0 简介
论文:A Simple Framework for Contrastive Learning of Visual Representations
代码:https://github.com/google-research/simclr
发表:2020年发表在ICML会议上
1 核心思想
如何构建对比学习的比较对象?本文按如下方式进行构建:
- 数据增强:输入 x x x,增强为 x ~ i \tilde{x}_i x~i( t ∼ T t \sim \mathcal{T} t∼T)和 x ~ j \tilde{x}_j x~j( t ′ ∼ T t^\prime \sim \mathcal{T} t′∼T),获得两个相关的视角,这两个相关的视角的距离越近越好;
- 和其他图片增强的视角进行对比:
x
x
x的视角和其他图片增强得到的视角距离越远越好。
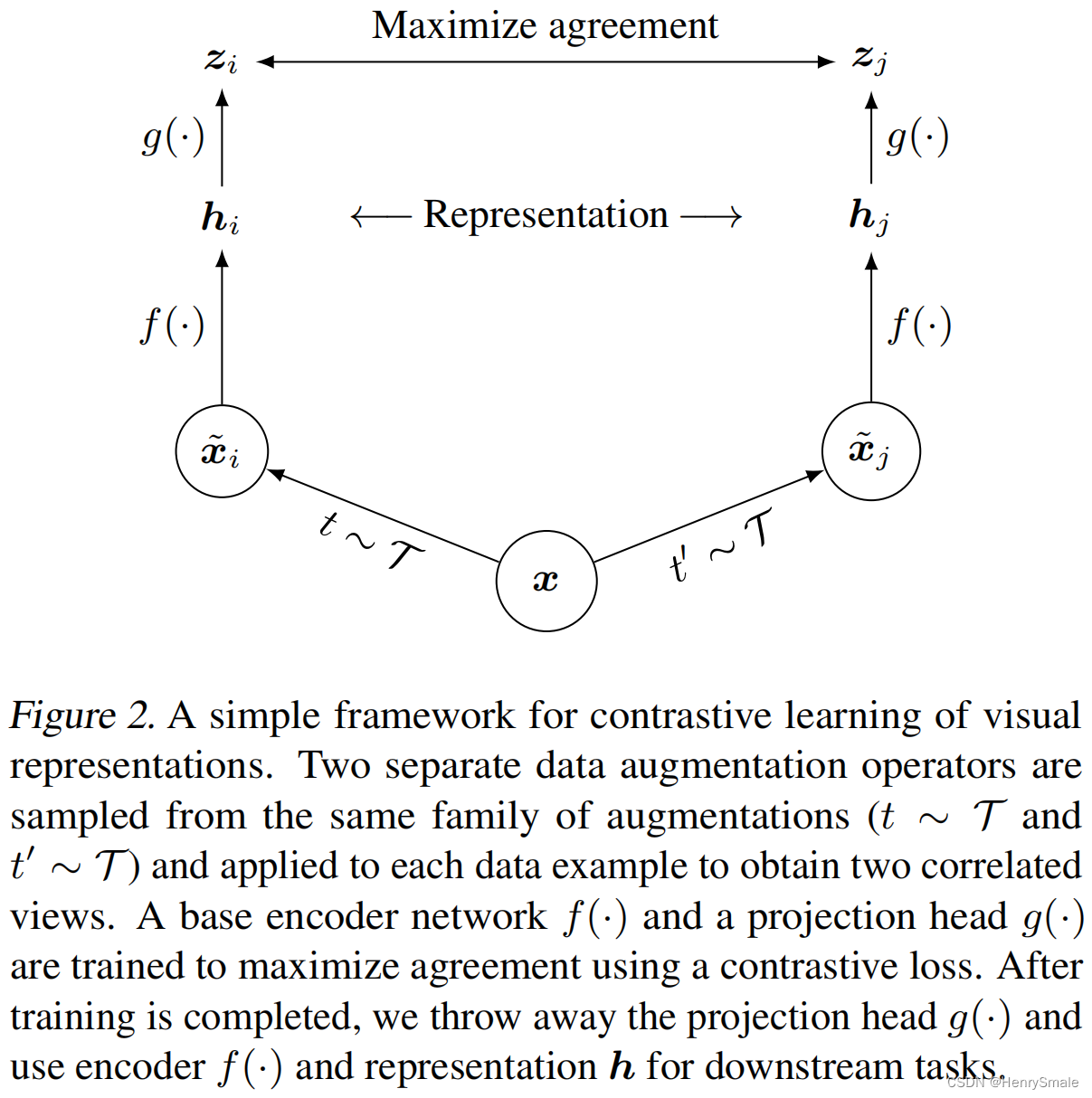
1.1 总体步骤
具体步骤如下:
- 输入图像 x x x,对其进行两种不同增强得到两张新图片 x ~ i \tilde{x}_i x~i( t ∼ T t \sim \mathcal{T} t∼T)和 x ~ j \tilde{x}_j x~j( t ′ ∼ T t^\prime \sim \mathcal{T} t′∼T);
- 将两张新图片输入ResNet,即 f ( ⋅ ) f(\cdot) f(⋅)提取特征,得到 h i , h j h_i, h_j hi,hj;
- 两个特征向量经过MLP网络,即 g ( ⋅ ) g(\cdot) g(⋅)处理,得到 z i , z j z_i, z_j zi,zj。
假设batch size大小为
N
N
N,经过数据增强,可以得到
2
N
2N
2N张图像。
SimCLR在对比学习时,需要正负例:
- z i , z j z_i, z_j zi,zj构成正例;
- z i z_i zi与batch size中其他图像(包括数据增强后的图像)的特征向量组成负例对,因此一张图片将存在1个正例对, 2 N − 2 2N − 2 2N−2个负例对。
