目录
1、缓存介绍
2、http缓存
3、强缓存
4、协商缓存
1、缓存介绍
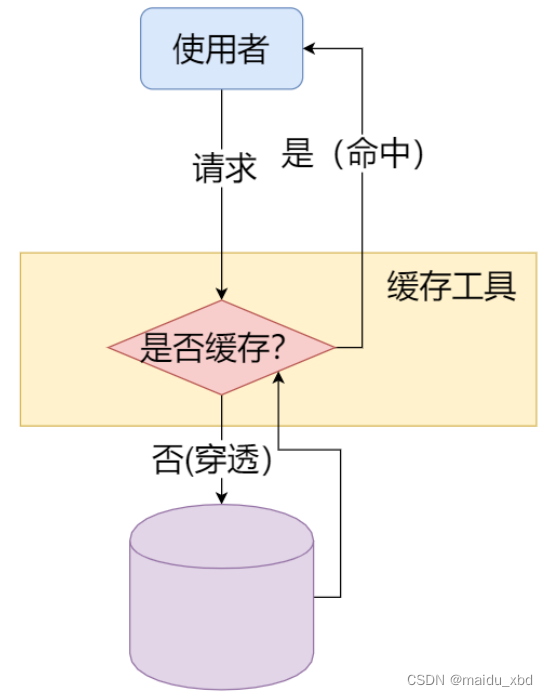
缓存:存储将被用的数据,让数据访问更快。
缓存相关术语
- 命中:在缓存中找到了请求的数据
- 不命中/穿透:缓存中没有需要的数据
- 命中率:命中次数/总次数
- 缓存大小:缓存中一共可以存多少数据
- 清空策略:如果缓存空间不够数据如何被替换
清空策略:FIFO先进先出;LFU-least Frequently used使用频率小的清除; LRU-Least recently used太久没使用的条目清理掉
2、http缓存
HTTP 缓存是web性能优化的重要手段,通过复用缓存资源,减少了服务器和客户端的通信次数,降低网络延迟,加速页面加载,解服务器端的压力。显著提升网站和应用的性能,提高用户体验
http缓存策略主要分为两种方式:强缓存 (浏览器端执行);协商缓存(服务器端执行)
优先级: 强缓存 > 协商缓存
3、强缓存
强缓存即强制直接使用缓存
强缓存的两种方式:【Expires】、【Cache-Control】,cache-control是expires的完全替代方案,在可以使用cache-control的情况下就不要使用expires
强缓存不会向服务器发送请求,直接从缓存中读取资源,在 chrome 控制台的 network 选项中可以看到该请求返回 200 的状态码,并且size显示from disk cache或from memory cache。
(1)Expires:该字段是HTTP1.0版本提出的,是浏览器访问服务器时,由服务器在Response Headers字段中设置该资源过期时间。Expires:<最后期限>;表示该请求在<最后期限>前使用缓冲资源,过后再次请求则请会请求服务器获取新的资源。Expires告诉浏览器该内容在何时过期,暗示浏览器在该内容过期之前不需要再询问服务器,而直接使用本地缓存即可。
(2)Cache-Control:该字段是HTTP1.1提出的,该字段的值是 过期时长(类似一种倒计时的功能),这样即使 服务器和浏览器日期时间不一致也不会导致Expires的问题,到了时间自动过期
Cache-Control:max-age=600;代表的是该请求的资源在600秒后过期, 600秒前使用缓存资源。
注意事项:
当Expires和Cache-Control同时存在时,优先使用HTTP1.1的Cache-Control
当强缓存的【Expires】、【Cache-Control】都不命中时,则进入协商缓存。
4、协商缓存
协商缓存就得和服务器协商确认下这个缓存能不能用
协商缓存的两种方式:【Last-Modified】、【ETag】,ETag并不是last-modified的完全替代方案,而是补充方案,具体用哪一个,取决于项目业务场景,无孰好孰坏之分
(1)Last-Modified:通过比对资源文件的修改时间进行协商缓存
Response Headers携带:Last-Modified:<昨天>
Request Headers携带:IF-Modified-Since:<昨天>
表示最后修改时间,是指请求的资源的最后修改时间,在浏览器第二次访问服务器时,会在Request Headers的If-Modified-Since中带上该字段的值(值来自服务器),服务器接到请求后,会对If-Modified-Since的值与该请求资源的最后修改时间进行对比,若请求的资源最后修改时间大于If-Modified-Since的值,则返回新的资源,并重新设置Last-Modified字段的值。
Last-Modified存在问题:
- 在文件内容本身不修改的情况下,依然有可能更新文件修改时间(比如修改文件名再改回来),此时文件内容并没有修改,缓存依然失效了
- 因为文件修改时间记录的最小单位是秒,所以当文件在几百毫秒内完成修改的时候,文件修改时间并不会改变,这样,即使文件内容修改了,依然不会返回新的文件
(2)ETag:通过生成文件内容的唯一哈希值,即文件指纹进行协商缓存
E-Tag没有采用内容的最后修改时间,而是采用了一串编码来标记内容,称为ETag
Response Headers携带:E-Tag:1234567
Request Headers携带:If-None-Match:1234567
如果两个文件指纹完全吻合,说明文件没有被改变,则直接返回304状态码和一个空的响应体并return。如果两个文件指纹不吻合,则说明文件被更改,那么将新的文件指纹重新存储到响应头的ETag中并返回给客户端
ETag缺点:
- 需要文件尺寸大,数量多,并且计算频繁,那么服务端就需要更多的计算开销,从而影响服务器的性能
- ETag有强验证和弱验证,所谓强验证,ETag生成的哈希值深入到每个字节,从而保证文件内容绝对的不变,非常消耗计算量;弱验证则是提取文件的部分属性来生成哈希值,因此不必精确到每个字节,所以整体速度会比强验证快,但是精确率不高,会降低协商缓存的有效性
参考文章: