目录
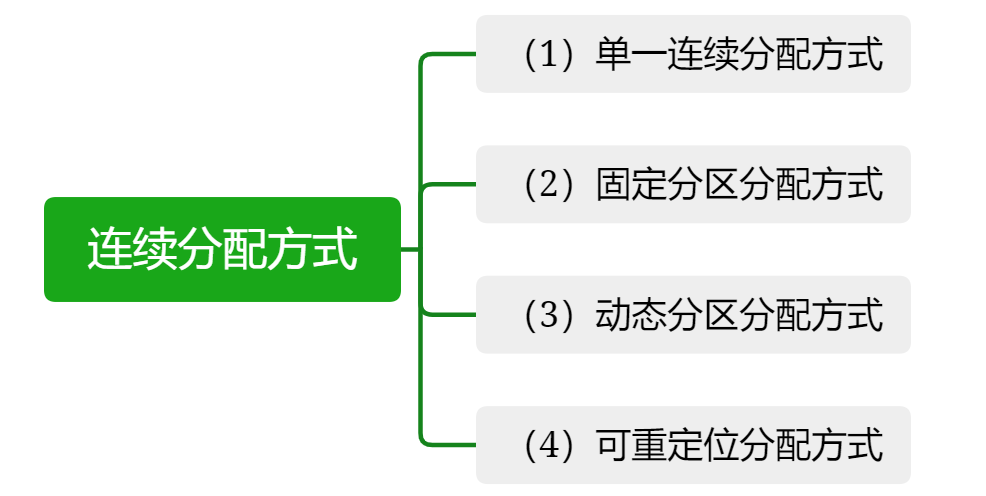
4.3.1 单一连续分配
4.3.2 固定分区分配
1. 分区说明表
2. 内存分配过程
4.3.3 动态分区分配
一、分区分配中数据结构
二、分区分配算法
三、分区分配操作
4.3.4 可重定位分区分配
1. 紧凑
2. 动态重定位
3. 动态重定位分区分配算法
连续分配是指为用户程序分配一个连续的内存空间。
因为程序空间本来就是连续的,所以用连续的内存装入连续的程序能够减少管理工作的难度。
4.3.1 单一连续分配
单一连续分配:内存中仅装有一道用户程序,即整个内存的用户空间由该程序独占。
在单道程序环境下,当时的存储器管理方式是把内存分为两部分:系统区和用户区。系统区仅提供给 OS 使用,它通常是放在内存的低址部分。而在用户区内存中,仅装有一道用户程序,即整个内存的用户空间由该程序独占。


4.3.2 固定分区分配
将整个内存用户空间划分为若干个固定大小的区域,每个区域称为一个分区(region),在每个分区中只装入一道作业 ,从而支持多道程序并发设计。

1. 分区说明表
分区说明表:指出可用于分配的分区数以及每个分区的起始地址、大小及状态。其中,各分区是按其大小进行排队的。
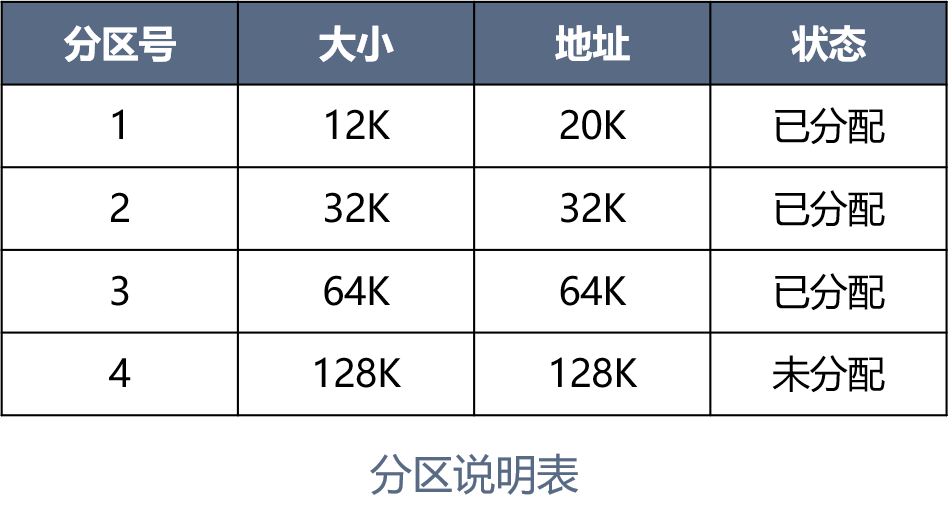
Q:为什么第一个分区的地址不是从 0 开始的?
A:因为内存的低址存放的是系统区的内容。
2. 内存分配过程
作业装入内存时,内存分配程序检索分区说明表,从中找出一个尚未使用的满足大小要求的分区分配给该作业,然后修改分区的状态。如果找不到合适的分区就拒绝为该作业分配内存。