一张图片的损失函数为:
ℓ
i
,
j
=
−
log
exp
(
sim
(
z
i
,
z
j
)
/
τ
)
∑
k
=
1
2
N
1
[
k
≠
i
]
exp
(
sim
(
z
i
,
z
k
)
/
τ
)
\ell_{i, j}=-\log \frac{\exp \left(\operatorname{sim}\left(\boldsymbol{z}_i, \boldsymbol{z}_j\right) / \tau\right)}{\sum_{k=1}^{2 N} \mathbb{1}_{[k \neq i]} \exp \left(\operatorname{sim}\left(\boldsymbol{z}_i, \boldsymbol{z}_k\right) / \tau\right)}
ℓi,j=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
其中
sim
(
z
i
,
z
j
)
\operatorname{sim}\left(\boldsymbol{z}_i, \boldsymbol{z}_j\right)
sim(zi,zj)表示余弦相似度,
1
[
k
≠
i
]
∈
{
0
,
1
}
\mathbb{1}_{[k \neq i]} \in \{0, 1\}
1[k=i]∈{0,1},当
k
≠
i
k \neq i
k=i等于1,
k
=
=
i
k == i
k==i等于0,
τ
\tau
τ为温度系数。
2
N
2N
2N张图像的损失函数之和求平均,得到最终的损失函数:
L
=
1
2
N
∑
k
=
1
N
[
ℓ
(
2
k
−
1
,
2
k
)
+
ℓ
(
2
k
,
2
k
−
1
)
]
.
\mathcal{L} = \frac{1}{2N} \sum_{k = 1}^{N}\left[\ell(2k-1, 2k) + \ell(2k, 2k-1)\right].
L=2N1k=1∑N[ℓ(2k−1,2k)+ℓ(2k,2k−1)].
