全景视觉里程计、同时做全景分割和视觉里程计
连接:PVO: Panoptic Visual Odometry
0.Abstract
我们提出了一种新的全景视觉里程计框架PVO,以实现对场景运动、几何和全景分割信息的更全面的建模。我们将视觉里程计(VO)和视频全景分割(VPS)在一个统一的视图下进行建模,使这两个任务相互受益。具体来说,我们在图像全景分割的指导下,在VO模块中引入了全景更新模块。这个PanopticEnhanced VO模块可以通过一个全景感知的动态掩模来减轻动态对象对相机姿态估计的影响。另一方面,VO- enhanced VPS模块利用VO模块获取的相机姿态、深度、光流等几何信息,将当前帧的全景图像分割结果实时融合到相邻帧中,从而提高了分割精度。这两个模块通过循环迭代优化相互促进。大量的实验表明,在视觉里程计和视频全景分割任务中,PVO的性能优于目前最先进的方法。(双sota)
1. Introduction
理解场景的运动、几何和全景分割在计算机视觉和机器人技术中扮演着至关重要的角色,应用范围从自动驾驶到增强现实。在这项工作中,我们采取一步来解决这个问题,通过单目视频以实现一个更全面的建模场景。
为了解决这一问题,提出了两个任务,即视觉里程计(VO)和视频全景分割(VPS)。其中,VO[9,11,38]以单目视频为输入,在静态场景假设下估计摄像机姿态。为了处理场景中的动态对象,一些动态SLAM系统[2,45]使用实例分割网络[14]进行分割,并显式地过滤掉某些潜在动态的对象类别,如行人或车辆。然而,这种方法忽略了一个事实,即潜在的动态对象实际上可以在场景中是静止的,比如一辆停着的汽车。相比之下,VPS[18,44,52]则专注于在给定一些初始全景分割结果的情况下,跨视频帧跟踪场景中的单个实例。当前的VPS方法没有明确区分对象实例是否在移动。虽然现有的方法广泛地独立解决了这两个任务,但值得注意的是,场景中的动态对象会使这两个任务都具有挑战性。认识到这两个任务之间的相关性,一些方法[5,7,20,22]尝试同时处理这两个任务,并以多任务的方式训练运动语义网络,如图2所示。然而,这些方法中使用的损失函数可能相互矛盾,从而导致性能下降。

图2。插图。我们的PVO将视觉里程计和视频全景分割结合起来,通过迭代优化使两者相互强化。相比之下,SimVODIS[20]等方法以多任务的方式优化运动和语义信息。
2. Related Work
2.1. Video Panoptic Segmentation
视频全景分割的目的是产生一致的全景分割和跟踪实例的所有像素跨越视频帧。VPSNet[18]定义了这一新的任务,并提出了一种基于实例级的跟踪方法。SiamTrack[44]通过提出像素管匹配损耗和对比损耗来提高实例嵌入的鉴别能力,对VPSNet进行了扩展。VIPDeeplab[32]通过引入额外的深度信息,提供了深度感知的VPS网络。STEP[43]则提出对视频全景分割的每个像素进行分割和跟踪。HybridTracker[52]建议从两个角度跟踪实例:特征空间和空间位置。与现有方法不同的是,我们引入了VO增强VPS模块,该模块利用VO估计的摄像机姿态、深度和光流来跟踪和融合当前帧到相邻帧的信息,能够处理遮挡问题。
2.2. SLAM and Visual Odometry
SLAM代表同步自定位和地图构建,而视觉里程计作为SLAM的前端,主要关注位姿估计。现代SLAM系统大致可分为两类:基于几何的方法[8,11,29,50]和基于学习的方法[37,39,42,57]。由于有监督学习方法的良好性能,基于无监督学习的VO方法[33,54,55]受到了广泛的关注,但其性能不如有监督学习方法。一些非监督方法[16,49,59]利用多任务学习和辅助任务(如深度和光流)来提高性能。
最近,TartanVO[40]提出构建一个可推广的基于学习的VO,并在具有挑战性的SLAM数据集TartanAir[41]上对系统进行了测试。DROID-SLAM[36]提出通过密集的束调整层迭代更新相机姿态和像素深度,并展示了优越的性能。DeFlowSLAM[53]进一步提出双流表示和自监督方法,以提高SLAM系统在动态场景中的性能。为了解决动态场景的挑战,动态SLAM系统[4,13]通常利用语义信息作为约束条件[24]或在此之前提高传统基于几何的SLAM的性能,但它们[1,2,10,27,31,34,47,56,58]主要作用于立体、RGBD或LiDAR序列。相反,我们引入了一个全景更新模块,并在DROID-SLAM上构建了全景增强的VO,可以用于单目视频。这样的组合可以更好地理解场景的几何和语义,因此对场景中的动态对象更具鲁棒性。与其他多任务端到端模型[20]不同,我们的PVO有一个循环迭代优化策略,可以防止任务之间的相互危害。
