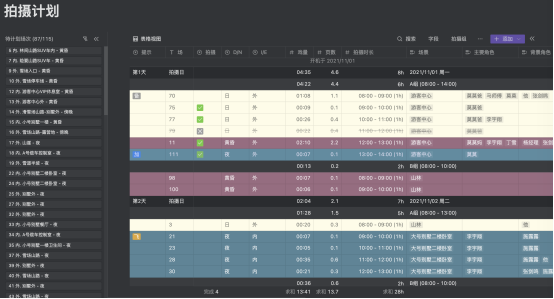
在客户的数据库RAC集群环境中,节点2发生了异常,最终通过重启解决。在节点2发生异常的10分钟左右时间内,由于RAC集群节点2异常,此时节点1的database实例无法提供服务问题,程序操作报超时;
对此现象,不符合ORACLE RAC集群涉及时一个节点宕机另一个节点可以正常提供服务的逻辑,对此问题我们结合各方面的日志,深入分析情况如下:
1.节点1性能问题发生的时间是从13:41:27 到13:46:01。 主要的等待是row cache lock 和enq: SQ - contention相关sequence的竞争,
2.等待log file sync 的前台进程等待在lgwr进程。 LGWR进程等待在广播scn 的wait for scn ack的等待上,这样节点1卡住了。
3.在此期间,由于节点2异常,大量程序的进程都连接到节点1,加剧了节点一的性能问题。
1.数据库ALERT日志
数据库alert日志显示,13:42:40秒开始出现LGWR进程无响应80秒,推算13:41:20秒出现问题,持续到13:45:45分,节点1检查到节点2异常,开始进行实例的Reconfiguration,13:45:51时完成,系统即恢复正常。
2023-01-13T13:40:47.088414+08:00
Completed checkpoint up to RBA [0xf3c3.2.10], SCN: 21009928480
2023-01-13T13:41:42.160952+08:00
KQR: cid 10 bucket 5658 marked HOT
KQR: cid 10 bucket 3669 marked HOT
2023-01-13T13:42:40.638888+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 80 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 78 secs.
2023-01-13T13:42:50.658728+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 90 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 88 secs.
2023-01-13T13:43:00.631001+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 100 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 98 secs.
2023-01-13T13:43:03.888993+08:00
DIA0 Critical Database Process As Root: Hang ID 2 blocks 139 sessions
Final blocker is session ID 9076 serial# 41758 OSPID 46269442 on Instance 1
If resolvable, instance eviction will be attempted by Hang Manager
2023-01-13T13:43:10.649386+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 110 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 108 secs.
2023-01-13T13:43:20.929922+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 121 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 118 secs.
2023-01-13T13:43:25.977776+08:00
DIA0 Critical Database Process As Root: Hang ID 4 blocks 1 sessions
Final blocker is session ID 9197 serial# 261 OSPID 9700264 on Instance 1
If resolvable, instance eviction will be attempted by Hang Manager
2023-01-13T13:43:27.030420+08:00
KQR: cid 10 bucket 3669 marked HOT
2023-01-13T13:43:30.737647+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 130 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 128 secs.
2023-01-13T13:43:31.108405+08:00
KQR: cid 10 bucket 3669 marked HOT
2023-01-13T13:43:31.255920+08:00
KQR: cid 10 bucket 3669 marked HOT
2023-01-13T13:43:37.140541+08:00
KQR: cid 10 bucket 3669 marked HOT
2023-01-13T13:43:41.003629+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 141 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 138 secs.
2023-01-13T13:43:50.711162+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 150 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 148 secs.
2023-01-13T13:43:53.023365+08:00
DIA0 Critical Database Process As Root: Hang ID 4 blocks 2 sessions
Final blocker is session ID 9197 serial# 261 OSPID 9700264 on Instance 1
If resolvable, instance eviction will be attempted by Hang Manager
2023-01-13T13:44:00.826390+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 161 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 158 secs.
2023-01-13T13:44:10.800697+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 171 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 168 secs.
2023-01-13T13:44:20.898910+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 181 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 178 secs.
2023-01-13T13:44:30.860429+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 191 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 188 secs.
2023-01-13T13:44:32.981457+08:00
KQR: cid 10 bucket 3669 marked HOT
2023-01-13T13:44:33.483355+08:00
KQR: cid 10 bucket 3669 marked HOT
2023-01-13T13:44:40.846847+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 201 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 198 secs.
2023-01-13T13:44:50.960891+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 211 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 208 secs.
2023-01-13T13:45:00.998718+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 221 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 218 secs.
2023-01-13T13:45:10.977777+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 231 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 228 secs.
2023-01-13T13:45:20.926153+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 241 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 238 secs.
2023-01-13T13:45:31.329679+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 251 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 249 secs.
2023-01-13T13:45:36.607969+08:00
KQR: cid 10 bucket 3669 marked HOT
2023-01-13T13:45:40.977875+08:00
LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 261 secs.
CKPT (ospid: 9700264) waits for event 'enq: XR - database force logging' for 258 secs.