内存中已分配给用户的但未被使用的区域称为 “内零头”,而采用固定分区分配方式将会产生内零头。比如:下例中的作业 B 得到 64KB 的分区,但是只使用了 30KB 的大小。

固定分区分配方式
特点:采用分区说明表这一数据结构记录分区的大小和使用情况。
优点:易于实现,开销小。
缺点:
- 内零头造成浪费
- 分区总数固定,限制了并发执行的程序数目
- 存储空间的利用率太低
现在的操作系统几乎不用这种方式了。
4.3.3 动态分区分配
动态分区分配又称为可重定位分区分配,它是根据进程的实际需要,动态地为之分配连续的内存空间。即分区的边界可以移动,且分区的大小是可变的。
虽然动态分区分配中还是有划分内存区域这个概念,但是在实际分配中可以根据实际需要动态地修改分区的大小 (?)

一、分区分配中数据结构
常用的数据结构有以下两种形式,选其一即可。
1. 空闲分区表

虽然空闲分区表和分区说明表长得很像,但是两者的区别还是蛮大的:
- 空闲分区表只记录空闲的分区
- 因此这些分区的地址不是连续的
- 空闲分区表中的分区没有按顺序排列
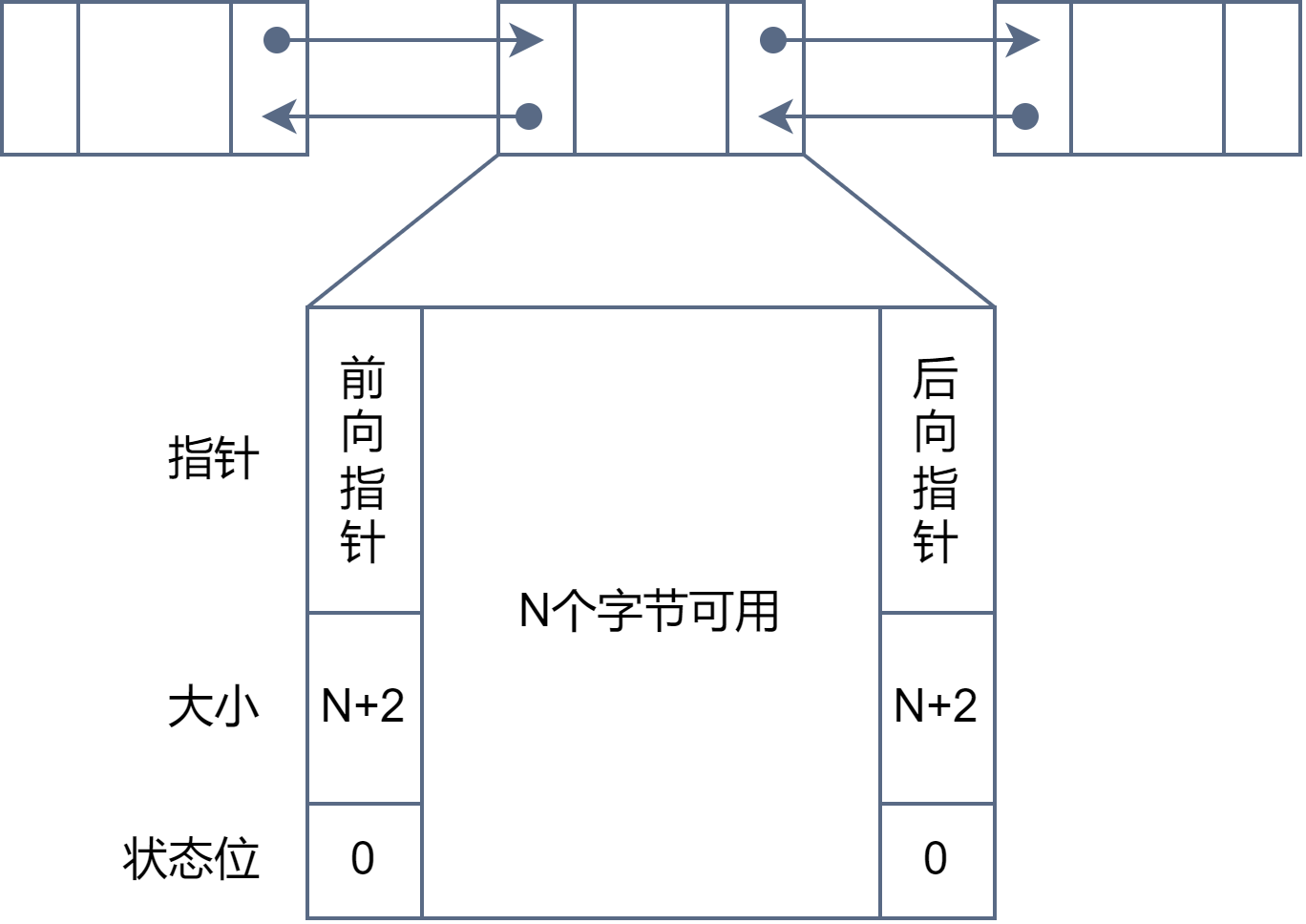
2. 空闲分区链
在每个分区的首部和尾部设置一些用于控制分区分配的信息,其中重复设置了分区大小和状态位表目,这是为了方便检索。
二、分区分配算法