3. Method
对于单目视频,PVO的目标是同时定位和全视三维制图。图3描述了PVO模型的框架。该系统由三个主要模块组成:图像全景分割模块、全景增强VO模块和全景增强VPS模块。VO模块的目标是估计摄像机的姿态、深度和光流,VPS模块输出相应的视频全景分割。最后两个模块以一种循环交互的方式相互作用。

3.1. Image Panoptic Segmentation
图像全景分割以单个图像作为输入,输出图像的全景分割结果,将语义分割和实例分割相结合,对图像的实例进行综合建模。输出结果用于初始化视频全景分割,然后送入panoptic - enhanced VO模块(见第3.2节)。在我们的实验中,如果没有特别说明,我们使用了广泛使用的图像全景分割网络PanopticFPN[21]。PanopticFPN建立在ResNet f的骨架上,用权值θe提取图像I的多尺度特征:
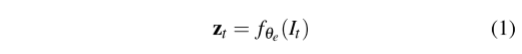
它使用解码器gθd和权值θd输出全景分割结果,包括语义分割和实例分割。每个像素p的全景分割结果为:
![]()
馈送到解码器的多尺度特征随着时间的推移而更新。一开始,编码器生成的多尺度特征被直接送入解码器(图3蓝色部分)。在后面的时间步中,这些多尺度特征在被送入解码器之前通过在线特征融合模块进行更新(见3.3节)。
(全景分割其实就是编解码器结构,而编码器出来的中间特征向量feature map,后续也要通过fused feature map更新。个人的直观理解:(如果不是初始化的第一帧)当前帧的语义分割,其实可以根据当前图像算,也可以通过前一帧+运动推测出来,换句话说如果你知道了你的位置和世界地图你也可以直接投影到当前帧得到一个先验)
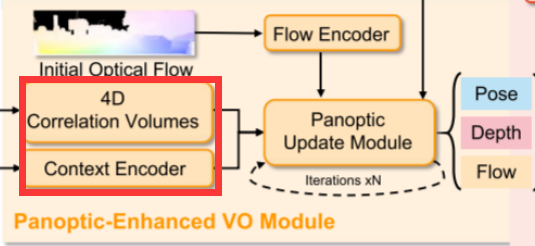
3.2. Panoptic-Enhanced VO Module
在动态场景普遍存在的视觉里程计中,滤除动态物体的干扰至关重要。DROID-SLAM[36]前端以单目视频为输入,通过迭代优化光流r和置信区间w,优化摄像机位姿G和逆深度d的残差。它不考虑大多数背景是静态的,前景对象可能是动态的,每个对象像素的权重应该是相关的。Panoptic-Enhanced VO Module的内部(见图4)是通过整合来自panoptic segmentation的信息来辅助获得更好的置信度估计(见图7)。因此,Panoptic-Enhanced VO Module可以获得更精确的相机姿势。接下来,我们将简要回顾DROID-SLAM的相似部分(特征提取和相关性),重点介绍panoptic update模块的复杂设计。

3.2.1 Feature Extraction and Correlation
特征提取。与DROID-SLAM[36]类似,Panoptic-Enhanced VO Module借用了RAFT[35]的关键部件来提取特征。我们使用两个独立的网络(一个特征编码器和一个上下文编码器)来提取每幅图像的多尺度特征,利用特征编码器的特征构建成对图像的4D相关量,并将上下文编码器的特征注入到panoptic update模块中(见3.2.2节)。该特征编码器的结构类似于全景分割网络的主干,可以使用一个共享的编码器。注意,为了实现方便,我们使用了不同的编码器。
相关金字塔和查找。与DROIDSLAM[36]类似,我们采用帧图(V,E)来表示帧之间的共可见性。例如,边(i, j)∈E表示保持重叠区域的两幅图像Ii和Ij,通过这两幅图像的特征向量的点积可以构造出4D相关体:
![]()
通过平均池化层得到金字塔相关。我们使用与DROID-SLAM[36]中定义的相同的查找操作符,通过双线性插值对金字塔相关体积值进行索引。将这些相关特征串联起来,得到最终的特征向量。
3.2.2 Panoptic Update Module
Panoptic-Enhanced VO Module(见图4)继承了DROID-SLAM的前端VO模块,利用全景分割信息调整VO权重。将初始光流输入流编码器获得的流信息,并将两帧建立的4D相关体和上下文编码器获得的特征作为中间变量输入GRU,然后三层卷积输出一个动态掩码M,相关置信度映射w和密光流delta r。给定初始化的全景分割,我们可以调整动态蒙版以适应全景感知的动态蒙版。为了便于理解,我们保持符号不变。特别是将材料分割设置为静态,将动态概率高的前景对象设置为动态。全景感知置信度是通过panoptic-aware filter module对置信度和动态mask处理得到的,η设为10。
![]()
将得到的流delta r加上原始光流,并将其反馈到密集束调整(DBA)层,对反深度和位姿的残差进行优化。全景更新模块迭代优化N次,直到收敛。在DROID-SLAM[36]之后,位姿残差∆ξ (n)在SE3流形上进行变换,更新当前位姿,深度残差和动态掩码分别添加到当前深度和动态掩码上:
![]()

(上边就是迭代公式,位姿G和深度d就是优化目标)
相关性。我们首先在每次迭代中使用当前的姿态和深度估计来寻找对应。参考DROID-SLAM[36],对于帧i中每个像素坐标pi,可以计算出帧图中每个边(i, j)∈E的密集对应域p,如下所示:
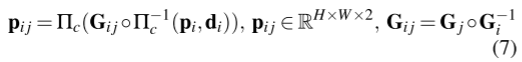
其中Πc为将三维坐标点重新投影到图像平面的相机模型,Π−1 c为将二维坐标网格pi和深度逆映射d投影到三维坐标点的反函数。Gij表示图像Ii和Ij的相对姿态。pi j是将像素pi的坐标用当前估计的位姿和深度映射到j帧时的二维坐标网格。修正后的对应关系表示预测对应关系和光流残差之和,即![]()
(公式7其实就是K是相机内参,G是转移矩阵T包括旋转和平移,相当于已知当前帧像素点的位置pi+深度di+位姿变换G,求另外一帧中的位置pij,这里还通过光流做了一个偏置)
DBA Layer。我们使用DROID-SLAM[36]中定义的密集束调整层(DBA)来修改地图流,以更新当前估计的像素深度和姿态。成本函数可以定义为:
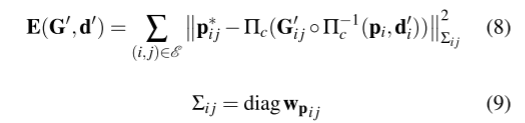
我们使用Schur补体来解决非线性最小二乘问题,方程8。利用高斯-牛顿算法更新位姿(∆ξ)、深度和掩模(∆Θ)的残差。
(这里这个优化范数最小,个人理解就是优化目标是重投影误差pij*-pij最小,优化参数是转移矩阵G+深度d)
3.3. VO-Enhanced VPS Module
视频全景分割的目的是获得每一帧的全景分割结果,并保持帧间分割的一致性。为了提高分割精度和跟踪精度,一些方法如FuseTrack[18]尝试利用光流信息融合特征,并根据特征的相似度对特征进行跟踪。这些方法仅来自可能遇到遮挡或剧烈运动的2D视角。我们生活在一个3D世界里,额外的深度信息可以用来更好地建模场景。我们的VO-Enhanced VPS模块就是基于这种理解,可以更好地解决上述问题。

图5所示为VO-Enhanced VPS模块,该模块利用视觉测程获得的深度、位姿和光流信息,将前一帧t−1的特征扭曲到当前帧t,从而获得扭曲的特征。在线融合模块将当前帧的特征和变形后的特征进行融合,得到融合后的特征。为了保持视频分割的一致性,我们首先将变形特征t−1(包含几何运动信息)和融合特征映射t输入解码器,分别得到全景分割t−1和t。然后使用一个简单的iou-match模块来获得一致的全景分割。这个结果将被送入全景增强VO模块。
VO-Aware Online Fusion.特征融合网络首先将两个特征zt−1和zt连接起来,然后经过一个具有ReLU激活的卷积层,得到融合后的特征ˆzt。受NeuralBlox[25]的启发,我们提出了两个loss function进行监督,以保证在线特征融合的有效性(见表5)。
Feature Alignment Loss我们采用一种特征对齐损失来最小化潜在空间中zt∗与ˆzt之间的距离:其中zt∗表示从不同图像到相同图像的相同像素的平均特征。
![]()
Segmentation Consistent Loss此外,我们添加了一个分割损失,以最小化使用不同特征zt∗和ˆzt解码的查询像素p的logit差异:
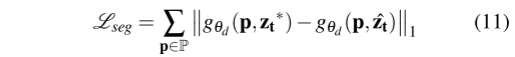
(上一帧的特征通过pose+depth+flow 转移到当前视角下,和当前图像对应的全景分割左iou loss,可以简单理解为通过运动从上一个估计的语义和当前时刻从图像出来的语义做loss,只不过这里用的是warp特征向量)
3.4. Recurrent Iterative Optimization
在EM算法的启发下,我们可以对所提出的Panoptic-Enhanced VO模块和VO- enhanced VPS模块进行循环迭代优化,直到收敛为止。实验上,通常只需要两次迭代循环就会收敛。从表5和表6可以看出,循环迭代优化可以提高VPS模块和VO模块的性能。
(循环迭代是,固定一个调整另外一个吗?有点gan的感觉?)
3.5. Implementation Details
PVO由PyTorch实现,主要包括三个模块:图像全景分割、全景增强的VO模块和VO增强的VPS模块。我们用三个阶段来训练我们的网络。
图像全景分割在Virtual KITTI[3]数据集上进行初始化训练。在PanopticFCN的基础上,我们在训练过程中采用多尺度的缩放策略。我们在两个GeForce RTX 3090 gpu上以1e-4的初始速率优化网络,其中每个小批处理有8张图像。SGD优化器的权重衰减为1e-4,动量为0.9。
panoptic-enhanced的VO模块的训练遵循DROIDSLAM[36],除了它补充地面真实全景分割结果。具体来说,我们在使用两个GeForce RTX3090 gpu的Virtual KITTI数据集上对该模块进行了80,000步的训练,这大约花了两天时间。在训练VO-enhanced video panoptic segmentation module时,我们利用地真深度、光流和姿态信息作为几何先验对特征进行对齐,并固定训练后的单图像全景分割的主干,然后只训练融合模块。该网络在一个GeForce RTX 3090 GPU上以1e-5的初始学习速率进行优化,其中每批有8张图像。当融合网络基本融合后,我们添加了分割一致性损失函数来进一步完善我们的VPS模块。
4. Experiments
对于视觉里程计,我们在三个动态场景的数据集上进行了实验:Virtual KITTI, KITTI和TUM RGBD动态序列。采用绝对轨迹误差(ATE)进行评价。对于视频全景分割,我们在cityscape和VIPER数据集上使用视频全景质量(VPQ)度量[18]。我们进一步在Virtual KITTI上进行消融研究来分析我们的框架设计。最后,我们论证了我们的PVO在视频编辑方面的适用性,如补充材料中的B节所示。
4.1. Visual Odometry
vkitti2。虚拟KITTI数据集[3]由从KITTI跟踪基准中克隆出来的5个序列组成,为每个序列提供RGB、depth、class segmentation、instance segmentation、camera pose、flow和scene flow数据。如表6和图6所示,我们的PVO在大多数序列上都比DROIDSLAM有很大的优势,并且在序列02上取得了竞争性能。
KITTI。KITTI[12]是一个捕捉真实世界交通场景的数据集,从农村地区的高速公路到城市街道,有大量的静态和动态对象。我们将在VKITTI2[3]数据集上训练的PVO模型应用于KITTI[12]序列。如图6 (KITTI 09和10序列)所示,PVO的位姿估计误差仅为DROID-SLAM的一半,证明了PVO具有良好的泛化能力。表1显示了在KITTI和VKITTI数据集上完整的SLAM比较结果,其中PVO在大多数场景下都大大优于DROID-SLAM和DynaSLAM。注意,我们使用的是DynaSLAM的代码,这是一个典型的SLAM系统,带有实例分割。DynaSLAM在VKITTI2 02、06和18序列中陷入灾难性系统故障。
TUM-RGBD.。TUM RGBD是一个用手持相机捕捉室内场景的数据集。我们选择了TUM RGBD数据集的动态序列来验证我们方法的有效性。我们将PVO与DROIDSLAM以及DVO SLAM[17]、ORB-SLAM2[30]和PointCorr[6]这三种最先进的动态RGB-D SLAM系统进行比较。注意,PVO和DROID-SLAM只使用单眼RGB视频。表2显示PVO在所有场景中都优于DROID-SLAM。与传统的RGB-D SLAM系统相比,我们的方法在大多数场景下都有更好的表现。
4.2. Video Panoptic Segmentation
我们将PVO与VPSNet-Track、VPSNetFuseTrack[19]和SiamTrack[44]三种基于实例的视频全景分割方法进行比较。VPSNetTrack在图像全景分割模型UPSNet[46]的基础上,增加了MaskTrack头[48],形成视频全景分割模型。基于VPSNet-Track的VPSNet-FuseTrack补充了时间特征聚合与融合。而SiamTrack细调VPSNet-Track与像素管匹配损失[44]和对比度损失,并有轻微的性能改善。之所以比较VPSNet-FuseTrack,主要是因为SiamTrack的代码不可用。
Cityscapes.我们在VPS[18]中采用了cityscape的public train/val/test分割,其中每个视频包含30个连续的帧,每5帧对应的ground truth注释。表3显示,我们使用PanopticFCN[23]的方法在val数据集上的性能优于目前最先进的方法,比VPSNet-Track实现了+1.6%的VPQ。与VPSNetFuseTrack[18]相比,我们的方法有轻微的改进,可以保持视频分割的一致性,如图补充材料中的A4所示。原因是由于内存有限,我们的VO模块只能获得1/8分辨率的光流和深度。
VIPER.VIPER维护了大量高质量的全景视频注释,这是另一个视频全景分割基准。我们遵循VPS[19],并采用其公共列车/val分割。我们使用10个从日常场景中选择的视频,每个视频的前60帧用于评估。表4显示,与VPSNet-FuseTrack相比,我们使用PanopticFCN的方法在VIPER数据集上获得了更高的分数(+3.1 VPQ)。
4.3. Ablation Study
VPS-Enhanced VO Module.在全景增强的VO模块中,我们使用DROID-SLAM[36]作为基线。(VPS>VO)表示预先添加全景信息以增强VO基线。(VPS->VO x2)意味着我们可以迭代优化VO模块两次。(VPS->VO x3)表示对VO模块进行3次循环迭代优化。表6和图7显示,在VKITTI2的大部分高动态数据集上,全景图信息可以帮助提高DROID-SLAM的准确性。循环迭代优化可以进一步改善结果。
VO-Enhanced VPSModule.为了评估VO是否有助于VPS,我们首先使用PanopticFPN[21]得到每帧的全景分割结果,然后利用RAFT[35]的光流信息进行帧间跟踪。这被设置为VPS基线。(VPS基线+ w/fusion)意味着我们额外地将特征与流量估计融合。(VO->VPS + w/o融合)意味着我们在基线上使用额外的深度、姿态和其他信息。(VO->VPS)意味着我们额外融合了特征。(VO>VPS x2)表示我们使用循环迭代优化模块来进一步提高VPS结果。如附录材料中的表5和图A3所示,VO-Enhanced VPS模块在提高分割精度和跟踪一致性方面是有效的。
Online Fusion in VO-Enhanced VPS Module.为了验证所提出的特征对齐损失(Feature Alignment Loss, fea Loss)和分割一致损失(Segmentation Consistent Loss, seg Loss)的有效性,我们采用以下方法:(VO->VPS + w/fusion + w/o fea Loss),即在没有特征对齐损失的情况下,对在线融合模块进行训练。(VO->VPS + w/fusion + w/o seg loss)表示我们在没有Segmentation Consistent loss的情况下训练在线融合模块。表5显示了这两个损失函数的有效性。
5. Conclusion
我们提出了一种新的全景视觉里程计方法,该方法将VO和VPS建模在一个统一的视图中,使这两个任务能够相互促进。全景图像更新模块可以提高姿态估计,在线融合模块可以提高全景图像分割。大量的实验表明,我们的PVO在这两个任务中都优于最先进的方法。
局限性。主要的限制是PVO建立在DROID-SLAM和全景分割的基础上,这使得网络很重,需要很大的内存。虽然PVO在动态场景中表现良好,但它忽略了摄像机返回到前一位置时的环路闭合问题。我们未来的工作是探索一种低成本、高效的闭环SLAM系统。
自己总结:
好像这个能做的差不多做完了,语义,VO,深度,光流,作者自己留的坑是回环,但是如果加回环,似乎也没有地图点这种优化,只能回环整体位姿优化?
如果用传统建地图点+深度学习+深度估计+光流,这时候再加回环和重定位、小地图等工程功能会不会更好?








![[测试猿课堂]小白怎么学测试?史上最全《软件测试》学习路线](https://img-blog.csdnimg.cn/img_convert/c59142a63c9c3d2442bb59f85d863f8c.jpeg)