2023-01-13T13:45:45.394435+08:00
Increasing priority of 8 RS
Reconfiguration started (old inc 6, new inc 8)
List of instances (total 1) :
1
Dead instances (total 1) :
2
My inst 1
^
2023-01-13T13:45:51.802394+08:00
Reconfiguration complete (total time 6.4 secs)
Decreasing priority of 8 RS
2023-01-13T13:45:51.955245+08:00
Instance recovery: looking for dead threads
2023-01-13T13:45:51.989728+08:00
Beginning instance recovery of 1 threads
parallel recovery started with 10 processes
Thread 2: Recovery starting at checkpoint rba2.数据库性能数据
分析数据库性能,结合ASH性能基表数据分析,数据库异常时段,主要性能问题为严重的library cache lock/enq: SQ - contention/row cache lock等待,从13:42:40秒持续到01.45.39秒,01.45.51节点Reconfiguration完成后性能恢复正常。
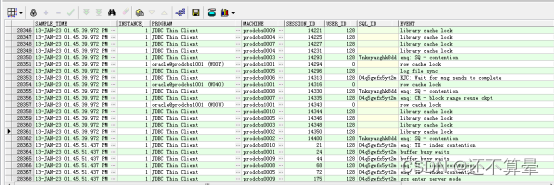
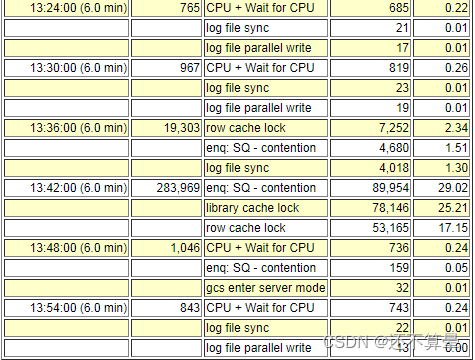
3.节点2数据库日志
数据库日志显示,节点2在13:41:19进行关闭,使用的ORACLE instance (abort)方式。13:44:25秒关闭完成。
2023-01-13T13:35:43.744996+08:00
ARC2 (PID:41157284): Archived Log entry 192858 added for T-2.S-37593 ID 0x64a5b8c1 LAD:1
2023-01-13T13:39:27.002339+08:00
Incremental checkpoint up to RBA [0x92d9.1d4ca.0], current log tail at RBA [0x92da.2b56.0]
2023-01-13T13:40:47.054397+08:00
Completed checkpoint up to RBA [0x92da.2.10], SCN: 21009929552
2023-01-13T13:41:19.537924+08:00
Shutting down ORACLE instance (abort) (OS id: 40567812)
2023-01-13T13:41:19.540206+08:00
Shutdown is initiated by oraagent.bin@test1002 (TNS V1-V3).
License high water mark = 5107
USER (ospid: 40567812): terminating the instance
2023-01-13T13:41:19.550602+08:00
opiodr aborting process unknown ospid (66913238) as a result of ORA-1092
2023-01-13T13:41:20.339957+08:00
Process termination requested for pid 23332742 [source = unknown], [info = 0]
……………………
2023-01-13T13:44:25.810533+08:00
Warning: 2331 processes are still attacheded to shmid 5243912:
(size: 65536 bytes, creator pid: 44761608, last attach/detach pid: 40567812)
Instance shutdown complete (OS id: 40567812)
2023-01-13T13:52:40.097865+08:00
Starting ORACLE instance (normal) (OS id: 6750924)总结节点1性能异常系统HANG住问题:
节点1数据库alert日志显示,13:42:40秒开始出现LGWR进程无响应80秒(LGWR (ospid: 46269442) waits for event 'wait for scn ack' for 80 secs),推算13:41:20秒出现问题,持续到13:45:45分,节点1检查到节点2异常,开始进行实例的Reconfiguration,13:45:51时完成,系统即恢复正常。LGWR进程无相应引起大量业务进程的阻塞( Hang ID 2 blocks 139 sessions,Final blocker is session ID 9076 serial# 41758 OSPID 46269442……)
节点2数据库alert日志显示,在13:41:19进行关闭,使用的ORACLE instance (abort)方式; 13:44:25秒数据库关闭完成。
时间线如下:
-
- 节点1性能问题发生的时间是从13:41:27 到13:46:01。 主要的等待是row cache lock 和enq: SQ - contention相关sequence的竞争,
- 等待log file sync 的前台进程等待在lgwr进程。 LGWR进程等待在广播scn 的wait for scn ack的等待上,此时节点1卡主。
- 在此期间,由于节点2异常,大量程序的进程都连接到节点1,加剧了节点一的性能问题(节点2在13:41:19进行关闭,使用的ORACLE instance (abort)方式,到13:44:25秒关闭完成。)
分析数据库性能,结合ASH性能基表数据分析,数据库异常时段,主要性能问题为严重的library cache lock/enq: SQ - contention/row cache lock等待,从13:42:40秒持续到01.45.39秒,01.45.51节点Reconfiguration完成后性能恢复正常。节点1 的性能问题是受到节点2 关闭实例的影响(节点1LGWR进程 HANG),同时也由于节点2的异常大量进程连接节点1,加剧了性能问题。直到节点1完成了重配,节点1恢复正常。






![[极客大挑战 2019]Havefun、[ACTF2020 新生赛]Include、[SUCTF 2019]EasySQL](https://img-blog.csdnimg.cn/070d1f4a3cd34343b6856dccaa6c8a7e.png)