点击上方蓝字关注我们!

对业务来说,完备的应用健康性和数据指标的监控非常重要,通过采集准确的监控指标、配置合理的告警机制,我们能够提前或者尽早发现问题,并做出响应、解决问题,进而保证产品的稳定性,提升用户体验。
过去单体服务或者微服务时代,对我们JavaBoy来说,或是通过SpringBoot的Actuator模块实现了本地应用的监控与管理,或者通过javamelody对Tomcat应用进行线程级别的监控(参考我另一篇文章:《一文看懂:性能监控神器JavaMelody》)。
如今进入到云原生时代,过去的一些监控在k8s应用部署的环境下,或是由于设计思路不同,或者开源社区不兼容等原因,变得不可用,这一下子让很多开发者变的束手无策起来。
在k8s应用部署的大背景下,下面将围绕着“建设云原生的可观测性监控指标”的主题,一起探讨“架构和业务层面可以做的事情”,最终得出建设业务监控系统平台的概念。

背景
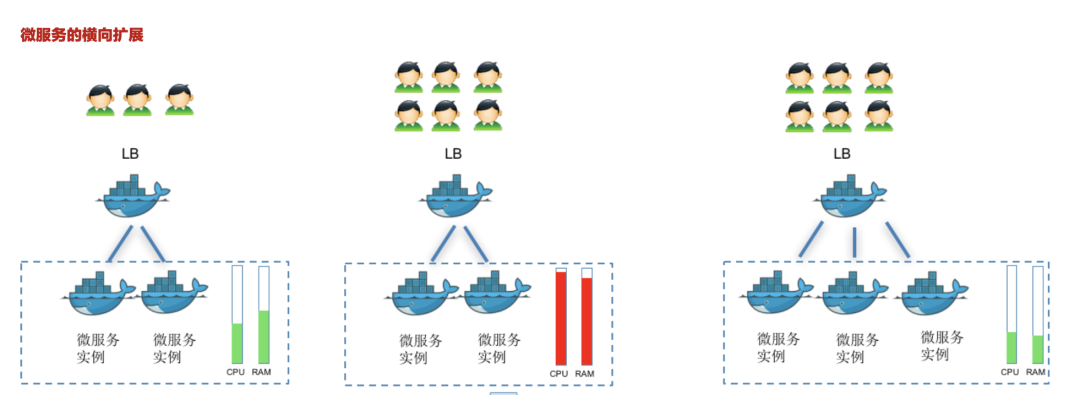
在微服务和容器化时代,我们开始大面积拆分小应用,将业务分割为一个个小系统,通过Docker来独立部署每个小系统,但遇到了容器编排、应用扩缩容、升级繁琐、容器难管理等诸多问题;
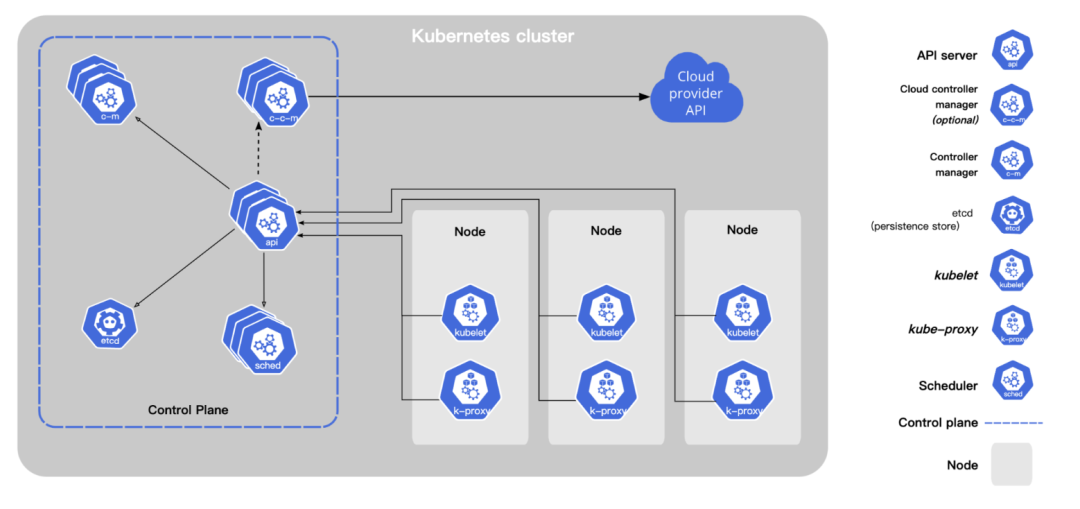
进入云原生时代后,Kubernetes横空出世,帮助运维同学高效实现容器集群的管理;
对于开发同学来说,我们所负责的业务系统经过上云部署之后,如果需要进行应用健康性和业务数据监控,会遇到哪些可观测性监控的问题,又应该如何解决呢?

云原生破局利剑与理论依据
winter
必须先提及两个基础概念:Promutheus 和 可观测性理论。
Prometheus不必多说,它就是云原生监控的破局利剑,是兵器;可观测性理论就是我们监控的理论来源,是兵法;有了兵法和兵器,我们才能披荆斩棘,解决实际问题。
Prometheus
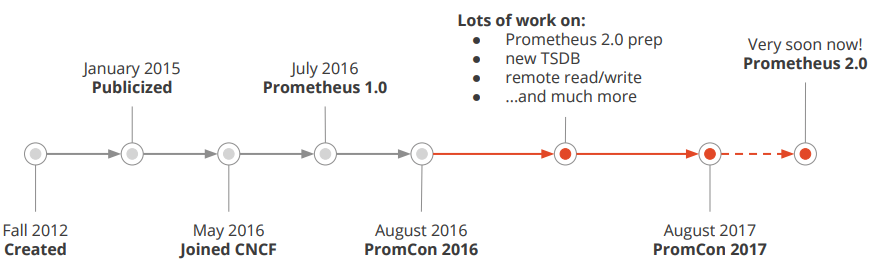
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来)。
2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。
2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。
2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
可观测性理论:
我们通过图表来定义描述Metrics, tracing, logging三个概念,进而明确监控的作用域,使各名词的作用范围更明确。
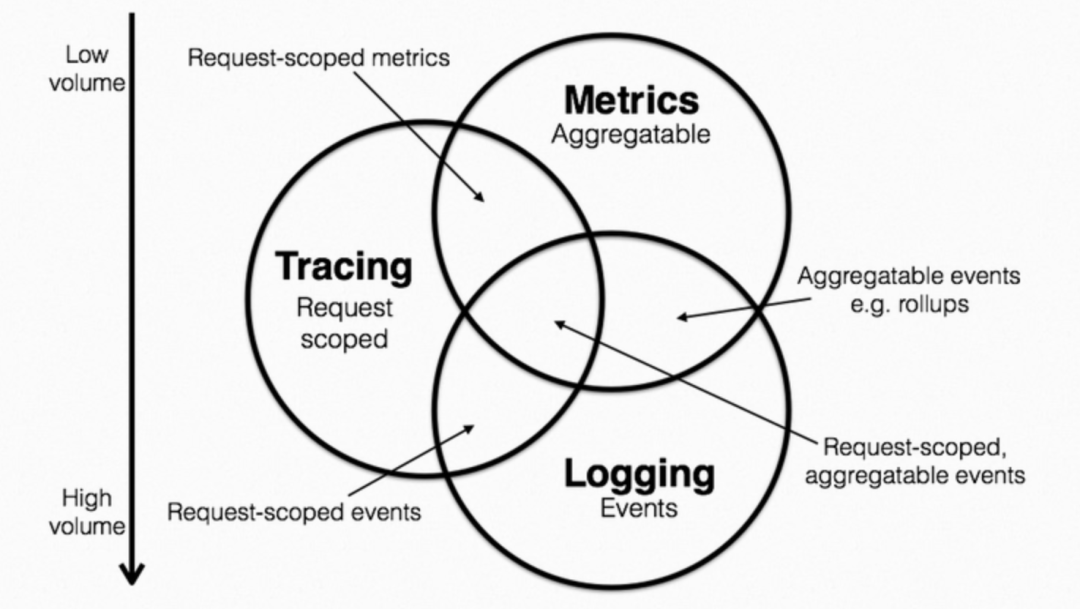
(1)Metric:特点是可累加和有原子性,每个都是一个逻辑计量单元,或者一个时间段内的柱状图。
例如:队列的当前深度可以被定义为一个计量单元,在写入或读取时被更新统计;输入HTTP请求的数量可以被定义为一个计数器,用于简单累加;请求的执行时间可以被定义为一个柱状图,在指定时间片上更新和统计汇总。
(2)Logging:特点是描述一些离散的(不连续的)事件。
例如:应用通过一个滚动的文件输出debug或error信息,并通过日志收集系统,存储到Elasticsearch中;审批明细信息通过Kafka,存储到数据库(BigTable)中;又或者,特定请求的元数据信息,从服务请求中剥离出来,发送给一个异常收集服务,如NewRelic。
(3)Tracing:特点是它在单次请求的范围内,处理信息。任何的数据、元数据信息都被绑定到系统中的单个事务上。
例如:一次调用远程服务的RPC执行过程;一次实际的SQL查询语句;一次HTTP请求的业务性ID。


云原生应用特点
云原生:云原生是一种专门针对云上应用而设计的方法,用于构建和部署应用,以充分发挥云计算的优势,比如我们耳熟能详的“腾讯云”、“阿里云”等。
云原生技术包含了一组应用的模式,用于帮助企业快速,持续,可靠,规模化地交付业务软件。
云原生由微服务架构,DevOps 和以容器为代表的敏捷基础架构组成。援引宋净超同学的一张图片来描述云原生所需要的能力与特征:
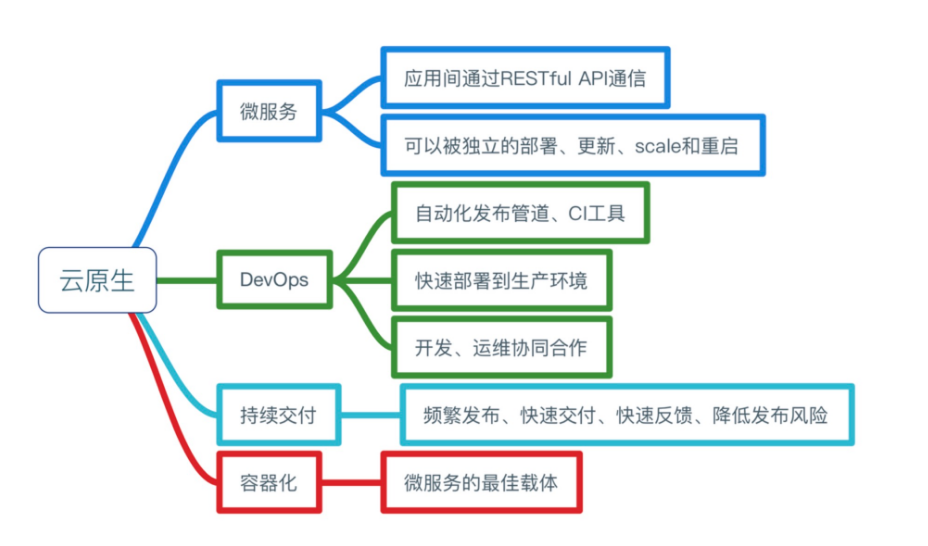
因此,借由云原生技术可以实现快速和频繁的构建、发布、部署,结合云计算的特点实现和底层硬件和操作系统解耦,可以方便的满足在扩展性,可用性,可移植性等方面的要求,并提供更好的经济性。
云原生也带给开发模式、系统架构、部署模式和基础设施巨大的改变,这些改变代表着云原生应用的特点:
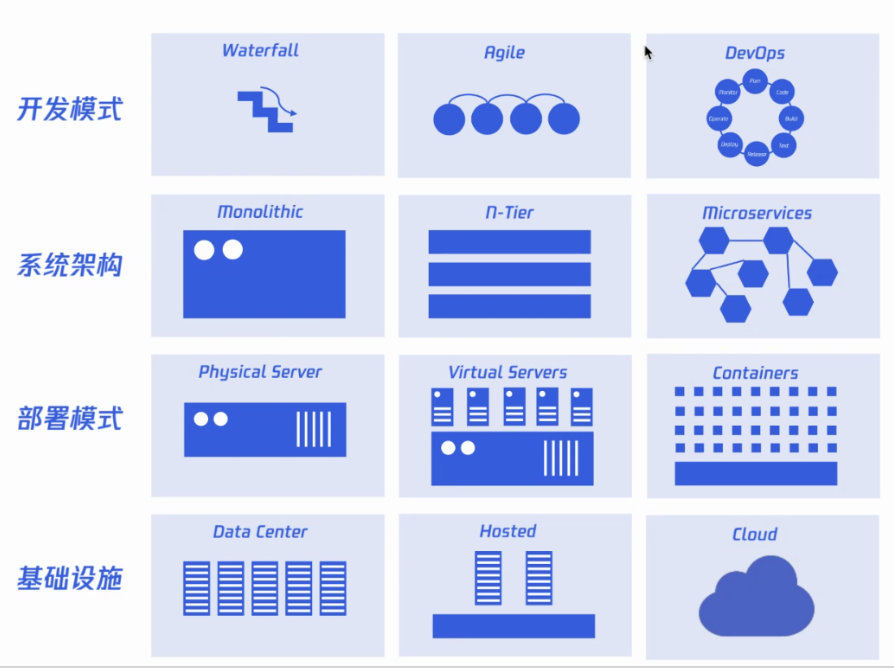
开发模式:效率要求更高,随着DevOps模式普及,规划、开发、测试、交付的效率越来越高。
系统架构:系统更加复杂,架构从开始的一体化到分层模式,到微服务架构。
部署模式:环境动态性增强了,容器化部署模式动态性增强,使得应用实例生命周期变短,更加可控制。
基础设施:上下游依赖更多了,依赖各种云原生应用和各类云厂商的产品,上下游变多了。

云原生监控的痛点与目标使命
中小企业往往是在公有云上部署自己的云原生应用,因此国内的五大云厂商(阿里云、华为云、腾讯云、天翼云和亚马逊云)都会定时采集用户反馈。我们梳理处下面五个常见的痛点:
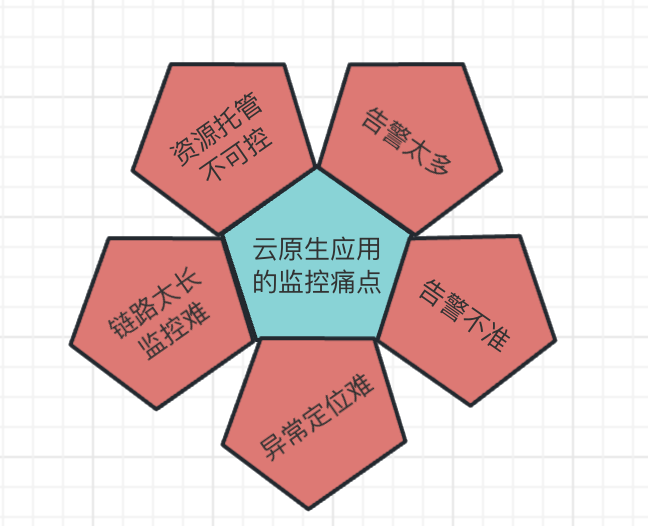
这些痛点,我们其实从新闻里也有听到过,对于toC用户来说,一些大故障,我们可以开诚布公,通过公开发文来解决舆论压力,比如:光缆被挖断;但是对于toB客户,云厂商面临的压力就很大,频率较高,这类产品要分类分级。
云原生监控的目标:监控体系做得好,保证一切都是可控的。
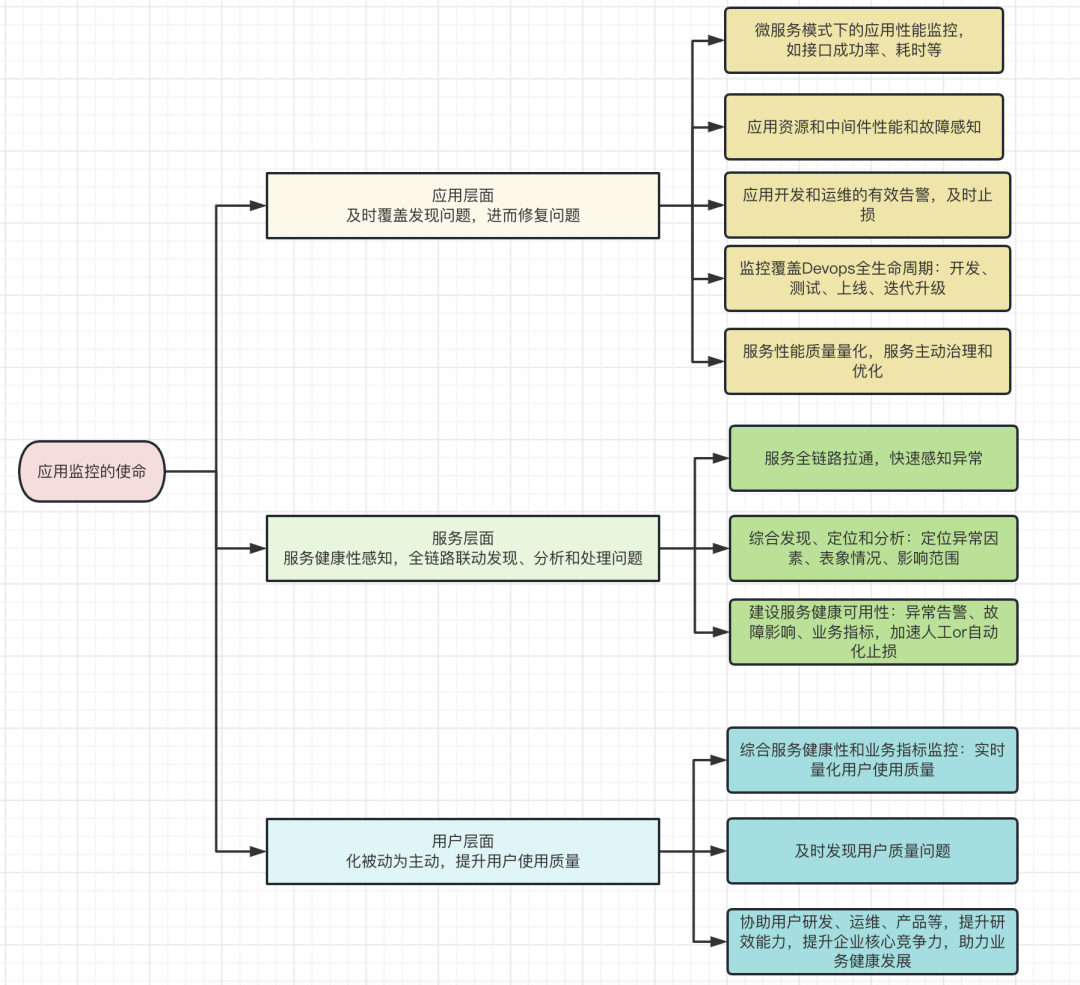
我们可以从三个方面入手:应用层面、服务层面、用户层面。
(1)应用层面:及时覆盖发现问题,进而修复问题
(2)服务层面:服务健康性感知,全链路联动发现、分析和处理问题
(3)用户层面:化被动为主动,提升用户使用质量

云原生业务立体化监控方案
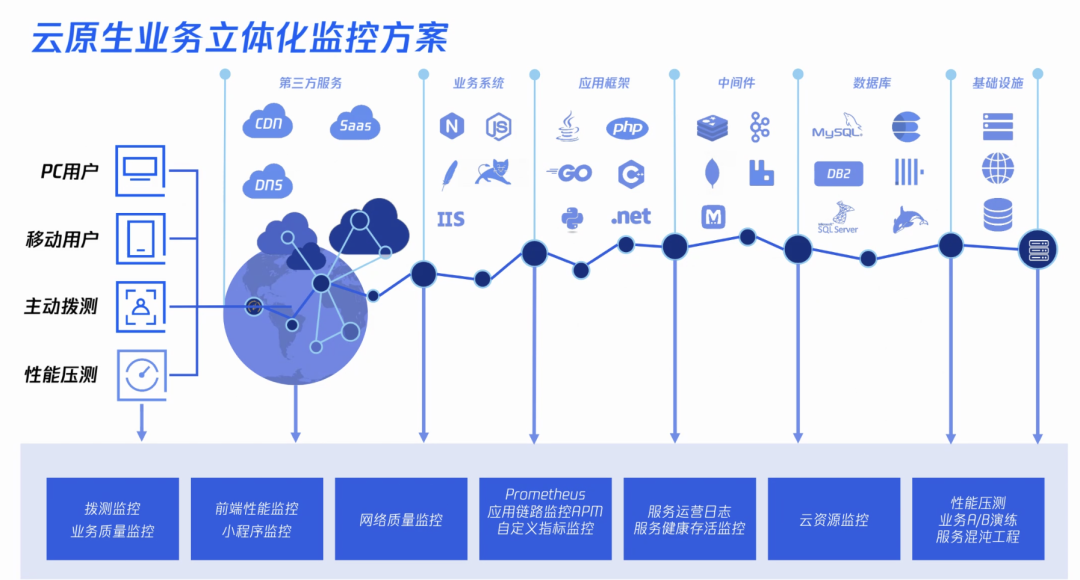
云原生业务立体化监控方案针对了七个环节进行监控:
拨测监控:业务质量监控;
前端性能监控:小程序等;
举例子:健康码白屏了,前端也要重点关注的
网络质量监控:国内外的网络环境差异较大
举例子:俄乌冲突下的居民用网问题
后端指标监控/链路监控:后端比较关注
服务运营日志:中间件监控(Redis、Kafka等)
云资源监控:数据库、云硬盘、服务器资源、CPU、带宽IO等。
其实开源社区有非常多的组件支持,让数据库、中间件直接接入,就可以实时监控了
性能压测:金丝雀发布演练
以上七个环节,每个环节都有自己的侧重点,下面我们逐个分析。

业务拨测

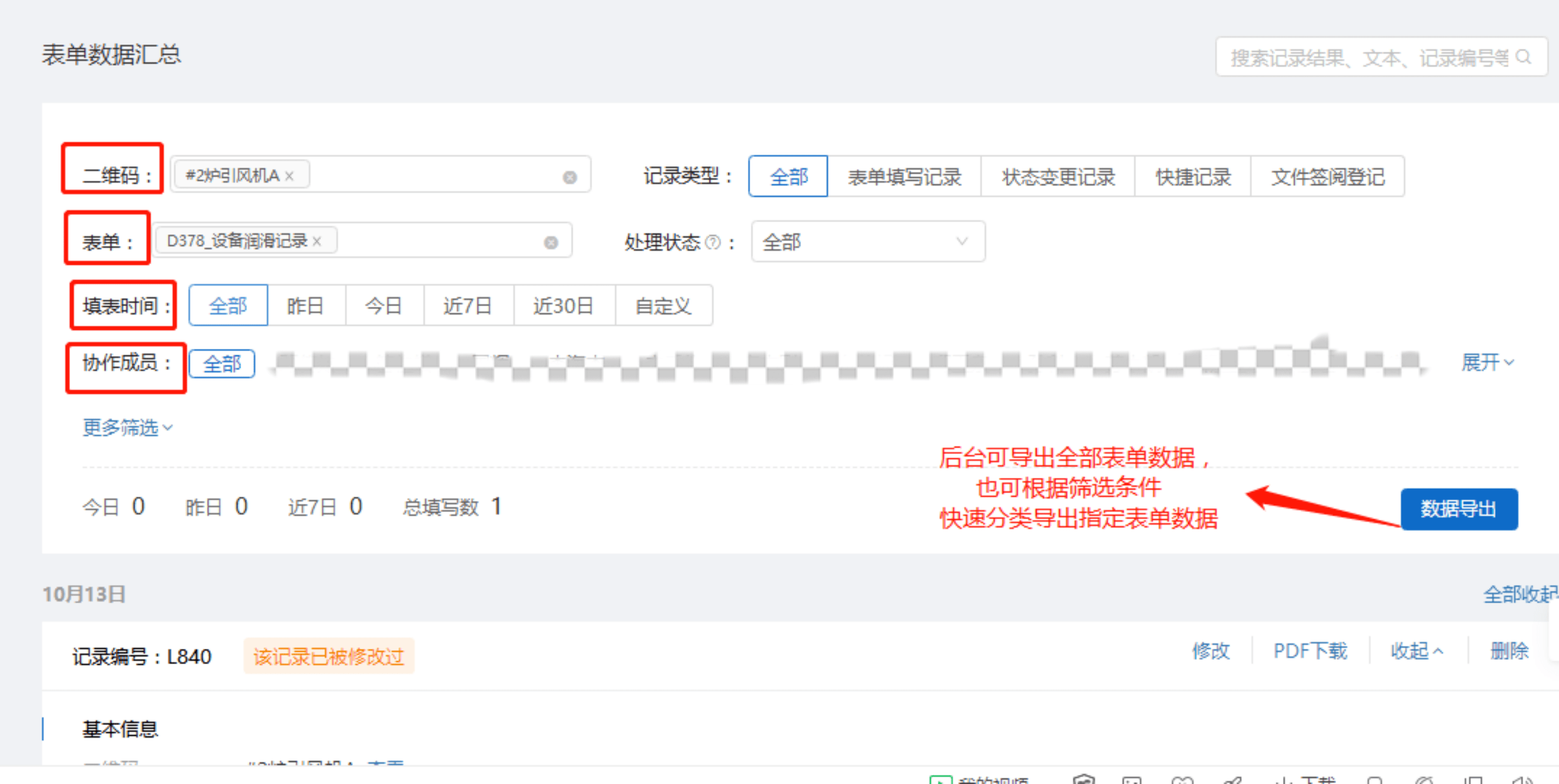
业务拨测:依托云厂商专有的服务质量监测网络,利用分布于全球的服务质量监测点,对网站、域名、后台接口等进行周期性监控,通过查看可用率和延时随时间区间变化来帮助分析站点质量情况。。
拨测原理:云厂商利用分布全球的检测网络(例如,腾讯云提供全球200+城市的1000+拨测点资源),提供模拟终端用户体验的拨测服务,来满足我们对未来、浏览、传输、协议、流媒体的周期性监控的拨测场景;
好处:以黑盒视角重点保障关键域名、服务功能,从客户端最直接感受,做质量管控,比如下面六种场景:
(1)服务质量优化
从全球模仿用户访问服务,获取各种业务场景(电商网站性能、API 测试等)的服务质量指标。
(2)发布验证
系统升级或新功能发布后的可用性和性能验证,提前发现业务打不开、运行速度慢等用户体验差的问题。
(3)CDN 质量评估
通过主动式拨测定位 CDN 的服务质量,并提供详细数据支撑,优化业务的用户体验。
(4)防劫持和防篡改
监测域名劫持、流量劫持、页面篡改等行为,保护应用流量和品牌形象。
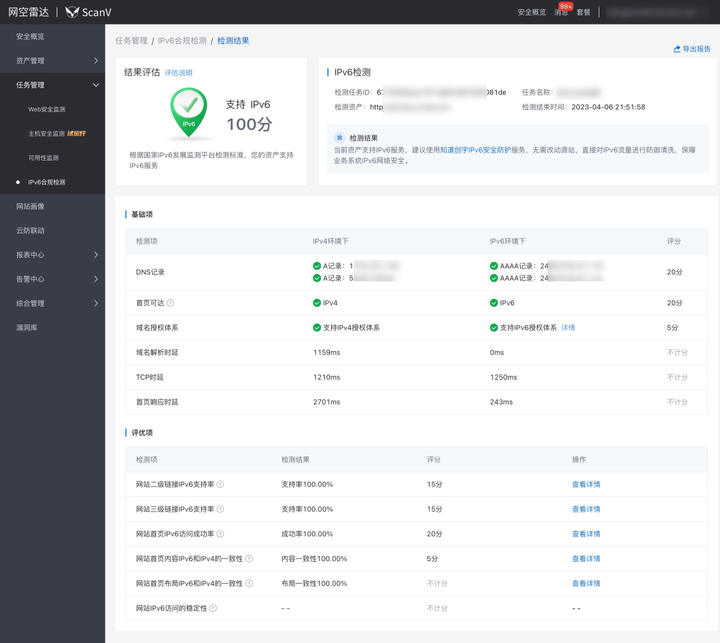
(5)IPV6 升级改造
对比验证 IPV6 改造后相对 IPV4 提升效果,以及全国各地区网络连通性等监测数据。
(6)竞品分析
拨测不同竞品应用的性能数据,掌握应用在行业内重点竞争对手中的优劣势。

前端监控&小程序监控

前端监控:用户终端实际用户操作行为与前端服务质量监控,低门槛、场景化,主动进行行为分析。
应用场景:
页面性能分析和优化
前端服务服务异常监控:JS/web元素异常
用户行为分析和运营数据处理

网络质量监控
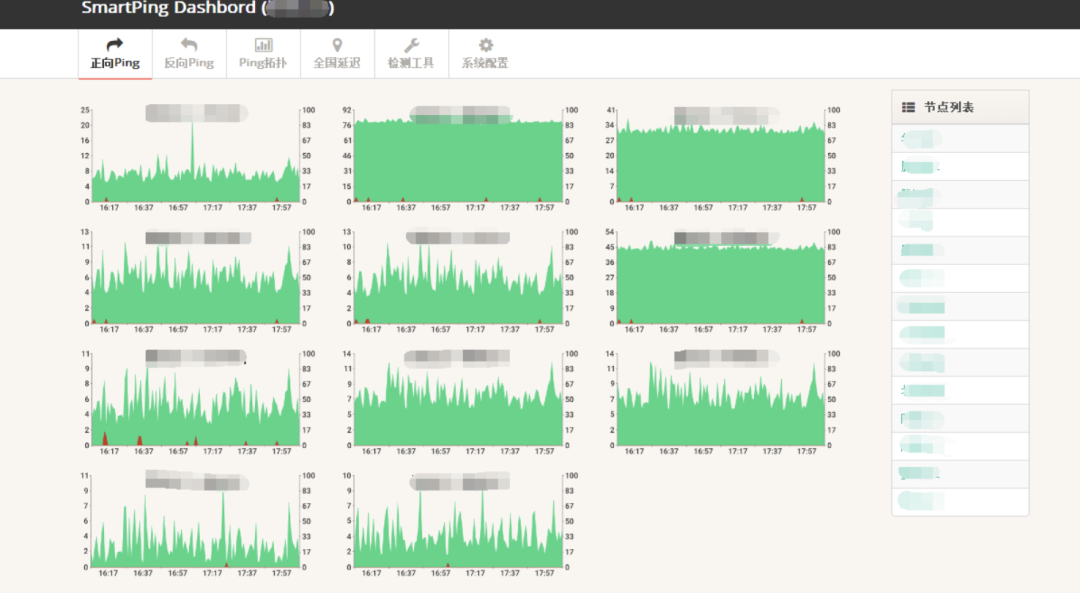
网络质量监控(尤其是核心网络质量)对业务健康性是至关重要的。
网络质量作为服务可用的第一关,对用户体验影响深远,而监测网络质量的方式其实并不复杂。一台 PC,通过 Ping、Dig、Telnet 等简单的命令行指令,就能快速发现网络问题。
其中,网络监控分为网络设备交换机、路由器等监控,光缆线路监控,网络连通性探测监控等。

以腾讯云为例子,腾讯云提供全地域,运营商网络质量对比一目了然。能够帮助用户快速发现区域性、运营商网络问题,及时修复,最大化降低业务影响。
目的:云上网络质量监控,能够确保业务核心网络和骨干网的健康性监控、网络质量探测分析,业务调度容灾。
场景:有些产品对网络要求比较高,尤其是出海业务。因为国内大可不必太担忧,但是国外(中东打仗了,俄乌冲突)很多意外,基础设施上不了,导弹忽然就到了,网络就断了,非常的不稳定;另外,国外会有很多运营商,整体不是一个可控的网络。

后端监控-自定义指标
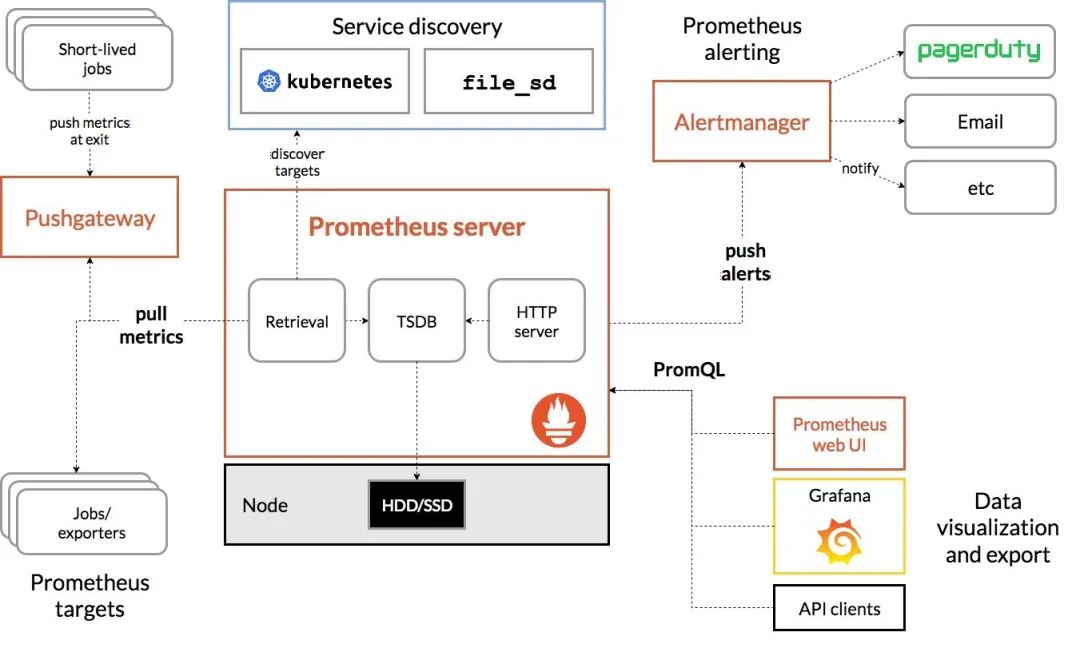
后端监控:Prometheus提供了非常多的开源组件的指标监控实现,让我们能够开箱即用的使用社区开源能力。
但也有部分业务场景,需要我们研发侧自行定义的,Prometheus提供了4 种不同的度量指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
结论:针对不同的服务场景,我们可以定义不同的指标监控,如果服务调用量、卡顿率、延迟分布监控、再比如服务价格性能、垃圾回收性能监控等。Prometheus协议:已经成为一个标准。对云资源进行指标监控。
应用场景:容器、kafka、db,各大云厂商监控支持Prometheus协议,且支持微服务自定义监控架构设计。