三、分区分配操作
涉及动态分区分配的主要操作有分配内存和回收内存。
这些操作是在应用程序接口中通过系统调用发出的。
1. 分配内存
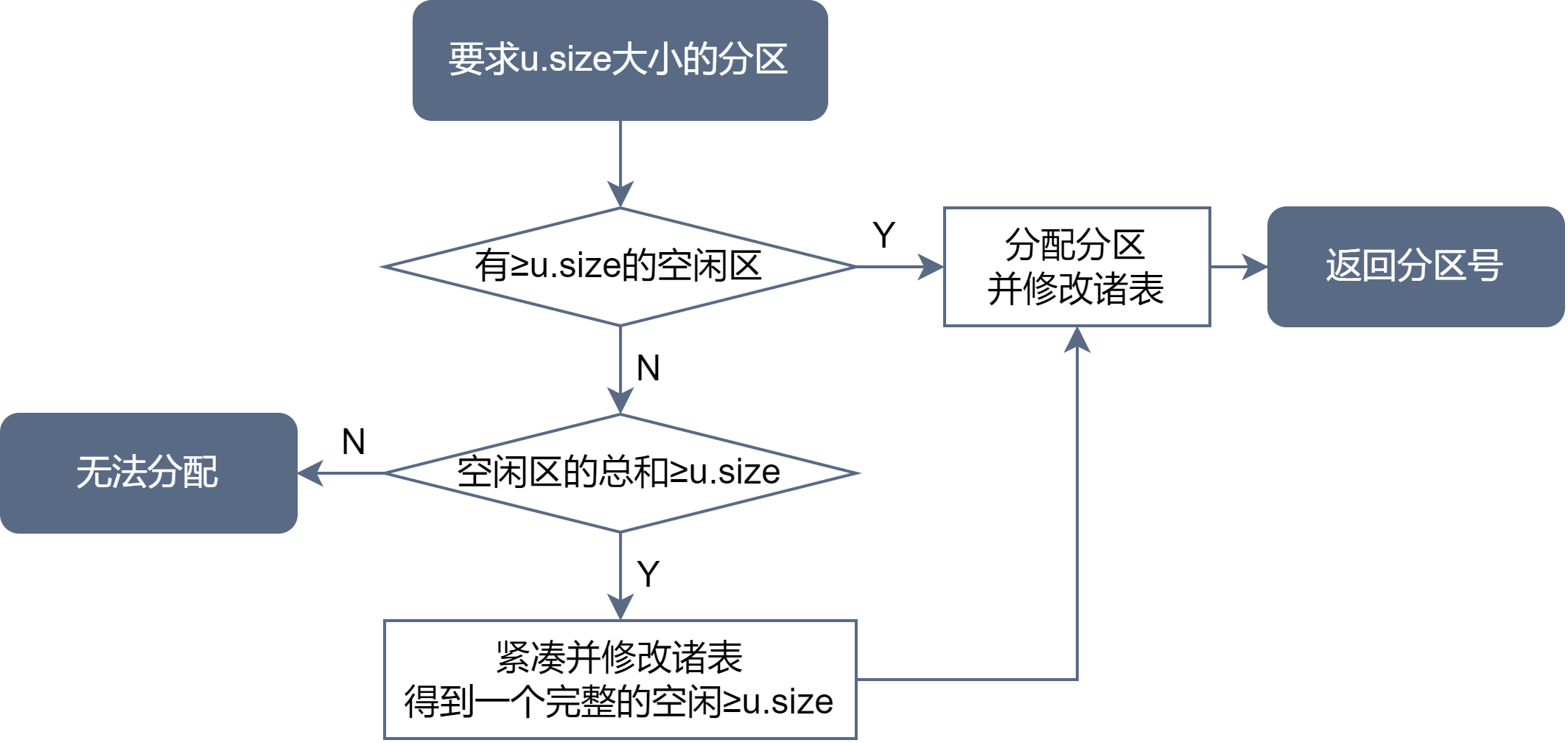
分配内存:向操作系统提出一特定存储量的请求。它并不要求这个分配的存储区域位于特定的位置,但是这个区域必须是连续的。
系统利用某种分配算法,从空闲分区表或链中找到所需大小的分区。
- 请求的分区大小为 u.size
- 表中每个空闲分区的大小为 m.size
- 事先规定不再切割的剩余分区的大小为 size
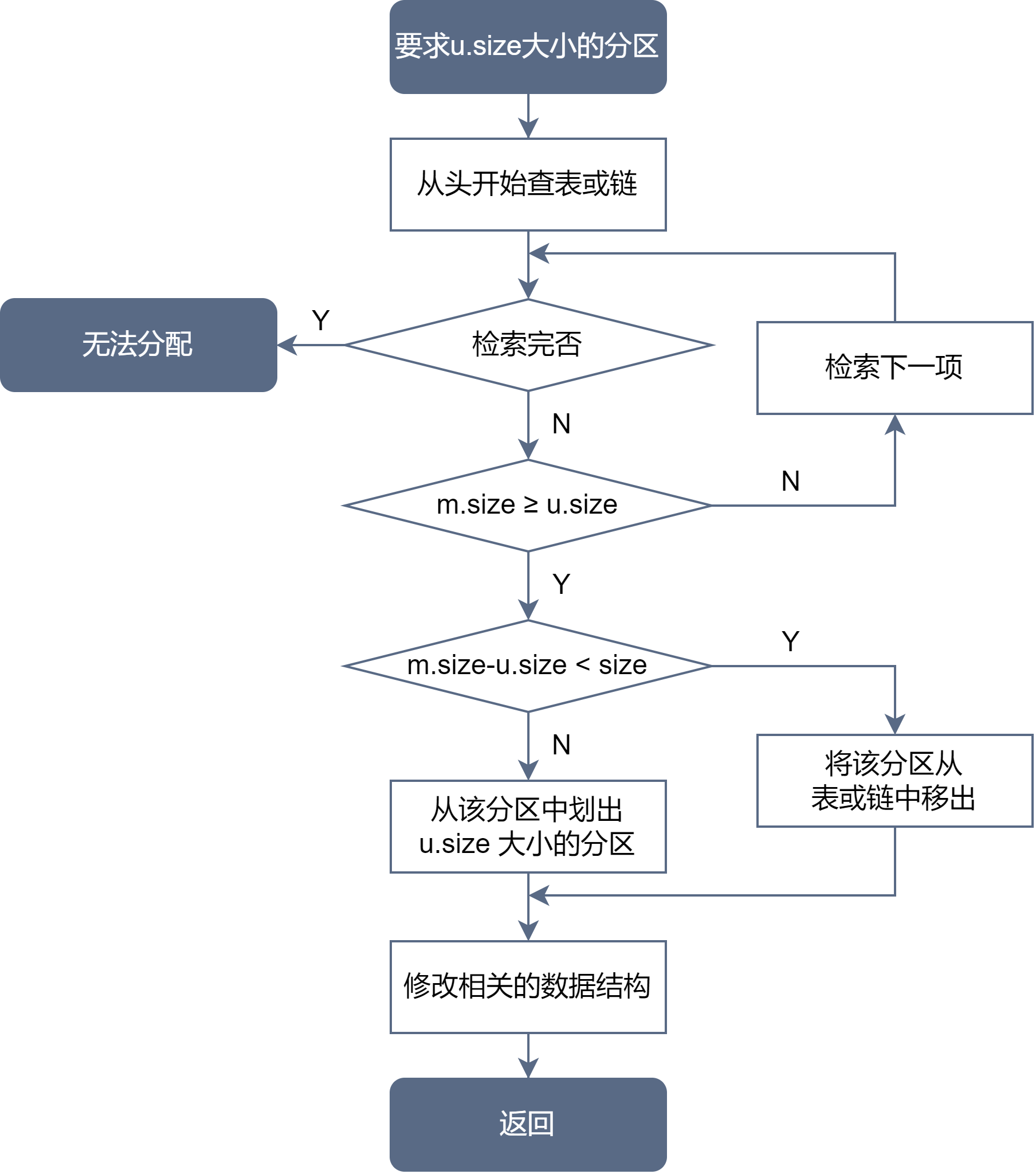
从原分区划出分区时可能形成外零头:虽然剩余区域大小大于 size,但是仍可能因为太小了而长期不能被分配出去。将该分区从表或链中移出时将会产生内零头,除非 m.size = u.size 成立。
2. 回收内存
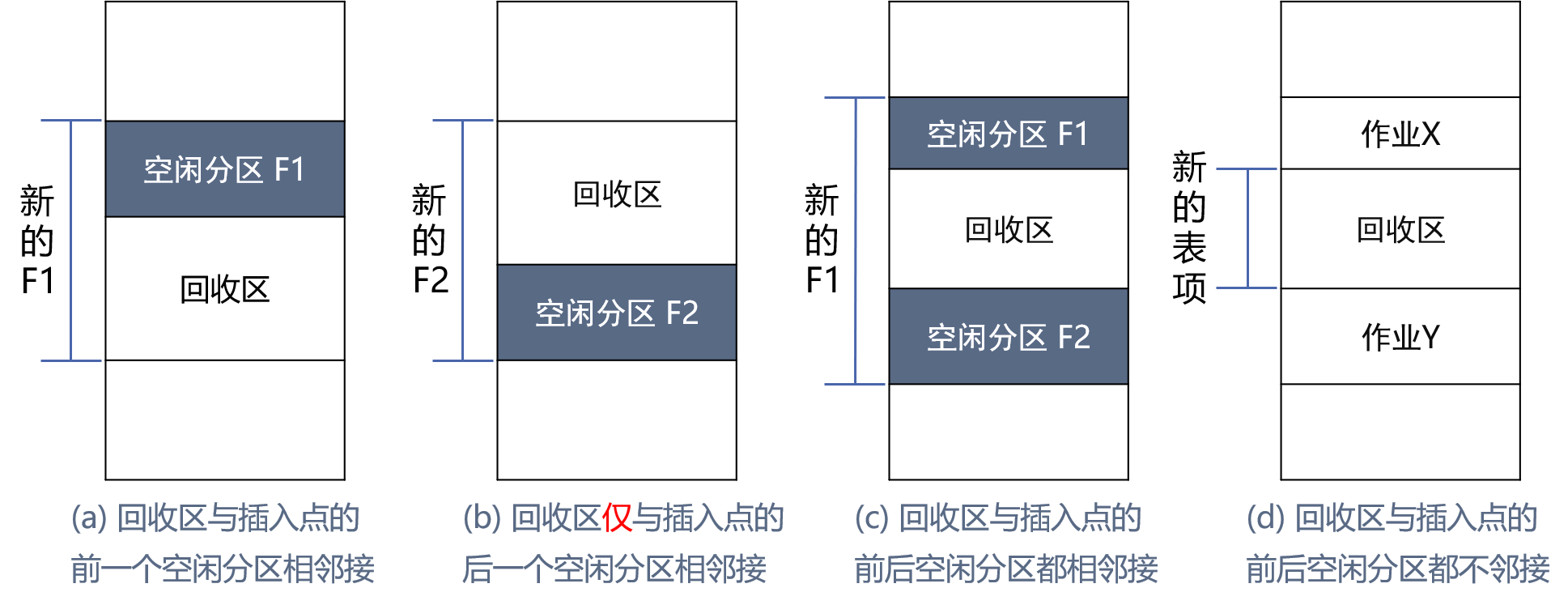
回收内存:当进程运行完毕释放内存时,系统根据回收区的首址,从空闲区表或链中找到相应的插入点,插入回收的内存。
一个回收的分区与空白区邻接的情况有四种,对这四种情况分别作如下处理:
4.3.4 可重定位分区分配
1. 紧凑
将内存中的所有作业进行移动,使它们全都相邻接,把原来分散的多个小分区合成一个大分区。
连续分配方式的一个重要特点是,一个系统程序或用户程序必须被装入一片连续的内存空间中,因此需要一个连续的大的空闲分区。

需要解决的问题:把一个作业从一个存储区域移动到另一个存储区域时,需要对作业中的某些地址部分和地址常数等进行调整。
2. 动态重定位
在动态运行时装入的方式中,作业装入内存后的所有地址都仍然是相对地址,将相对地址转换为物理地址的工作,被推迟到程序指令要真正执行时进行。
程序在执行时,真正访问的内存地址是相对地址与重定位寄存器中的地址相加而形成的。

3. 动态重定位分区分配算法
动态重定位分区分配算法与动态分区分配算法基本上相同,差别仅在于:在这种分配算法中,增加了紧凑的功能。