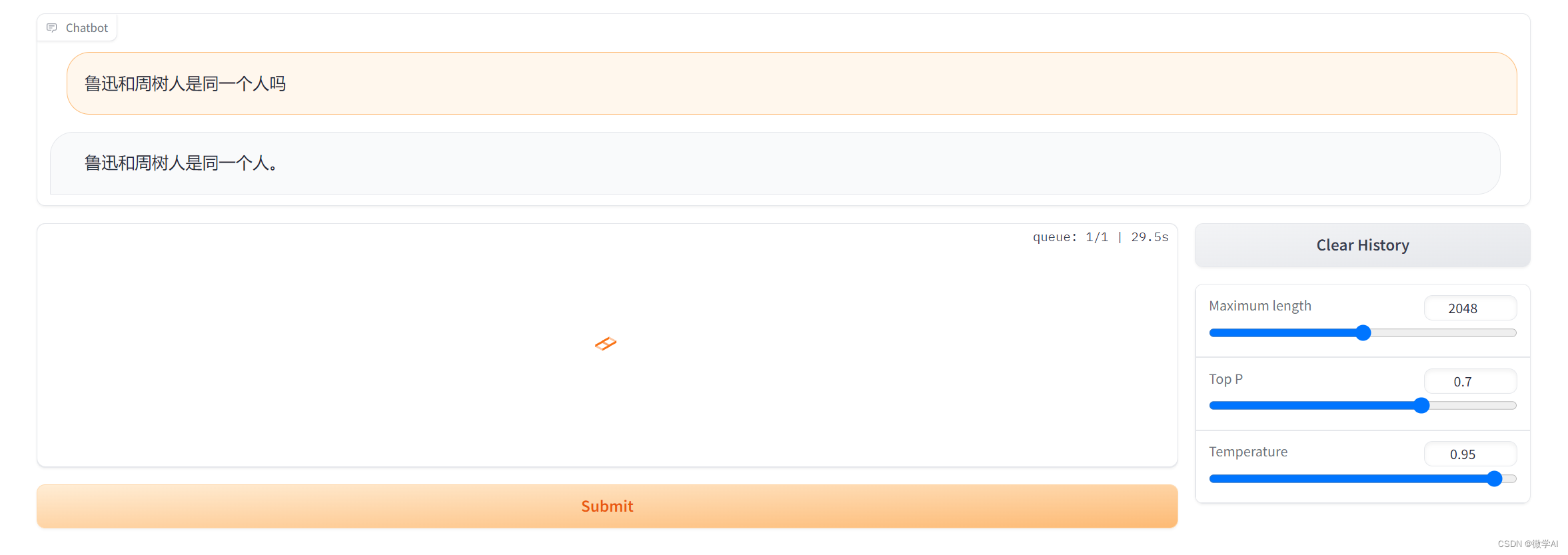
1.鲁迅和周树人是同一个人吗?
ChatGLM的结果:
ChatGPT的结果:

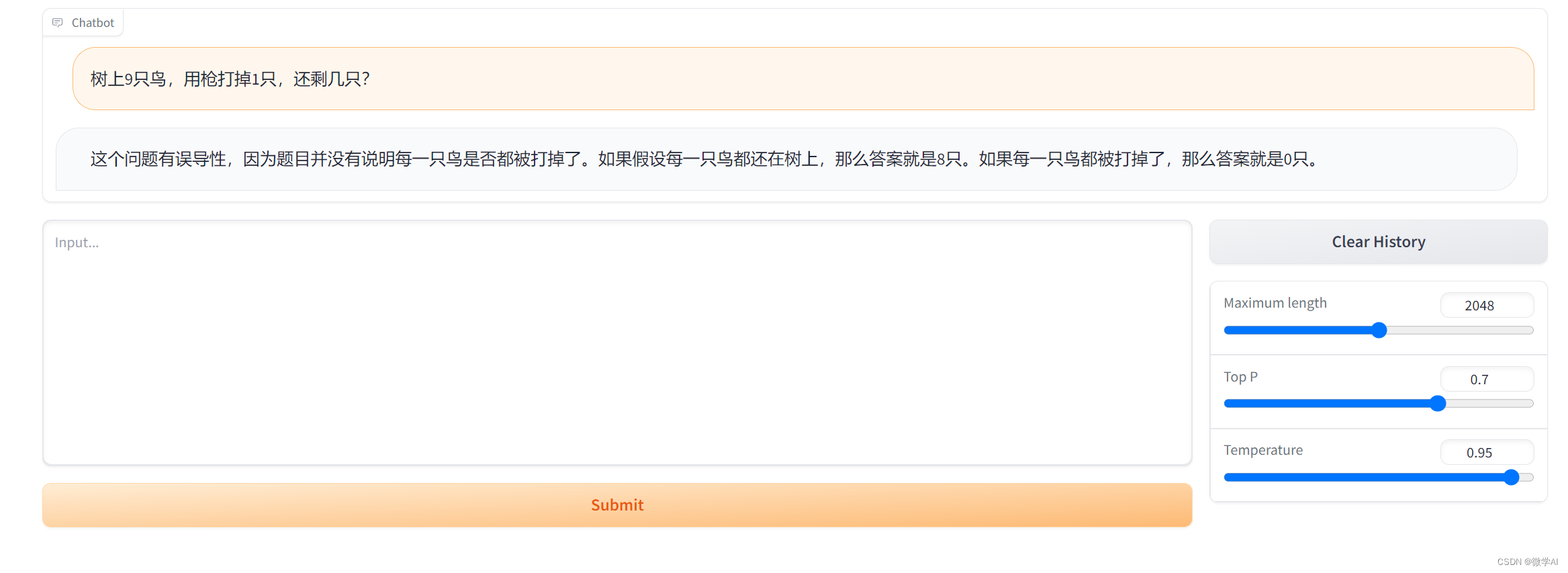
2.树上9只鸟,用枪打掉1只,还剩几只?
ChatGLM的结果:
ChatGPT的结果:

ChatGLM在某些中文问题和常识问题上超过ChatGPT,但是总体上是不如ChatGPT,他在总结任务上,代码编写上不如ChatGPT,总体达到ChatGPT的80%左右,可以做简单的任务。