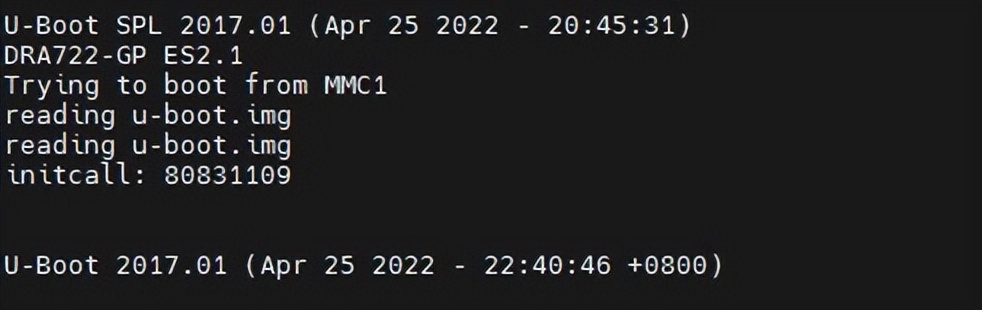
MPT树存储的优缺点
区块链如果采用MPT树存储,大概会有以下优点:
- 可用全局数据的根哈希做共识,数据篡改会被立即发现;
- 可以查询任意历史区块对应时刻的所有数据;
- 方便从指定区块开始同步数据,因为正如上面所说每个区块包含当时的所有数据;
- 方便区块回滚和重演,这在发生分叉和修正最长链时很有帮助。
大概就是因为这些优点,以太坊用一棵账户树记录所有账户的信息,账户下面挂接一棵存储树记录该账户的合约信息,这便是以太坊MPT存储的全部。

以太坊MPT存储
那么这种存储结构就没有什么缺点吗?
当然有。其中一个问题是,随着数据量的增大,查询延时越来越大。这对性能压力较高的区块链服务是个不得不面对的问题,你会看到随着数据量的增长,TPS越来越低,合约执行性能的降低尤其明显。通过分析发现,时间主要花在levelDB的读取上。
性能问题的原因分析
下图就是MPT树在内存中的大致结构,真实的环境因为key-value字符串比较长所以树要深很多。应用层读一个key,会触发底层读取一系列的节点构建MPT树最终找到存储在叶子节点中的value。如果key对应的value被修改,对应叶子节点到根节点路径上所有节点都要更新并写到磁盘。说白了,MPT树存在读写放大的问题。

MPT树
解决方案讨论
为了解决读写放大的问题,我们尝试了直接使用key-value储存(以下简称kv存储),即不再构建MPT树。这样读写放大问题就不复存在,但是又引入了以下几个新问题:
- 之前用MPT树的根节点哈希作共识,现在用什么作共识?
- 用MPT存储能查到历史数据,直接kv存储没有历史数据怎么办?
- 假如kv存储节点执行区块后只写入部分数据就断电了,重启后怎么基于前一块继续运行?
- 采用类似POW的概率一致性共识算法的链遇到主链变更时,怎么基于历史块重演最长链?
下面讲一下这几个问题相关的思考,以及我们在实现时留意到的细节。
第一个问题,之前用MPT树的根节点哈希作共识,现在用什么作共识?
MPT是对所有数据作共识,kv用区块执行后修改数据的有序集作共识。这有点类似数据的全量备份和增量备份,kv用每个块执行后的“增量”部分作共识。kv存储的节点可以从创始块开始验证所有区块和数据。实现时需要留意“有序集”,区块链全网节点执行区块修改时要用统一的规则对变动数据求哈希用作共识,我们写测试代码用的统一规则是对共识修改后的key-value按key进行排序。这部分的改动对合约执行性能有大幅提升,TPS大概能提升3倍。
第二个问题,用MPT存储能查到历史数据,直接kv存储没有历史数据怎么办?
可以基于kv存储构建可提供历史数据查询服务的“全量节点”。具体实现就是全量节点提供每个块kv共识哈希到MPT树根哈希的映射,也就是全量节点采用MPT存储但在内存构建kv有序集参与共识。
第三个问题,假如kv存储节点执行区块后只写入部分数据就断电了,重启后怎么基于前一块继续运行?
这个问题讲的其实是,一个块产生的数据修改集是个原子性事务,要么全部执行成功,要么全都不能修改。在批量写一个块产生的修改集时,程序可能崩溃或被杀死,机房可能断电,类似情况不可避免,而kv存储节点又没有历史数据,所以一定要用某种机制保证节点能回到前一块执行成功后的状态。解决方案是在更新数据前,将相关数据的旧状态写入wal文件。这样节点重启发现块执行失败时可以恢复前一状态,然后重新执行一遍该高度的块。当执行成功后,就可以清除相关区块执行失败的标识。
最后一个问题,采用类似POW的概率一致性共识算法的链遇到主链变更时,怎么基于历史块重演最长链?
如果你像我们一样采用类似PBFT的绝对一致性共识算法,那么这个问题就不存在了。当然区块链不能随便改用共识算法,所以我们还是尝试讨论下这个问题。其实这个问题的解决办法类似第三个问题,使用wal可以回到前一个块的状态,使用一系列wal当然可以回到几个块之前的状态。只需要回到两条链第一个共同的祖先块,再依次执行另一条链的块,就可以修正最长链了。当然对采用概率一致性共识算法的链改用kv存储支持重演时还可能遇到其它问题我们没考虑到,如果有小伙伴看到这里,有兴趣做了存在重演时的kv存储修改,可以分享一下。
小结
用kv存储代替MPT存储对性能有很大提升,但也需要考虑会引发的问题,要有合适的解决方案。
原文链接:https://zhuanlan.zhihu.com/p/75953913
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !