目录
一.引言
二.MMoE 模型分析
三.MMoE 逻辑实现
• Input
• Expert Output
• Gate Output
• Weighted Sum
• Sigmoid Output
• 完整代码
四.总结
一.引言
上一篇文章介绍了 MMoE 借鉴 MoE 的思路,为每一类输出构建一个 Gate 并最终加权多个 Expert 的输出,提高了相关性不高的多任务问题,下面根据思路简易实现下 MMoE 逻辑。
二.MMoE 模型分析
上图为 BaseLine、MoE 与 MMoE,下面我们专门了解 MMoE 的实现细节,其中 bs 为 BatchSize,Hidden_units 代表隐层输出维度,E0、E1、E2 代表多个 Expert,Tower A、Tower B 代表 N 个输出。

这里 Gate 与 Expert 都可以理解为浅层模型。 下面针对 bs 里的一个样本,分析下 MMoE 执行过程。
• Input
输入一个 embedding_size 长度的向量,这里也可以是 Filed 个变量,进入对应 Embedding 层 Lookup 再做 pooling,为了简单,这里直接取 1 x F,F 为 Field Size。
• Expert Output
输入向量分别经过 E1、E2、... 的 K 个 Expert 计算,得到 Expert 个输出,每个输出维度为 1 x Hidden。
• Gate output
输入向量分别经过 G1、G2、... 的 K 个 Gate 计算,得到 Expert 个输出,维度为 1 x expert,每一维代表对应 Expert Output 的权重,注意这里 Gate 最终输出需经过一层 softmax。
• Weighted Sum
将当前样本输出的 expert 分别与对应 Expert Output 加权求和作为每个任务的 Tower 的输入向量,合并后维度为 1 x hidden_units。
• Sigmoid Output
每个 Tower 最终为 sigmoid 输出的二分类深度模型,输入为 Expert x Hidden 的加权求和,维度仍然为 1 x Hidden。
Tips:
实际 BatchSize 执行时,将上述 1 x ... 换为 bs x ... 即对应 Batch 的逻辑。
三.MMoE 逻辑实现
参数设置为:
num_field = 4
hidden_units = 8
num_expert = 3
num_output = 2
4 个 Field 域、8 维输出、3 个 Expert、2 个任务。
• Input
这里 N 就是上面的 bs 即 Batch Size,F 为 Field Size,这里实现逻辑比较简单,实践场景下可以先将 Field Lookup 得到 Embedding 再 pooling 输入到后面的 Expert 和 Gate:
# 1.构造 Input => N x F
num_samples = 10
inputs = np.array([np.ones(shape=num_field) for i in range(num_samples)])
print("Input Shape:", inputs.shape)Input Shape: (10, 4)• Expert Output
# 2.构建专家 kernel [(filed * hidden) x expert]
expert_kernels = np.random.random(size=(num_field, hidden_units, num_expert))
print("Expert Shape:", expert_kernels.shape)
# 3.获取 Expert 输出 => [N x F] * [F x Hidden x Expert] = N x Hidden x Expert
outputs_by_expert = tf.tensordot(inputs, expert_kernels, axes=1)
print("Output By Expert:", outputs_by_expert.shape)Expert Shape: (4, 8, 3)
Output By Expert: (10, 8, 3)• Gate Output
Gate:在 Dense 输出基础上,增加 softmax 逻辑。
class Gate(Layer):
def __init__(self, expert_num, **kwargs):
self.expert_num = expert_num
self.gate = None
super(Gate, self).__init__(**kwargs)
def build(self, input_shape):
self.gate = Dense(self.expert_num, activation='relu', kernel_initializer=glorot_normal_initializer)
super(Gate, self).build(input_shape)
def call(self, _inputs, **kwargs):
weight = self.gate(_inputs)
_output = tf.nn.softmax(weight)
return _output根据 num_output 任务输出数,决定构造 Gate 的数量,这是 MMoE 与 MoE 的区别之一。
# 4.构建 Gate
gate = [Gate(num_expert) for i in range(num_output)]
# 5.获取每个任务的 Gate 输出权重 output x N x expert
outputs_by_gate = np.array([gate[i](inputs) for i in range(num_output)])
print("Output By Gate:", outputs_by_gate.shape)Output By Gate: (2, 10, 3)
• Weighted Sum
# 6.获取最终输出 N x output
part_input = []
for output_by_gate in outputs_by_gate:
# N x Expert => N x 1 x Expert
expand_output_by_gate = tf.expand_dims(output_by_gate, axis=1)
# N x 1 x Expert => N x Hidden x Expert
repeat_gate_weight = K.repeat_elements(expand_output_by_gate, hidden_units, axis=1)
# N x Hidden x Expert
weighted_expert_output = tf.cast(outputs_by_expert, dtype='float32') * repeat_gate_weight
# N x Hidden
weighted_expert_sum = tf.reduce_sum(weighted_expert_output, axis=2)
part_input.append(weighted_expert_sum)
print("Part Input:", np.array(part_input).shape)原始输入样本个数 N=10,输出 hidden_size=8,任务有2个,所以每个任务获得 BS x hidden_size 即 10 x 8 的 batch 样本。
Part Input: (2, 10, 8)
• Sigmoid Output
这里两个任务对应两个 Tower,之前介绍了多输出模型:TF x Keras 之多输出模型

任务架构基于 Shared-bottom Multi-task Model,实现了同时预测年龄、收入、性别的多分类问题,有兴趣的同学可以把 Shared-bottom 的架构切换为多个 Expert 再加入 Gate 即可实现基础的 MMoE,这里就不再展开了。

• 完整代码
import numpy as np
import tensorflow as tf
from tensorflow.python.keras.layers import *
from tensorflow.keras.layers import Layer
from tensorflow.python.ops.init_ops import glorot_normal_initializer
from tensorflow.keras import backend as K
class Gate(Layer):
def __init__(self, expert_num, **kwargs):
self.expert_num = expert_num
self.gate = None
super(Gate, self).__init__(**kwargs)
