论文:https://arxiv.org/pdf/2010.03045.pdf
本文提出了可以有效解决跨维度交互的triplet attention。相较于以往的注意力方法,主要有两个优点:
1.可以忽略的计算开销
2.强调了多维交互而不降低维度的重要性,因此消除了通道和权重之间的间接对应。
传统的计算通道注意力的方法为了计算这些通道的权值,输入张量在空间上通过全局平均池化分解为一个像素。这导致了空间信息的大量丢失,因此在单像素通道上计算注意力时,通道维数和空间维数之间的相互依赖性也不存在。后面提出基于Spatial和Channel的CBAM模型缓解了空间相互依赖的问题,但是通道注意和空间注意是分离的,计算是相互独立的。基于建立空间注意力的方法,本文提出了跨维度交互作用(cross dimension interaction)的概念,通过捕捉空间维度和输入张量通道维度之间的交互作用,解决了这一问题。
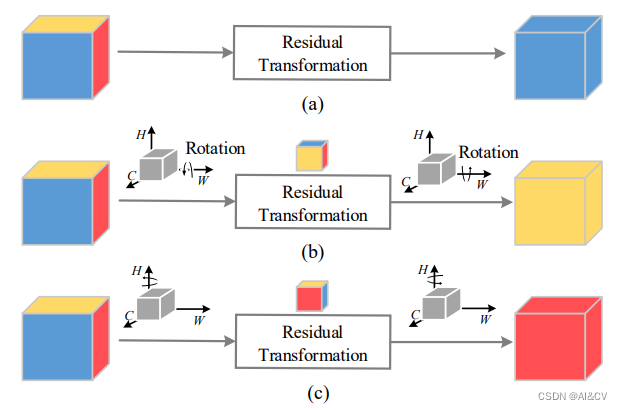
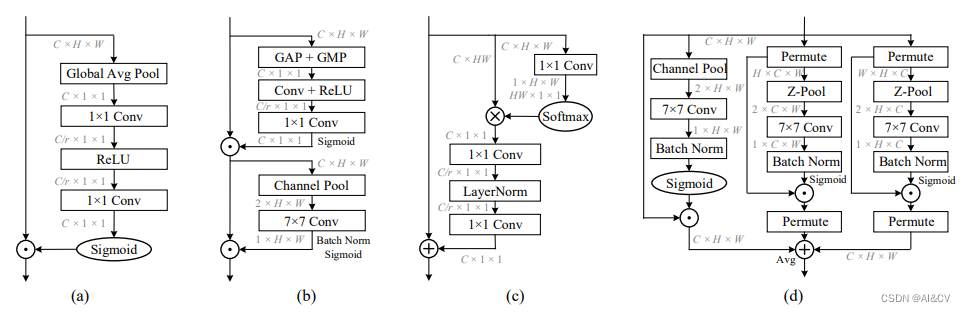
所提出的Triplet Attention如下图所示,Triplet Attention由3个平行的Branch组成,其中两个负责捕获通道C和空间H或W之间的跨维交互。最后一个Branch类似于CBAM,用于构建Spatial Attention,最终3个Branch的输出使用平均求和。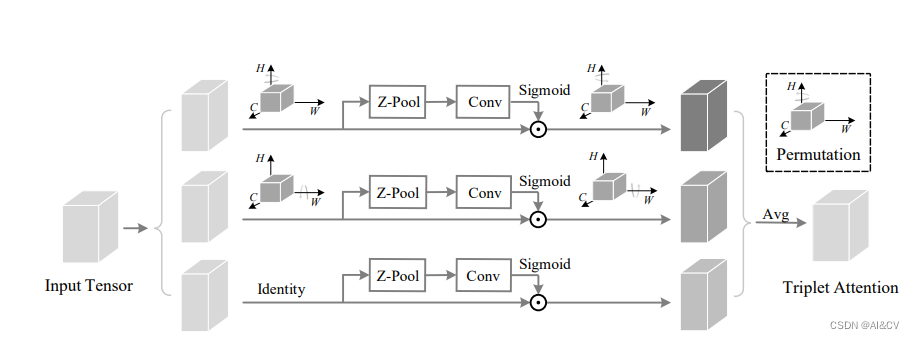
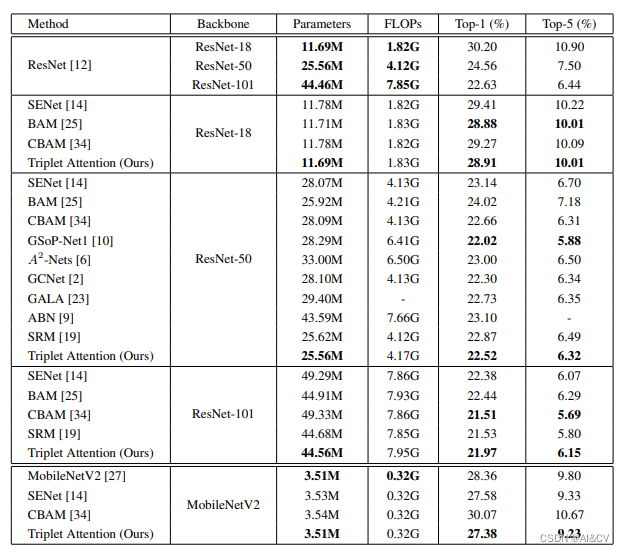
效果优于CBAM、SE
2.Triplet加入Yolov5
2.1Triple加入common.py
###################### TripletAttention #### start by AI&CV ###############################
class BasicConv(nn.Module): #https://arxiv.org/pdf/2010.03045.pdf
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True,
bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding,
dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ZPool(nn.Module):
def forward(self, x):
return torch.cat((torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1)
class AttentionGate(nn.Module):
def __init__(self):
super(AttentionGate, self).__init__()
kernel_size = 7
self.compress = ZPool()
self.conv = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.conv(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, no_spatial=False):
super(TripletAttention, self).__init__()
self.cw = AttentionGate()
self.hc = AttentionGate()
self.no_spatial = no_spatial
if not no_spatial:
self.hw = AttentionGate()
def forward(self, x):
x_perm1 = x.permute(0, 2, 1, 3).contiguous()
x_out1 = self.cw(x_perm1)
x_out11 = x_out1.permute(0, 2, 1, 3).contiguous()
x_perm2 = x.permute(0, 3, 2, 1).contiguous()
x_out2 = self.hc(x_perm2)
x_out21 = x_out2.permute(0, 3, 2, 1).contiguous()
if not self.no_spatial:
x_out = self.hw(x)
x_out = 1 / 3 * (x_out + x_out11 + x_out21)
else:
x_out = 1 / 2 * (x_out11 + x_out21)
return x_out
###################### TripletAttention #### END by AI&CV ###############################2.2Triple加入yolo.py
def parse_model(d, ch): 加入以下代码
elif m is TripletAttention:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, *args[1:]]2.3 修改yolov5s_TripletAttention.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 6 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, TripletAttention,[1024]], # 23 (P5/32-large)
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]