官网引用


总结性
产生的需求

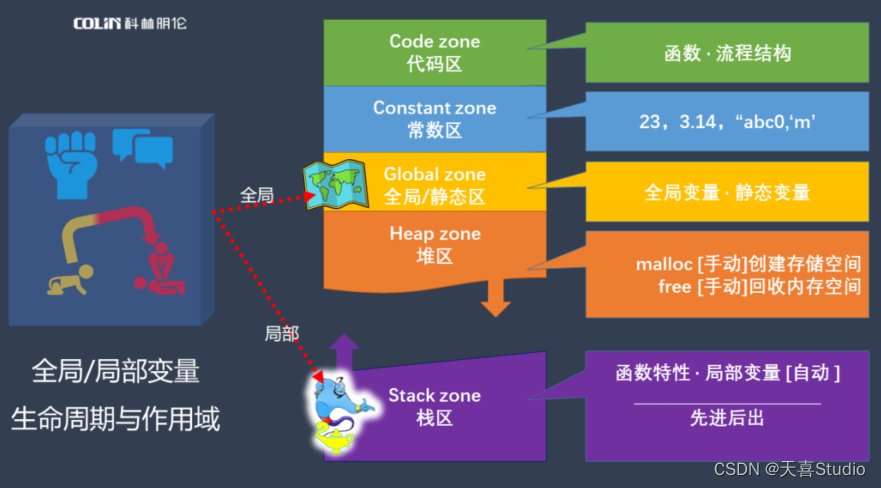
YARN工作逻辑
通用的资源管理系统,为上一层应用提供统一的资源管理和调度。解决集群资源利用率,数据共享,资源管理统一问题,yarn取代Job Tracker角色
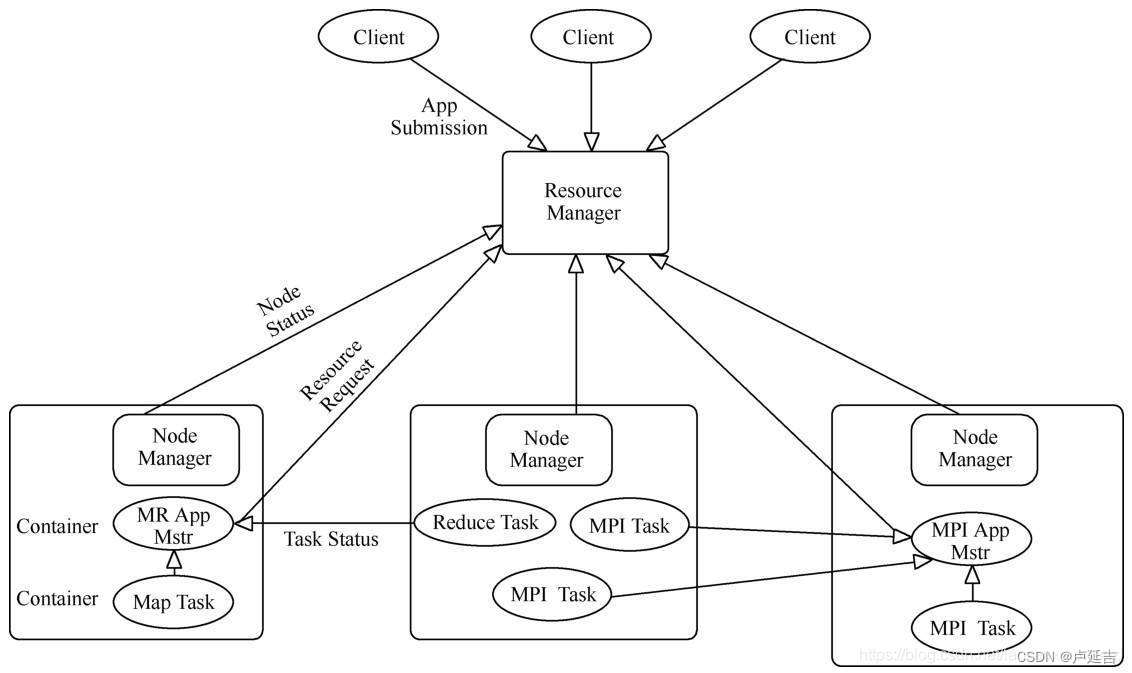
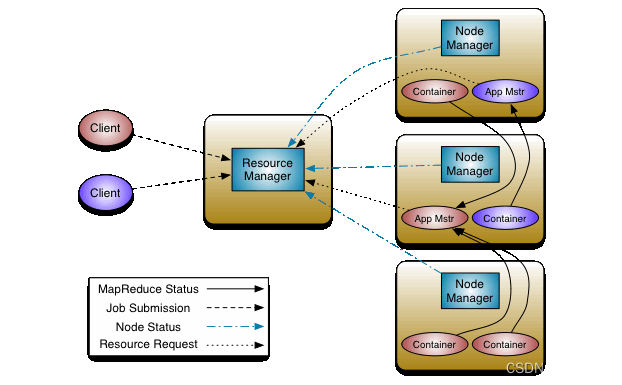
组件说明
- Client
向RM提交任务,终止任务。
- Resource Manager(RM)
一个集群中只有一个RM,一个RM对应多个NM
处理客户端的请求(启动/终止应用程序)
启动/监控AM,若AM挂掉,RM会在另一个NM节点启动AM
监控NM,接收NM汇报的心跳信息并分配任务给NM执行;一旦某个NM故障,标记下该NM上的任务,通知对应的AM如何处理。
- Node Manager(NM)
集群中有多个NM,负责单个节点资源管理和使用
周期性地通过心跳信息向RM汇报本节点上的资源使用情况和各个Container的运行状态
接收并处理来自RM的Container启动和停止的各种命令
- Application Master(AM)
对应每一个应用程序,负责应用程序的管理
AM向RM申请资源用在NM上启动相应的任务
为应用程序/作业向RM申请资源(Container),并分配给内部任务
与NM通信,已启动/停止任务
任务监控和容错,在任务执行失败时重新为该任务申请资源以重启任务
处理RM发过来的命令(终止Container,让NM重启)
- Container (任务运行环境的抽象)
任务是在Container中运行的,一个Container既可以运行AM,也可以运行具体的Map,Reduce,MPI,SparkTask
MapReduce作业启动时产生Map任务——Map Task
MPI框架对应执行任务——MPI Task
YARN架构设计
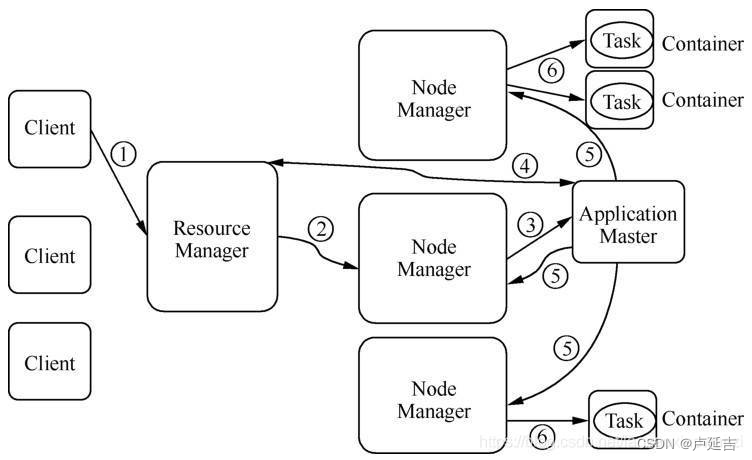
- 用户向YARN提交应用程序作业,包括AM程序,启动AM程序的命令和用户程序
- RM为作业分配第一个Container,并与对应的NM通信,要求它运行这个Container中启动该作业的AM
- AM首先向RM注册,这样用户就可以直接通过RM查询作业的运行状态;然后再为各个任务申请资源并监控任务的运行状态,直到运行结束(AM采取轮询的方式通过RPC请求向RM申请资源)
- AM一旦申请到资源,便与对应的NM通信,要求它启动任务
- NM启动任务
- 各个任务通过RPC协议向AM汇报自己的状态和进度,以便AM随时掌握各个任务的运行状态,从而在任务失败时重新启动任务
- 作业在运行过程中,用户可以随便通过RPC向AM查询作业的当前运行状态
- 作业完成后,AM向RM注销并关闭自己
yarn容错性
- RM可基于ZK实现HA,避免单点
- NM执行失败后,RM将失败任务高速对应的AM,由AM决定如何处理失败任务
- AM执行失败后,有RM负责重启(AM需要处理内部任务的容错问题,保存已经运行完成的Task,重启后不再运行)