后端监控-链路跟踪
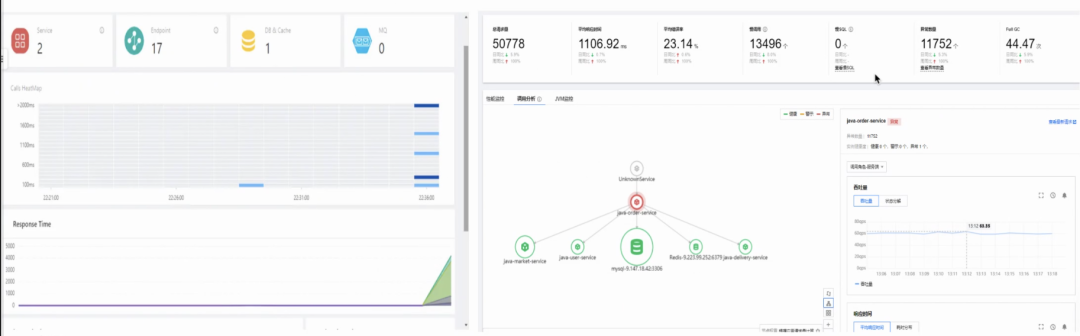
链路跟踪:专注于后台服务APM(应用性能管理),应用性能观测(Application Performance Management ,APM)是一款应用性能管理平台,从服务代码层面实现全链路监控:调用量、成功率、耗时、异常问题详情。
作用:后端服务全链路监控、服务异常及时关联定位分析、业务活动重保护航、服务主动优化治理、业务成本优化和预算评估。
场景:大部分情况,我们是通过Skywalking进行traceid的链路传递和监控。

云资源监控
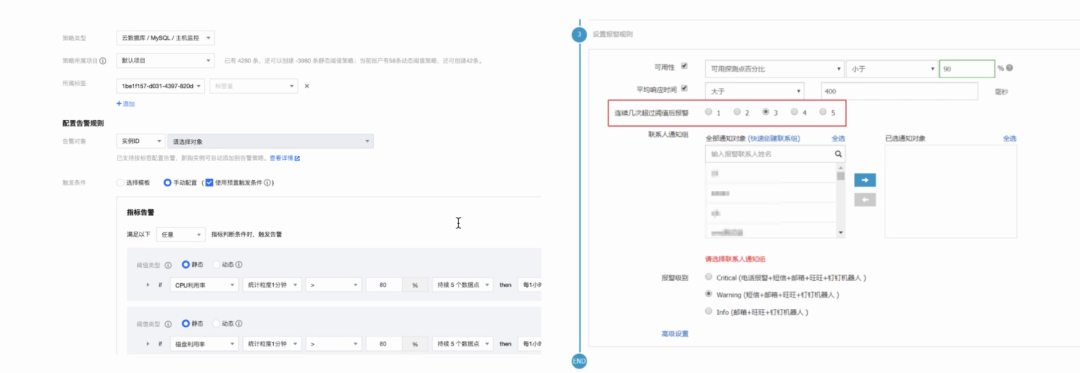
云资源监控:专注于云资源:容器、虚拟机、存储、中间件等实时监控,更加倾向于运维保障效率、软硬件性能和可用性监控。
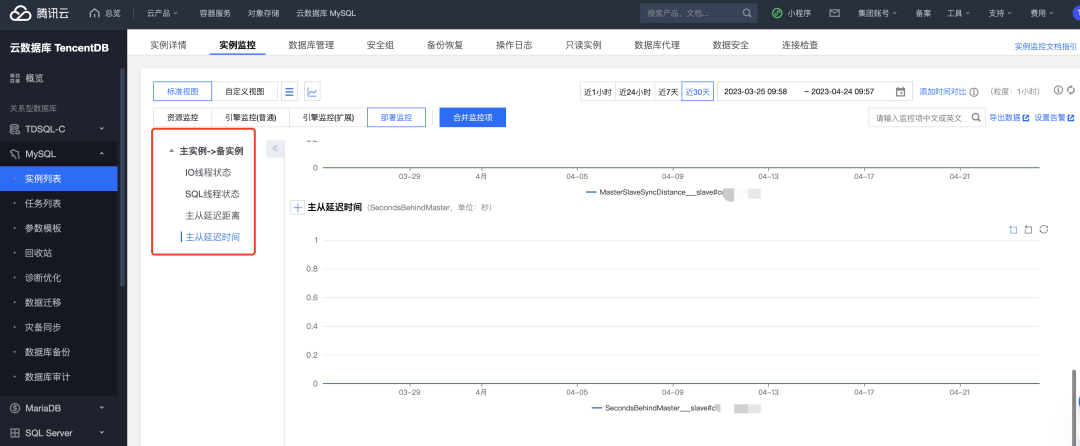
举个简单例子:云数据库产品(以腾讯云Mysql为例子)
过去的DB部署,是由DBA专门负责的,通过DBA手动敲指令盯着Mysql性能的方式来监控;
而如今现在的DB上云之后,Paas交付给客户的只有一个DB实例了,监控手段更加多样化,可以通过云监控组件,可视化的了解各类数据库负载指标。
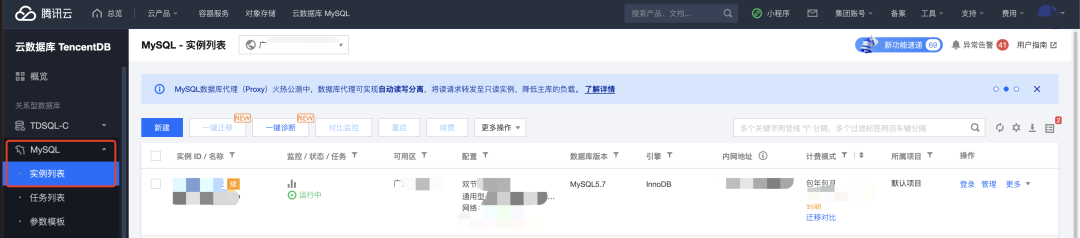
监控指标
可以通过大盘方便快捷的监控我们的数据库实例的四类指标:
【1】资源监控:CPU/硬盘/网卡/内存
包括不限于下面指标:CPU利用率、内存利用率、内存占用、磁盘利用率、磁盘使用空间、磁盘占用空间、IOPS、IOPS 利用率、内网出流量、内网入流量
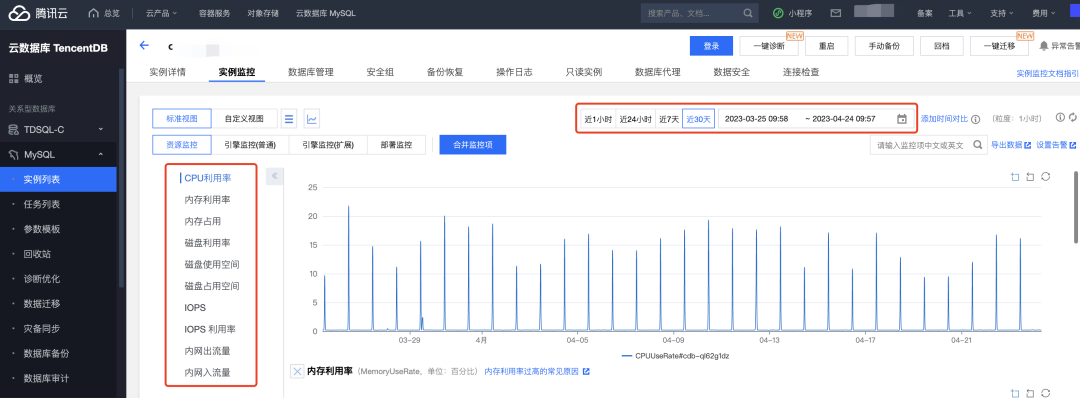
【2】引擎监控:数据库连接/表/InnoDB/访问响应
数据库连接包括了:每秒执行操作数、每秒执行事务数、连接数利用率、当前打开连接数、最大连接数等;
访问响应包括了:慢查询数、全表扫描数、查询数、更新数、删除数、插入数、覆盖数、总请求数、查询使用率;
表:临时表数量、等待表锁次数
InnoDB:缓存命中率、缓存使用率、读磁盘数量、写磁盘数量、fsync数量、当前InnoDB打开表的数量等;
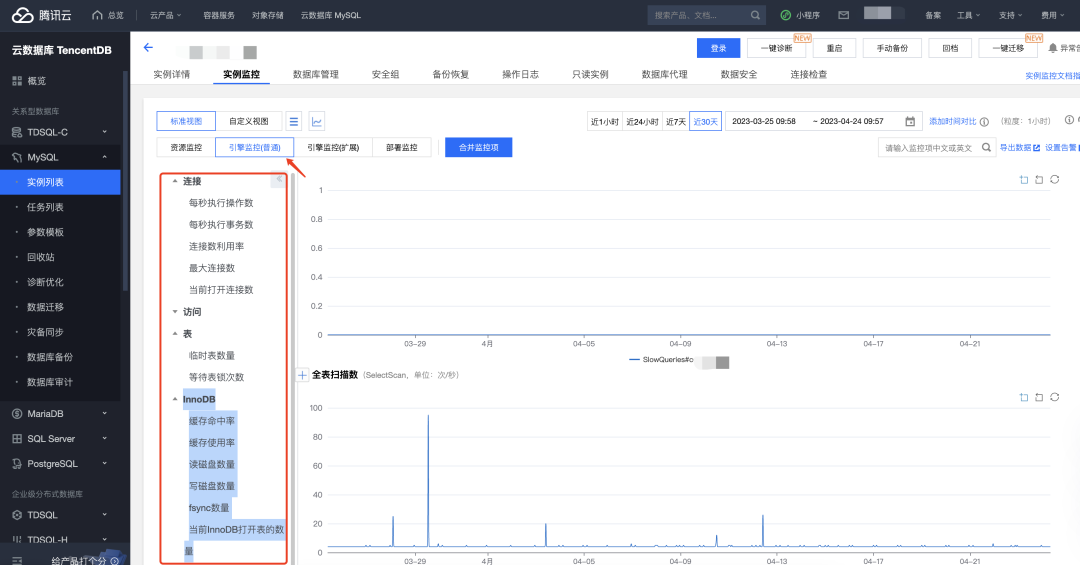
【3】引擎监控的扩展指标
包括了连接数、InnoDB写入读出量等
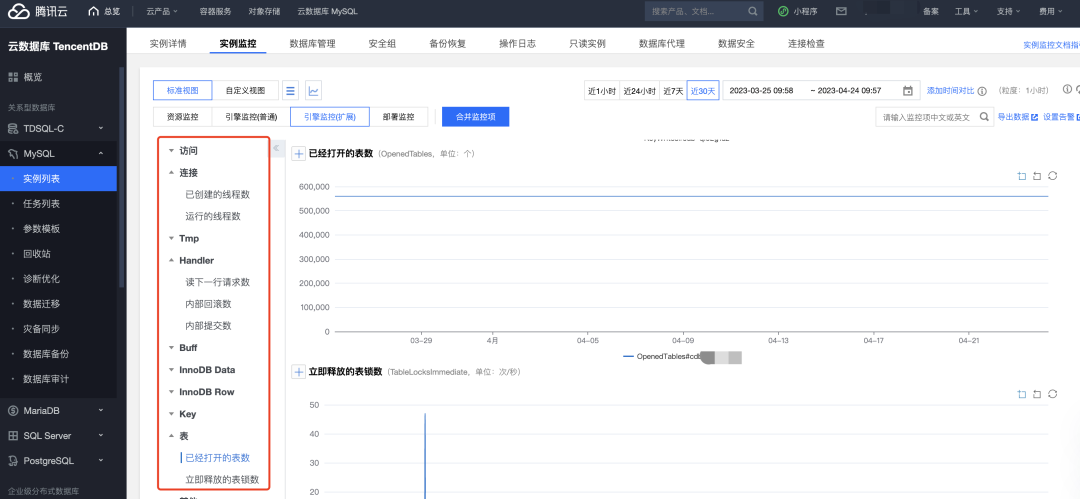
【4】部署监控
由于大部分企业级应用都追求高可用性,往往会采取一主多从的部署模式,因此存在主从延迟等问题,云监控能够帮助我们方便快捷的监控到这类指标。

性能压测
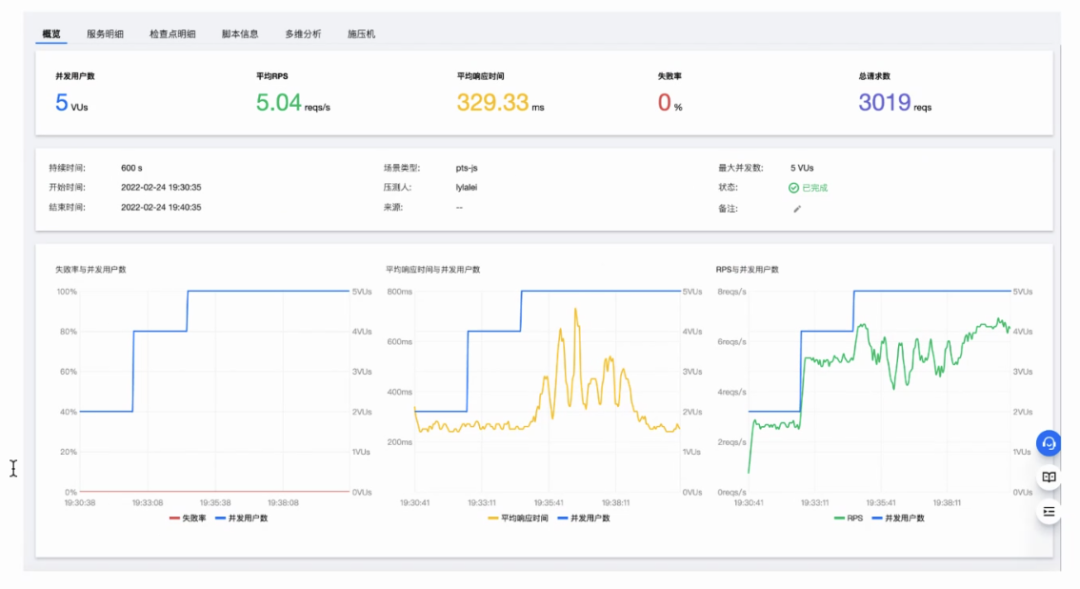
全链路性能压测:借助云厂商的工具,丰富我们的测试场景:从简单模式(GET/POST/PUT/PATCH/DELETE)、脚本模式、自定义录制。才有box/ship方案,支持压测引擎动态插拔,通过灵活的第三方压测引擎,丰富我们的测试场景。
我们研发开发阶段,往往会通过Jmeter等工具模拟并发请求的场景;进入云原生时代,这种压测也可以在发布阶段后,给业务进行压测。
目的:新系统上线性能压测、业务峰值稳定性测验、业务容量规划评估、技术迭代升级验证。

建设业务质量监控
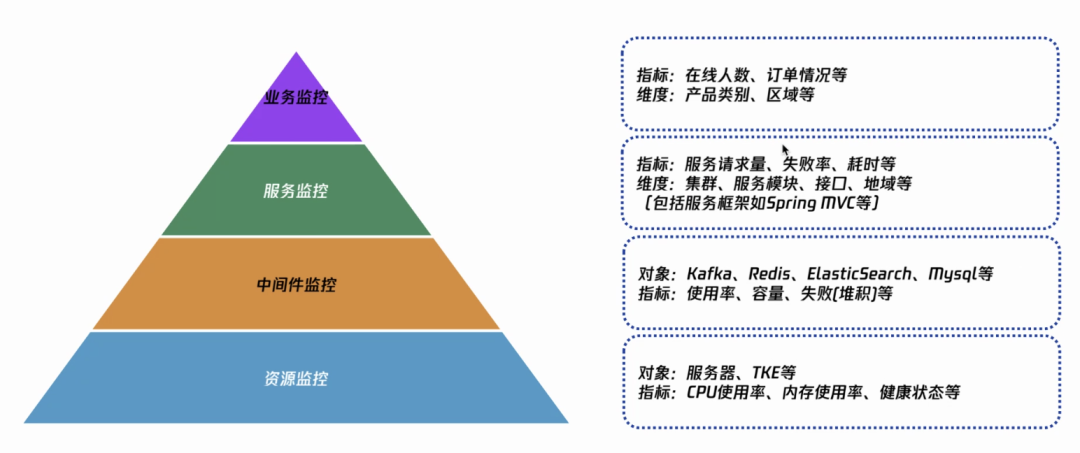
业界认可的服务监控模型如上所示:越往上的指标越少(容易辨别是什么问题),越往下约多(分析维度多)。
建立云原生业务质量监控的步骤如下:
确定业务监控目标:明确需要监控的业务指标,如响应时间、成功率、用户满意度等。
选择合适的监控工具和技术:根据业务监控目标,选择合适的监控工具和技术,如 Prometheus、Grafana、InfluxDB 等。
设计监控指标和监控策略:根据业务监控目标和监控工具,设计合适的监控指标和监控策略,如告警、日志记录、性能监控等。
收集和整合监控数据:收集和整合监控系统中的数据,包括告警信息、日志记录、性能监控数据等,并进行数据清洗、汇总和分析。
建立监控告警机制:根据监控数据和分析结果,建立监控告警机制,及时发现和解决问题。
优化监控流程和系统:对监控系统进行优化和改进,提高监控效率和准确性。

总结
随着互联网业务的快速发展,云原生应用正在成为互联网应用的主流架构模式。云原生应用具有轻量、灵动、可伸缩、易于维护等特性,非常适合高并发、大流量的业务场景。
业务监控是云原生应用的关键能力之一,可以帮助运维团队实时了解应用的运行状态,发现和解决问题,确保应用的稳定性和可靠性。
总之,云原生时代的业务监控将更加智能化、高效化和可视化,帮助运维团队更加高效地管理和维护云原生应用,确保应用的稳定性和可靠性。朋友们,如果说编程已经无法提现我们的专业能力,那么云原生知识栈更应该要学起来。
往期推荐
《互联网技术峰会》
《ArchSummit:从珍爱微服务框架看架构演进》
《ArchSummit_2022_全球架构峰会》
《2021年深圳ArchSummit全球架构师峰会》
《降本30%,酷家乐海量数据冷热分离设计与实践》
《经典书籍》
《Java并发编程实战:第1章 多线程安全性与风险》
《Java并发编程实战:第2章 影响线程安全性的原子性和加锁机制》
《Java并发编程实战:第3章 助于线程安全的三剑客:final & volatile & 线程封闭》
《服务端技术栈》
《Docker 核心设计理念》
《Kafka原理总结》
《HTTP的前世今生》
《如何进行一次高质量CR》
《一时重构一时爽,一直重构一直爽》
《一文带你看懂:亿级大表垂直拆分的工程实践》
《API加速优化方案:多级缓存设计》