目录索引
- ==requests请求:==
1. 基于get请求:- *基础写法:*
- *带参数的get请求:*
2. 基于post请求:
- ==获取数据:==
1. 获取json数据:2. 获取二进制数据:
引入:
requests是python的第三方库,采用的是Apache2 Licensed开源协议的HTTP库
换言之,也就是requests是一个Python代码编写的HTTP请求库,方便在代码中模拟浏览器发送http请求。
requests请求:
#举个例子:
import requests
#取一个变量名来接收请求
response = requests.get('https://www.baidu.com/')
print(response)#响应体对象(响应源码+响应状态码+响应URL)
print(response.text)#查看响应体的内容
print(type(response.text))#查看响应内容的数据类型
print(response.status_code)#查看响应状态码
print(response.url)#查看响应的url
呈现效果:
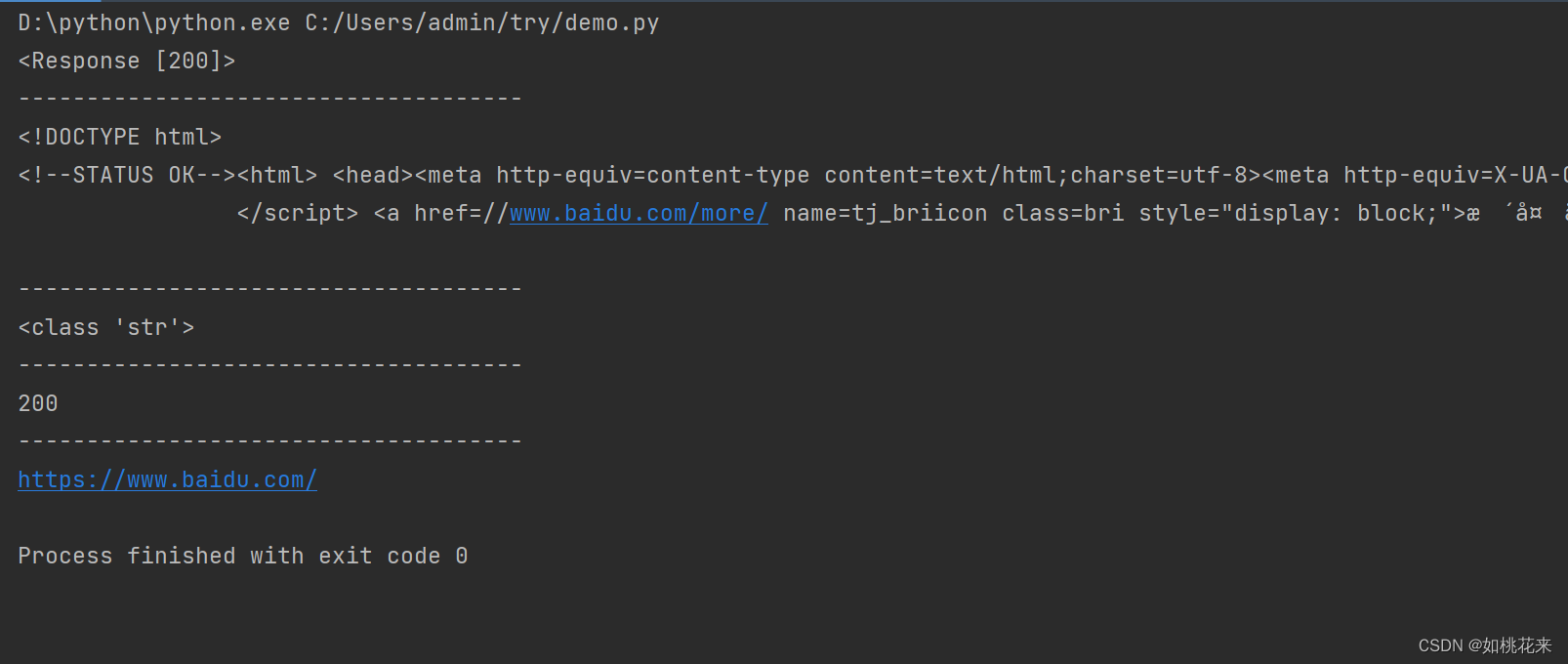
注意: 这里的虚线是为了区分特意添加的,没写在代码中。
下面讲述请求方法,主要是get请求和post请求
requests.get('http://httpbin.org/get') # GET请求
requests.post('http://httpbin.org/post') # POST请求
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
1. 基于get请求:
基础写法:
- 测试网站:http://httpbin.org/get(这是一个测试网站)
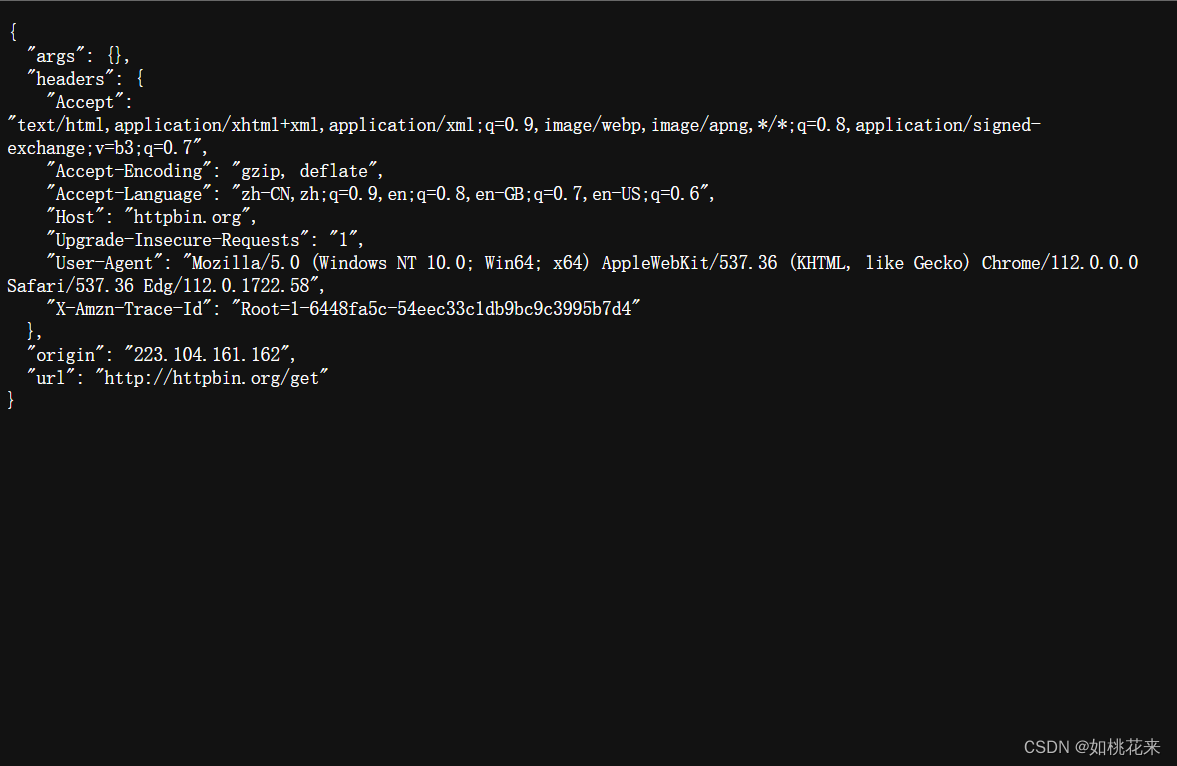
import requests
url = "http://httpbin.org/get" #把我们的目标站点保存在url变量中
r = requests.get(url)#发出get请求
print(r.status_code)#获取状态码
print(r.text)#获取响应内容
print(type(r.text))#text属性里面提取的信息都是字符串类型
带参数的get请求:
第一种写法:
- 把参数直接跟在网址的后方
import requests
#https://www.baidu.com/?tn=15007414_8_dg
url = "https://www.baidu.com/?tn=15007414_8_dg"
r = requests.get(url)
print(r.status_code)#获取状态码,200为正常
print(r.text)
在网址的后面由?来传递参数,每个属性之间用&符连接,比如:http://httpbin.org/get?name=lisi&age=10。
第二种写法:
- 把参数采用关键字传参的方式传入(推荐!)
import requests
#把参数单独构建在字典中
data_message = {
"name":"xiaoming",
"sex":"男"
}
url = "http://httpbin.org/get"
r=requests.get(url,params=data_message)#params:携带get请求的参数
print(r.text)
注意:
- get请求的关键字参数是params
- 字典的键值对之间别忘记用逗号隔开
呈现效果:
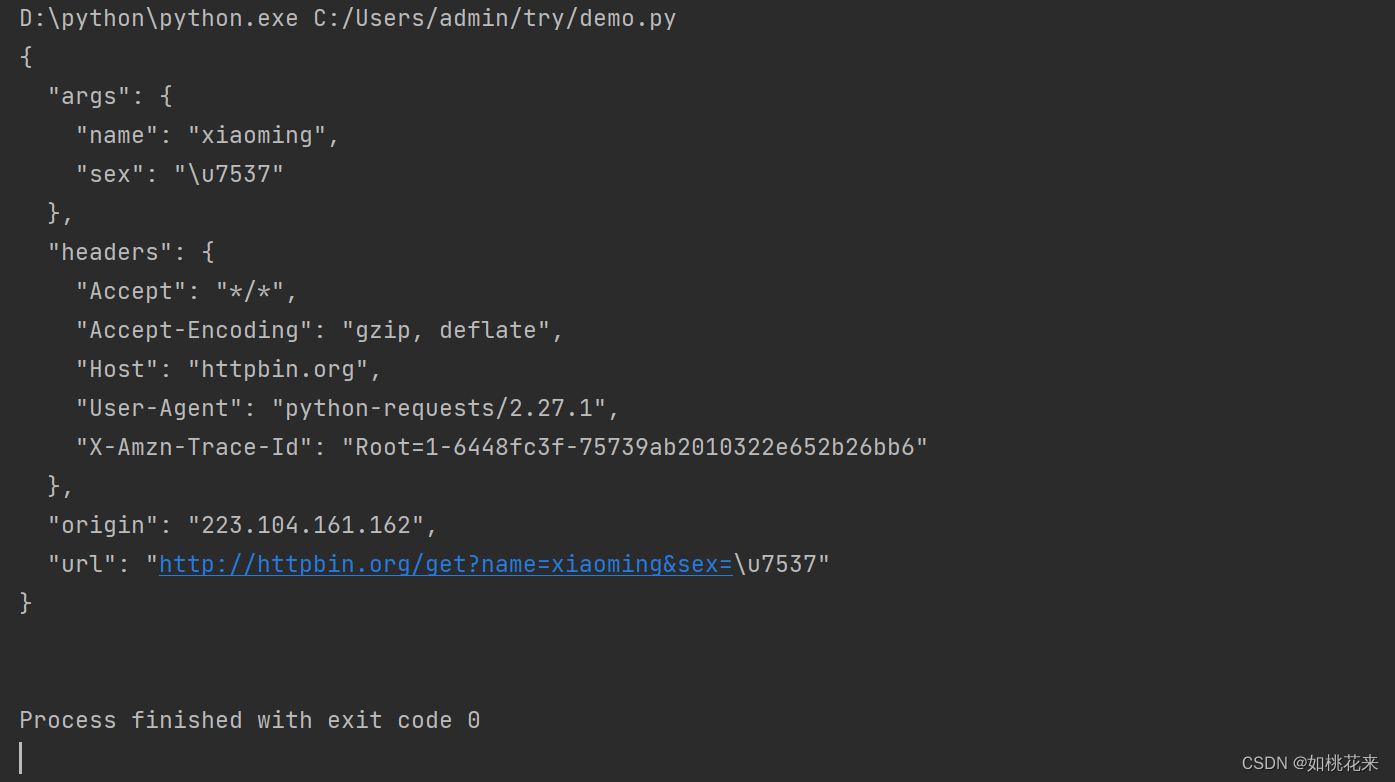
对比我们可以发现,get请求中我们传入的参数都在args内部。记忆:params中带有ar,那么参数都在args内部。
2. 基于post请求:
测试网站: http://httpbin.org/post
这个网站直接打开是打不开的,因为浏览器不能直接打开post请求,虽然不能直接打开,但是可以通过代码进行测试
import requests
url = "http://httpbin.org/post"
data_message = {
"name":"小明",
"age":10
}
r = requests.post(url,data=data_message)#data:携带post请求的参数
print(r.text)
呈现效果:
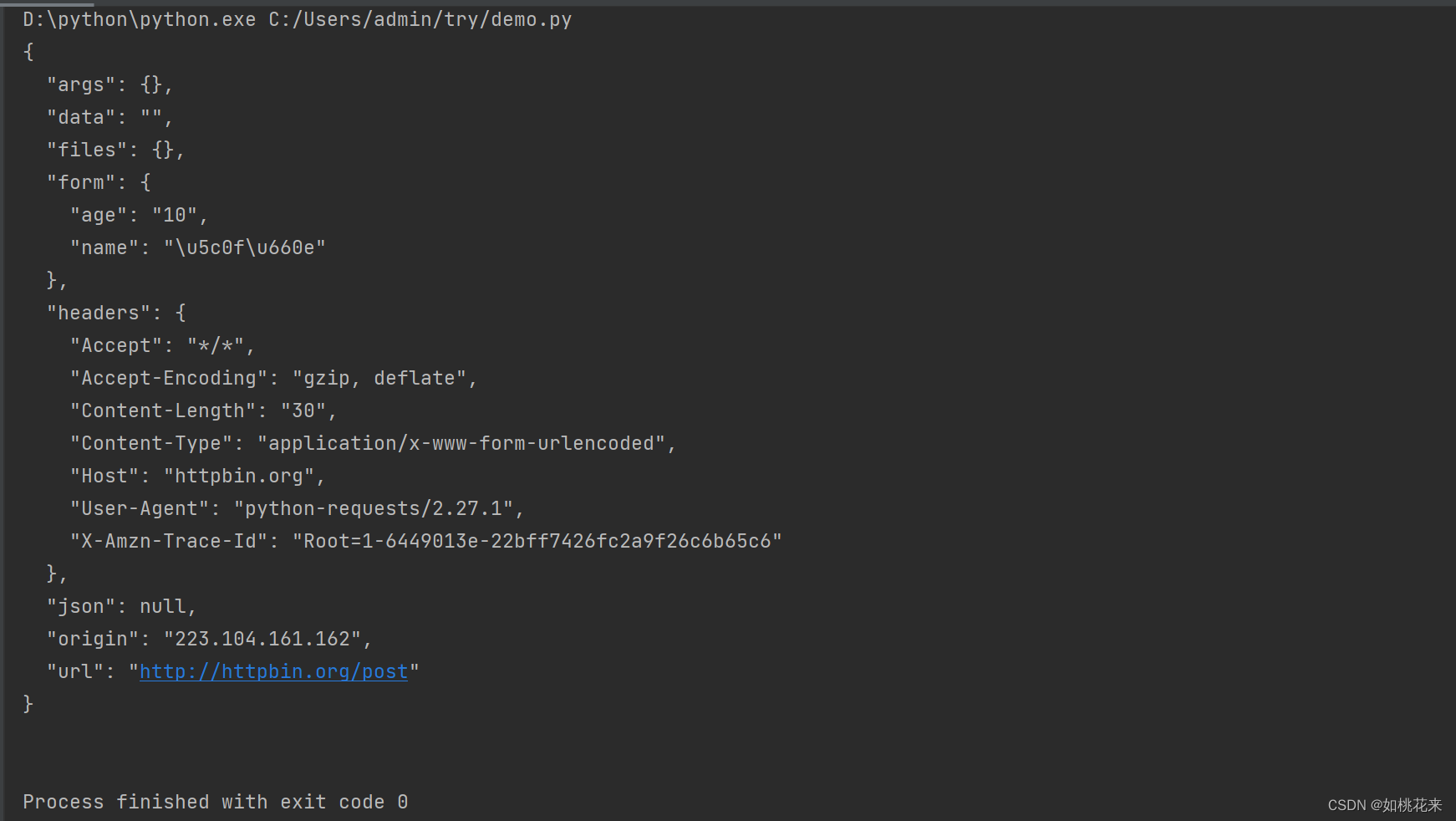
注意: post请求的参数是存储在form中的
总结:
- get请求和post请求传递参数的方式是不一样的,get是通过params传递的,post是通过data进行传递的。由开发人员规定。
获取数据:
1. 获取json数据:
json是种数据格式,长得跟字典特别像。具体区别不在这里展开叙述。json和字典可以通过json模块进行转化。
import requests
import json
url = "http://httpbin.org/get"
r = requests.get(url)
print(r.status_code)
a = r.text#获取里面的数据
dict_data = json.loads(a)#将字符串转化为字典类型
print(dict_data)
print(type(dict_data))
呈现效果:
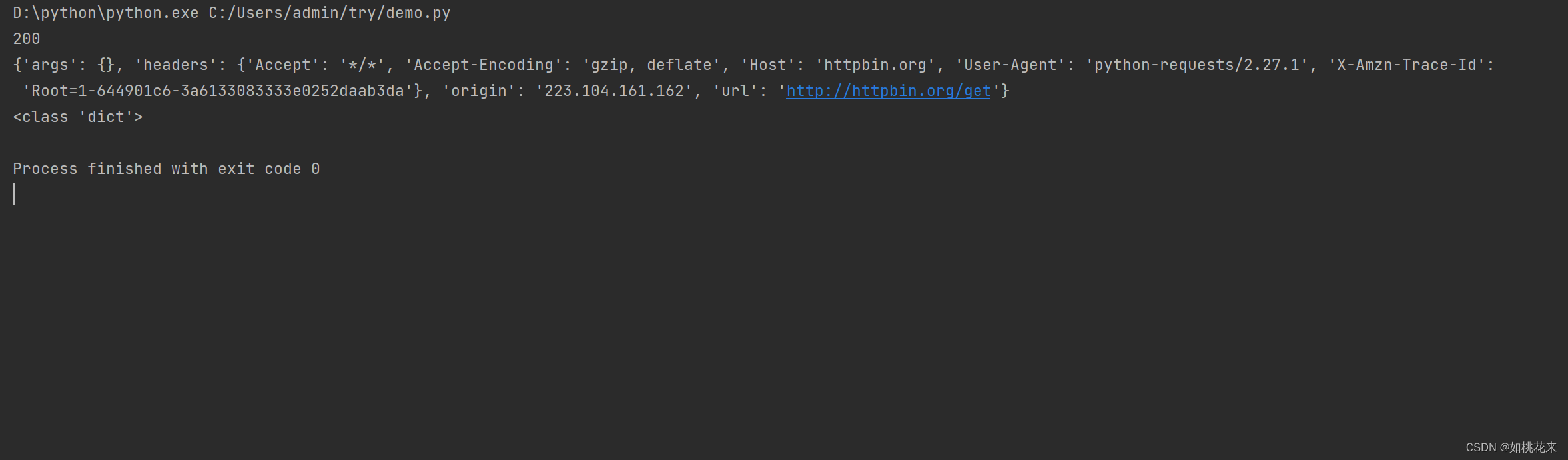
- 试想一下: 我们该如何拿到User-Agent后面的数据?
#只写了添加代码
res = dict_data["headers"]["User-Agent"]#涉及字典嵌套的知识
print(res)
- 但是这样太麻烦了,下面有一种方法可以直接获取json数据的源代码,数据类型是字典
- 注意: json模块是模块,json()方法是方法,注意区别。使用json方法不需要引入json模块
import requests
url = "http://httpbin.org/get"
r = requests.get(url)
print(r.status_code)
a = r.json()#获取里面的数据
print(a)
print(type(a))#自动将数据类型转换成了字典
呈现效果:

2. 获取二进制数据:
- 获取二进制数据的时候,不用text属性获取,而是使用content属性专门获取二进制数据
- 二进制数据是以字节形式存在的:
bytes类型是指一堆字节的集合,在python中以b开头的字符串都是bytes类型- 一个字节使用两个16进制数来表示: 1个16进制数对应4个二进制数位,2个16进制数位对应8个二进制数位,所以一个字节占8位
Bytes类型的作用:
- 1, 在python中, 数据转成2进制后不是直接以0101010的形式表示的,而是用一种叫bytes(字节)的类型来表示
- 2,计算机只能存储2进制, 我们的字符、图片、视频、音乐等想存到硬盘上,也必须以正确的方式编码成2进制后再存。
记住一句话: 在python中,字符串必须编码成bytes后才能存到硬盘上
总结:
- 获取正常文本数据用==.text属性==
- 获取json数据用==.json()方法==
- 获取二进制数据用==.content属性==