def build(self, input_shape):
self.gate = Dense(self.expert_num, activation='relu', kernel_initializer=glorot_normal_initializer)
super(Gate, self).build(input_shape)
def call(self, _inputs, **kwargs):
weight = self.gate(_inputs)
_output = tf.nn.softmax(weight)
return _output
def MMOE(num_field, hidden_units, num_expert, num_output):
# 1.构造 Input => N x F
num_samples = 10
inputs = np.array([np.ones(shape=num_field) for i in range(num_samples)])
print("Input Shape:", inputs.shape)
# 2.构建专家 kernel [(filed * hidden) x expert]
expert_kernels = np.random.random(size=(num_field, hidden_units, num_expert))
print("Expert Shape:", expert_kernels.shape)
# 3.获取 Expert 输出 => [N x F] * [F x Hidden x Expert] = N x Hidden x Expert
outputs_by_expert = tf.tensordot(inputs, expert_kernels, axes=1)
print("Output By Expert:", outputs_by_expert.shape)
# 4.构建 Gate
gate = [Gate(num_expert) for i in range(num_output)]
# 5.获取每个任务的 Gate 输出权重 output x N x expert
outputs_by_gate = np.array([gate[i](inputs) for i in range(num_output)])
print("Output By Gate:", outputs_by_gate.shape)
# 6.获取最终输出 N x output
part_input = []
for output_by_gate in outputs_by_gate:
# N x Expert => N x 1 x Expert
expand_output_by_gate = tf.expand_dims(output_by_gate, axis=1)
# N x 1 x Expert => N x Hidden x Expert
repeat_gate_weight = K.repeat_elements(expand_output_by_gate, hidden_units, axis=1)
# N x Hidden x Expert
weighted_expert_output = tf.cast(outputs_by_expert, dtype='float32') * repeat_gate_weight
# N x Hidden
weighted_expert_sum = tf.reduce_sum(weighted_expert_output, axis=2)
part_input.append(weighted_expert_sum)
print("Part Input:", np.array(part_input).shape)
if __name__ == '__main__':
num_field, hidden_units, num_expert, num_output = 4, 8, 3, 2
MMOE(num_field, hidden_units, num_expert, num_output)四.总结
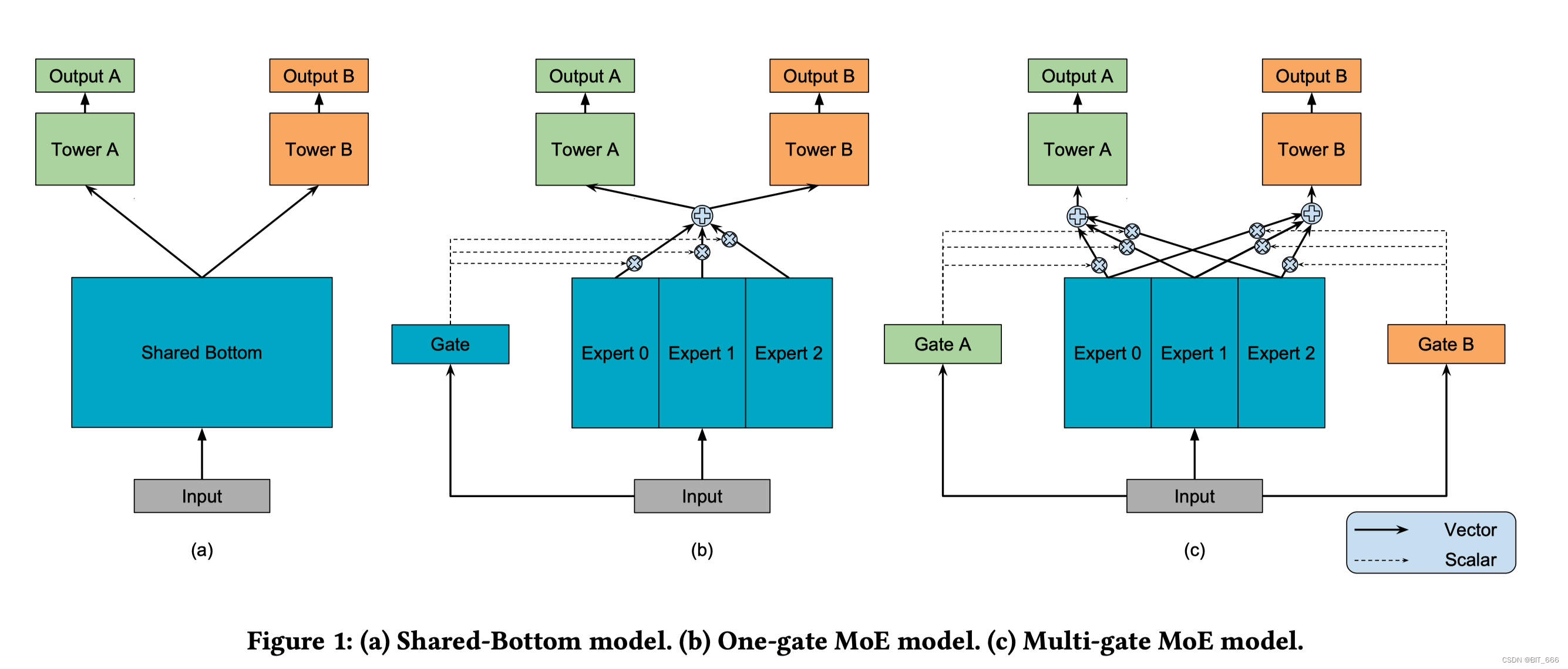
MMoE 几个 Expert 最终输出维度相同,Gate 输出维度与 Expert 数量相同,通过分析 Gate 的输出概率可以看出不同 Expert 对不同 Output 的测出,也可以控制 loss_weights 显式的指定某个 Output 占据主导地位。