Contents
- 0. 引言
- 0.1 关联规则挖掘
- 0.2 Apriori算法
- 实验
- Step 1:Familiarize yourself with the arules package in R.
- 1.1 Load the package.
- 1.2 To load data into R enter.
- 1.3 To get information about the total number of transactions in a file sample1.csv enter:
- 1.4 To get a summary of data set sample1.csv enter:
- 1.5 接下来,列出最频繁的项目和每个交易的项目分布。
0. 引言
0.1 关联规则挖掘
关联规则挖掘(Association Rule Mining)是一种在大型数据集中发现变量之间有趣关系的数据挖掘方法。它用于寻找数据中频繁出现的项集(itemsets)以及基于这些项集的关联规则。关联规则挖掘的一个典型应用场景是购物篮分析,即分析顾客购买商品之间的关系,以便为商家提供有关产品组合、促销活动和陈列布局的建议。
关联规则挖掘主要包括两个步骤:
频繁项集挖掘(Frequent Itemset Mining):找出数据集中经常一起出现的项集。为了度量项集的频繁程度,我们使用支持度(support)这个指标。支持度表示某个项集在所有事务中出现的频率。通常会设置一个最小支持度阈值,只保留达到阈值的频繁项集。
关联规则生成:基于频繁项集,生成表达项之间关系的关联规则。关联规则通常表示为 “X -> Y”,其中 X 是规则的前件(lhs),Y 是规则的后件(rhs)。为了评估关联规则的质量,我们使用两个指标:置信度(confidence)和提升度(lift)。置信度表示规则前件出现时规则后件同时出现的概率;提升度表示规则前件和后件的关联程度,即它们是相互独立还是有某种关联。
在关联规则挖掘中,常用的算法有 Apriori、Eclat 和 FP-growth 等。这些算法在挖掘频繁项集和生成关联规则时采用了不同的策略和优化技术,以提高挖掘效率和降低计算复杂度。
总之,关联规则挖掘是一种探索数据中项之间关系的方法,广泛应用于购物篮分析、推荐系统、异常检测等领域。
0.2 Apriori算法
Apriori算法是一种用于关联规则挖掘的经典算法,主要用于发现频繁项集(在数据集中频繁出现的项组合)以及基于这些项集生成关联规则。Apriori算法由Agrawal和Srikant于1994年提出,主要应用于购物篮分析等场景。Apriori算法的核心思想是通过逐步构建候选项集并利用先验知识剪枝,从而减少计算量。
Apriori算法主要包含两个阶段:
频繁项集挖掘:算法从包含一个项的项集开始,逐步增加项集的大小,直到不能找到更大的频繁项集。在每一步中,算法会计算当前候选项集的支持度(support),即项集在数据集中的出现频率,并根据给定的最小支持度阈值筛选出频繁项集。为了减少计算量,Apriori算法利用一个重要的性质:任何非频繁项集的超集也必然是非频繁的。这意味着如果一个项集不满足最小支持度要求,那么包含这个项集的更大的项集也不可能满足最小支持度要求。利用这个性质,算法可以在构建候选项集时剪枝,避免计算不必要的项集。
关联规则生成:基于挖掘到的频繁项集,生成满足最小置信度阈值的关联规则。对于每个频繁项集,算法会产生所有可能的规则组合(例如,对于频繁项集{A, B, C},可能的规则有 A->B, A->C, B->A, B->C, C->A, C->B, A->BC, B->AC, C->AB等)。然后计算这些规则的置信度(confidence),并根据给定的最小置信度阈值筛选出有效的关联规则。
尽管Apriori算法在关联规则挖掘中具有较好的性能,但它仍然面临一些挑战,例如计算候选项集的数量可能会很大,导致计算效率较低。为了解决这些问题,后续研究者提出了更高效的算法,如FP-growth和Eclat等。
实验
改变工作区
setwd("/Users/Library/w8-lab05")
注意R语言里用的是正斜杠/,而不是windows里的反斜杠\,来表示地址
Step 1:Familiarize yourself with the arules package in R.