1.2 增强图片的方式
- 随机裁剪(random cropping);
- 随机颜色失真(random color distortions);
- 随机高斯模糊(random Gaussian blur)。

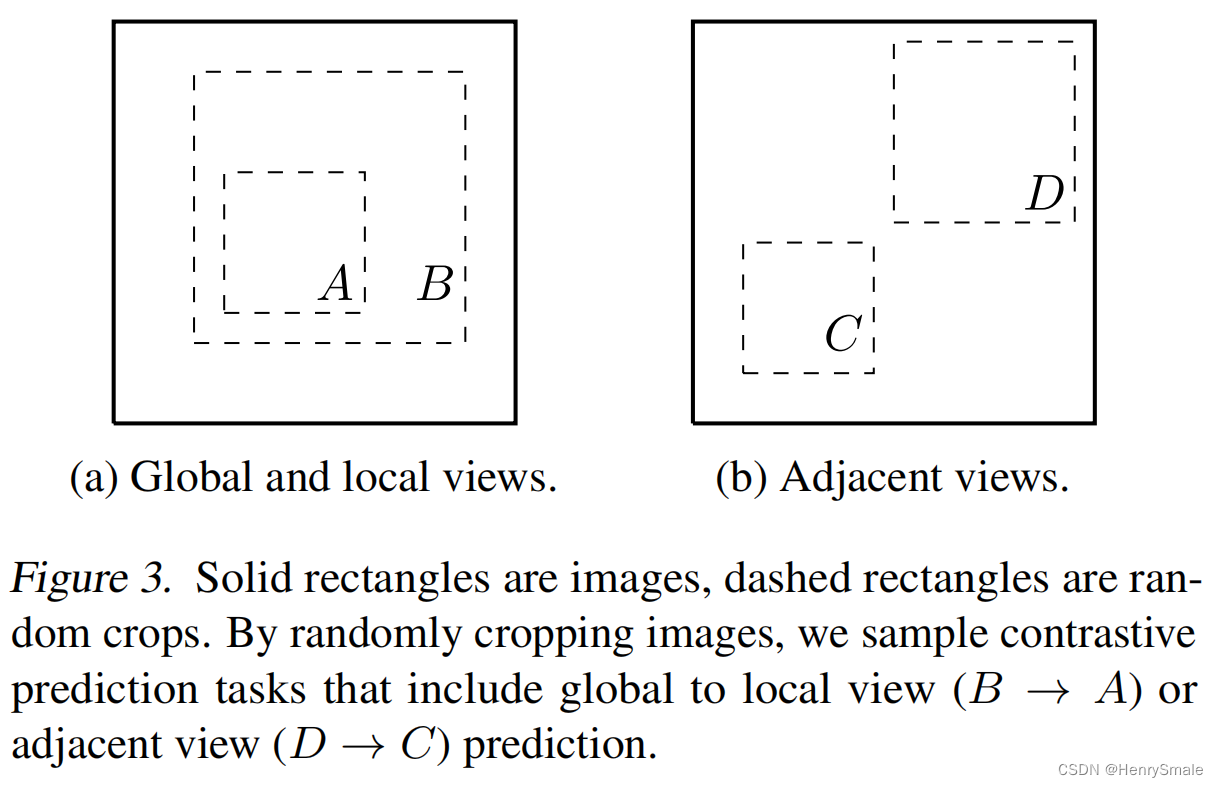
实矩形是原始图像,虚线矩形是随机裁剪。通过随机裁剪图像,我们采样对比预测任务,包括全局到局部视图( B → A B \rightarrow A B→A)或相邻视图( D → C D \rightarrow C D→C)预测。
1.2 特征提取
h
i
=
f
(
x
~
i
)
=
ResNet
(
x
~
i
)
\boldsymbol{h}_{i}=f\left(\tilde{\boldsymbol{x}}_{i}\right)=\operatorname{ResNet}\left(\tilde{\boldsymbol{x}}_{i}\right)
hi=f(x~i)=ResNet(x~i)
其中
h
i
∈
R
d
\boldsymbol{h}_{i} \in \mathbb{R}^d