1.1 Load the package.
library(arules)
# 如果没有arules包,就下载
install.packages("arules", dependencies = TRUE)
1.2 To load data into R enter.
sample1.transactions <- read.transactions("sample1.csv", sep=",")
read.transactions()函数是 R 语言中arules
包的一个重要函数。它的主要功能是从文件或其他数据源读取交易数据,并将数据转换为适用于关联规则挖掘的格式。在关联规则挖掘中,交易数据通常是一个包含多个项集(items)的事务(transactions)集合。每个事务代表一个包含多个项的记录,例如购物篮中的商品。
read.transactions()函数接受多种参数,以便处理不同类型和格式的数据源。下面是一些常见参数的解释:
file:输入文件的路径和名称。它可以是一个 CSV 文件、R 语言的数据框(data.frame)或其他格式的文件。sep:用于分隔数据项的字符。例如,如果数据项是以逗号分隔的,可以设置sep=","。format:输入数据的格式。read.transactions()支持多种数据格式,如 “basket”(逗号分隔的项集),“single”(数据框中每行表示一个项)等。根据数据源的格式选择适当的选项。cols:指定从数据源中读取的列。此参数用于仅选择包含所需数据的列。rm.duplicates:是否删除事务中的重复项。默认为TRUE,表示自动删除重复项。在将数据读入
read.transactions()函数后,可以将其作为输入传递给关联规则挖掘算法,如 Apriori算法。arules包的其他函数(如summary()和
inspect())可以用于查看和分析处理后的交易数据及挖掘出的关联规则。
1.3 To get information about the total number of transactions in a file sample1.csv enter:
sample1.transactions
output:

输出结果表明,sample1.transactions 数据集包含 10 条交易记录(行)和 5
个不同的项(列)。这是对数据集基本结构的描述。“transactions in sparse format”
表明数据以稀疏格式存储。稀疏格式是一种高效存储和处理包含大量零值的数据的方法。在关联规则挖掘中,稀疏格式非常实用,因为事务中只包含少数项,而其他项则缺失(即值为零)。稀疏格式仅存储非零值,从而节省存储空间和计算资源。
在这个示例中,10 条交易记录(行)表示数据集包含 10 个事务。每个事务可以是一个购物篮、一次在线浏览会话或其他类似场景。5 个项(列)表示数据集中有 5 个不同的商品或其他实体。这些项可以是购物篮中的商品、网站上的页面或其他类型的数据。
sample1.csv如下图所示,的确包含10条交易记录,一共有五种不同的商品

1.4 To get a summary of data set sample1.csv enter:
summary(sample1.transactions)
output:

- “transactions as itemMatrix in sparse format with 10 rows (elements/itemsets/transactions) and 5 columns (items) and a density of 0.48”:这部分描述了数据集的基本结构。数据集包含 10 行(事务)和 5 列(项),以稀疏格式存储。稀疏矩阵的密度是 0.48,表示 48% 的单元格是非零值,即数据集中 48% 的事务-项组合是有效的。
- “most frequent items: butter beer bread milk sausage (Other)”:这部分列出了数据集中最频繁出现的项,及其出现的次数。在这个示例中,butter 出现了 6 次,beer、bread 和 milk 分别出现了 5 次,sausage 出现了 3 次。
- "element (itemset/transaction) length distribution: “sizes” 下方的四个数字(1、2、3、5)表示事务长度,即事务中包含的项数。在这个示例中,长度为 1 的事务有 2 个,长度为 2 的事务有 4 个,长度为 3 的事务有 3 个,长度为 5 的事务有 1 个。
- 下面的统计信息描述了事务长度的分布情况:最小值(Min.)为 1,第一四分位数(1st Qu.)为 2,中位数(Median)为 2,平均值(Mean)为 2.4,第三四分位数(3rd Qu.)为 3,最大值(Max.)为 5。
- “includes extended item information - examples: labels”:这部分显示了一些示例项的标签。在这个示例中,项的标签为 “beer”、“bread” 和 “butter” 等。
注意:
在输出结果的 “includes extended item information - examples”
部分,仅展示了一些项的示例标签,而不是所有项的标签。这是为了让用户快速了解数据集中的一些项,而不需要显示所有可能的项。在这个示例中,仅显示了
“beer”、“bread” 和 “butter” 这三个标签,而没有显示 “milk” 和 “sausage”。实际上,这些标签仅作为示例,帮助用户了解数据集中的项。如果需要查看所有项的标签,可以使用其他方法和函数来获取完整的项信息。例如,使用
itemInfo()函数可以返回所有项的详细信息,包括标签:item_info <- itemInfo(sample1.transactions) item_info这将返回一个包含所有项标签的数据框。

1.5 接下来,列出最频繁的项目和每个交易的项目分布。
在我们的案例中,2个交易包含一个项目,4个交易包含两个项目,3个交易包含三个项目,1个交易包含四个项目。为了发现关联规则,请输入:
sample1.apriori <- apriori(sample1.transactions)
output:

这段代码的输出描述了使用
apriori()函数对sample1.transactions
数据集执行关联规则挖掘时的相关参数和执行过程。下面对输出的各部分进行解释:
“Apriori”:表示正在使用 Apriori 算法执行关联规则挖掘。
“Parameter specification” 部分列出了用于执行 Apriori 算法的参数设置。以下是一些主要参数的解释:
confidence: 置信度阈值,规则必须达到此置信度才会被保留。这里设置为 0.8,表示只保留置信度大于或等于 0.8 的规则。support: 支持度阈值,项集必须达到此支持度才会被保留。这里设置为 0.1,表示只保留支持度大于或等于 0.1 的项集。minlen和maxlen: 规则的最小和最大长度。这里设置为 1 和 10,表示保留长度在 1 到 10 之间的规则。- 其他参数:包括一些用于优化算法性能的设置,如
maxtime(最大运行时间)和memopt(内存优化)等。“Algorithmic control” 部分列出了一些用于控制 Apriori 算法执行的参数。这些参数用于调整算法性能和输出结果的详细程度。
“Absolute minimum support count: 1”:表示绝对最小支持计数为 1,即项集至少出现在一个事务中才满足最小支持度要求。
接下来的输出描述了 Apriori 算法执行的各个阶段及其用时。包括设置项外观(item appearances)、设置事务(transactions)、对项进行排序和重新编码、创建事务树(transaction
tree)以及检查不同大小的子集等。“writing … [29 rule(s)] done”:表示找到了 29 条符合指定参数的关联规则。
“creating S4 object”:表示创建了一个 S4 类型的对象来存储挖掘结果。在 R 语言中,S4 对象是一种用于存储复杂数据结构的对象类型。
总之,这段输出描述了使用 Apriori 算法对
sample1.transactions
数据集执行关联规则挖掘的过程及参数设置。算法找到了 29 条满足支持度和置信度阈值的关联规则。
支持度(support):度量一个项集在所有事务中的出现频率。它是一个介于0和1之间的值,表示项集在数据集中的频繁程度。设置最小支持度阈值的目的是筛选出在数据集中出现频次较高的项集,这有助于减少需要处理的项集数量,从而提高关联规则挖掘的效率。
置信度(confidence):度量关联规则的可靠性。对于一个规则 X -> Y,置信度表示在所有包含X的事务中,同时包含Y的事务所占的比例。置信度越高,说明规则在数据集中的表现越好。设置最小置信度阈值的目的是筛选出具有较高可靠性的关联规则,这有助于找到在实际应用中更有价值的规则。
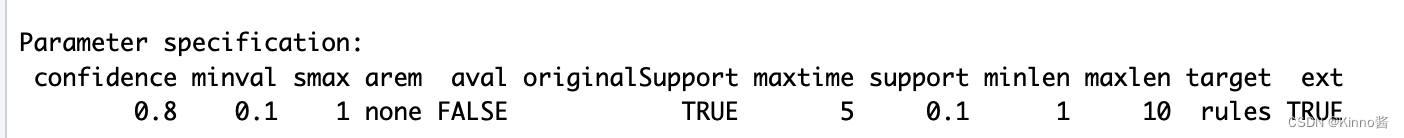
- 在Parameter specification中,以下是各属性的含义:
| 属性名 | 含义 |
|---|---|
| confidence | 关联规则的最小置信度阈值。只有置信度大于或等于此阈值的规则会被保留。 |
| minval | 最小置信度提升值(lift)阈值。置信度提升是评估关联规则兴趣度的一种方法,表示规则X->Y的置信度与Y的支持度之间的比值。只有具有大于或等于此阈值的置信度提升的规则才会被保留。 |
| smax | 最大支持度阈值。只有支持度小于或等于此阈值的项集才会被考虑。 |
| arem | 关联规则评估度量的简写,用于指定评估关联规则的度量方法。例如,可以使用"confidence"(默认),"lift"等。 |
| aval | 用于指定度量方法的参数。例如,当arem为"lift"时,aval可以用于设置最小提升值。 |
| originalSupport | 布尔值,指示是否使用原始数据集的支持度计数。如果为TRUE,则保留原始数据集的支持度计数;如果为FALSE,则在计算支持度时使用样本数据集。 |
| maxtime | 算法运行的最大时间(以秒为单位)。 |
| support | 关联规则的最小支持度阈值。只有支持度大于或等于此阈值的频繁项集会被保留。 |
| minlen | 关联规则的最小长度。规则的长度是指规则左侧和右侧项的总数。只有长度大于或等于此阈值的规则才会被保留。 |
| maxlen | 关联规则的最大长度。只有长度小于或等于此阈值的规则才会被保留。 |
| target | 指定关联规则挖掘的目标类型。例如,可以设置为"rules"(生成关联规则,这是默认设置)或"itemsets"(仅挖掘频繁项集) |
| ext | 布尔值,指示是否返回包含扩展信息(例如关联规则的置信度、支持度和提升值)的结果对象。如果为TRUE,则返回扩展信息;如果为FALSE,则不返回。 |

在Algorithmic control部分,以下是各属性的含义:
| 属性名 | 含义 |
|---|---|
| filter | 频繁项集过滤阈值。在Apriori算法中,频繁项集的生成过程会涉及到多次候选项集的生成和测试。filter参数用于控制在某个阶段是否对候选项集进行过滤。设置为0.1表示在每个阶段过滤掉频繁度低于0.1的项集。 |
| tree | 布尔值,表示是否使用事务树(transaction tree)数据结构来存储事务数据。事务树可以提高Apriori算法的计算效率。设置为TRUE表示使用事务树。 |
| heap | 布尔值,表示是否使用堆(heap)数据结构来存储待处理的候选项集。使用堆可以提高算法的内存利用率和运行速度。设置为TRUE表示使用堆。 |
| memopt | 布尔值,表示是否对算法进行内存优化。内存优化可以在一定程度上降低算法的内存需求,但可能会增加计算时间。设置为FALSE表示不进行内存优化。 |
| load(不确定,需要问老师) | 布尔值,表示是否在内存中加载整个数据集。设置为TRUE表示一次性将整个数据集加载到内存中,这可以提高算法的运行速度,但会增加内存需求。设置为FALSE表示按需加载数据,这可以降低内存需求,但可能会降低运行速度。 |
| sort(不确定,需要问老师) | 整数值,表示项集排序的程度。值越大,排序程度越高,但可能会增加计算时间。设置为2表示使用中等排序程度。排序可以在一定程度上提高算法的运行速度,特别是在处理大数据集时。 |
| verbose | 布尔值,表示是否输出详细的算法执行信息。设置为TRUE表示输出详细信息,这有助于理解算法的运行过程和调试。 |