hi∈Rd。
z
i
=
g
(
h
i
)
=
W
(
2
)
σ
(
W
(
1
)
h
i
)
\boldsymbol{z}_{i}=g\left(\boldsymbol{h}_{i}\right)=W^{(2)} \sigma\left(W^{(1)} \boldsymbol{h}_{i}\right)
zi=g(hi)=W(2)σ(W(1)hi)
其中
σ
\sigma
σ就是一个ReLU非线性操作。
2 具体算法

总体分为三个重要的过程:
- 数据增强,通过两个增强函数操作,图片成对存储 [ ( x ~ 1 , x ~ 2 ) , ( x ~ 3 , x ~ 4 ) , … , ( x ~ 2 k − 1 , x ~ 2 k ) , … , ( x ~ 2 N − 1 , x ~ 2 N ) [(\tilde{x}_1, \tilde{x}_2), (\tilde{x}_3, \tilde{x}_4), \dots, (\tilde{x}_{2k-1}, \tilde{x}_{2k}), \dots, (\tilde{x}_{2N-1}, \tilde{x}_{2N}) [(x~1,x~2),(x~3,x~4),…,(x~2k−1,x~2k),…,(x~2N−1,x~2N);
- 特征提取,经过ResNet(对应
f
(
⋅
)
f(\cdot)
f(⋅))操作和MLP(对应
g
(
⋅
)
g(\cdot)
g(⋅))操作后,得到特征向量组
[
(
z
1
,
z
2
)
,
(
z
3
,
z
4
)
,
…
,
(
z
2
k
−
1
,
z
2
k
)
,
…
,
(
z
2
N
−
1
,
z
2
N
)
[(z_1, z_2),(z_3, z_4), \dots, (z_{2k-1}, z_{2k}), \dots, (z_{2N-1}, z_{2N})
[(z1,z2),(z3,z4),…,(z2k−1,z2k),…,(z2N−1,z2N)

- 对比学习,先是
x
~
2
k
−
1
\tilde{x}_{2k-1}
x~2k−1和其它图片进行对比学习,然后是
x
~
2
k
\tilde{x}_{2k}
x~2k和其它图片进行对比学习
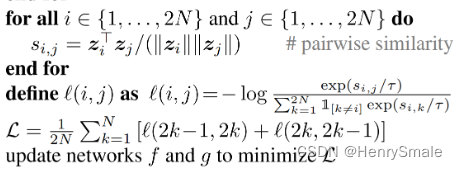
3 实验
本文的实验分析非常有用,讨论了模型在什么情况下更有效,有利于读者选择合适的参数。
3.1 数据增强方式对性能的影响
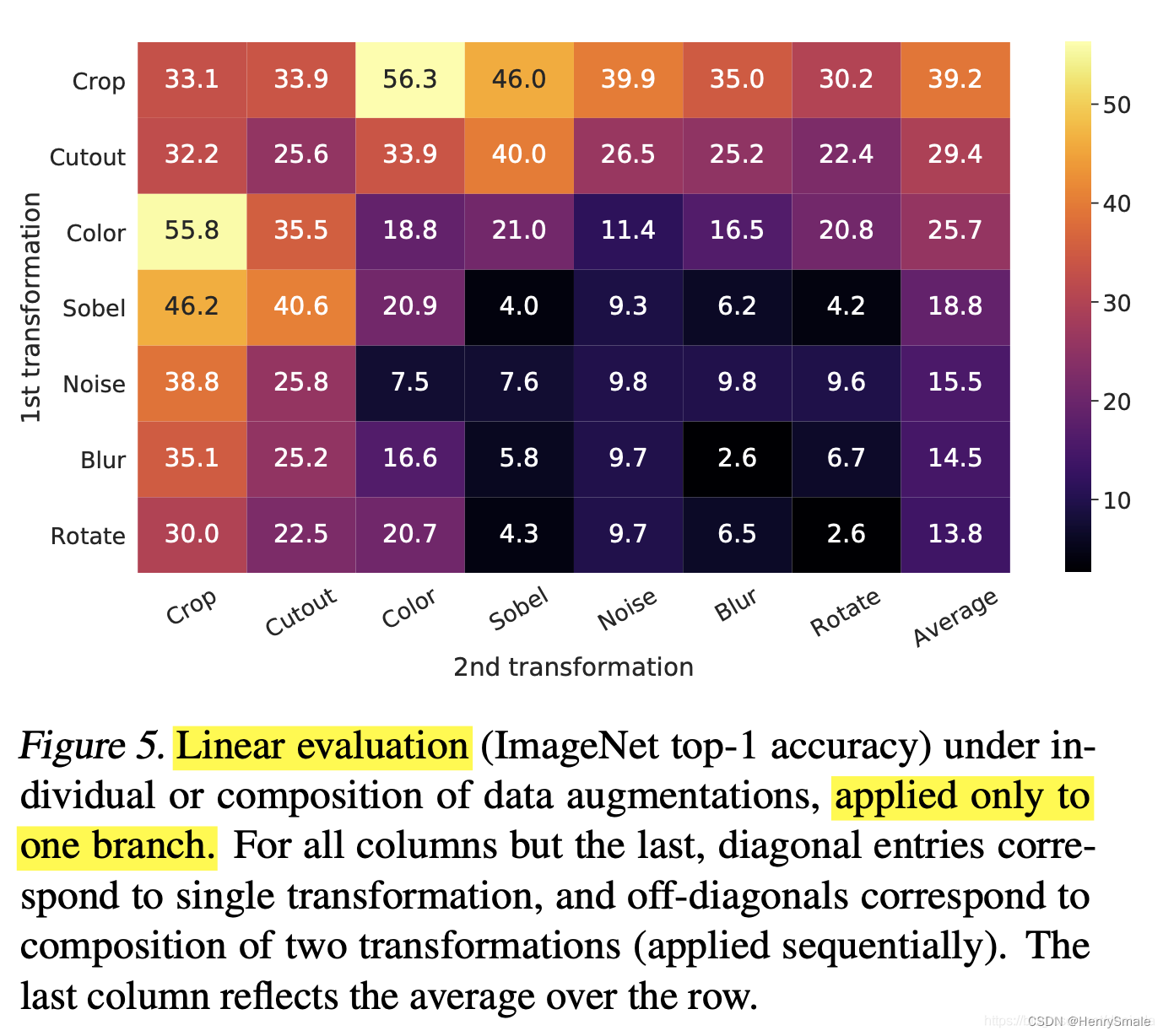
【问】:怎么理解这个图?
【答】:以左上角的33.1为例,第一次数据增强采用Crop方法,第二次数据增强采用Crop方法;以左上角33.9为例,第一次数据增强采用Crop方法,第二次数据增强采用Cutout方法。
得到如下三个结论:
- 单独使用一种数据增强,对比学习的效果会很差;
- 效果最好的组合:第一次数据增强采用Crop方法,第二次数据增强采用Color方法,得到的精度为56.3;效果次好的组合:第一次数据增强采用Color方法,第二次数据增强采用Crop方法,得到的精度为55.8;
- 数据增强方式对对比学习的影响非常明显,这不是一个好的性质,很多时候我们需要进行穷举试错。
3.2 模型宽度和深度对性能的影响
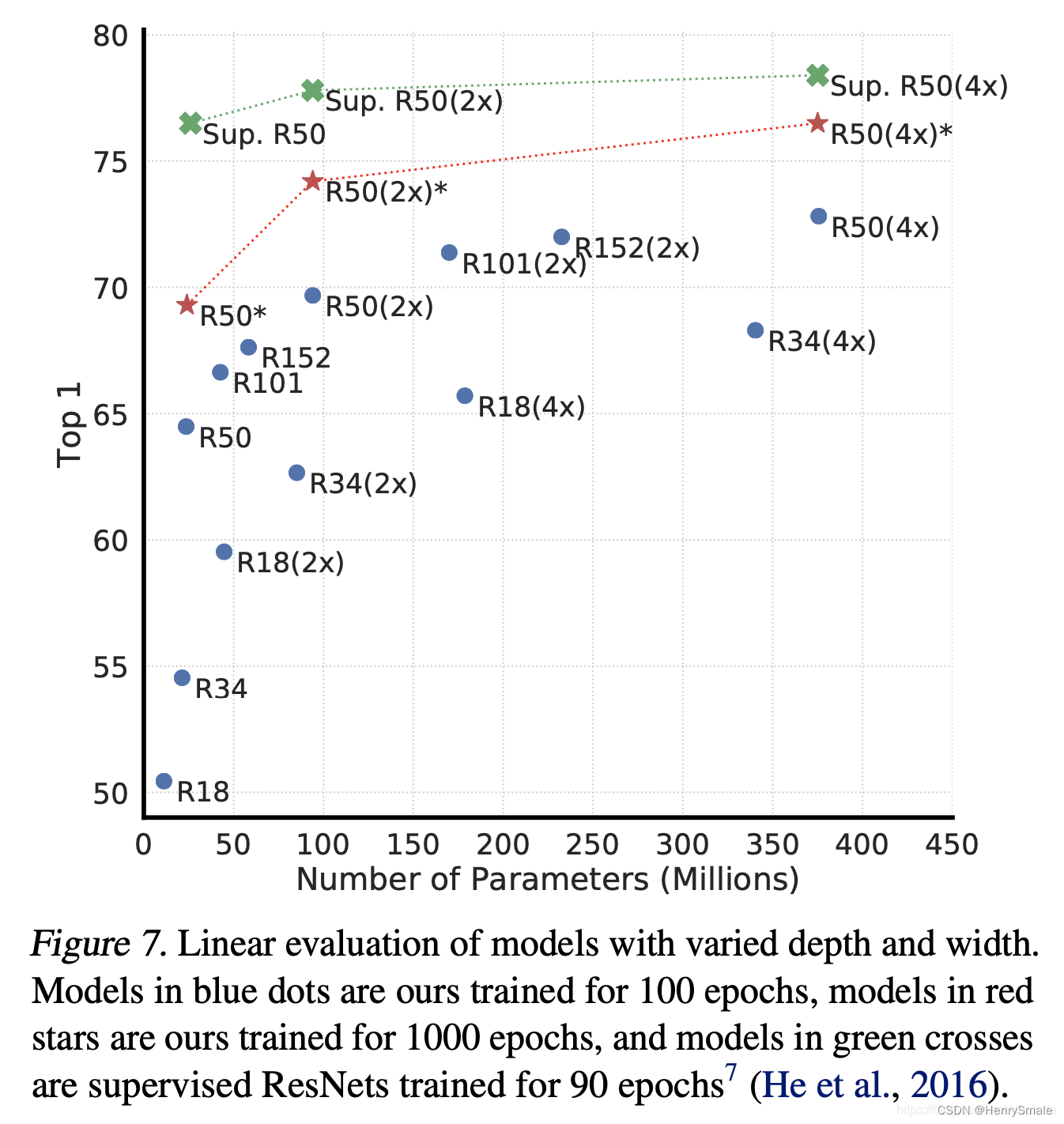
【问】:怎么理解这个图?
【答】:以R18(4x)为例说明,R18表示18层的ResNet网络,4x表示模型宽度加宽4倍。
从图上可以得到如下结论:
- 增大模型容量时,优先增加模型的深度,比如ResNet152比ResNet18性能高不少,参数量并没有增加多少;
- 次选增加模型的宽度,比如ResNet18(4x)比ResNet18(2x)性能高一些,但参数量增加较多,导致训练速度变慢。
3.3 特征向量 z i z_i zi的长度对性能的影响
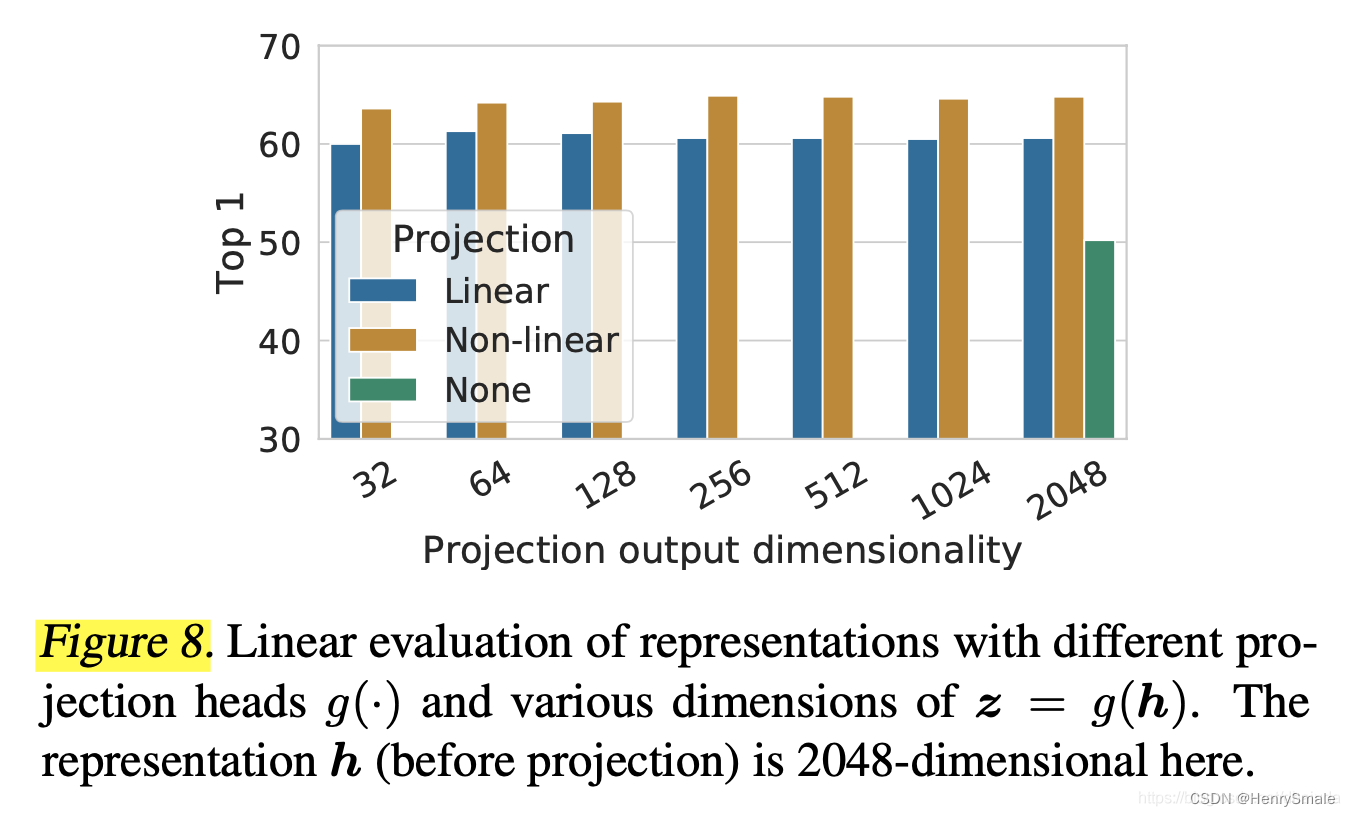
从图上可以得到如下结论:
- 向量长度对性能影响不大;
- 非线性MLP性能优于线性MLP;
- SimCLR中可以用于线性分类的特征有两个,一是特征提取器的输出 h \boldsymbol{h} h,二是MLP层的输出 g ( h ) g(\boldsymbol{h} ) g(h),在线性分类中,使用 h \boldsymbol{h} h的性能要优于 g ( h ) g(\boldsymbol{h} ) g(h)(大于10%),可能是因为MLP过滤掉了一些有用的信息。
3.4 batch size对性能的影响
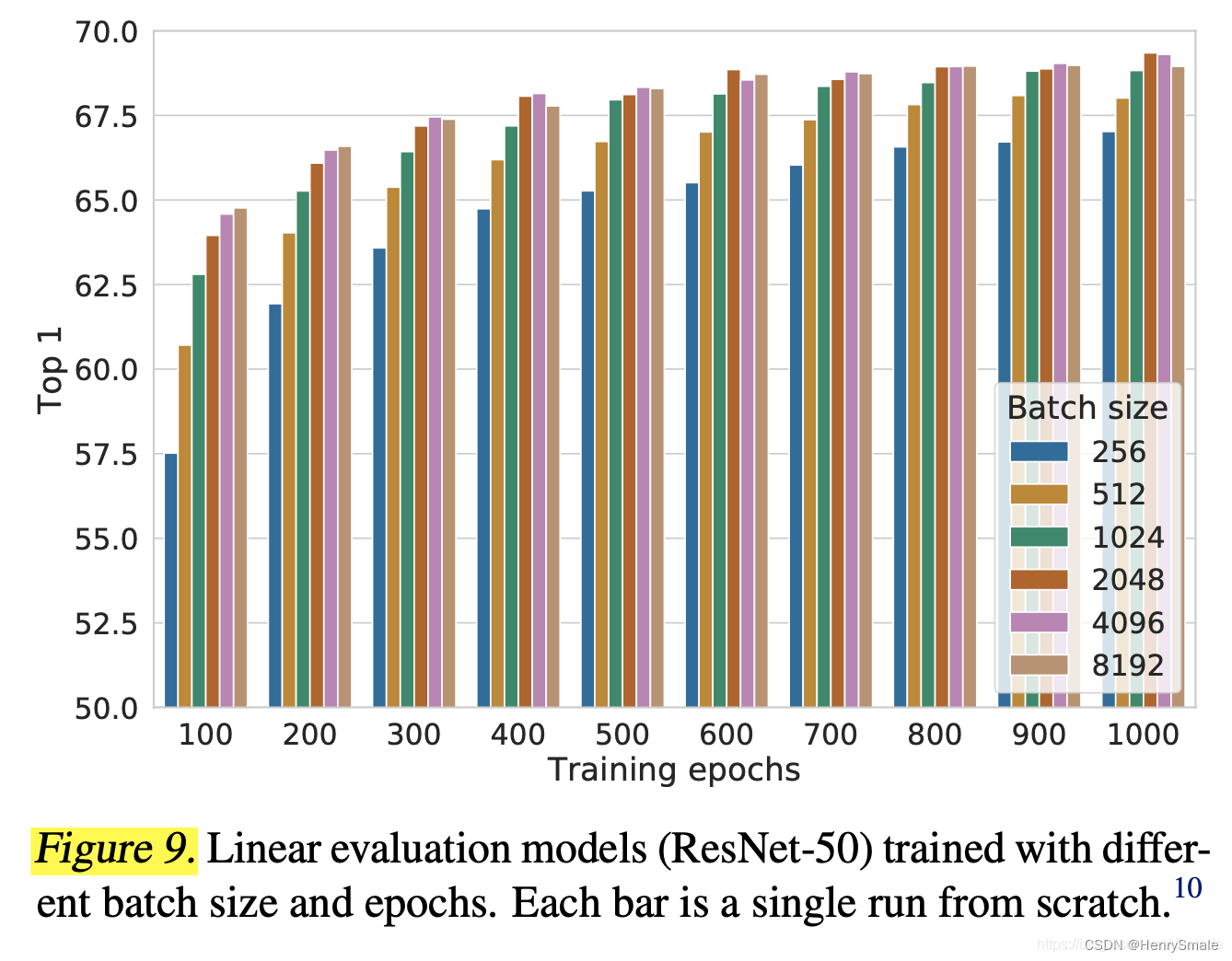
从图上可以得到如下结论:
- 对于有正负例的对比学习算法而言,batch size越大,效果越好,并且提升显著;
- 如果只有正例的对比学习算法而言(如BYOL、simsiam),batch size大小对性能影响没有如此显著;
- 对于有正负例的对比学习算法和只有正例的对比学习算法,训练epoch越长,效果越好。